
基于铁路出行数据的旅客常住地智能识别算法研究
2018-12-01 07:04:54郭根材
铁路计算机应用 2018年11期
郭根材
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
人口流动性是经济社会发展的一个重要指标,人口以流动方式追求经济社会目标而形成的较长时间的自由迁徙和异地生活状况。由于升学、工作等原因,我国居民身份证号中包含的居住地信息与居民实际的常住地有较大差异。掌握旅客常住地信息有助于根据居住地人均收入推断旅客的消费水平,为个性化产品推荐提供基础。
目前,获取常住地信息的方法主要有常住人口、户籍登记、人口普查、大数据分析等。文献[1]以年度人口变动调查为基础,通过调查指标之间的关系、人口变动自身特征与抽查的情况,分析我国各地区常住人口的推算方法;文献[2]以第六次上海市流动人口普查数据为对象,通过分析变量离散趋势、空间分布等探讨了上海流动人口的分布特征;文献[3]描述和分析了区域人口迁移流动的实际状况,构建了常住-户籍人口缺口指标来观察我国分地区人口迁移流动态势;文献[4]结合人口普查数据与GIS数据,系统分析了武汉城市圈常住人口空间分布特征;文献[5]提出分布式存储与计算,大数据技术成为数据分析重要手段,文献[6]基于移动通信运营商的即时通话记录数据所表征的用户行为对人口的流动性进行判断和测度,这些研究为常住地识别提供了较好的基础。
本文参考上述研究结果,分析了利用铁路出行数据推断旅客常住地的主要影响因素,结合大数据技术设计了基于逻辑判断的旅客常住地智能识别算法,并进行了案例验证。
1 常住地界定
根据联合国经济和社会事务部统计司在《人口和住房普查原则与建议》中的建议,常住地可按照以下标准界定:(1)在最近12个月的大部分时间一直居住的地方,不包括因度假或工作引起的短暂出行;(2)至少在最近12个月一直居住的地方,不包括因度假或工作引起的短暂出行[1]。
旅客出行一般是从常住地出发经过一个或多个目的地后返回常住地,完成一次出行。对于普通旅客,旅客在目的地的停留时间要远小于在常住地停留的时间。铁路出行数据可以描述旅客乘坐火车的出行轨迹,通过分析旅客的出行记轨迹、在目的地的停留时间,利用逻辑判断、概率计算等方法可以判断旅客每次出行的起点,从而可以利用旅客一年以上的出行数据推断旅客的常住地。
2 基于出行数据识别常驻地
2.1 影响因素
利用铁路旅客出行数据推断常住地信息,受出行数据质量影响,主要有:
(1)出行次数过少。部分旅客在统计周期内的出行次数过少,不能形成有效的出行回路,无法在出行起点与出行终点之间确定常住地,这些旅客的常住地不能通过铁路出行数据进行识别。
(2)行程不连续。综合交通背景下,旅客可组合多种交通方式完成出行,导致铁路出行数据在整个行程上是不连续的,该类型旅客需要结合其他交通方式的出行数据进行判断。
(3)多出行起点。铁路出行数据可能构成多个出行回路,旅客出行时可能存在多个不同的出行起点,该情况下可选取比重最大的出行起点作为常住地。
(4)目的地最大停留时间。根据不同的出行目的,旅客在目的地的停留时间一般会有一个时间上限,当旅客在目的地的停留时间过长时旅客可能存在多个常住地,该情况有效无法识别旅客常住地。
2.2 基本概念
根据铁路出行数据识别旅客常住地的影响因素,通过统计判断、概率计算推断铁路旅客常住地,设计了基于铁路旅客出行数据的常住地智能识别算法。为描述算法,给出了行程、差旅、差旅集合的定义。
(1)行程是指旅客从一个城市到达另一个城市的出行信息,包括出发城市、到达城市、出发时间和到达时间。
(2)差旅是指旅客从常住地出发通过乘坐多趟列车到达目的地,最后返回常住地的行程集合,由多个行程构成。
(3)差旅集合是指旅客在指定时间段内的差旅集合,差旅出发城市是影响常住地判断的重要因素。
2.3 算法流程
单名旅客的常住地智能识别算法流程如下:
(1)选取某一旅客在指定时间内的行程数据,并按照旅客的出行时间排序,构建行程集合;初始化识别参数,设置行程判断序号i=0;
(2)设置i=i+1,从旅客的第i个行程进行深度搜索;如果i<行程集合数量,执行下一步,否则执行(7);
(3)设置深度搜索序号j=i;
(4)选取行程j和行程j+1,判断行程j的到达城市与行程j+1的出发城市是否相同,如果相同,执行下一步,否则i=j执行(2);
(5)判断行程j到达与行程j+1出发的间隔时间是否小于最大停留时间,如果是,执行下一步,否则设置i=j并执行(2);
(6)判断行程i的出发城市与行程j+1的到达城市是否相同,如果相同,根据i至j+1的所有行程构成一个差旅,并添加在差旅集合中,设置i=j+1并执行(2);如果不同,设置j=j+1并执行(4);
(7)统计差旅集合的差旅个数,如果差旅集合的差旅数量为0,旅客常住地为未知,否则执行下一步;
(8)统计差旅集合的差旅出发城市及次数,选取次数最大的出发城市为常住地。
3 案例
3.1 计算平台
铁路作为大众化交通工具,服务旅客数量庞大,传统的单个服务器程序很难在短时间内推算所有旅客的常住地。本文利用Scala语言在铁路客运大数据平台上实现常住地识别算法。铁路客运大数据平台分为外部系统层、数据层、存储层、分析层、展示访问层和应用层[7],可实现铁路旅客群体分析应用[8]。该平台由1个控制节点、2个管理节点、19个数据节点组成,SPARK版本为1.6。利用铁路旅客出行记录推断旅客常住地,2017年旅客出行记录条数为30.46亿,旅客数量约4.45亿人。
3.2 算法实现
算法参数目的地旅客最大停留时长为30天,基于SPARK的旅客常住地识别核心伪代码,如图1所示。

图1 旅客常住地识别算法伪代码
在铁路客运大数据平台提交作业,平台将计算作业划分为3个任务、5个阶段的运算过程,SPARK作业流程图,如图2所示。SPARK运算通过一系列弹性分布式数据集(RDD,Resilient Distributed Datasets)的转换,实现分布式读取数据、数据重新分区、常住地识别、结果转换等计算流程,最终将计算结果写入铁路客运大数据平台的分布式数据仓库HIVE中。图2中黄色部分为常住地核心算法,实现分布式推算旅客常住地。
在运算过程中通过对数据的重新分区与分组降低了作业的内存使用规模与执行单元数量。通过SPARK运算,推算出我国铁路近两年服务旅客的常住地信息,识别率为67.7%。
4 结束语
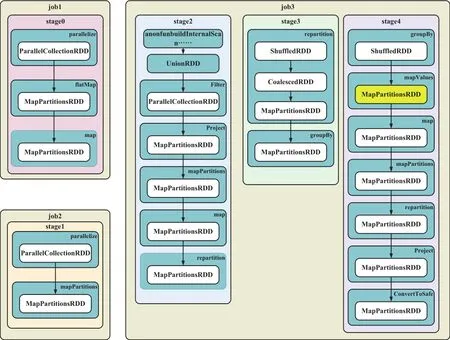
图2 推算旅客常住地SPARK作业流程图
本文设计了基于铁路出行数据推算旅客常住地的识别算法,该算法可以推算出铁路旅客的常住地信息,识别率为67.7%,为常住地的获取提供了一种新思路。受旅客出行次数、行程是否连续等因素影响,算法的识别率可结合其他交通方式的出行数据进一步提高,并利用计算结果进行常住人口分析与预测[9-10]。
猜你喜欢
小主人报(2022年7期)2022-08-16 06:59:30
中国品牌(2021年7期)2021-08-09 21:21:51
小哥白尼(趣味科学)(2021年3期)2021-07-16 07:47:32
小天使·三年级语数英综合(2021年4期)2021-06-15 03:25:33
小猕猴学习画刊·下半月(2018年9期)2018-05-14 13:34:42
故事大王(2018年3期)2018-05-03 09:55:52
青岛画报·新青岛(2017年3期)2017-01-17 12:28:55
石油化工管理干部学院学报(2016年3期)2016-08-10 06:39:07
幸福·婚姻版(2016年6期)2016-06-21 12:35:53
空中之家(2016年1期)2016-05-17 04:47:43
