
HTTP协议报文头域关键字段的隐蔽通信检测模型*
2018-12-19 03:45李东东赵运弢冯永新
火力与指挥控制 2018年11期
刘 芳,李东东,赵运弢,冯永新
(沈阳理工大学信息科学与工程学院,沈阳 110159)
0 引言
隐蔽通信[1]最早的描述模型是Simmons提出的囚徒问题(The Prisoners’problem)[2]。其概念最先被Lampson提出,其是允许一方不违反系统的安全策略的方式将消息传递到另一方,同时它可以有效抵御外部的审查[3]。在隐蔽信息秘密的交互过程中及双方系统安全策略许可的条件下,利用信息隐藏的手段在传递正常消息的基础上加载让人无法察觉的信息。
网络协议的信息隐藏主要以网络层[4]的IP和ICMP协议,传输层的TCP和UDP协议为主,伴随着HTTP协议[5]在实际生活中广泛的使用,并且现实的防火墙[6]技术对非法HTTP拦截的能力的有限,使得人们的信息安全无法受到保障,其中HTTP隐蔽信道威胁就是其中之一。国内对于隐蔽通信领域研究已经快速地起步,1999年,周仲义、何德全和蔡吉人3位院士在北京联合发起第一届全国信息隐藏学术会议,这意味着隐蔽信道在国内学术研究正式展开[7]。在这短短的十年时间,关于隐蔽信道的会议已经开展了十几届,涉及了众多的学科领域,如密码学[8]、信息处理技术等[9],邹晓光等提出了基于HTTP参数排列的信息隐藏算法[10]。利用请求报文的请求首部Accept域中的选项参数之间的排列位置来编码隐藏信息。
本文主要针对网络应用层HTTP报文头域敏感关键字段采用相关性分析[11]模型及差值距离检测算法对隐蔽信道进行检测。
1 HTTP隐蔽信道相关理论研究
在实际的HTTP应用中,通信双方只会针对规定的关键字和选项参数进行处理,而对协议规定外的关键字或者选项参数采取被动忽略策略,这些字段则自动丢弃,这一特性的产生就会导致隐蔽信道的存在,具体的信息隐蔽通信方式如下:
字符串自定义[12]:向HTTP报头文件中加入无关字段Convert-Text,通过这一字段进行隐蔽信息的传递。
选择法编码[12]:通过报头字段进行选择对隐蔽信息进行编码,以实现隐蔽通信,具体如图2所示。在HTTP通信双方处理HTTP协议报文时,对关键字段和选项参数的排序是不敏感的,因为该顺序在RFC2616的HTTP协议1.1版本规范[13]中并未有严格说明,并且该顺序不会对HTTP的具体应用产生任何的影响。
排列顺序编码[12]:由于HTTP协议报文对字段的顺序排列是不敏感的,通过该特征排列顺序对隐蔽信息进行编码,实现隐蔽通信。
重排序方式在HTTP协议的隐蔽信道实际构建当中是极易使用的手段,通信双方对HTTP协议报文进行处理时,利用其关键字段和选项参数不敏感特性进行信息隐藏,因此,本文重点对以上3种隐蔽信道构建模型进行检测,提出了HTTP协议下隐蔽通信空间相关性检测模型。
空格编码法与字符大小写编码:由于HTTP协议报文对字段内空格与字符大小写是不敏感,这两种格式并不会影响协议通信的正确性,而且在实际隐蔽信道的构建中这两种形式极易形成,因此,本文主要针对空格编码与字符大小写编码隐蔽信道进行检测。
以空格编码与字符大小写隐蔽信道为例,具体方式如图1所示。
2 算法模型设计
目前,隐蔽信道的检测研究理论成果重点针对网络层与传输层中赘余字段进行研究,而对于应用层协议(本文重点是HTTP协议)隐蔽信道形成理论与检测手段还存在明显的欠缺。因此,本文提出了对HTTP报文协议隐蔽信道关键字段检测模型。该检测模型能够精确实现对HTTP报文头域从二维的角度对关键字段进行检测。
HTTP隐蔽信道检测设计模型主要在纵向检测和横向检测两种领域展开。
纵向检测定义:在单一报文分别对报文头域关键敏感字段(Host、Connection、Content-Type等)隐蔽信道存在性进行检测。
横向检测定义:对多组报文间报文头域关键敏感字段(Host、Connection、Content-Type等)隐蔽信道存在性进行检测。

图1 HTTP协议报头空格编码(左)与字符大小写编码(右)隐蔽信道
2.1 隐蔽信道纵向检测模型设计
相关分析(correlation analysis)是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向及相关程度。
2.1.1 相关性模型理论分析
HTTP报文隐蔽信道构建主要包含以下两类:
1)直接将隐蔽信息嵌入到数据报文中;
2)通过改变数据报文的每一个字段的特征,并利用该特有的特征对其进行信息编码,从而达到隐蔽信道传递的目的。
HTTP报文隐蔽信道的构建通过对隐蔽信息进行人为编码设计,实现隐蔽信息传递,在这一过程中被处理后的报文数据特征与正常数据报文信息特征会存在明显的差异性,这种差异性会导致正常HTTP数据报文与非正常HTTP隐蔽报文之间相关性程度大大降低。在HTTP正常数据报文交互过程中,其报文的绝大多数字段是固定的,其小部分字段会发生改变,例如Host与Context-length字段;人为设计的隐蔽信道要保证传递信息的保密性,信息容量大特性会对其特征字段进行人为的更改,其改变不再局限于Host与Context-length两个字段,而是扩展到其他的HTTP数据报文字段;利用这一特征通过对其相关性计算可以得到正常通信HTTP数据报文相关性检测结果为G,正常样本与隐蔽信道相关性检测结果为H,在使得两次相关性结果进行相减得到两次相关性检测的差值A,通过大量的实验样本数据得到人为的相关性检测阈值,通过A与之间的比对最终实现隐蔽信道的判决。具体检测流程如图2所示。
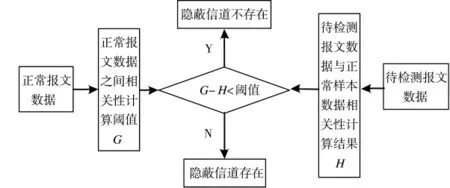
图2 字符隐蔽信道检测流程图
2.1.2 实验相关性检测模型设计
皮尔逊相关也称为积差相关(或积距相关),是英国统计学家皮尔逊于20世纪提出的一种计算直线相关性的算法,其具体的公式推理如下:
假设有两个变量X,Y那么两变量之间的皮尔逊相关系数ρxy可以通过以下公式计算:
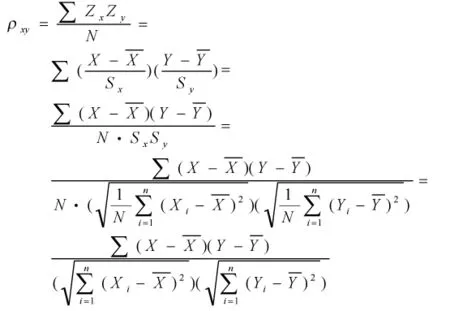
相关系数 ρx,y性质如下:
2)ρx,y为正值,两变量之间呈现正相关性,ρx,y为负值,两变量之间呈现负相关性;
3)相关系数 ρx,y的绝对值 ρx,y越大,两变量的相关程度就越密切,ρx,y=+1时,两变量完全正相关;ρx,y=-1 时,两变量完全负相关;ρx,y=0 时,两变量完全无关。
2.2 隐蔽信道横向检测模型设计
2.2.1 差值距离模型理论分析
网络信息的传递依靠HTTP报文沿时间轴的方向传输,这改变了纵向检测模型的检测理论范围,增加了隐蔽信道的构建形式,而沿时间轴方向隐蔽信道构建在现实很多领域都切实存在着。
横向隐蔽信道构建会通过对关键敏感字段中利用一个或多个字符在多报文之间沿时间轴方向进行隐蔽信息隐藏,这种隐藏手段利用纵向检测手段很难实现有效的检测,根据横向隐蔽信道形成的特点可以发现,在多报文之间相对应的字符会产生改变,进而改变字符的ASCII值,利用这一特性可以进行多报文头域字符差值计算,正常报文传输报文头域中标志位变化程度很低,其差值为0,当人为进行隐蔽信道构建的过程中会对其修改,这会导致报文头域关键敏感字段差值改变,通过这种改变实现隐蔽信道判定。
2.2.2 差值距离检测算法设计
建立数学模型:Y(s,z,t)=F(s,z,t)
s:代表报文中位置坐标(0,50,100,150,200,…);
z:代表不同时间,相同位置坐标下差值xi2~xi1大小;
t:代表时间轴;
对实验数据进行处理,建立数据矩阵A。
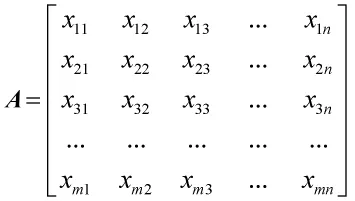
x11,x21…表示报文每一位十进制数值;
m代表报文头域中位置排列序号;
n代表报文传输的时间。
运用差值距离检测算法 F(s,z,t)分别报文头域中相邻位置上的十进制数求差值,得到矩阵B;
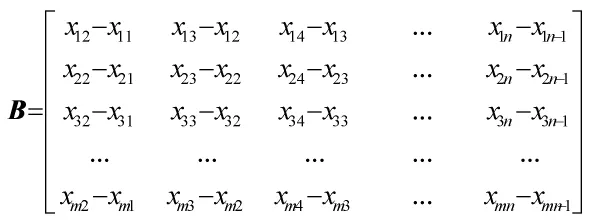
3 实验结果分析
3.1 数据准备
本实验数据来源于实验室UDDI[14]服务数据,利用抓包软件Wireshark对HTTP报文数据进行抓取。
3.2 实验结果与分析
本实验采用的样本为HTTP协议报文样本,样本数量为400,随机抽取其中一个样本进行相关性比对,重复试验和过程,直到所有样本测试完毕,并最终验证HTTP报文字段空格隐蔽信道的存在。正常数据1与正常数据2之间数据相关性为99.4%,非正常报头(空格隐蔽信道)与正常报头1之间的相关性为74.9%,非正常包头与正常报头2之间的相关性为75.3%,其出错概率(显著性)为0,通过实验的数据可以表明,正常隐蔽信道与非正常隐蔽信道之间的相关性区分度和准确性非常明显,可以很好地检验隐蔽信道的存在,实验数据结果如表1所示,仿真效果如图3所示。

表1 单一样本随机抽样空格隐蔽信道相关性实验仿真数据结果
字符大小写隐蔽信道检测实验同样采用HTTP协议报文样本,样本数量为400,随机抽取其中一个样本进行相关性比对,重复试验和过程,直到所有样本测试完毕,并最终验证HTTP报文字段字符大小写隐蔽信道的存在。正常报头1与正常报头2之间的相关性程度为99.4%,正常报头1与非正常报头(含有字符大小写隐蔽信道)之间的相关性程度为61.8%,正常包头2与非正常报头之间的相关性为62.8%,其隐蔽信道区分度差异较大,可以很好地识别字符隐蔽信道的检测,实验数据结果如表2所示,仿真效果如图4所示。
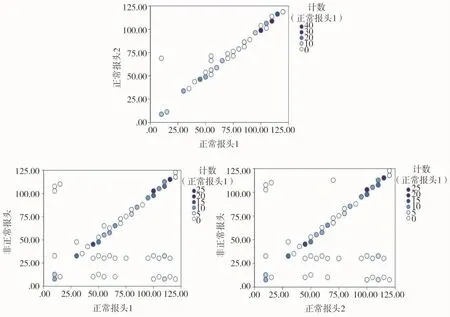
图3 空格隐蔽信道相关性检测仿真图
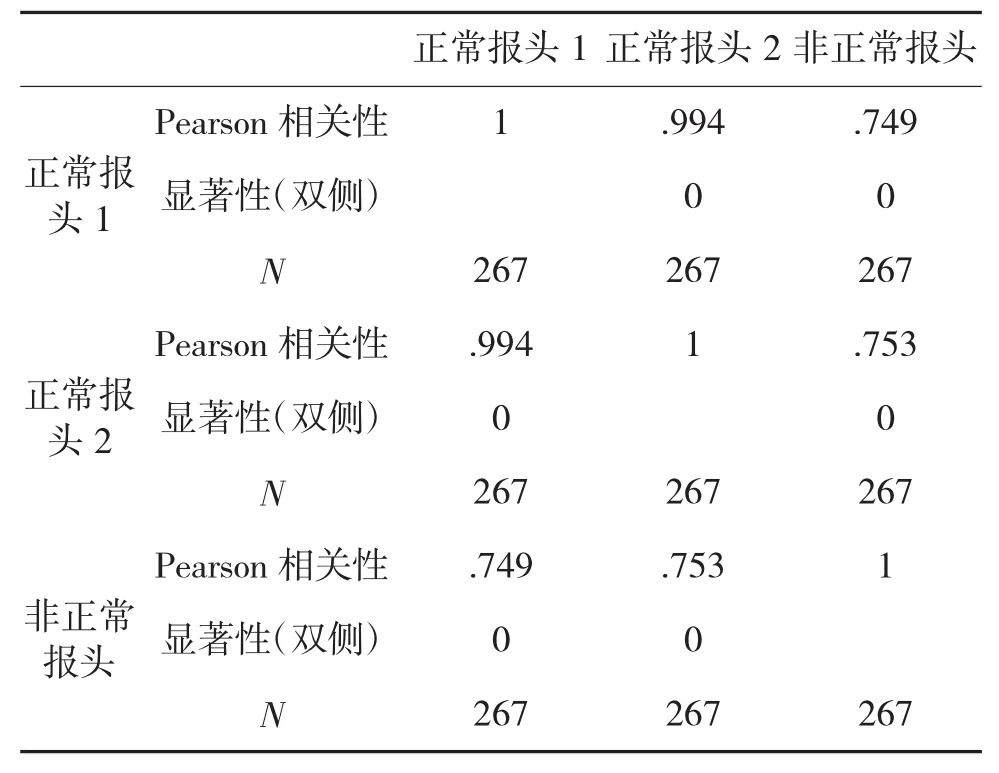
表2 单一样本随机抽样相关性字符大小写实验仿真数据结果
由于正常报文通信的过程中,其报文头域格式是相对固定的,其变化主要与host(主机iP地址)与Context-length(包体长度)字段。由此可以得到正常报文与正常报文2之间的相关性仅有较少的差异,其相关性程度非常高。然而认为加入的隐蔽信道大大改变了信息报文头域中字段特征,其字段变化不再仅局限Host字段和Context-length字段,对其相关性程度很低,其仿真结果呈现杂乱无章的状态。
差值距离检测实验采用316个HTTP报文头域实验检测样本数据,由于人为对HTTP报文头域中“双字符”进行隐蔽信息处理,通过差值距离检测算法对HTTP报文数据进行差值计算,最后由MatLab软件进行仿真,得到最终的仿真实验结果,通过仿真结果可以看出:人为对隐蔽信道进行处理在相同字符不同时间上差值会产生波峰、波谷变化,通过差值距离检测算法模型可以很好地对隐蔽信道进行横向检测,其检测分辨率明显,具体如图5所示。由图所知报文头域字符空间为0~200之间,纵坐标波峰与波谷代表相邻字符数据的差值变化。图5左图、右图分别代表多字段信息隐藏与单一字段信息隐藏检测效果图。

图4 字符大小写隐蔽信道相关性检测仿真图
4 结论
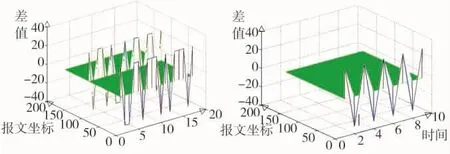
图5 差值距离检测仿真效果图
本文所设计的技术模型主要针对HTTP网络应用层报文头域隐蔽信道关键字段进行检测。通关相关性检测模型实现纵向隐蔽信道检测,通过差值距离检测算法实现对隐蔽信道横向检测,验证了相关性模型与差值距离检测算法理论的正确性与检测的有效性,使得隐蔽信道的检测精度有了很大的提升。从而很好地提升了目前针对应用层HTTP隐蔽信道检测存在的检测手段与检测精度不足的问题。然而隐蔽信道检测领域仍然存在着很大的检测漏洞威胁,对于报文头域多维字段隐蔽信道检测还存在明显的不足,有效地解决隐蔽信道报文头域多维检测成为未来该领域发展的主要趋势。
猜你喜欢
电脑爱好者(2021年23期)2021-12-08
昆明医科大学学报(2021年5期)2021-07-22
办公室业务(2019年13期)2019-08-01
新闻爱好者(2018年11期)2018-12-05
高中时代(2017年7期)2018-02-24
南方农业·下旬(2017年8期)2017-10-23
同舟共进(2016年5期)2016-05-04
新世纪图书馆(2014年7期)2014-09-19
新世纪图书馆(2014年7期)2014-09-19
新闻爱好者(2009年15期)2009-11-26
