
“同工不同酬”究竟来于何处?
——基于Appleton分解的方法
2018-12-03 11:03:28何乔
现代经济探讨 2018年11期
何 乔
内容提要:该文使用Appleton工资分解法研究了工作地所在户籍人口(本地人)与非户籍人口(外地人)的小时工资差异,研究发现,外地人与本地人的工资差距中81.52%归因于在行业内受到的歧视,行业间的歧视为7.17%。而当我们把样本城市按移民数量占比分为“移民接纳型城市”与“本地人主导型城市”两类后,发现“移民接纳型城市”中不可解释的部分仅占工资差距的12.75%,而“本地人主导型城市”中歧视则占到96%以上,前者说明我国目前外地人与本地人相比同工不同酬的现象仍然十分明显,后者则表明外地人歧视问题在我国城市具有多样性。
一、 引言与文献回顾
歧视问题是劳动经济学经常讨论的问题,改革开放40年来,原先捆绑在户籍制度上的利益逐渐稀释,从全国范围看,户籍歧视相比过去也有很大改善,然而对于目前的中国而言,由于“超级城市”如北京、上海的兴起,越来越多的人前往这些城市寻求发展机会,国家卫计委《中国流动人口发展报告2013》公布的数据显示,我国流动人口数量在2012年已经多达2.36亿,也就是说每六个人中就存在一个流动人口。巨大的外来人口流入导致这些城市中“原住民”与外来人员间的矛盾逐渐加深,由此形成了越来越严重的外地人歧视。这些歧视体现在:高收入行业优先招聘本地人、给予本地人更快的升职或给予外地人较低的工资等等。这些歧视一方面导致了劳动力市场资源配置的低效率,形成了一种新的二元劳动力市场,另一方面也扩大了本地人与外地人之间的收入差距。
有研究认为,本地人和外地人在不同行业间的分布也会造成本地人和外地人工资之间的差距,这方面的影响在许多大城市十分常见,最明显的就是大部分收入底层职业如清洁工、普通维修工由外地人占据。其次,在很多区域的事业单位招聘中往往含有户籍限制,2006年实施的《事业单位公开招聘人员暂行规定》中明确了“在事业单位公开招聘人员时,不得设置歧视性条件要求”后,不少地区采取了非户籍要求与高学历挂钩的“户籍开放政策”。然而,在多大程度上职业分布对本地人和外地人工资差距产生影响?在“原住民”强势地区(如北京、上海)和“移民”城市(如深圳、东莞)间有无差异?它们与传统的工资歧视相比谁起的作用更大?回答这些问题需要对工资差异进行分解,而答案有助于我们开对“药方”。
本文采用Appleton分解方法来探究是否拥有本地户籍对城镇就业者工资的影响。这种分解方法的好处在于既解决Brown分解存在的指数基准问题(index number problem)(葛玉好,2007),又能同时估计出工资歧视以及行业歧视两种劳动力市场歧视。
关于劳动力市场就业和工资差距的问题,已有的文献已经进行了许多深入的研究,严善平(2006)首次比较正式地界定了外地人歧视这个问题。他给出了三个理论假设:第一,中国的城市劳动力市场包含了外来劳动力和本地居民两大部分,但他们的劳动力市场是分层的。第二,从非正规行业流向正规行业的上升移动会带来工资收入的增加,但本地居民和外地人实现流动的机会是不均等的。第三,在求职过程中选择什么性质的行业、以何种方式在不同行业之间流动,主要取决于以户籍为代表的制度因素,而不是个人的教育水平、工作经历等人力资本。可以看到,严善平定义的外地人歧视既包含了工资歧视又包含了进入机会歧视。而关于歧视产生的原因,根据Ehrenberg(2011)的理论,可以分为个人偏见、统计性歧视和非竞争性力量三种解释,而就我国目前情况而言,前两种解释似乎更具有说服力。其中个人偏见是指雇主或其他雇员本身对外地人存在歧视,需要降低工资或者给予其他雇员更高的工资才能弥补他们的效用损失;而统计性歧视则是由于难以观测到雇员的完整信息,因此在雇佣劳动力时,雇主会利用雇员所在群体的劳动生产率组中值来评价这个雇员,而由于大多数外来劳动力从事低端工作,因此会使得该雇员受到偏低的评价。
姚先国、赖普清(2004)研究了城乡工人在工资收入方面的差异,认为这种差异基本上可以归结于两个方面:首先,人力资本水平的差异和工人就业企业的差异;其次,农民工就业中所受到的户籍歧视问题解释了两类工人工资收入差异的70%。也就是说人力资本和企业状况是决定工人收入差异的首要因素;同时,户籍歧视所造成的差距也是不容忽视的,其比例达到30%。谢嗣胜、姚先国(2006)采用浙江省企业调查和农村劳动力流动调查数据并运用Cotton分解对城市户籍工人和农民工进行工资分解,进一步将工资歧视分解为对企业农民工工资的直接歧视和企业对城市户籍工人的工资优待(即反向歧视)。王美艳(2005)利用Brown分解对五城市抽样数据进行研究,首次将外地人和本地人之间的歧视分解为岗位间歧视和岗位内歧视,但此方法并未解决指数基准问题(葛玉好,2007)。值得注意的是,钟笑寒(2006)针对农民工和城市职工职位隔离、工资差异的现象给出了一个理论上的解释,他认为不同的职位(蓝领和白领)对于生产而言属于不完全替代要素,由于农民工人力资本显著低于城镇职工,在蓝领岗位上的边际贡献更高,因而,农民工的加入促进了劳动市场的重新配对(劳动再分工),即高效率的城镇职工获得更高的职位“白领”,而低效率的农民工则从事“蓝领”工作,因此无论是城镇职工还是农民工,其收入都比原来升高了,具有帕累托改进的含义,因而得到劳动力流动促进效率提高的结论。这篇文章虽然没有涉及到歧视问题,但我们很容易想到,在雇员和雇主间存在的信息不对称使得雇主会或多或少地使用雇员所属群体的组中值来估计这个雇员的劳动生产率,如果雇主对于外地人的印象就是低效的话,那么产生对外地人的歧视就是在所难免的了。因此,这也可以认为是外地人歧视存在的一个理论解释。
之后的许多文献基本上围绕着上述问题,应用不同的方法和数据对外来劳动力和本地劳动力间的工资差异进行分析,主要的方法有OLS回归,如杨云彦、陈金永(2000),章元、王昊(2011);Oaxaca-Blinder分解法,如杜梦昕、郭磊磊(2010);Brown分解法,如黄志岭(2010);Neumark分解法,如许启发、蒋翠侠(2012)。
但目前尚未有应用Appleton分解对外来劳动力和本地劳动力进行工资差异研究的文献。这种方法的好处在于结合了经典的Oaxaca-Blinder分解法和Brown分解法中能够同时估计行业内工资歧视和行业间进入歧视的特点,而且解决了前两种方法存在的指数基准问题。更为重要的是,在已有的文献中,大部分都将工资差异视为一个普遍存在的问题,因而并未对样本进行区分,但我们可以看到,对不同人口组成的城市,其对外来劳动力的接纳度是不一样的。例如深圳和北京,这两个城市在发展过程中依靠的“主力”劳动力就完全不同,深圳作为一个“移民”城市,对外来劳动力的接纳度就要相对高一些;而北京作为一个“人满为患”的城市,外来劳动力的涌入造成了许多问题,因此其接纳度相对要低一些,这从北京出台的一些政策、当地人的征婚条件中也可以体现出来。因此区分不同外来劳动力接纳度的城市能够更加真实地还原劳动力市场的工资差异现象。
二、 研究设计
1. 数据描述和基本统计分析
本文使用CHIP(Chinese Household Income Project)2008年数据库。这个数据库最大的特点在于它拥有市级而非省级的数据信息,这在研究劳动力流动问题上提供了巨大的帮助。该数据库包含三个子样本:农村住户样本、农村-城镇流动人口样本、城镇住户样本。其中城镇和农村调查由国家统计局执行,而城乡流动人口的调查由中国收入分配研究院课题组组织完成,其中城镇和农村调查样本来自国家统计局每年的常规住户调查大样本库,而城乡流动人口调查样本为9省15市,根据本文需要,我们以城乡流动人口样本数据为基准,与城镇住户样本拼接成本文所用数据库。
由于两个子样本中对于工作行业的划分并不完全相同,因此,本文首先以国家统计局行业划分为标准将城乡流动人口调查样本中的行业从24个合并至20个,其中由于“国际组织”样本量太少而予以舍弃。参照王美艳(2005)的办法,根据《中国统计年鉴2008》所公布的分行业平均工资水平,将全行业按平均工资高低划分为5类。工资水平由低到高的五类行业分别为:① 农、林、牧、渔,住宿和餐饮业,水利、环境和公共设施管理业,建筑业;② 居民服务和其他服务业,制造业,批发和零售业,教育;③ 房地产业,交通运输、仓储和邮政业,卫生、社会保障和社会福利业,公共管理和社会组织;④ 租赁和商务服务业,文化、体育和娱乐业,采矿业,电力、燃气及水的生产和供应业;⑤ 科学研究、技术服务和地质勘查业,金融业,信息传输、计算机服务和软件业。
针对本研究而言,本文首先对样本做如下处理:首先根据我国对男女退休年龄的规定,选择年龄大于16周岁小于60周岁的男性样本和年龄大于16周岁,小于55周岁的女性样本;然后仅选择在城市有工作的样本,剔除职业类型为自由职业、个体、私营业主、务农、志愿者的样本;最后剔除在年龄、工作经验、婚姻情况、收入、工作时间等变量上存在缺失值的样本。
数据清理后剩余10841个样本,其中本地人样本6819个,外地人样本4022个。此处本地人受访者的户口就在其常住城市,外地人指受访者户口不在受访者常住城市,本文中对于本地人和外地人的区分就在于此。

表1 分市平均小时工资表

续表
从表1可以看出,本地人和外地人的工资差异几乎在每个城市都存在而且差异巨大,在性别之间也存在着明显的差异,这一方面可能来自于劳动者自身的人力资本、技能因素的差别(如受教育程度、工作经验等),另一方面则是来源于劳动力市场的歧视。

图1 本地人与外地人行业比例图
从行业布看,绝大多数外地人就业岗位都集中于平均收入最低的两个行业中,越是高收入行业,外地人职位所占的比重越小。这一点说明外地人与本地人之间可能存在着职位隔离,而Appleton分解恰好能够同时处理工资歧视与职位隔离两种歧视。
2. Appleton分解方法
如前文所述,Brown分解法存在着指数基准问题,所谓指数基准问题,是指在进行工资分解时,将不同的人群作为对照组,会得到不同的歧视结果,传统的做法是研究者根据自己的“经济学直觉”选取其中一个“恰当”的结果作为结论,这显然缺乏说服力。指数基准问题产生的原因在于无论是Oaxaca-Blinder分解还是Brown分解,都是要么将被歧视组作为基准,要么将被偏爱组作为基准,而根据前文所述,歧视既包含对外地人的歧视(也称“正向歧视”),又包括对本地人的偏爱(也称“反向歧视”),无论将谁作为基准,都已经包含了歧视的因素,故而无法得到一致的结果。Appleton解决了这个问题,并将行业内歧视与行业间歧视分离出来,实现了进一步的分解,Brown分解可以看成是Appleton分解的一个特例。
Appleton分解方法是1999年由Appleton在研究性别工资差异时提出的均值建模方法,在本质上是一种加权比较方法,它通过加权平均的思想构造出假设的“无歧视”状态,既包括同一行业内无歧视工资又包括进入同一行业的无歧视概率,然后分别将本地人和外地人的工资和进入行业概率与无歧视状态进行比较,进而将工资差异分解为能力因素、行业内因素和行业间因素。更进一步,Appleton分解法还将歧视分为对本地人的偏爱和对外地人的歧视。
在多行业情况下,平均工资可以表示为参与各行业的概率与该行业平均工资的乘积之和,即期望工资。因此,本地人与外地人的平均工资差别可以表示为:
(1)

(2)
因此可以将A式进一步分解为:
(3)
这样,A1表示由于行业内技能差异原因导致的本地人和外地人工资差距,A2表示行业内对本地人的优待,A3表示行业内对外地人的歧视。


综上所述,A1、B1、B2之和表示由于个人禀赋差异造成的工资差异;A2、A3之和表示行业内对外地人的歧视;B3、B4之和表示行业间对外地人的歧视;A2、A3、B3、B4之和表示由于对外地人的歧视而造成的工资差异。
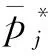
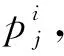
(4)
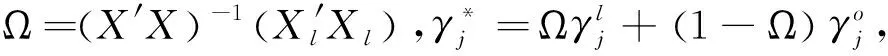
(5)
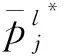
上所述,进行Appleton分解的主要步骤为:
① 进行多元回归,得到分行业工资方程;② 采用multinomial logit回归分别估计本地人和外地人的职业获得矩阵;③ 计算加权矩阵Ω、Δ;④ 计算无歧视情况下的行业获得概率与工资水平;⑤ 两两相比得到Appleton分解结果。
三、 实证结果分析
使用Appleton分解需要估计本地人与外地人的工资方程及行业选择方程。借鉴Mincer方程,本文采用受教育年限、工作经验及其平方项以及城市虚拟变量(成都为基本组)作为控制变量,在估计行业获得方程时,采用受教育年限、是否已婚、年龄以及年龄的平方项作为控制变量。由于一个劳动者i在j行业中工作, 可能是因为他在该行业的工资高于他在其他行业的工资(根据自己的比较优势决定自己的就业行业),也可能是因为他对该行业有着特殊的偏好,如果不能控制这些因素的话,得出来的βij(i=l,o)系数的估计就不是一致的,基于这些系数而进行工资分解可能就会得出错误的结果,因此在Appleton(1999)和葛玉好(2007)中,都采用了Lee(1983)的方法对样本进行调整以避免样本选择偏差,然而之后的研究认为Lee(1983)关于不可观测值ui独立同分布的假设在联合分布中并不成立,而由于Appleton分解要求的工资方程为分别对每一个行业和本地人/外地人进行回归,因此无法使用两阶段Heckman方程纠正样本选择偏差。但本文利用全样本进行的两阶段Heckman方程的结果与普通工资回归结果基本一致,因此可以认为在此的样本选择偏差并不是很严重,故而本文并没有予以纠正。
表2给出了Appleton分解的结果,从分解结果来看,本地人和外地人的工资差距大部分是由行业内歧视造成的,占到了全部工资差异的81.52%。这说明本地人和外地人之间存在着明显的同工不同酬情况,相比之下,行业间歧视仅占到7.17%,这说明图1中外地人与本地人在行业分布的不同主要由劳动者自身技能导致而不是由于歧视。

表2 Appleton分解结果
为了进一步探究不同外地人接纳程度的城市给予外来劳动力的工资差异情况,本文进一步根据国家统计局将15个城市按外地人占城市总人口的比重划分为原住民主导型和移民接纳型。外地人占城市总人口比重高于15个城市平均比重的认为是移民接纳型城市,反之则为原住民主导型城市,如表3所示。然后分别对其进行Appleton分解,由于涉及的回归表格较多,因此仅报告分组后的Appleton分解结果,如表4、表5所示。
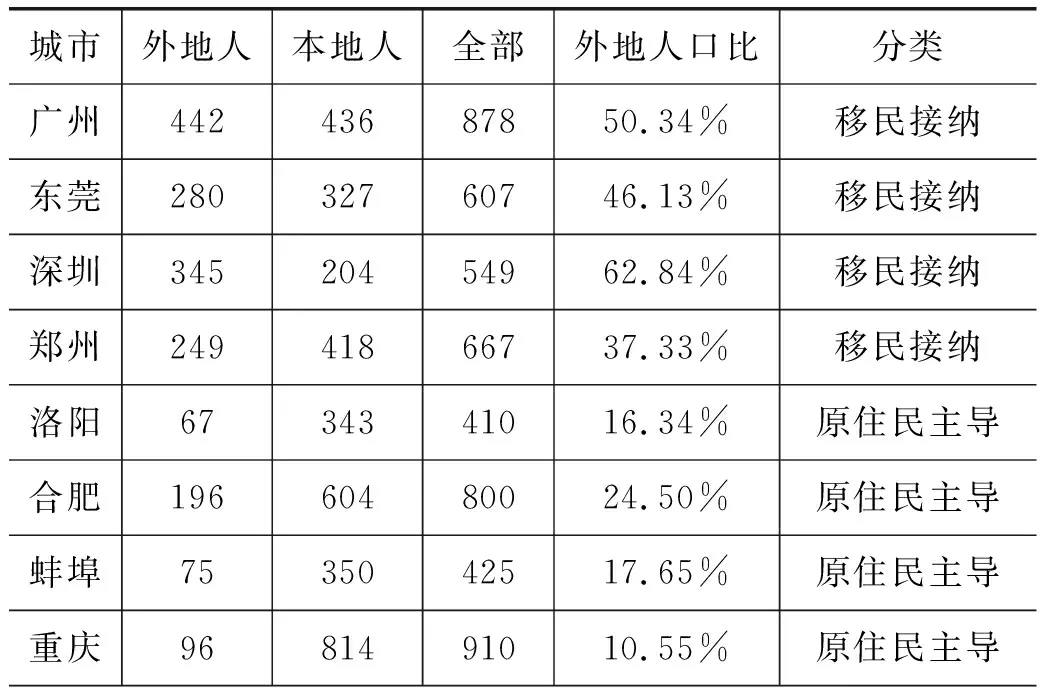
表3 城市类型分类表

续表

表4 移民接纳型城市Appleton分解

表5 原住民主导型城市Appleton分解
Fortin(2010)提出:在使用Oaxaca及其扩展型均值工资分解法时,需要注意数据应当满足可比性原则,即不应出现在某一层次的数据只有一个群体有观测值而另一个群体没有观测值的情况。针对本文而言,由于数据由CHIP两个子样本拼接而成,因此外地人中大部分是属于农民工群体,很显然,博士学历不可能存在于农民工群体中,因而可能违反Fortin提出的要求。针对此,本文进行了一次稳健性检验,即将受教育年限超过16年(大学本科)的样本全部剔除,再次进行Appleton分解,得到如表6分解结果:

表6 Robust检验Appleton分解
可以看到,表6与表2几乎没有差异,基本结论也没有任何改变,因此可以认为非平衡数据对本文的影响并不大,对Appleton分解的准确性和解释力无显著的影响。
四、 结论与政策建议
基于CHIP2008年数据库,本文选取Appleton方法探究了本地人与外地人在工资上的差异问题,发现高达81.52%的工资差异来源于行业内对外地人的歧视和对本地人的偏爱,这表明目前我国“同工不同酬”的现象依然比较严重。在区分了“原住民主导型城市”和“移民接纳型城市”后,可以显著看到两种不同类型城市对待外地人的差异。以深圳、东莞为代表的移民接纳型城市中大部分工资差异来源于本地人与外地人之间的技能差异;以上海为代表的原住民主导型城市中的工资差异则大部分来源于行业内歧视,这一结果反映出不同地区对外地人的歧视程度差异很大,在研究歧视问题的时候可以将不同发展阶段、不同历史背景的地区分开研究,可能会有更好的效果。
对于产生两类城市在对外地人工资歧视巨大差异的原因,本文猜想可能与不同城市由于其管理水平等原因,“移民接纳型”城市雇主雇佣一名外地人所需花费的成本更低,典型的例子就是用工大户富士康落户成都郫县后,当地政府针对外地人劳务合同等方面出台了一系列优惠政策,甚至承诺帮助其招聘一定数量的一线工人,这样的政策大幅降低了雇主雇佣外地员工的成本。由于缺乏相关数据,此猜想并未得到验证。这里还需要提到的是,Peter Kuhn和Kailing Shen在一篇尚未发表的论文中指出,在厦门市,雇主面对相同条件(性别、年龄、经验、技能等)的雇员时,更愿意雇佣外地人,因为他们失去工作的机会成本更高,所以在工作时会更加努力。由于厦门市并未包含在本文样本中,因此并不能判断其属于哪一个城市,但从这篇文章的解释里已经可以看出,企业能够用相同的工资购买更多的外地人的劳动,这也从侧面印证了本文的观点。
当然本文依然存在一些可以改善的地方。Appleton分解法一个重要的缺陷在于它只能显示分解后的数值而不能反映其置信区间,Ben(2008)给出了Neumark分解的置信区间近似计算方法,相信Appleton分解也能用类似的方法进行计算。其次相比分布分解方法,Appleton分解局限于对工资均值进行分解,这在财富分配差距较大的中国可能会导致其代表性的下降,这也是下一步研究的方向。
猜你喜欢
意林彩版(2022年2期)2022-05-03 00:07:26
今日农业(2021年1期)2021-03-19 08:35:16
今日农业(2020年24期)2020-12-15 16:16:00
时代邮刊·下半月(2019年3期)2019-09-10 07:22:44
汉语世界(The World of Chinese)(2018年4期)2018-10-20 10:46:20
金山(2017年11期)2017-12-06 12:48:34
小雪花·初中高分作文(2016年1期)2016-05-30 02:08:14
华南农业大学学报(社会科学版)(2015年3期)2016-01-11 11:46:23
商道(2015年3期)2015-03-19 07:16:43
商道(2015年2期)2015-03-18 07:20:51
