
基于数据用语智能分词技术的数据关联方法
2018-12-12 19:31张新阳张梅马文程永新
科技传播 2018年22期
关键词:数据治理
张新阳 张梅 马文 程永新
摘 要 当前数据资产梳理以及数据标准建立过程中,对其中所遇到的数据命名不统一、中文语义复杂、难以建立数据关联等难点问题进行分析,提出了一套基于中文智能分词及大数据字符串分析技术的数据用语标准建立方法以及建立数据关联的方法。通过将该方法应用的数据资产管理项目中,实现了对某企业45套业务系统,10万多张表、70余万数据字段以及数百个业务接口的全自动梳理,建立了跨业务系统的数据标准体系和数据关联地图,为企业的数据资产进一步分析、挖掘、变现提供了有利支撑。
关键词 数据治理;数据关联;智能分词;数据标准
中图分类号 TP3 文献标识码 A 文章编号 1674-6708(2018)223-0121-03
随着IT技术的发展,未来10年内,数据将成为一个重要的财富创造来源,并且将越来越多地被视为一项值得重视的企业资产,数据资产日益成为企业的重要利润潜力增长点。为此,各企业急需梳理沉淀十数年以来各业务系统的数据,希望从中整理出属于数据资产的有价值数据,并面向数据应用建立起相应的数据模型,为大数据平台的数据分析和数据挖掘提供支撑服务,麦肯锡认为“大数据是指其大小超出典型数据软件抓取、储存、管理和分析范围的数据集合”。在创建和应用大数据的这个过程中,以下这些问题尤为凸显,成为数据资产梳理的难点。
1)企业内各业务平台系统建设跨越时间长,系统复杂,且由多个项目实施建成。IT系统的建设目标以实现业务需求为首要目标,未考虑后期的数据集成需要。因此各业务平台系统中存在对同一个业务术语的不同定义形式,造成跨系统的数据难以建立关联,甚至同一业务系统中都存在对相同业务术语的不同定义。
2)虽然企业已经开始对数据标准体系做建设,但是针对既有业务系统,出于经济考虑,不可能做大面积的重构处理,只能对新上线系统做规范化要求。而大量的对企业有重要价值的数据资产是沉淀在原有业务系统中的,如何将数据标准与现有系统中的数据做关联成为一个难点问题。
3)中文语言的博大精深,一方面丰富了人们的语言表达,但也因此存在大量的近似用语。不同环境背景下的语言和组词均有差异,这也是造成制订数据标准困难的主要原因,难以形成一套适应所有环境的统一数据标准体系。
以上问题在建立企业内部或跨行业的数据标准体系并盘活现有企业数据资产时成为数据管理者所面临的难点,如何建立不同业务系统,甚至不同行业之间的数据标准体系,并将数据标准应用到既有系统,成为建立跨系统的数据集成平台所需跨越的鸿沟。
1 正文
本文基于中文的智能分词技术,论述一种基于数据标准用语智能分词的跨系统数据关联梳理方法,并说明应用此方法的梳理展现效果。
1.1 梳理数据用语字典
数据梳理的第一步是建立起企業内或行业内业务术语的数据用语字典。数据用语字典包括数据库中的表名用语、字段名用语、系统的接口用语、报表中的指标用语等。用语的来源可以是系统建设时的需求规范、设计规范、接口规范等文档,也可以从现有系统的表结构逆向采集获取。用语字典的形式可以用如下形式体现,如图1。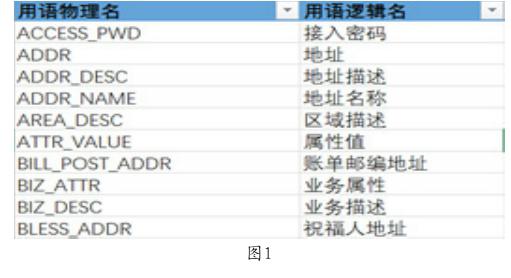
用语物理名是用语在数据库字段或数据库表命名时的体现,而用语逻辑名是具备某个特定业务术语描述的中文体现。
这个数据用语字典,将是我们要作为跨系统数据关联的数据基础。
1.2 建立数据用语单词库
对于已建立的数据用语字典,其用语的定义是面向某个具体的业务术语的描述,其中包含了一个或多个中文词语。
通过智能分词技术,可以实现将用语自动拆分为多个词语的组合。例如“年收入额”可以拆分为“年”和“收入”“额”三个有具体涵义的字或词语,拆解出的词语或字,可以命名为词素或单词。
收集整理拆分出的单词或词素,可以得到一个涵盖行业或者企业所有业务系统的用语单词库。其展现形式如图3。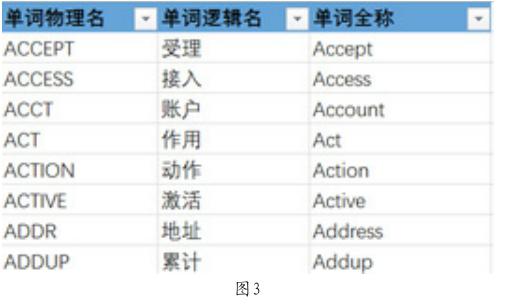
单词物理名为一个词语在业务系统中使用时的名称,用语数据库表、字段、接口、接口属性、口径等定义使用。单词逻辑名作为一个词语的中文名称,用语面向用户的可视化涵义展现,单词全称作为中文名称的英文全名备注。
1.3 建立单词同义词库
建立上述步骤的用语单词库后,分析发现对于每个词语在语言使用都可以存在多个同义词或近义词,又或者同一个单词的逻辑名存在多个不同的单词物理名的情况。在不同的业务系统中,由于系统设计开发人员的习惯不同,造成其使用的名称不一致。例如“额”这一业务术语,在某些业务系统中可能会命名为“金额”,“管理员”这一词语,在另一系统中也可能定义为“管理者”,而同一个单词“区域”,有些系统会命名其物理名为“AREA”,而另一些系统可能会命名为“ZONE”或“REGION”。这些都会造成不同的系统的使用人员或数据分析人员在数据集成时数据无法直接建立关联。
实现不同系统之间能对具有同样含义的词语建立起关联,需要将每个词语可能存在的同义词或近义词进行整理。这一步骤可以借助于行业专业词典以及同义词典等工具书籍的电子版本,通过大数据分析技术获取单词库中各单词的同义词列表。如图4的物理名同义词列表。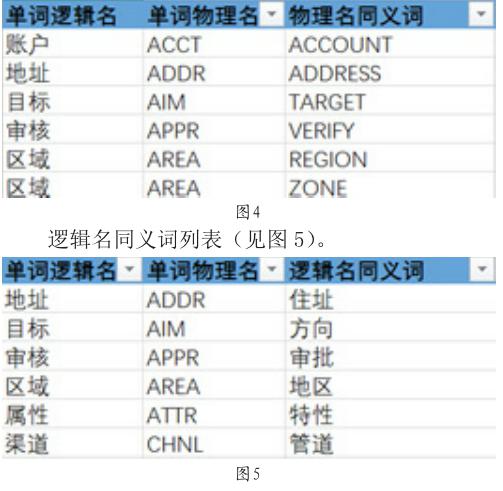
1.4 推举数据标准单词
当一个业务在各业务系统中或行业中有规范做数据标准定义时,可以将行业规范作为数据标准的来源。但目前有很多行业或企业并无统一规范的数据标准定义,而各业务系统也在各自的专属功能领域运行上10年之久,如何形成一套符合绝大多数人习惯的标准术语描述则成为一大难点。
基于前面所述的数据用语单词库以及单词同义词库,可以建立起在用语单词中的同义词关联关系。当一个单词具有多各同义词时,通过检索这个单词及同义词在所有业务系统中的用语使用次数,获取应用得最多的一个词语,并将此词语作为暂定数据标准单词,而具有同义词含义的其他单词则作为此数据标准单词的同义词。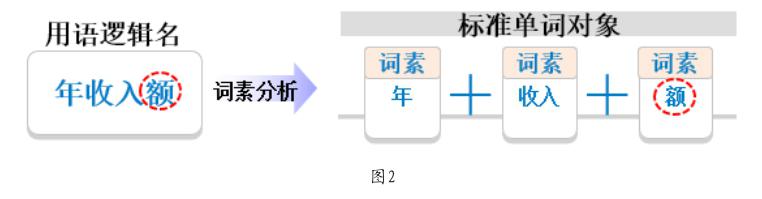
1.5 建立数据标准用语档案库
数据标准单词确定后,可以将前面梳理出的系统中使用的用语字典做标准化处理。将用语智能分词为单词,对每个单词获取其标准化单词后,重新组装为符合数据标准定义的用语,其过程如图6所示。
1.6 建立数据关联
通过建立数据标准用语档案库,也可以得到每個用语与数据标准用语之间的对应关系。当存在多个系统中的不同用语对应同一个数据标准用语时,可以认定这两个用语不管是不是在同一个业务系统中,其数据应具备相关性,具备数据关联分析及进一步关联数据挖掘使用的价值。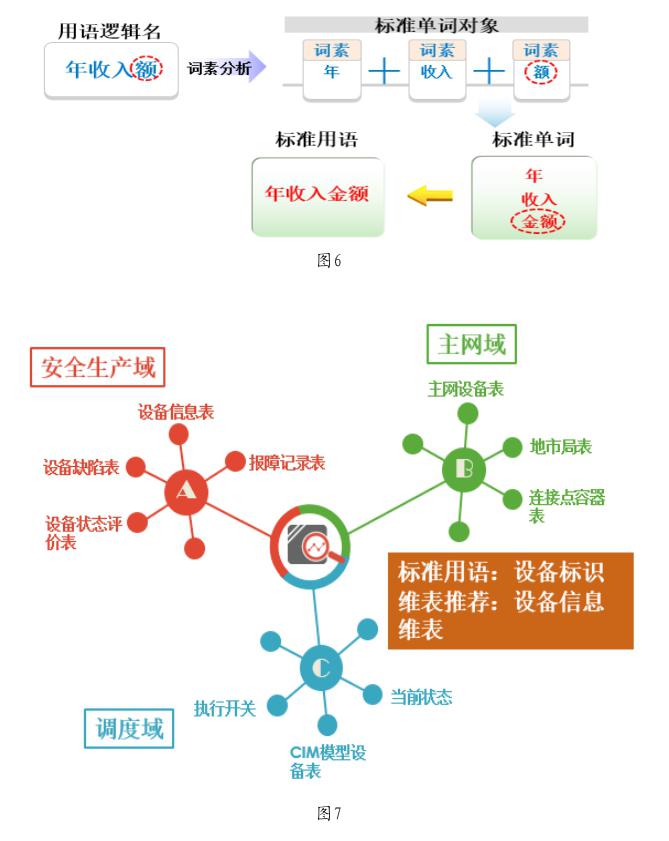
2 结论
随着电力业务集约化、精益化、标准化的要求越来越高和信息化支撑能力的不断提升,数据治理已成为电力企业信息系统集中建设(一级部署)、大数据应用、智能分析决策应用的重要基石。企业在进行跨业务系统数据梳理时,面对大量沉淀数据往往不知如何下手,各数据的命名规范性问题作为长期影响企业进一步挖掘数据价值的拦路虎存在,本文应用当前已经成熟的大数据字符串处理技术以及中文智能分词技术,将系统中原本需要靠繁重的人工识别的数据关联,赋予系统自动化处理的能力,能够大幅提升数据资产梳理的效率,减少人工成本,为挖掘各业务系统中的健在数据资产价值提供有力的帮助。
参考文献
[1]张志刚,杨栋枢,吴红霞.数据资产价值评估模型研究与应用[J].现在电子技术,2015,38(20):44-51.
[2]Gartner.Top ten strategic technology trend for 2012[EB/OL].[2011-11-05].http://www.gartner.com.
[3]巨克真,魏珍珍.电力企业级数据治理体系的研究[J].电力信息与通信技术,2014,12(1):7-11.
[4]成于,思施云涛.面向专业领域的中文分词方法[J].计算机工程与应用,2018,54(17):30-34,109.
[5]张生,杰霍丹.基于语义信息的中文分词研究[J].电脑知识与技术,2018,14(22):184-186.
猜你喜欢
科技创新导报(2017年16期)2017-08-23
中国教育信息化·高教职教(2017年7期)2017-07-25
山东工业技术(2017年14期)2017-07-18
中国教育信息化·高教职教(2017年5期)2017-05-18
图书与情报(2016年6期)2017-04-17
中国教育信息化·高教职教(2016年12期)2017-04-15
电脑知识与技术(2017年3期)2017-03-27
科技创新导报(2017年1期)2017-03-21
科技与创新(2016年9期)2016-05-28
湖南师范大学社会科学学报(2015年5期)2015-09-25
