
利用网络数据预测企业失信行为
2018-12-01 01:52周涛李艳丽李倩陈端兵谢文波吴桐曾途
大数据 2018年5期
周涛,李艳丽,李倩,陈端兵,3,谢文波,3,吴桐,曾途
1. 电子科技大学大数据研究中心,四川 成都 611731;2. 成都数联铭品科技有限公司,四川 成都 610041;3. 成都数之联科技有限公司,四川 成都 610041
1 引言
随着互联网、移动互联网、物联网和各种遥感探测技术的发展,一个“一切都被记录,一切都被分析”的数据化时代已经到来[1]。大数据的技术发展与应用实践已经为社会经济和人们的日常生活带来了显著的贡献[2]。在医疗领域,大数据和人工智能被用于精准识别医疗影像中早期的病灶,定位致病基因并开展相应的靶向治疗,实时监测评估健康状况,提前预警重大健康风险等[3];在交通领域,海量数据和预测算法的结合能够帮助人们进行更高效的交通导航,尽可能减少拥堵时间[4];在教育领域,对学生发展过程中学习和生活数据的分析可以帮助了解学生行为和学业表现之间的关系,从而设计更高效的个性化教育方案,提前对不利于学业发展的异常行为进行干预[5]等。
在各种大数据研究对象和大数据应用场景中,网络大数据是独具特色且受到广泛关注的方向[6-7]。网络科学是以网络为研究对象的一门有数百年历史的专业性很强的学科,又是众多学科中不同研究对象的统一抽象的表达方式[8]。目前万维网具有超过万亿 的统一资源定位符(uniform resource locator,URL),Facebook有10亿个节点和千亿条连边,大脑神经元网络有数百亿节点……如何分析挖掘大规模网络中隐藏的信息,进一步应用于解决实际问题,已经成为学术界和企业界亟待解决的重要挑战。
金融网络分析是网络大数据在金融领域的应用,因为其可见的巨大价值,最近受到了广泛的关注[9-10]。真实的金融网络包括金融机构之间的业务关系网络[11]、投资机构和企业之间或投资机构之间因共同投资而形成的投资关系网络[12]等。这些网络往往度分布范围很广,网络连接总体上比较稀疏,网络连接呈现负相关性(度大的节点倾向于和度小的节点相连),但度很大的若干节点之间表现出“富人俱乐部效应”(即度最大的若干节点之间连接特别紧密)。金融网络分析可以帮助人们尽早发现金融风险,提升抗击重大风险的能力[13-14]。
本文拟将金融网络大数据分析技术应用于预测企业失信行为。笔者认为,定量刻画企业信用水平,进一步预测企业可能出现的各种失信行为,是建立信用社会、提升营商环境中不可或缺的重要环节,可以作为商务合作、股权投资、担保贷款、招商引资等业务的前置条件。传统的分析方法多从企业规模、经营地、行业类别、注册与实缴资本等特征属性出发,预测结果往往并不准确。最近大数据方法被广泛应用于企业征信领域,取得了大量、丰富且重要的成果[15-17]。但是,据笔者所知,目前尚没有直接利用大规模企业间投资关系网络来提升分析精确性的研究工作。本文采集清洗了大量数据,建立了包含400多万家企业的有向投资网络,其中存在各类失信行为的企业占比6%左右。研究结果显示,企业失信行为存在明显的“网络效应”,即目标企业的股东或者投资企业若存在失信行为,则目标企业发生失信的风险远远大于平均值。基于以上分析,笔者实现了一个简单的失信行为预测算法,其精确性远远超过了不考虑网络效应的回归方法。
2 数据描述和网络分析
本文分析的数据采 自国家企业信用信息公示系统的公开数据,包括企业的基本信息(如企业类型、企业注册资本、企业注册地、企业所属行业等)、工商变更等备案信息、各类行政处罚和其他失信行为公告等多项数据。表1给出了我国企业的行业分类信息。
本文分析的网络数据集包括4020504家企业,其中有259760家企业存在至少一次失信行为(本文为了便于叙述,把各种行政处罚都归为失信行为),占比为6.46%。笔者建立了这些企业之间直接投资形成的有向网络,其中每一个节点代表一家企业,如果企业i投资了企业j(i是j的股东),则用一条有向边i->j表示。
图1显示了不同规模的4个有代表性的弱连通子图,其中灰色节点为没有失信行为的企业,黑色节点为有失信行为的企业。图1中连边的方向没有表现出来。
式中,WT为流域中下游年径流变化的总量;WH为人为活动对流域中下游年径流变化的影响量;WC为气候变化对流域上游年径流变化的影响量;WN为背景值,W入河为流域入河径流量;W山口为流域水文站的实测年径流深;WHN为流域水文站的模拟值或预测值;ηH为人为活动对流域中下游径流变化影响的百分比;ηC为气候变化对流域中下游径流变化影响的百分比。
即便以有向网络弱连通作为判据,该网络也不是完全连通的网络。图1给出了所有弱连通子图规模(节点数)的Zipf分布(关于Zipf分布的定义以及其与幂律分布和Heaps定律的关系,请参考文献[18])。可以看到,仅有一个超级连通图规模在100万个节点以上,其余第二大连通图规模只有不到10万个节点。绝大部分连通图的规模都很小。笔者也在图1中选择了若干可以用可视化方法直接画出来的规模较小的连通图,方便读者直观地看到投资网络的结构(为了可视化效果,投资关系的方向在此处省略了)。后文为了便于叙述,将存在失信行为的企业简称为失信企业,读者要注意这并不是严格等同的概念。

表1 企业行业信息字段和内容

图1 按照弱连通图规模排序得到的Z ipf分布
笔者猜测,企业失信行为在企业之间的投资网络中具有明显的“网络效应”。也就是说,如果一个目标企业的投资者(法人股东)或其投资对象(子公司、控股公司、参股公司等)存在失信行为,那么这个目标企业存在失信行为的可能性也很大。为了方便、直观地观察上述网络效应,先考虑一种简单的情况,即将有向投资关系网络转化为无向网络加以考虑,暂时忽略连边的方向性。用P(B|m)表示所有邻居中失信企业数目大于或等于m的企业是一个失信企业的概率。显然,当m=0时,P(B|0)=0.0646,就是整个数据集中失信企业的比例。图2给出了P(B|m)随m变化的曲线。该曲线上升的趋势非常明显,尤其在m比较小的时候(m很大的时候数据点很少,因此会出现一些波动)。即便只知道“目标企业的投资方和投资对象存在失信企业”这一信息(也就是m=1),该目标企业是失信企业的概率就从P(B|0)=0.0646陡增到P(B|1)=0.1641。而如果一家企业邻居中有3家或3家以上失信企业,它自己是失信企业的可能性会超过40%。笔者在图2中还用虚线强调了一个值(虚线所示),即如果已知目标企业的邻居中没有失信企业,则该目标企业自身是失信企业的可能性是0.0474,比整个数据集中失信企业占比低了27%。
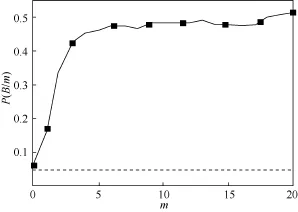
图2 P(B/m)随m的变化曲线
以上分析显示,投资网络模型对于分析企业失信行为而言是一个非常有效的工具。事实上,如同社交网络上吸烟―戒烟[19]、肥胖―减肥[20]的网络效应(如果你身边有很多烟鬼,那么你是烟鬼的可能性会大大增加;类似地,如果你的很多社交好友都在减肥,那么你减肥成功的可能性也会增大)一样,企业失信行为也有明显的网络效应,即目标企业的投资方或者投资对象若存在失信行为,则目标企业发生失信的风险会大大增加,而且随着失信邻居数目的增加,失信风险也快速增加。这种现象既可能来自投资关系本身的风险传递(如果目标企业的投资对象出现了信贷违约,说明该企业现金流出现了严重问题,那么目标企业可能已经为投资对象注入了现金,并且获得期望投资收益的可能性很小,因此目标企业自身也可能出现类似风险),也可能来自全行业的问题(例如环保标准上升后大量家具行业受到行政处罚,而这些同行业企业之间容易有产业链条上的投资关系)。
3 预测算法和预测结果
因为有一些企业基本信息数据不完备,为了和只用基本特征信息进行分析的算法做对比,本文仅考虑基本信息完备的3207962家企业,其中有失信行为的企业有257163家。因为本文的核心诉求是揭示企业失信行为的网络效应,所以不采用和对比非常复杂的算法。笔者选择了广义线性回归模型[21],该模型拟合过程是并行的,计算速度非常快,适用于本文拟处理的数百万规模企业。因为预测企业失信行为是一个典型的二分类问题,选用伯努 利分布作为广义线性模型的函数族,故一个企业是失信企业的似然值可由以下计算式拟合:
E(x,w)=[1+exp(-wTx)]-1(1)其中,x为特征向量,w为特征权重向量。表2给出了本文使用的企业基本特征和网络特征说明,其中二阶邻居是指与目标企业在无向图中距离恰好为2的企业集合。企业基本特征中的离散型已转化为多项2值特征——1 代表“是”,0 代表“否”。
本文实验中采用10次交叉验证,抽取9:1的数据作为训练集和测试集,通过10次实验求平均。每次实验根据训练集回归模型拟合的参数,对测试集中所有企业存在失信行为的期望值打分,把风险最高的企业排在前面。如果风险最高的Top N个企业中失信企业有r个,就定义精确度为:

图3给出了预测精确度随N的变化曲线。图3中,NOR表示使用全部的企业基本特征,S1表示使用网络特征中的一阶邻居特征,S2表示使用网络特征中的二阶邻居特征。ALL表示融合S1、S2和NOR的特征。可以看到,网络特征中一阶邻居网络特征较二阶邻居网络特征预测效果更好,仅用企业基本特征不能很好地预测企业失信行为。如果结合了网络特征,预测的精确度能够被大幅度提升。其中预测出来失信风险最高的100家企业有70%以上有失信行为,前10000家企业40%左右有失信行为。

表2 预测模型中涉及的基础特征及网络特征

图3 使用不同特征进行组合时预测模型的精确度对比
4 结束语
本文采集了400多万家企业的真实数据,构建了大规模的企业间投资网络,揭示了企业失信行为显著的网络效应,即目标企业的投资方或者投资对象若存在失信行为,则目标企业发生失信的风险会大大增加。进一步的分析显示,随着失信邻居数目的增加,失信风险也快速增加。基于此,本文设计了一个简单的广义线性回归模型对企业失信行为进行预测。算法结果显示,网络特征的加入可以大幅度提高仅采用文本特征的算法的精确度。结合网络特征的算法可以在给出10000家最高失信风险企业的情况下做到40%的预测精确度。
企业征信是金融生态体系,甚至经济生态体系建设中至关重要的一环。本文仅仅是开展了初步的尝试,就有效证明了大数据在金融征信领域的巨大应用价值。事实上,企业投资关系网络是应用潜力非常广泛的一类数据。举例而言,通过投资关系网络,可以发现一些异常的投资行为,例如通过多地、多次变更,形成企业A1全资控股A2,A2全资控股A3,…,As-1全资控股As,As全资控股A1这样的长度为s的企业投资有向环,利用这样的有向环,企业A1可以把1亿元注册资本给A2,A2再给A3,以此类推,最终回到A1。资金没有真正投入,但是每家企业的实缴注册资本都增加了1亿元。这些都是企业获取虚假资质、假造项目承接能力甚至非法集资常用的伎俩。这些重大金融经济风险问题转变成了在一个几千万个节点的企业投资关系网络中发现有向环的典型的图论问题。事实上,企业投资关系网络的应用还很多,本文的思路和方法还可以刻画金融担保圈的风险传播,提高识别金融担保圈中关键节点的准确度[22],提升大数据在打击非法集资[23]、反洗钱[24]方面的效率和准确度。本文研究内容仅仅是其万千应用中的一角,希望能给金融管理工作者有益的启发,并激发数据科学家和数据工程师投身于网络大数据的研究和应用中。
猜你喜欢
黄河之声(2022年10期)2022-09-27
机械工业标准化与质量(2022年6期)2022-08-12
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
国际眼科杂志(2021年9期)2021-09-15
装备制造技术(2020年2期)2020-12-14
疯狂英语·新策略(2019年10期)2019-12-13
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
