
柑桔病虫害自适用本体构建方法*
2018-12-15 01:41:58赵嫦花米春桥
吉首大学学报(自然科学版) 2018年5期
赵嫦花,米春桥
(1.怀化学院计算机科学与工程学院,湖南 怀化 418000;2.武陵山片区生态农业智能控制技术湖南省重点实验室,湖南 怀化 418000)
本体是概念的可视化,即标准化现实世界中抽象的概念,使概念与概念、概念与对象、对象与对象之间的关系更加清晰,从而实现知识重用和知识共享.本体引入计算机科学领域之后,国内外许多研究机构对基于叙词表的领域本体建构及相关问题进行了研究,目前已经开发了大量相对成熟的本体.[1]由于本体建构方法和应用领域的不同,这些本体在规模和复杂性上有一些差异.为了使提取出的关键字能反映文档主题,刘俊等[2]提出了一种新的词的主题特征(Topic Feature)计算方法,该方法利用主题模型中词和主题的分布情况计算词的主题特征和提取关键字;Vigneshwari S等[3]提出了一种使用基于多本体的散列法实现语义的社会信息检索技术.
支持本体推理规则和语义推理的工具有很多,如FACT,RACER,Jena[4]等.在本体中推理出病虫害及其相应的处理知识之间的关系后,可开发用于分析病虫害产生原因及其影响的智能软件.与其他的资源获取渠道相比,本体能提供详尽的病虫害相关信息[5],并帮助农民理解专家知识,使得不同的病虫害得到特定的防治方案,从而最低限度地减小损失.随着时间的推移,病虫会形成耐药性,动态更新病虫害知识库十分重要.笔者拟采用自适用本体构建方法设计一套本体知识库系统,并将其命名为CitrusPestOntoGenerator.该系统能从对柑桔病虫害的最新文字描述中提取关键字信息,并构建相应的本体库,也能帮助农业专家更新病虫害知识库,如加入新的病虫害种类、实例、症状、原因和补救措施等.
1 构建思路
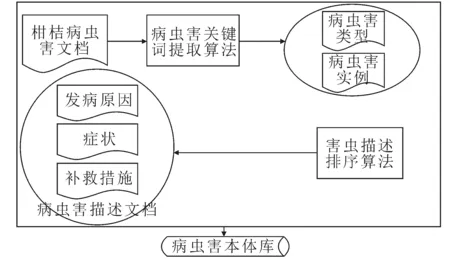
图1 CitrusPestOntoGenerator流程Fig. 1 Workflow of CitrusPestOntoGenerator
CitrusPestOntoGenerator的核心思想是动态构建本体库以支持柑桔病虫害管理.农业专家有很多与农作物病虫害管理相关的说明文件,这些文件一般都是文本格式,不能在自动化系统里直接使用,因此必须让这些文本具有与本体一样的结构.利用本体可以将柑桔病虫害文本进行层次结构划分,一旦构建好病虫害本体,文本就可以很容易地转化成任何语言.CitrusPestOntoGenerator的整体工作流程是如图1所示.
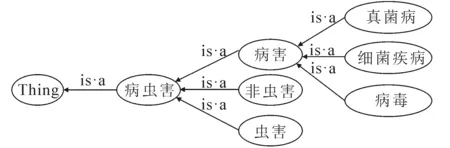
图2 CitrusPestOntoGenerator使用的本体库基础Fig. 2 Foundation Ontology Used by CitrusPestOntoGenerator
CitrusPestOntoGenerator系统为农业专家提供了基础本体(图2),笔者选择OWL作为构建本体的语言.由于OWL可以表征互联网的信息,因此一旦柑桔病虫害知识被存储为OWL文档,就可以使用网络访问,也可轻松应用于其他任何农业专家系统.柑桔病虫害基础本体中的基本类别分为虫害(Insetct Pests)、非虫害(Non-Insect Pests)和病害(Diseases),病害又包括真菌病(Fungal)、细菌疾病(Bacterial)和病毒(Viruses)3个子类.
2 病虫害关键字提取算法
为了添加更多类别的虫害实例和有害生物到本体库中,农业专家需要提供包含特定作物虫害细节的文本语料库.通过友好的用户界面,农业专家可以在文本语料库中添加或删除文本描述.从所有柑桔病虫害语料库中提取关键字时,首先逐个读取文件,并应用关键字提取步骤收集所有关键字[6-7],然后删除重复的关键字,提供最终更新的虫害本体关键字列表.柑桔病虫害关键字提取算法的具体流程如下所示:
输入:柑桔病虫害描述文件
输出:相关关键字
Begin
从文件中提取文本
While
切分文本
去除停用词
通过应用OpenNLP POS标签和保留POS
标签来提取名词和专有名词
对所有关键字进行排序
将关键字与AGROVOC词库进行比较,去
除无关的关键字
EndWhile
移除重复关键字
将列表分为2个列表,一个为名词,另一个为专
有名词
End
使用由Java提供的StringTokenizer来提取和分割与柑桔病虫害有关的文件.文档中的停用词若对本体构建无用,则先标记出来,再将这些字词从标记集合中删除.关键字是否为停用词通过使用频率来确定,若使用频率小于3,则判定其为停用词,并将停用词从列表中删除.剩下的关键字将通过英文分词算法被还原成英文单词原型,如将planted还原成plant.病虫害类以owl:class表示并保存在病虫害本体中,它的实例以owl:individual表示.本体中的类(Class)和实例(Individual)通常是语句中的名词和专有名词,笔者利用这个特性,使用openNLP POS标签来提取名词和专有名词.
关键字提取是对关键字进行排序且只保留排名靠前的关键字,这是通过使用TFIDF算法实现的[6].TFIDF值包括词频(Term Frequency,TF)和逆向文件频率(Inverse Document Frequency,IDF)两部分,TF表示词条在文档中出现的频率,IDF是一个词语普遍重要性的度量.某一特定词语的IDF可以由总文件数目除以包含该词语的文件数目,再对得到的商取对数.这里每个关键字在具体病虫害文件中的都要计算出来,然后按逆序频率删除关键字.关键字的TFIDF值词频和逆向文件频率,列表根据TFIDF值进行排序.在CitrusPestOntoGenerator中,笔者对每个文件提取了大约100个关键字.
3 算法实现
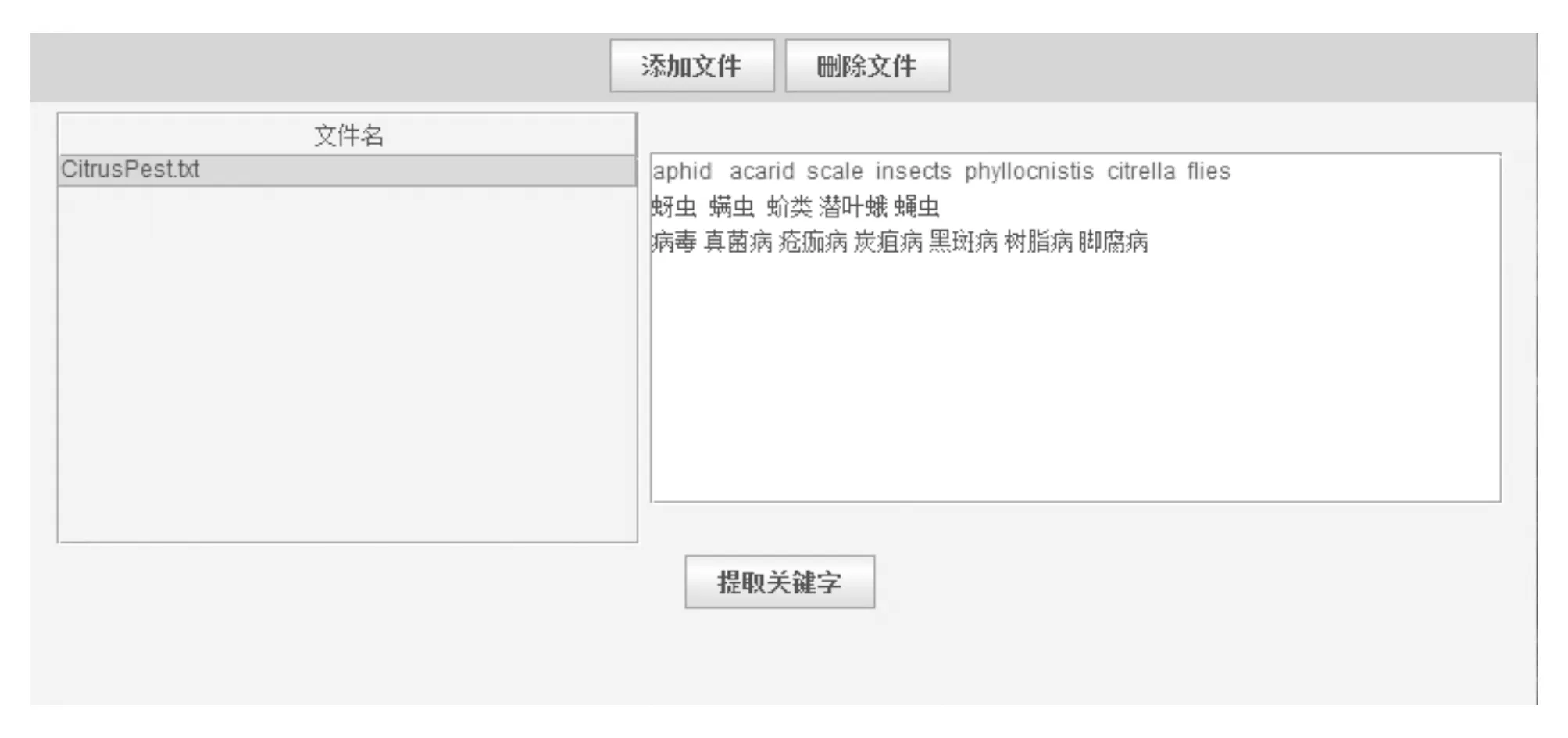
图3 提取柑桔病虫害关键字的界面Fig. 3 Keywords Extraction
为了找到关键字与农业领域的相关性,笔者寻找存在于农业多语种叙词表(AGROVOC)中的关键字,那些AGROVOC中不存在的关键字将从关键字列表中删除.所有这些步骤都是重复读取柑桔种植业专家提供的文件,再将从这些文件中收集到的关键字放在一起,最后准备2个关键字列表,一个是名词,另一个是专有名词.列表中的词将按照类和实例添加到新的病虫害本体中.提取柑桔病虫害关键字的界面如图3所示.
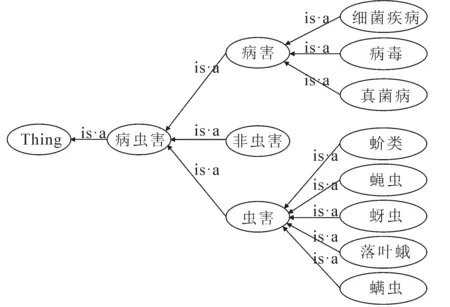
图4 CitrusPestOntoGenerator对基础本体库的扩展Fig. 4 Extending of Foundation Ontology Through CitrusPestOntoGenerator
找到关键字后,农业专家首先删除无用的关键字,然后按照前面收集的关键字类和实例添加新的虫害类型、虫害实例和虫害属性,以此更新基础病虫害本体库.CitrusPestOntoGenerator对基础本体库的扩展如图4所示.从图4中可以看出,本体库增加了虫害的子类,分别为蚜虫(Aphid)、螨虫(Acarid)、蚧类(Scale Insects)、潜叶蛾(Phyllocnistis Citrella)和蝇虫(Flies).
系统提取的关键字不仅可以添加到柑桔病虫害本体中,而且可以添加到专家自己的知识库中.这些关键字被保存到单独的关键字本体中,它将随着柑桔病虫害本体的更新而动态更新,也会和AGROVOC进行比较扩展.这使得系统具有健壮性,有助于提高关键字提取的精度.为了将信息存储为OWL文档,使用斯坦福大学基于Java语言开发的本体开发环境Protégé5.0,在Protégé中可以添加或删除类、方法、实例、数据属性和对象属性等.笔者将虫害类型存储为OWL类,实例存储为OWL个体,将症状、原因和补救措施存储为OWL个体的数据属性,并将其设置为字符格式.
4 实验结果
采用柑桔病虫害关键字提取算法对100个柑桔病虫害文档进行关键字提取,并将其中8个样本的提取结果进行关键字分类,结果如表1所示.
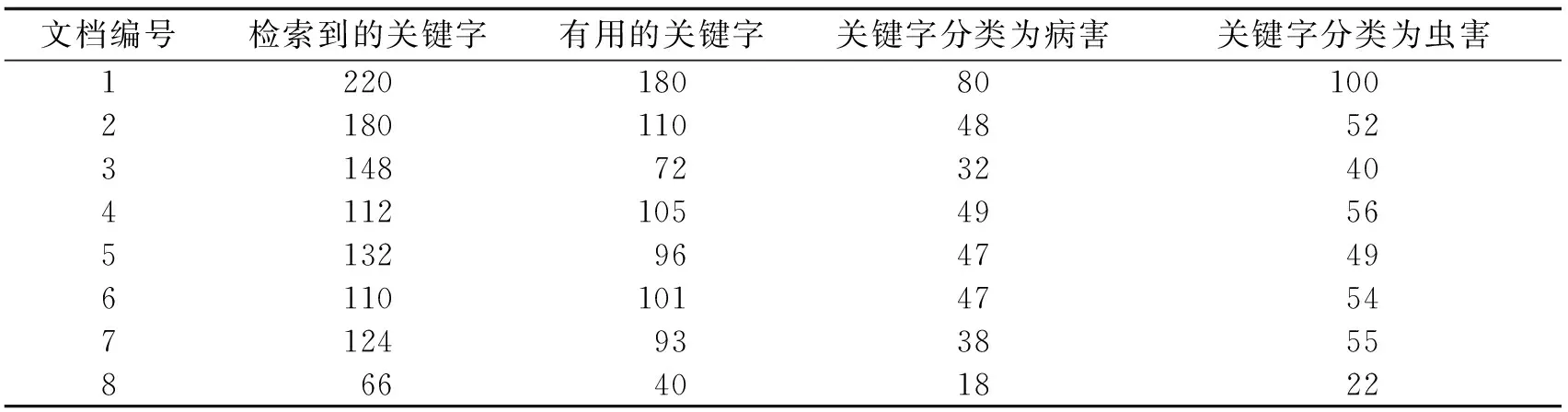
表1 8个样本的柑桔病虫害关键字提取分类
由表1中的数据,可计算得到CitrusPestOntoGenerator系统关键字的平均提取准确率为73%.使用CitrusPestOntoGenerator系统生成100个本体,检索来自每个文档的100个关键字并记录其中有用的关键字,实验结果表明该自适应算法有助于有用的关键字的提取.
5 结语
本体在语义网中扮演着重要的角色,它能很好地表示异构数据,柑桔病虫害本体的构建能很好地为农民解决问题.CitrusPestOntoGenerator系统使用自然语言处理技术,协助农业专家为柑桔病虫害分级,并确定它的类型和实例.在使用CitrusPestOntoGenerator系统时,农业专家不需要理解本体,只需确认从文本中提取出来的病虫害类型、实例、症状、原因及补救措施即可.CitrusPestOntoGenerator系统利用NLP技术和OWL表征知识的强大能力,将专家知识转化为结构化格式,并以各种方式向农民提供信息.
猜你喜欢
小学生学习指导(高年级)(2024年4期)2024-05-07 03:28:46
华人时刊(2022年1期)2022-04-26 13:39:28
小学生学习指导(中年级)(2021年4期)2021-04-27 10:14:56
课堂内外(初中版)(2020年5期)2020-06-19 08:11:11
动漫界·幼教365(大班)(2019年10期)2019-10-28 01:54:09
现代园艺(2018年1期)2018-03-15 07:56:20
现代园艺(2018年3期)2018-02-10 05:18:39
现代园艺(2018年3期)2018-02-10 05:18:22
现代园艺(2018年3期)2018-02-10 05:18:14
华东师范大学学报(自然科学版)(2014年3期)2014-03-11 16:18:15
