
基于云计算的嵌入式人机交互系统
2018-12-15 07:05叶鹏田会峰宗航飞
电子设计工程 2018年23期
叶鹏,田会峰,宗航飞
(江苏科技大学苏州理工学院电气与信息工程学院,江苏张家港215600)
随着计算机以及电子技术的不断发展,人机交互越来越频繁,人机交互的模式也发生着巨大改变[1]。人们不满足于仅仅实现基本功能,对交互方式提出了更多需求,而语音交互以其有效、直接、自然的特点成为替代传统按键与屏幕交互的理想方式。对此已有诸多探索,例如将语音交互技术应用于智能家居[2]与无人驾驶车辆[3]中。
此前嵌入式系统中语音交互的研究重点都集中于在各种硬件平台例如可编程逻辑门阵列(Field-Programmable Gate Array,FPGA)[4],STM32[5]或者数字信号处理器(Digital Signal,DSP)[6]上实现实时语音算法。然而在硬件上集成语音识别算法不仅对硬件的成本要求过高,并且由于嵌入式平台的计算资源有限,识别效率并不高。文中提出了一种基于云计算[7]与ZigBee无线通信技术[8]的人机交互系统,该系统借助云端识别引擎以较低成本获得了较高的识别率。
1 系统方案设计
1.1 人机对话的基本流程及相关技术介绍
人机对话的目的是通过模拟人与人自然语言交流的过程实现人机交互,涉及的技术包括连续语音识别,智能问答系统,文本转语音(Text To Speech,TTS)等,图1为其主要流程。

图1 人机对话流程图
1.2 连续语音识别系统
语音识别是机器通过识别和理解过程把语音信号转变为相应的文本文件或命令的技术,作为一门交叉学科,它涉及声学、语音学、语言学、人工智能、数字信号处理理论、信息理论、模式识别理论、最优化理论、计算机科学等众多科学紧密相连,除此之外,其应用前景也非常广阔。

图2 连续语音识别框图
如图2所示,一个完整的语音识别系统由四个部分组成:特征提取,声学模型训练,语言模型训练和解码器特征提取[9]。语音识别分两个阶段进行。首先需要进行模型的训练。其中,声学模型的训练指根据训练语音库的特征参数训练出声学模型参数;语言模型的训练指对训练文本数据库进行语法、语义分析,经过基于统计模型训练得到语言模型。其次,语音识别阶段,需要先提取语音特征,即去除语音信号中对于语音识别无用的冗余信息,保留能够反映语音本质特征的信息,并用一定的形式表示出来。再将提取的特征进行解码,即通过声学模型和语言模型将训练集外的语音数据识别成文字。
而语音识别的基本框架可由如下公式表示。
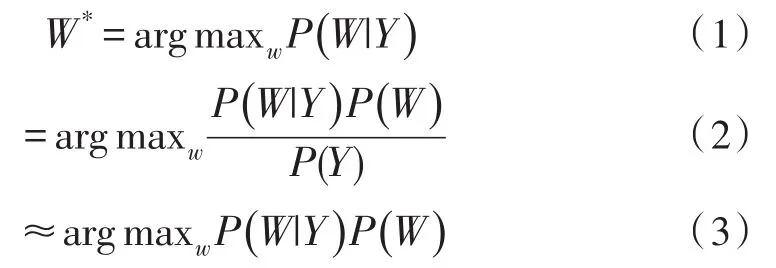
上式中W表示文字序列,Y表示语音输入。公式(1)表示语音识别的目标是在给定语音输入的情况下,找到可能性最大的文字序列。根据贝叶斯公式,可以得到公式(2),其中分母表示出现这条语音的概率,它相比于求解的文字序列没有参数关系,可以在求解时忽略,进而得到公式(3)。公式(3)中第一部分表示一个给定的文字序列出现这条音频的概率,即语音识别中的声学模型(Acoustic Model,AM);第二部分表示出现这个文字序列的概率,即语音识别中的语言模型(Language Model,LM)。
1.3 自动问答系统
自动问答系统是自然语言处理领域的一个重要方向,旨在让用户直接用自然语言提问并获得答案,。传统的搜索引擎是根据关键词检索并将返回大量相关文档集合,需要用户亲自去查找自己相关的资料。从这样的比较可以看到,问答系统的实现将使用户在海量数据中查找相关资料时节省大量的时间。

图3 问答系统的处理框架
如图3所示,其处理框架主要包括问句理解、信息检索、答案生成与验证3个部分[10],其中问句理解实现词法分析、句法分析和问题分类等基本功能以保证系统的高准确率;信息检索这步通过传统信息检索技术获得可能存在答案的文档并对文档进行排序;答案生成及验证部分指对信息检索得到的候选文档进行词法、句法、语义等方面的分析,并且根据问题的类别抽取相应的答案返回给用户。
目前,自动问答系统还处在起步阶段,其准确率还较低,例如在一项改进微信平台的自动问答系统的工作中,问答系统的准确率为76.77%[11]。
1.4 文字转语音系统(TTS)
TTS是语音合成应用的一种,它可以将文本转换成自然语音输出。其处理流程如图4所示。
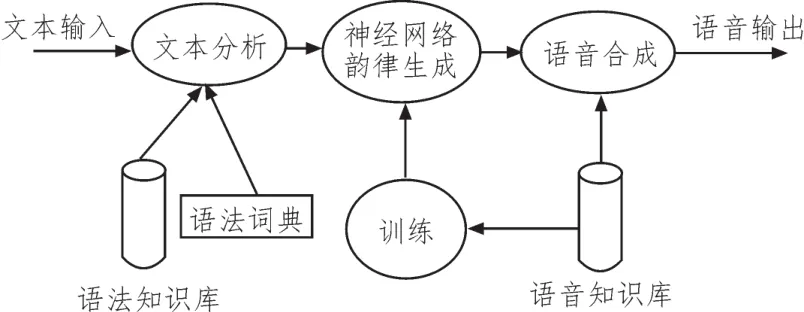
图4 文字转语音系统框架图
如图中所示,语音转文字系统有3个模块:文本处理模块、韵律处理模块、声音合成模块[12]。因为本文中介绍的是基于云计算的系统,所以韵律生成模块会在云端进行训练与调用。文本处理模块位于系统的前端,其内容有文本分词、非标准词正则化、字音转换。韵律处理模块主要负责从文本中提取韵律结构、重音和语调等与韵律有关的信息。声音合成模块是语音合成系统的后端模块,主要进行声音合成并对其进行修改与输出。
随着深神经网络技术的兴起,已有不少学者对深度神经网络在语音生成上的应用做出诸多尝试[13]。
1.5 人机交互系统总体设计
1.5.1 总体结构
如图5所示,系统总体可以分为云端和硬件交互系统两大部分。其中云端上搭载训练好的语音模型,实现连续语音识别、自动问答、语音转文字3个人机对话的核心功能,并且云端也可以实现数据存储以及硬件节点的控制。硬件交互系统主要负责语音的采集播放以及传感器信息、语音信息、云端控制信息在节点、主控和云端之间的传递,它包含五部分:基站、节点、机器人平台、麦克风阵列、连接在节点上的传感器和执行机构。
其中,节点与基站之间通过ZigBee通信技术实现无线通信,并且每个节点以单片机作为主控,单片机上连接了多个传感器与执行机构,可以将云端解析出的语音信息变成相应的执行动作。

图5 系统总体结构图
1.5.2 系统运作模型
如图6所示,使用该人机交互系统进行交互的过程是一个用户、硬件与云端相互合作的过程。本文将系统划分为用户、基站和节点、云端3个对象主体,基于UML活动图[14]建立了系统整体运作模型,该图描述了用户与系统进行交互过程中涉及的各个对象主体的主要活动和相互之间的动态行为。
由系统的运作模型可知,实现用户与系统交互有3个主要环节:一是用户操作,二是硬件采集和播放声音,节点执行机构执行指令和传感器采集环境信息,三是调用云端引擎。具体的运行逻辑可以从基站与节点两个方面阐述。
首先是基站,基站主要设计了两部分功能,本地的语音交互功能与远距离的手机APP控制功能。基站通过采音设备采集各个节点处的语音信号并将其上传至云端语音识别引擎进行解析,解析出的结果会以文本的形势返回。基站再对返回的文本进行匹配,如果匹配上事先设置好的控制命令则会通过ZigBee网络传输给节点执行相应的命令以实现语音交互中的控制功能;如果没有匹配到事先设置好的命令,则会将此文本上传至云端的TTS引擎进行文字转语音,并将解析出的语音信号返回本地播放,从而实现语音交互中的对话功能。
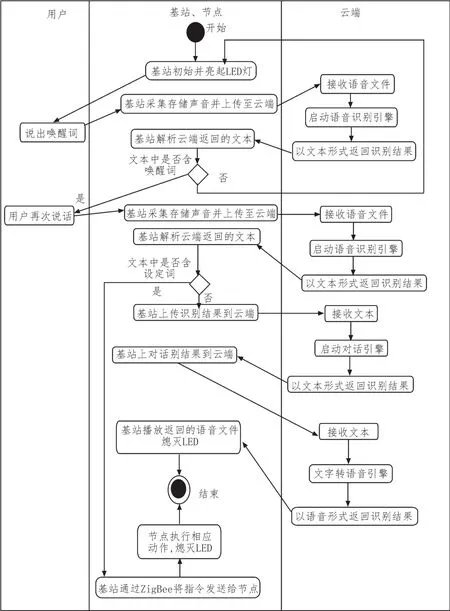
图6 系统交互UML活动图
基站主控还连接开源的物联网云平台YeeLink,借助配套的手机APP,我们可以远距离查看与节点相连的设备状态,并且可以通过手机远程控制家里的家电设备。
节点有两种工作模式,第一种模式下它可以作为交互系统的终端执行机构和环境信息的采集装置,第二种模式下它可以单独作为一个自动运行的控制器,例如在智能家居的应用场景中,
通过设置可以让节点工作于两种状态,用户通过说出“进入用户模式”的指令控制节点进入第一种状态,此时节点等待用户的指令,如果此时用户有打开窗户的指令,节点就会驱动相应的执行机构动作,实现开窗的操作,如果用户说出“进入自动模式”就会进入第二种模式,此时节点就会按照事先设定的程序自动运行,例如下雨关窗,天黑关窗帘等。
2 交互系统硬件设计
2.1 基站硬件设计
基站由树莓派开发板作为主控,它是一款基于ARM的微型电脑主板,以MicroSD卡为内存硬盘,卡片主板周围有4个USB接口和一个以太网接口,可连接键盘、鼠标和网线,同时拥有视频模拟信号的电视输出接口和HDMI高清视频输出接口。
主控与一块ZigBee通信模块相连,它是一种自组网多跳无线通信模块。该模块上电后会与周围的模块自动组成一个无线多跳网络,此网络为对等网络,不需要中心节点。模块频率为2.4~2.45 GHz,属于全球免费的无线频段。将ZigBee模块设置为串口透传工作模式后,可以通过串口将基站或节点单片机上的数据自动打包成相应的数据格式并借助ZigBee网络发送给对方,实现传感器数据与控制信号的本地网络传输。
基站还连接多个采音设备以及一个扬声器,其电路图如图7所示。
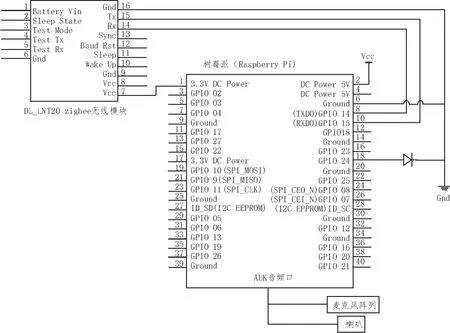
图7 基站电路图
其中所有的语音采集设备和扬声器均通过延长线伸展至节点附近,用户只需在节点附近靠近麦克风处发出语音命令就能进行交互,节点不承担相关语音采集以及处理等计算资源的消耗。
考虑到采音设备的采音质量会对最后的识别率与准确识别的距离产生较大影响,此处我们选择使用麦克风阵列的模块提高采音质量。
2.2 ZigBee节点硬件设计
节点的电路图如图8所示,STC15F2K60S2单片机做为主控,外接一个光敏传感器,一个温湿度传感器DHT11,一个ZigBee通信模块与多个舵机等执行机构。

图8 ZigBee无线节点电路
其中,温度和湿度传感器都为数字式传感器,无需对获得的数据再做数模转换。
3 系统验证
3.1 识别率测试
因为本系统采用的云端语音识别引擎为百度语音,官方公布的平均正确识别率为97%,为了测试本系统的实际识别率,我们通过用手机录制特定命令,并以相同的音量播放,通过多次实地测试,得到图9所示的不同距离下的识别准确率。
由于识别准确率不仅受云端的影响,具体应用时还受到采音设备性能[15]的影响,本文中设计的交互系统采用的是麦克风阵列采集语音信息,由图9数据易知,本文中设计的系统在距离为3.5 m范围内,识别率在90%以上,在距离较近时,甚至接近官方公布的97%的准确率。

图9 不同距离的识别率曲线
3.2 基站与节点的通信距离
由下面表1易知,在两面墙的测试环境之下,节点之间的通信距离仍有20 m,由于节点之间是组网通信,模块会自动寻找最优的信号传输路径,在此通信距离之下,该系统适用于绝大多数的实际家居、办公场景。
4 结 论
文中以ARM作为基站主控,单片机作为节点主控,在嵌入式平台上实现了语音交互功能。
首先,借助云端语音识别引擎解决了传统嵌入式系统移植开发语音算法成本过高与识别率不高[15]的问题,并借助云端智能问答系统和语音转文字引擎实现了实时聊天对话的功能。
其次,应用ZigBee通信技术实现了语音信息、传感器信息、云端控制信息在各个节点间的传递与执行。本文设计的嵌入式无线交互系统可应用于家庭、医院、养老中心、餐厅、智能车载等场景。但是在实际验证系统时发现系统的声音采集设备还存在较大问题,拾音距离不够理想,后期的工作集中于寻找更好的远距离声音采集方案。
猜你喜欢
现代装饰(2020年5期)2020-05-30
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
电子制作(2017年8期)2017-06-05
探索科学(2017年4期)2017-05-04
丝路艺术(2017年5期)2017-04-17
初中生(2017年3期)2017-02-21
小学生优秀作文(趣味阅读)(2017年3期)2017-02-11
中国交通信息化(2016年2期)2016-06-06
