
基于多分类支持向量机的相控阵雷达T/R组件寿命分布仿真识别
2018-12-04 06:18蒋伟,王挺,盛文,鲁力
兵器装备工程学报 2018年11期
蒋 伟,王 挺,盛 文,鲁 力
(空军预警学院 防空预警装备系, 武汉 430019)
T/R组件作为相控阵雷达的重要组成部分,主要担负通过雷达天线向外辐射能量,并接收目标的回波信号,同时依靠环行器、移相器、衰减器等辅助电路实现发射信号和接收信号在空中合成的作用[1-3],随着T/R组件的集成度越来越高,其故障率也随之增长。相控阵雷达T/R组件数量庞大,少则几百,多则上千上万。
相控阵雷达T/R组件的结构比较复杂,对使用条件的要求也非常高,因此对后续的使用保障和维修工作提出了更高的要求。为了对后续的使用保障提供理论依据,需要对T/R组件的可靠性进行分析研究,得到T/R组件运行时间和可靠度之间的关系。在可靠性分析中,寿命分布建模是一种常用的数学方法[4],目前在判断一组可靠性数据的分布类型方面,主要有以下几种方法:1.最小误差法[5],即选取几个通常可能的分布类型,然后用可靠性数据分别进行拟合,当中误差最小的就是所求的分布类型;2.图形法[6],即将可靠性数据映射到图形中,若该数据与某一特定分布数据图形相一致,则该分布为所求的分布类型;3.智能识别方法,当前寿命分布的智能识别算法很多,比如文献[7]提出一种智能复合结构,能够对常见的几种寿命分布进行识别,且识别率达到90%以上;文献[8]提出了一种基于最大隶属优势准则的变量汞寿命分布识别方法,具有较高的可信度;文献[9]利用BP神经网络对可靠性数据进行寿命分布识别,文献[10]利用经典分布拟合法、最大熵值法、多项式逼近法和正态信息扩散法对岩土参数的概率分布进行推断,但上述方法中,最小误差法和图形法可能出现有多个分布同时满足要求的情况和BP神经网络收敛速度慢等问题。因此本文首先根据可靠性数据的特点,对其样本的峰度、偏度、累积概率、分位数等特征进行提取,然后利用核主成分分析法对数据特征进行降维,并构造了可靠性数据概率分布特征的训练样本,最后运用多分类支持向量机模型对数据的概率分布进行模式识别。
1 T/R组件寿命分布数据特征及分布模式选取
根据寿命分布数据的特点可知,其统计特征主要包括:极差、标准偏差、变异系数、算数平均值、中位数、众数、峰度、偏度、累积概率。在对T/R组件寿命分布样本进行构建时,根据文献[9]以及通过反复研究试验,结果表明当选取峰度、偏度、变异系数、累积概率、中位数作为样本的主要特征进行提取时,能够得到更好的分类效果,因此本文选取峰度、偏度、变异系数、累积概率、中位数作为数据样本的特征。
在对T/R组件寿命分布数据进行识别时,首先要对其可能的分布模式进行选取,根据T/R组件所属的器件类型为电子器件,且根据工程实际情况,选取指数分布、正态分布、威布尔分布、对数正态分布四种分布类型为可能的分布模式类别。
2 核主成分降维分析方法
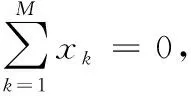
1) 从可靠性数据中获取数据特征信息,将其表示为m×n矩阵,其中m为样本组数,n为特征属性个数。
(1)
2) 选取合适的核函数,并计算核矩阵K,本文在建模时选取径向基(RBF)核函数:
(2)
式中:xi,xj为输入空间的样本,δ1为核参数。
3) 对核矩阵K进行修正,得到矩阵Kp,计算矩阵Kp的特征值V和特征向量D。
4) 将特征值按降序排列,同时调整对应的特征向量。
5) 计算特征值的累积贡献率Rc,并给定最小提取阈值,提取t个主元分量α1,α2,…,αt。
6) 计算在提取的特征向量上的投影,Y=Kp·α,其中α=α1,α2,…,αt,Y即为所得的降维后的数据。
3 支持向量机模型构建
支持向量机在解决小样本、非线性及高维模式识别中表现出许多特有的优势[14-16]。
3.1 传统二分类支持向量机
二分类支持向量机的基本思想为:首先通过非线性变换将输入变量空间映射到一个高维空间,然后在这个高维空间中求取最优线性分类面,最优分类线的选取原则为不但能将两种类别无错误分类,而且要使两种类别的分类间隙最大,最优分类线如图1所示。
图1中,○和▲分别为两类样本,H为把两类样本无错误分开的最优分类线,H1和H2分别为经过各类样本且离最优分类线最近的平行于最优分类线的直线,H1和H2之间的距离称为分类间隙,将图1推广到高维度空间,最优分类线就变为最优分类面。
3.2 多分类支持向量机
支持向量机其实为一个二类分类器,但为了能够实现对多种类型进行分类,主要方法就是训练多个二分类器,当前多分类实现方式主要有以下两种方法:1).一对多,即对于给定的m个类别,需要训练m个分类器,其中分类器i是将i类数据设置为类1(正类),其他所有m-1个i类以外的类共同设置为类2(负类),因此对于每一类都要训练一个二分类器,最后总共需要m个二分类器。对于一个即将要进行分类的数据X,用分类器i对数据进行分类,如果获得的是正类结果,就说明数据X属于i类,如果获得的是负类结果,则说明数据X不属于i类,如此反复最终得到数据X的类别属性。2).多对多,即对于给定的m个类别,对m个类别中的每两个类都训练一个分类器,总共二分类器的个数为m(m-1)/2。对于数据X,它需要经过所有分类器的识别,最终确定所属的类别,该方法与“一对多”方法相比,需要的分类器较多。本文利用Matlab软件中的libsvm工具包,选用多对多方法进行分类,并利用网格搜索的方法确定错分惩罚因子gam和径向基核函数的参数δ2。
4 T/R组件寿命分布识别流程
根据上述核主成分降维分析方法以及多分类支持向量机模型可建立一套完整的T/R组件寿命分布识别流程,具体的流程为:
1) 确定初始训练样本集。根据1.2节所选取的四种分布类型,并选定四种分布参数,利用Matlab软件,产生四种分布的随机数,求出每组随机数的数据特征,并进行归一化处理,将处理后的数据作为初始训练样本集;
2) 利用核主元分析法进行降维处理。通过建立的核主元模型对初始训练样本集进行主元特征降维处理,设置累积贡献率为0.95,当累积贡献率到达0.95时,确定主元特征数量,并把输出的特征向量作为后续支持向量机模型的训练样本;
3) 多分类支持向量机的参数设置及样本训练。设置SVM模型中的初始参数,然后将四种类型分布的随机数经过特征提取和降维后,分为训练样本和测试样本输入到模型中,判断识别率β是否达到要求,若未达到则修改模型初始参数,直到识别率满足要求为止;
4) 实例仿真识别。对T/R组件的寿命数据进行特征选取,并经主成分分析法提取主元特征,构成待识别寿命分布样本;
5) 验证识别结果的正确性。与传统假设检验识别方法进行比较,验证所建立模型的正确性。
具体流程图如图2。
5 实例仿真分析
5.1 确定初始训练样本
在对T/R组件寿命分布数据进行识别时,1.2节已经选取了指数分布、正态分布、威布尔分布、对数正态分布四种分布类型为可能的分布类型,为了更好地分析四种概率分布的形状及细节特点,本文对四种分布的具体参数细分,得到了100种分布模式,如表1所示。

表1 100组分布模式
利用Matlab仿真软件产生上述100组分布模式的100个随机数,然后求出每组随机数的数据特征:峰度、偏度、变异系数、累积概率、中位数,将处理后的数据作为初始训练样本集,部分初始训练样本集如表2所示。
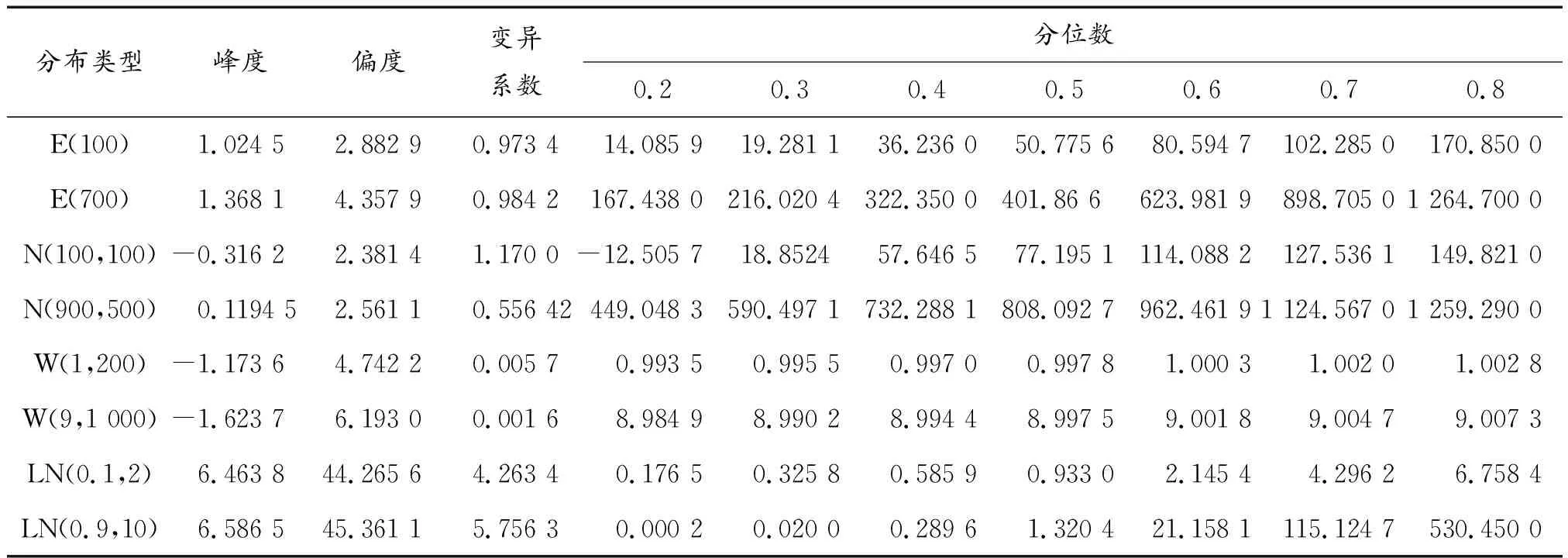
表2 部分初始训练样本集
5.2 核主元分析法降维
根据上述第2节中所建立的主元分析法步骤,对初始训练样本数据(100×10维矩阵)进行主元特征提取,核函数选择径向基核函数,经过仿真试验,本文δ1取值为100时,前4个核主元的方差累积贡献率达到97.17%,如图3所示。因此主元个数选取为4个,然后将初始训练样本在主元方向上对应的特征向量作为后续多分类支持向量机模型的输入量。
5.3 多分类支持向量机模型
本文按照3.2节多分类支持向量机的实现算法编写Matlab程序,构建了多分类支持向量机寿命分布识别模型,其中对错分样本惩罚程度的可调参数gam和径向基核函数的参数δ采用网格搜索的方法确定具体取值为gam=5.656 9,δ2=16,设置样本分类数为4类。本文在对模型进行训练时,将100组数据样本进行主元特征提取,然后将提取后的主元特征向量作为多分类支持向量机的训练样本,其中20组数据作为测试样本,测试样本的识别率达到95%,所建立的多分类支持向量机模型对测试样本的具体识别结果如图4所示。
为了说明核主元降维分析法的作用,将100组未经过核主元分析法的测试样本输入到多分类支持向量机模型,测试样本的识别率达到100%,具体识别结果如图5所示。
图4为经过核主元降维后的测试样本识别结果,图5为未经过核主元降维后的测试样本识别结果,虽然两者的识别精度有略微差别,但总体识别精度都在95%以上。经过核主元降维后的样本数据降低到4维,输入到多分类支持向量机模型中大大减少了运算时间。上述仿真结果表明,利用核主元分析法可以对训练样本数据进行降维,对后续多分类支持向量机模型识别方面大大降低了运算时间,因此在保证一定识别精度的前提下(识别精度在90%以上),经过核主元分析降维方法能够降低运算时间,相比于未经过核主元降维的方法,更具优越性。
5.4 T/R组件寿命分布实例仿真识别
本文对100组T/R组件进行寿命试验,对该100组T/R组件的首次失效时间进行记录,记录的失效时间依次为:13 524 h、23 722 h、2 938 h、5 036 h、8 062 h、5 597 h、11 882 h、3 330 h、6 079 h、5 356 h、57 h、6330 h、21 381 h、1 504 h、436 h、11 995 h、2 734 h、1 855 h、4 284 h、13 647 h、1 910 h、903 h、829 h、6 539 h、14 162 h、2 120 h、1 041 h、2 458 h、3 037 h、7 515 h、9 284 h、1 632 h、2 412 h、3 624 h、3 590 h、4 248 h、1 822 h、13 985 h、3 675 h、2 097 h、6 786 h、4 715 h、5 485 h、1185 h、1 351 h、1 795 h、2 366 h、4 219 h、9 074 h、8 010 h、1 817 h、660 h、3 625 h、7 836 h、385 h、4 054 h、2 920 h、7 737 h、542 h、4 906 h、4822 h、5 213 h、7 175 h、8 495 h、2 560 h、6 487 h、262 h、2 267 h、4 322 h、6 044 h、14 717 h、379 h、4 052 h、2 684 h、179 h、9 564 h、12 179 h、333 h、582 h、238 h、5 138 h、587 h、3 381 h、3 693 h、854 h、6 172 h、4 335 h、17 538 h、5 894 h、776 h、4 543 h、7 507 h、4 195 h、486 h、268 h、6 684 h、9 932 h、353 h、22 316 h、10 523 h。利用Matlab软件计算出该组数据的10个数据特征分别为1.764 8、7.921 8、0.954、1 473.8、2 277.6、3 405.2、4 565.3、6 070.2、8 476、10 815。然后对该10个数据特征进行核主元分析,将核主元降维后的数据输入到多分类支持向量机模型,得到最终的分类结果符合指数分布。
利用极大似然估计法对T/R组件的寿命分布数据进行参数估计,置信度设置为95%,求出不同假设分布的参数,并用k-s检验方法进行检验,具体结果如表3所示。
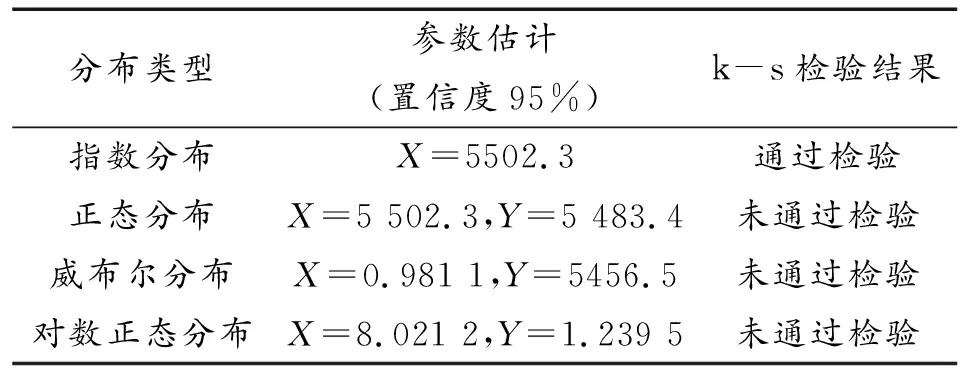
表3 分布参数拟合和k-s检验
分析表3的结果可知,利用极大似然估计和k-s检验统计法得到的最终寿命分布结果和本文建立的核主元降维-多分类支持向量机模型的分布识别结果一致,验证了模型的正确性。由于传统的极大似然估计和k-s检验统计法在对寿命分布进行识别时,有可能出现多种分布同时满足要求,这就需要进一步细分,增加了复杂程度,而本文建立的核主元降维-多分类支持向量机模型能够在保证一定识别精度条件下,最大限度降低运算速度,降低模型复杂程度。
6 结论
与传统极大似然估计和k-s检验统计法相比,本文所采用的核主元降维-多分类支持向量机模型分类精度高,能够降低模型的运算速度,更具优势性。
猜你喜欢
车主之友(2022年4期)2022-08-27
能源工程(2022年2期)2022-05-23
汽车实用技术(2022年4期)2022-03-07
商用汽车(2021年4期)2021-10-13
电力设备管理(2020年4期)2020-12-05
无线互联科技(2020年10期)2020-08-14
装备环境工程(2020年3期)2020-04-03
科技创新与应用(2020年6期)2020-02-29
海峡姐妹(2019年12期)2020-01-14
现代电子技术(2016年23期)2017-01-12
