
基于FLTK多种编码字体的量宽式分行显示研究
2018-12-13 09:08饶天贵胡士杰
计算机应用与软件 2018年12期
李 凯 饶天贵 胡士杰 曾 升
1(株洲中车时代电气股份有限公司轨道交通技术中心 湖南 株洲 412001)2(株洲中车时代电气股份有限公司数据与智能技术中心 湖南 株洲 412001)
0 引 言
目前基于Linux系统的FLTK工具广泛应用于国内外机车、地铁等车辆显示器UI软件开发。FLTK为Linux系统下轻量级的图形数据开发库[1],开发的UI软件具有占用系统资源少、协议兼容性强、运行稳定可靠、可配置等优点[2],所以目前在轨道交通领域使用广泛。跟随智能化的发展方向,显示器不仅要能实时显示车辆的基本信息,还要实时播报和记录车辆发生的故障情况,并且能向司机和维护人员给出每条故障可能发生的原因和处理措施。通常这类信息描述的文字很多,而每个界面中FLTK控件宽度有限,且显示的文字不能自动换行,再加上不等宽字体每个字符所占的像素大小不同[3],普通的分行方法会导致每行文字显示参差不齐,影响界面美观。较好的折行显示算法尤为重要,因此为了解决FLTK控件不能自动分行显示文字的问题,并针对不等宽字体,提出了一种兼容多种编码方式的自适应分行显示方法。
1 传统分行显示方法
1.1 固定字符数分行显示方法
将文本文件中的每条信息按固定字节数进行分割,然后分别在各控件中显示,是固定字符数分行显示的主要处理思路,如图1所示。根据FLTK控件宽度,通过测试,可以找到分行的固定字符数值,可以保证固定宽度的控件能完整显示文字,但对于不等宽字体,比如汉字、数字、标点符号、英文等所占像素宽度并不相同,会使得相同字符数的不同文字显示得参差不齐,严重影响了界面的美观。

图1 固定字符数分行处理方法
1.2 插入标签分行显示方法
该方法的处理思路是在文本文件中的每条信息适当位置上插入特定的字符,然后根据这些标签进行分割,最后分别在各控件中进行显示,如图2所示。根据FLTK控件宽度,通过多次测试,在要显示的文本串中插入特殊的分行符来进行差别化分行处理可以解决每行显示参差不齐的问题,但是对于上千条的信息,一一测试并在每条信息中插入分行符,工作量极大,效率极低,会严重影响项目交付进度。
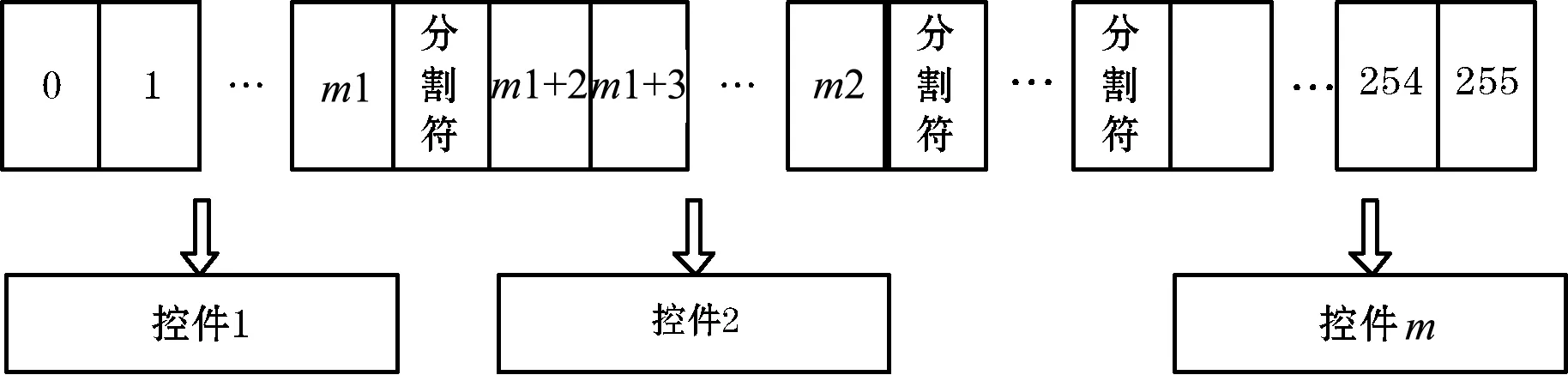
图2 插入标签分行处理方法
1.3 其他分行处理方法
文献[3]给出了针对不等宽字体分行处理的基本思路,但是只针对GB2312编码、ASCII编码字体的分行处理方法,分行处的英文单词未做分行处理,而是直接将整个单词另起一行,这样可能会导致每行显示参差不齐,影响显示效果。文献[4]在Android平台中设计了一种扩展的文本显示控件,可以实现对不等宽字体的分行处理,同样在兼容文字的多编码方式、英文分行处理上并未作相关处理。
2 分行显示方法设计
2.1 整体设计思路
该方法是针对单个FLTK控件无法显示大量文字(包含中英文、符号等)而作出的一种处理方法。是将预显示的文字串分割成多个文字片段,再用多个相同的控件来显示,从而达到分行显示的效果。整体的文字串分割思路如图3所示。

图3 字符串分割再分行的处理思路
目前常用的字体,包括点阵字体和矢量字体,基本都是不等宽字体。不等宽字体的汉字、字母、标点符号等在控件中显示所占的像素宽度并不相等,使得相同宽度的控件能显示的字符总数不同,所以分配给每个控件显示的字符数需要灵活调整,即图3中每个虚线框所分割字符串并不相同。
2.2 针对多种编码的分割处理机制
2.2.1 基于GB2312编码的处理机制
基于常用的GB2312编码的分割处理机制,根据分割处字符所属文字类型的不同,可分为两种情况,如图4所示。如果分割处是汉字,根据GB2312编码规则,每个汉字占用2个字节[5],则需回跳2个字节字后截断字符串;如果分割处是字母、数字或者普通符号,根据GB2312编码规则,只占用1个字节[5],只需回跳1个字节字后截断字符串。

图4 基于GB2312编码的分割处理机制
2.2.2 基于UTF-8编码的处理机制
UTF-8编码是变长字节编码[6-7],汉字、字母、数字、符号等所占字节数不相同,不正确的编码解析易导致乱码显示[8-9],使得字符串分割处的情况变得相对复杂,如图5所示。
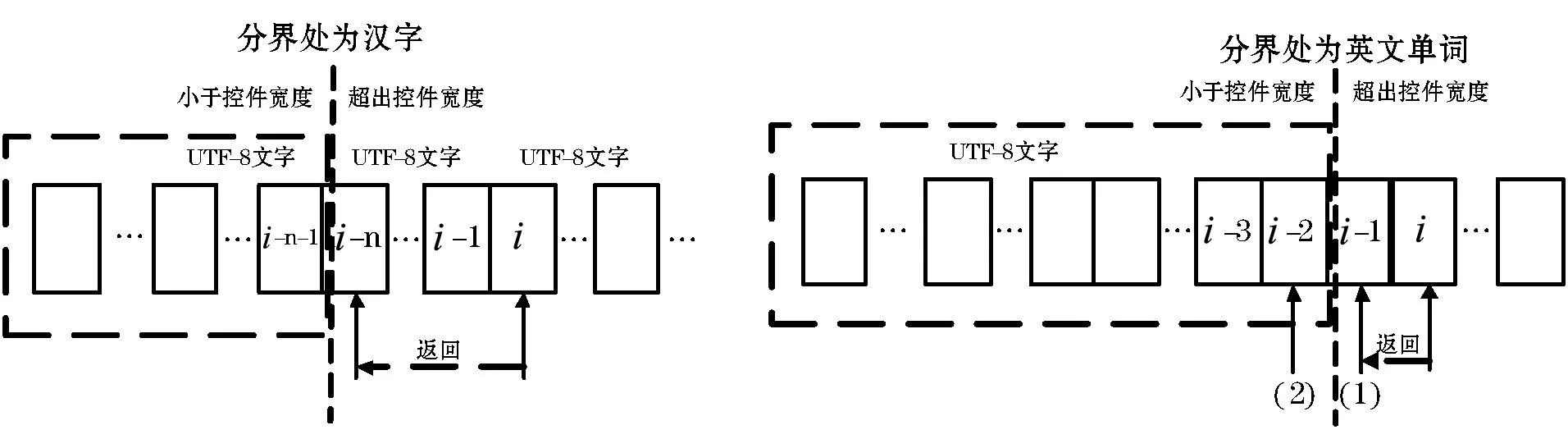
图5 基于UTF-8编码的分割处理机制
1) 当分割处是汉字时,获取的该段字符数减n(n为分割处汉字所占字节数,1≤n≤6);
2) 当分割处是字母/字符时,分两种情况:(1) 一般情况下获取的该段字符数为能正常显示的字符数减1。(2) 对于英语单词的截断换行,需考虑在行末添加短横线,这样获取的该段字符数需减2;对于该行最后一个字符为单词首字母的情况,需将该字母移划分到下一个字段中,同时添加空格字符,这样获取的该段字符数也需减2。
2.3 软件实现流程
具体实现的流程图如图6所示。
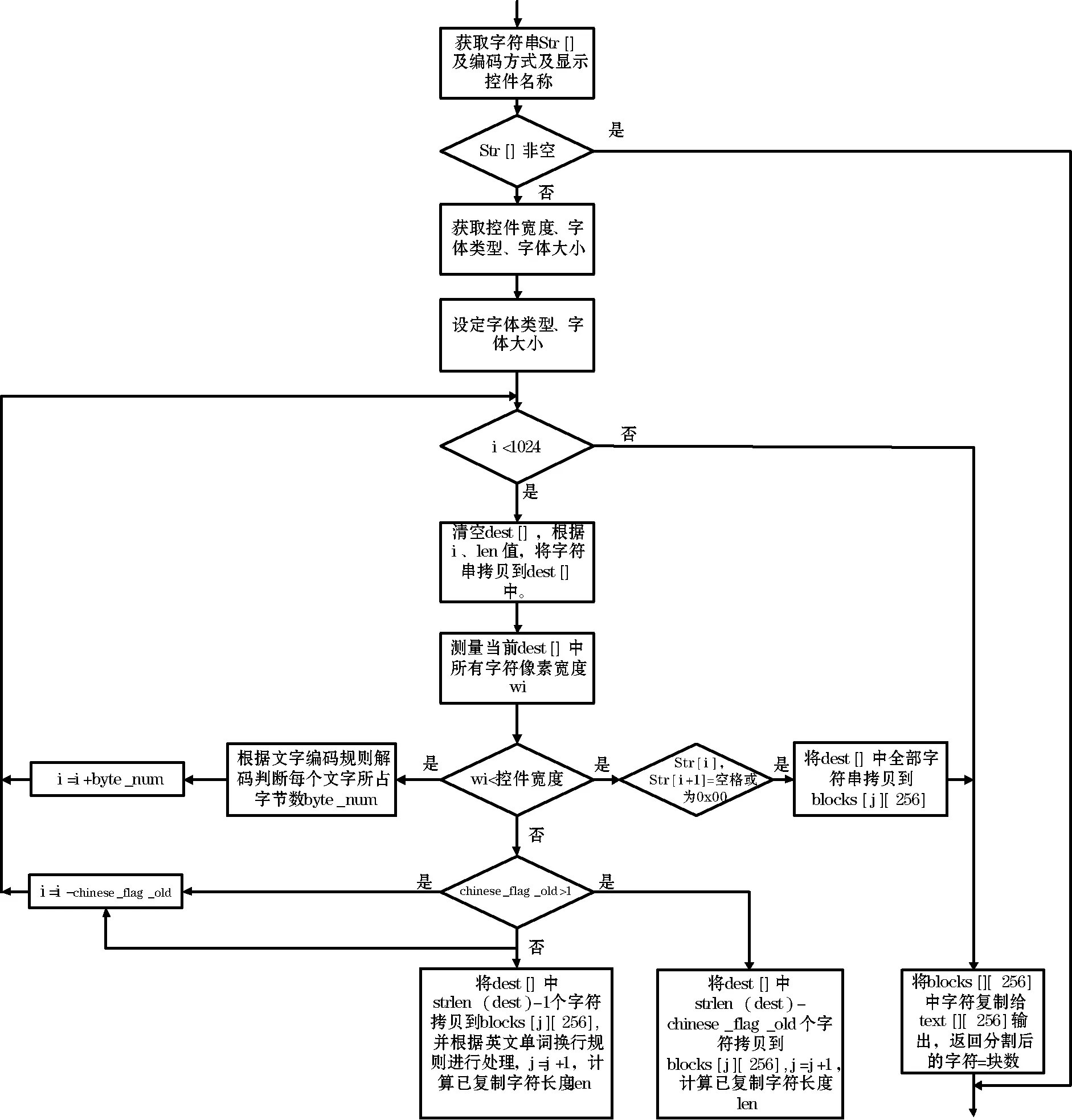
图6 基于FLTK的字符分割处理流程
字符分割处理流程如下:
1) 判断预分割处理的字符串str[]是否为空,若为空,则退出,否则向下执行。
2) 通过FLTK函数库中的函数,分别测量出显示字符的控件宽度widge_width、字体类型font_index、字体大小font_size参数。
3) 通过FLTK函数库中的函数,以及步骤2测量的字体类型font_index、字体大小font_size参数来标定测量属性,这样后续测量的字符串所占像素宽度才是正确的。
4) 设字符串str[]的下标为i,分段数为j,已拷贝至blocks[j][256]的字符总数为len。如果i<1 024,根据i、len值将下标为len至i-len+1(不包含)间字符拷贝至用于临时存取本次截取的片段的数组dest[]中。
5) 使用TLFK函数库中函数测量当前dest[]中所有字符所占像素值wi。
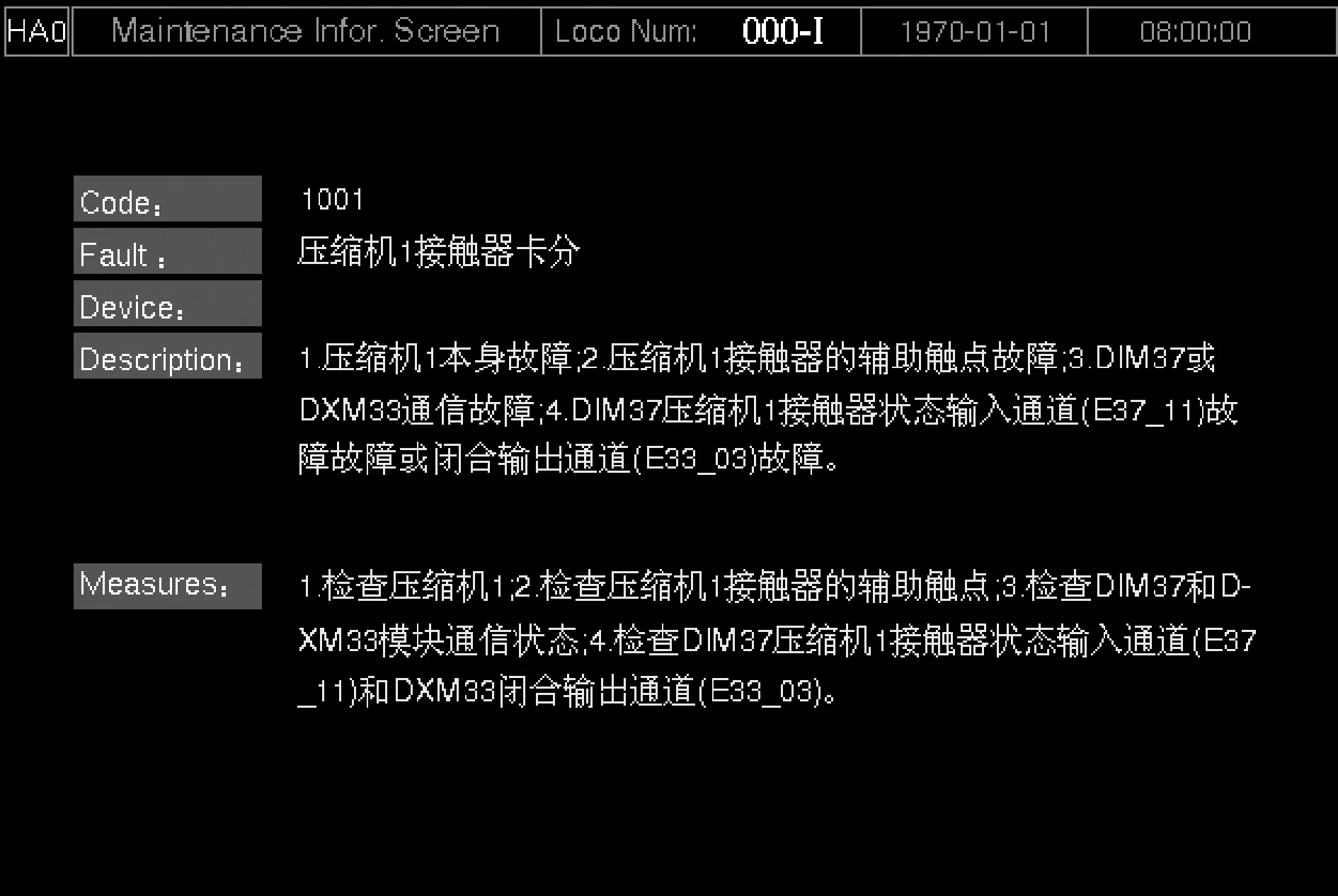
6) 比较wi与widge_width,若wi 7) 如果汉字标志chinese_flag大于1,i=i-chinese_flag_old,同时将dest[]中前strlen(dest)- chinese_flag_old-1个字符拷贝至blocks[j][256]中,len=len+strlen(char_blocks[j]),j=j+1,返回至步骤4,否则,执行步骤8。 8) 如果汉字标志chinese_flag小于等于1,i=i-1,如果同时dest[i-len-1]为字母,dest[i-len]不为“,”、“.”或空格,则dest[i-len]变换为“-”,len=len-1,即解决单词分割后,前半部分结尾处添加短横线的问题。如果汉字标志chinese_flag=0,同时dest[i-len]为字母,dest[i-len-1]为“,” 或“.”或空格,则dest[i-len]变换为空格,len=len-1,即解决分割的单词前半部分仅有一个字母的显示的问题。将dest[]中前strlen(dest)-1个字符拷贝至blocks[j][ 256]中,j=j+1,len=len+strlen(char_blocks[j]),返回至步骤4。 以上介绍了该方法的整体思路、处理机制、具体实现流程。 为了证明本文提出的文本分行显示算法在FLTK控件上实现的优异性,与目前应用较多的分行方法在文本编辑格式和显示效果上进行了比较。 固定字符数分行方法对文本格式举例如下(左右两项内容各固定分四行): 1001:1.X出现故障原因1;:1.请检查X1;. 1001:2.X出现故障原因2;:2.请检查X2;. 1001:3.X出现故障原因3;:3.请检查X3;. 1001:4.X出现故障原因4。:4.请检查X4。. 该方法需预先确定分行数目以及固定分行的字节数,文本编辑时需严格确保分行字符对齐。使用该方法的显示效果如图7所示,从图中可明显看到相同字符数分行有时会因为不等宽字体的差异导致行末参差不齐,影响美观。 图7 固定字符数分行显示方法的显示效果 文本中手动插入标签分行方法的文本编辑格式如下: 1001:1.X出现故障原因1;:2.X出现故障原因2;:3.X出现故障原因3;:4.X出现故障原因4。: 1001:X故障导致的结果1;:X故障导致的结果2。: 1001:司机对应的处理措施。: 1001:维护人员对应的处理措施。: 该方法需根据控件实际显示情况调整分行符标签位置,这样使得每条信息文本分行位置并不固定。该方法分行显示效果较好,但对文本编辑的工作量太大,如图8所示。 图8 文本中手动插入标签分行方法的显示效果 本文提出的新方法对文本编辑格式要求如下: 1001:1.X出现故障原因1;2.X出现故障原因2;3.X出现故障原因3;4.X出现故障原因4。: 1001:处理措施1;处理措施2;处理措施3。: 从文本格式可以看出,只需要将每条文本信息单独在一行列出,无需添加任何分行标签或其他处理,明显降低了对文本格式的要求。量宽式的文本分行显示方法不仅大大减少了文本编辑工作量,而且在显示效果上也保持了较高的质量,行末文字参差不齐的现象基本解决,同时也具备对英文单词换行处理的能力,如图9所示。同时,该方法兼容多种文本编码格式,在减少乱码显示方面,也具备较强的能力。 图9 量宽式分行方法的显示效果 通过对比分析,本文提出的新的量宽式分行显示方法,在有效降低文本编辑工作量和提高文本分行显示效果上,均得到了提高。 目前,该方法已在出口埃塞俄比亚电力机车等项目上进行了应用。 根据控件的像素宽度、字体类型、字体大小属性来对预显示的字符串进行自适应分割处理再分行显示的方法,不仅可以充分利用控件宽度大小来进行文字显示,而且不会出现文字的漏显问题,保证了文字显示的正确性、美观性。因为该方法只需要获取控件名称,就会自动获取其基本属性,并对需要显示的文字串进行自适应分割处理,使得对文本格式的要求降低,大大减少了对文本的处理时间;该方法还解决了每行显示参差不齐的问题,较好地保证了文本显示的美观性。该方法在对待编号分行处理上的能力还有待提高,这也是今后需要进一步研究的方向。3 实现效果与应用法


4 结 语
猜你喜欢
电脑爱好者(2021年21期)2021-11-04
中文信息(2020年10期)2020-11-30
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
软件(2018年7期)2018-08-13
普洱(2015年7期)2015-11-29
小雪花·成长指南(2014年10期)2014-10-31
移动一族(2009年3期)2009-05-12
