
基于GF-1 PMS影像和k-NN方法的延庆区森林蓄积量估测
2018-11-30 06:28:08王海宾彭道黎高秀会李文芳
浙江农林大学学报 2018年6期
王海宾,彭道黎,高秀会,李文芳
(1.北京林业大学 林学院,北京 100083; 2.中国空间科学技术研究院 通信卫星事业部,北京 100094;3.北京市大兴区林业站,北京102600)
森林结构参数估测是森林可持续经营和生态环境监测的重要内容。森林蓄积量作为森林结构参数中的一个重要因子,是组成陆地植被生物量的重要成分之一,是评价森林资源数量与质量、反映森林经营管理水平的重要因子,也是评估森林固碳能力和森林碳收支的重要指标[1-4],因此,准确地估测森林蓄积量对森林经营管理和生态环境保护建设具有重要意义[5-6]。目前,应用遥感技术估测森林蓄积量的研究主要集中在2个方面:一是选取或结合不同遥感数据源(光学遥感、微波探测和激光雷达探测数据)构建估测模型,进行森林蓄积量估测;二是估测方法的多样性,由典型的参数方法(线性回归)向非参数方法转变(如人工神经网络、k近邻分类算法等)[2,4,7-10]。在森林蓄积量模型构建的过程中,自变量间的复共线性问题是亟待解决的一个问题。这些在传统的线性回归估测中无法避免[11-12]。k-最邻近(k-nearest neighbor,k-NN)方法作为一种非线性方法,可以不考虑复共线性问题,并且具有稳定的抗逆性,在欧洲和北美地区的森林资源监测中得到了广泛的应用。国内也开展了有关k-NN法估测森林蓄积及生物量的研究[10-13],但对比参数方法和非参数方法进行估测的研究不多。在以往的研究中,采用高分辨率数据进行森林蓄积量的估测多以国外数据为主。高分1号(GF-1)卫星是中国高分辨率对地观测卫星系统重大专项的第1颗卫星,它可以提供高分辨率的多光谱(8 m)和全色波段(2 m)数据,为森林资源动态监测提供了新的数据源[14]。然而,受限于GF-1卫星影像的覆盖范围等原因,针对GF-1全色和多光谱(panchromatic and multispectral,PMS)影像用于县域尺度森林蓄积量定量估测的研究较少。GF-1 PMS数据将高空间分辨率、高时间分辨率等优势集合于一体,挖掘并探讨GF-1 PMS影像数据估测森林蓄积量的潜力,对森林生理生态参数进行定量评价和GF-1 PMS影像数据的应用推广具有重要意义。本研究应用GF-1 PMS影像数据,通过挖掘影像的光谱信息,建立植被指数自变量集,并对自变量进行优选,采用k-NN方法构建森林蓄积量估测模型,并与偏最小二乘回归法构建的森林蓄积量估测模型进行对比,以此分析GF-1 PMS影像数据和2种估测方法的应用潜力,为县域尺度应用GF-1 PMS影像数据估测森林生理生态参数提供参考。
1 研究材料
1.1 研究区概况
延庆区位于北京市的西北部(40°16′~40°47′N, 115°44′~116°34′E), 东邻怀柔, 南接昌平, 西面和北面与河北省怀来县、赤城县相接,三面环山,总面积达1 993.75 km2。该区属大陆性季风气候,是暖温带与中温带,半干旱与半湿润的过渡带。年平均温度为8.8℃,无霜期150~160 d。年平均降水量为467.0 mm,降水主要集中在6-8月。该区内森林植被属于针阔混交林森林植被,现存植被主要为人工林以及一些次生植被类型。区内主要森林类型有油松Pinus tabulaeformis林,侧柏Platycladus orientalis林,华北落叶松Larix principis-rupprechtii林,蒙古栎Quercus liaotungensis林,刺槐Robinia pseudoacacia林,白桦Betula platyphylla林,山杨Populus davidiana林和杂木林等。据2015年北京市公布的森林资源数据显示,延庆区森林面积为11.5万hm2,森林覆盖率为57.46%,森林蓄积量达到215.77万m3,占北京市总森林蓄积量的12.68%,具有重要的生态系统防护作用和固碳功能。
1.2 研究数据
1.2.1 地面数据及辅助数据 地面数据是延庆区2014年森林资源二类调查数据(以下简称 “二调数据”),以矢量地理信息数据的形式储存。全区二类调查数据中的小班个数为2.37×104个,小班面积及蓄积的统计特征见表1。本研究所应用到的调查因子包括小班编号、地类、小班蓄积、小班面积等因子。辅助数据包括延庆区边界矢量数据和覆盖延庆区的1∶10 000数字高程模型(DEM)数据,地面数据和辅助数据的坐标为北京54坐标系。
1.2.2 遥感影像 GF-1号卫星装载有2 m分辨率全色和8 m分辨率多光谱相结合的相机(PMS1~PMS2),多光谱相机包括蓝(0.45~0.52 μm), 绿(0.52~0.59 μm),红(0.63~0.69 μm)和近红外(0.77~0.89 μm)4 个波段,全色相机包括1个全色波段(0.45~0.89 μm),2台相机组合幅宽达60 km,重访周期为4 d。本研究选取了覆盖研究区的7景GF-1 PMS影像,由中国林业科学研究院资源信息研究所提供,其中序号2影像由于影像缺失,采用了2014年的影像进行补充,并假设对估测结果未产生影响,序号6和序号7的影像获取时间为2015年1月31号,作为补充影像,只覆盖了少部分区域,因此产生的差异可以忽略不计。GF-1 PMS影像数据详情见表2。
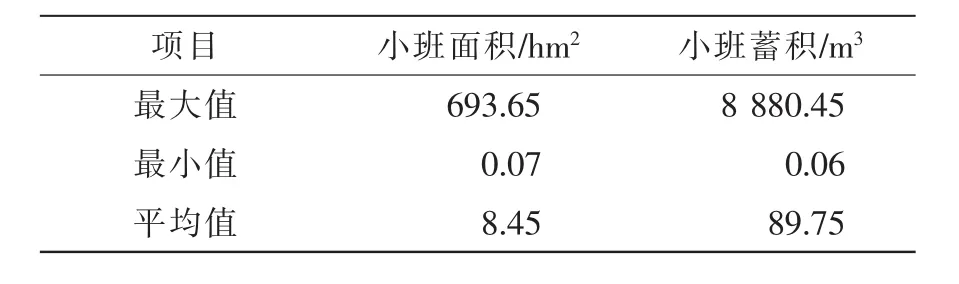
表1 延庆区二类调查数据小班面积及蓄积基本统计量Table 1 Descriptive statistics of small class area and volume of forest management inventory in Yanqing District

表2 覆盖延庆区的GF-1 PMS影像列表Table 2 List of GF-1 PMS images covering Yanqing District
1.2.3 地面数据处理 二类调查数据为区划调查数据,可以覆盖整个延庆区。在估测森林蓄积量前,需要计算小班内的每公顷森林蓄积量[不包括非森林地类的蓄积量(疏林地、散生木、四旁树的蓄积量),以下统称公顷蓄积量],采用Arc GIS软件中属性表中的字段计算器计算(公顷蓄积量=小班蓄积/小班面积)。本研究采用系统抽样方法在延庆区内布设抽样点,为与GF-1 PMS影像3×3窗口大小近似匹配,确定抽样点的面积大小为600 m2,形状为正方形。利用Arc GIS软件布设覆盖延庆区的格网,格网面积大小为600 m2。在布设格网时,存在单个格网覆盖多个小班的情况。本研究采用格网内小班公顷蓄积乘以对应小班的面积权重值,并求和获得覆盖多个小班的格网的蓄积量,最后计算格网内公顷蓄积量的变异系数,并取可靠水平为90%和估计精度为85%(二类规程要求)的控制标准,计算需要布设的抽样点个数及间距,并以此为基础外推估算延庆区的森林蓄积量。经计算公顷蓄积量的变异系数为2.015 3,确定样本数为489个,抽样间距为2.02 km。为与北京市一类清查样地布设间距相近,在满足抽样精度的基础上,本研究设置系统抽样间距为2 km×2 km(图1)。经系统布设样地后得到延庆区的抽样点共计492个,将抽样点所在的小班属性信息追加到抽样点上。处理后的样点数据包括样地号、地类、公顷蓄积量等因子,样点数据同时用于影像的分类结果验证。提取出蓄积量大于0的样点用于森林蓄积量反演,经处理后提取抽样点数据(蓄积大于0)共计156个。
1.2.4 遥感影像预处理 应用ENVI 5.1对7景GF-1 PMS影像进行辐射定标、大气校正,参照已校正好的2004年SOPT-5融合数据(2.5 m),对高分影像进行正射校正,误差控制在1个像元以内,对校正好的7景GF-1 PMS影像进行镶嵌处理,生成覆盖整个延庆区的GF-1 PMS影像,并利用延庆区边界矢量数据进行裁剪,生成延庆区范围内的GF-1影像(图1),遥感影像校正后的坐标同地面数据和辅助数据。本研究选取应用较为广泛的最大似然分类法提取森林植被信息[12]。依据《国家森林资源连续清查主要技术规定》(2014)中的森林面积定义:森林面积等于乔木林面积、竹林面积与特殊灌木林面积之和。由延庆区二类调查数据可知,地类中无竹林地和特殊灌木林地,因此本研究中的森林面积只包括乔木林面积,森林蓄积量只包括乔木林蓄积量。按照《国家森林资源连续清查主要技术规定》(2014)地类划分标准,结合研究区实际地类情况,确定分类类别为乔木林地,其他林地(包括灌木林、疏林地、未成林造林地、苗圃地、迹地、宜林地),农地(耕地),建筑(建设用地),水域和其他土地(未利用地)等6类,对分类结果合并归类为森林和非森林2类,其中森林包括乔木林,非森林包括除乔木林之外所有的地类,最后对影像分类结果进行验证。结果表明:GF-1 PMS影像分类总精度达到87.90%,Kappa系数为0.75。分类结果见图2。
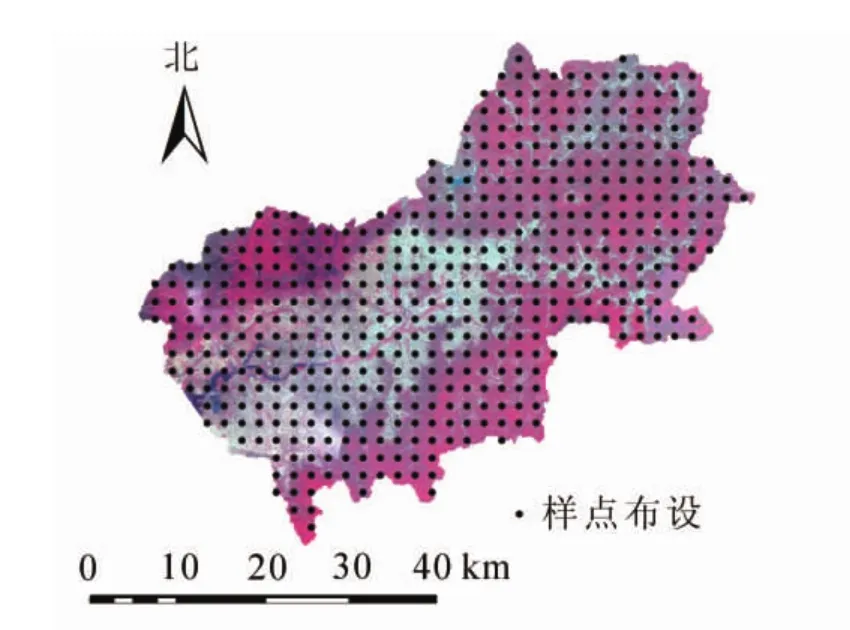
图1 延庆区GF-1 PMS影像(432假彩色)及系统布设抽样点(2 km×2 km)Figure 1 GF-1 PMS image of Yanqing District (432 false color)and sampling points of system layout(2 km ×2 km)
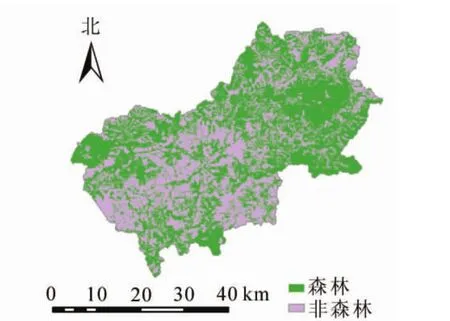
图2 GF-1 PMS影像分类图Figure 2 Classification result of GF-1 PMS image
2 研究方法
2.1 遥感特征变量
遥感影像的植被信息是通过绿色植物叶片和植被冠层光谱特性及其变化差异反映的[14]。选择合适的植被指数可以有效地增强植被信息或抑制非植被信息,减小非植被信息如阴影对模型构建的影响[3]。因此,本研究借鉴前人的经验并结合蓄积量估测特点,选择9种植被指数作为建模变量(表3)。
应用布设好的抽样点提取对应位置的GF-1 PMS影像光谱信息,计算样本内的光谱平均值作为样本点的光谱值,参与模型的构建。本研究中,蓄积大于0的抽样点均落在乔木林(即有林地)范围内,不包括散生木、四旁树和疏林地部分,因此所构建的模型为乔木林蓄积量模型,参与全区的森林蓄积量估算。
2.2 自变量筛选
在建模变量中,自变量往往存在多重共线性问题,导致所构建的模型不够稳定,尤其是在变量个数较多时,会降低模型的预测精度,因此选择适宜的方法筛选自变量用于建模具有重要作用[24]。常用的变量筛选方法较多,有逐步回归法、Pearson相关系数法、平均残差平方和法等[4,24-26]。相关研究表明:平均残差平方和法在变量筛选中具有很好的适用性[26],因此本研究选择此方法作为自变量筛选方法,平均残差平方和方法筛选变量的实现步骤参考文献[26]。
2.3 偏最小二乘回归法
偏最小二乘回归法是伍德(WOLD)和阿巴诺(ALBANO)于1983年提出的一种新型的多元统计方法。它集多元回归分析、典型相关分析和主成分分析的优点于一体,可以有效地解决多元回归分析中的变量多重相关性及噪声问题[27-29], 近年来被逐渐地应用到森林参数的估计上[3,30-31]。
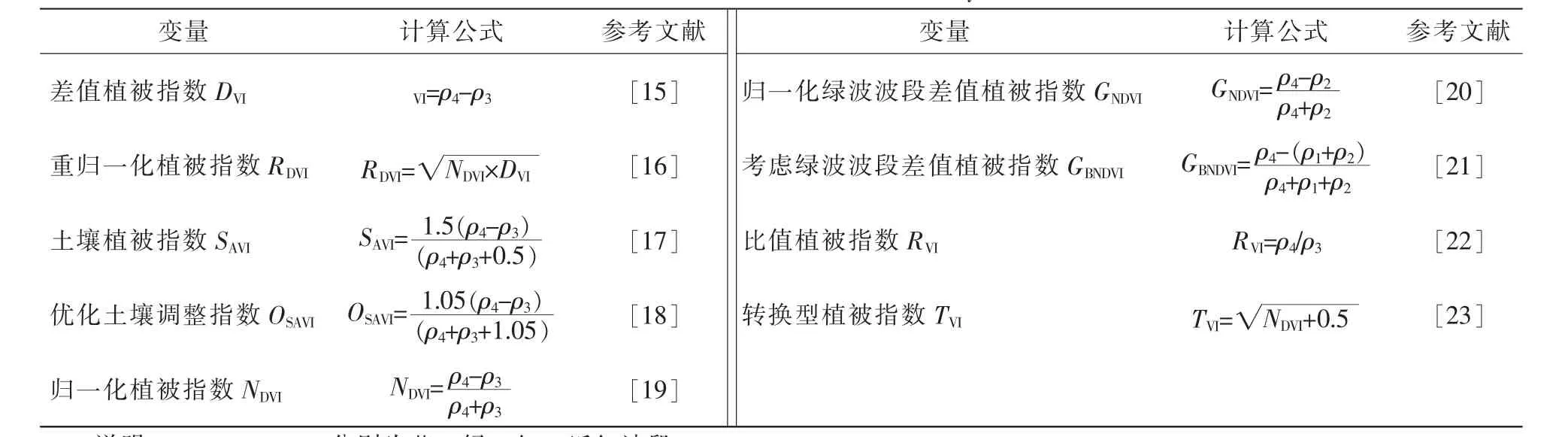
表3 研究中用到的变量Table 3 Variables used in the study
以单因变量为例阐述其基本建模思想:设有因变量y和p个自变量{x1,x2,…,xp},样本数为n,构成因变量和自变量的数据表y=[u]n×1和x[x1,x2, …,xp]n×p,对数据表x进行主成分处理,提取一个主成分t1(t1是x1,x2,…,xp的线性组合),要求t1尽可能多地携带x中的变异信息,同时与y的相关性最大,提取第1个主成分t1后,实施y和x对t1的回归,如果此时回归方程达到满意的精度,则算法停止,否则利用x和y被t1解释后的残余信息进行第2轮的主成分提取,如此反复,直到能达到较为满意的精度为止。若最终对x提取了m个主成分t1,t2,…,tm,偏最小二乘回归将实施y对t1,t2,…,tm的回归,然后表达成y对原变量x的回归方程。应用偏最小二乘回归法进行模型构建的详细过程见文献[9]。本研究应用MATLAB 2014a软件实现偏最小二乘回归模型的构建。
2.4 k-NN算法基本原理
k-NN算法是一种典型的非参数方法,基于观测点和预测点之间的空间相似性关系进行单变量或多变量预测(如蓄积量等森林参数),在欧洲和北美得到了广泛应用[32-34]。k-NN法用于森林参数估计的最大优点在于它不仅能同时估计若干个森林参数,而且它还能够维持参数之间的自然依赖结构,保持参数之间的一致性,同利用遥感自变量和森林参数建立的回归模型相比,k-NN方法更多地考虑森林参数同自变量间的非线性依赖关系[12,35]。其基本原理为:记p为目标点,pi为参考点,并且参考点的森林参数(本研究为森林蓄积量)是已知的,Dp,pi为目标点和参考点之间的光谱距离,它是用来衡量样本参数间的相似度的。对于目标点p,找出其光谱空间最邻近的k个参考点p1,p2,…,pk,其中Dp,1<Dp,2<…<Dp,k。由于目标点p受其近邻的影响是不同的,通常距离越近的参考点对其影响越大,反之则影响越小。目标点p的森林参数VP可以通过k个参考点的相应的森林参数Vpi(i=1,2,…,k)的加权平均法获得[12],其中k个参考点的权重wpi,p通过光谱空间的反距离函数获得[12]。k-NN实质上是一个常用于空间插值的反距离加权平均法,当k=1时,k-NN即为最邻近距离法[35]。

式(1)~式(2)中:t为距离分解因子,一般取值为0,1,2。光谱距离Dpi,p可采用多种距离进行度量,常用的有欧氏距离、马氏距离和光谱角制图等。在借鉴前人研究的基础上[12-13],选择t值为1,马氏距离作为距离度量标准,在确定最优波段的基础上,计算最优的k值用于全区森林蓄积量反演。本研究的k值是由MATLAB 2014a软件计算获得。
2.5 模型评价
选择留一交叉验证评价。模型估测精度采用均方根误差(ERMS),相对均方根误差(ERRMS),偏差(bbias)3个指标来评价,指标计算公式如下:

式(3)~式(5)中:yi为蓄积量实测值,y^i为蓄积量预测值,yi为蓄积量实测值平均值,n为样本个数。
3 研究结果
3.1 自变量筛选
利用平均残差平方和准则筛选出蓄积量估测的建模变量因子。由图3可知:经过变量优选,提取的SAVI,OSAVI,NDVI,GNDVI,GBNDVI,DVI可以得最小的平均残差平方和, 为 13.71。 因此选择SAVI,OSAVI,NDVI,GNDVI,GBNDVI,DVI共6个因子作为蓄积量模型构建的优选变量。
3.2 蓄积量估测模型构建
3.2.1 偏最小二乘回归模型构建 将筛选的自变量构建森林蓄积量估测模型,应用MATLAB计算模型的各个参数,最后得到基于偏最小二乘回归法构建的蓄积量估测模型,其数学表达式为V=0.809 5+0.017 5SAVI+0.025 8OSAVI+0.025 6NDVI+2.034 4GNDVI+3.545 9GBNDVI+0.001 5DVI。其中,V为森林蓄积量,SAVI,OSAVI,NDVI,GNDVI,GBNDVI和DVI为表 3 对应的植被指数。
3.2.2k值的确定k-NN方法的估测精度随着k值的不同而变化。相关研究表明[12,23,26]:k值取1~10的范围时,对不同参数的估测效果较好。本研究将k的取值范围设置为3~10,并对不同k值的估测结果进行分析,得到最优k值。由图4可知:当k值为7时,k-NN方法估测的均方根误差(ERMS)最小,为10.633 4 m3·hm-2。因此,本研究选取7作为蓄积量估测的最佳k值。
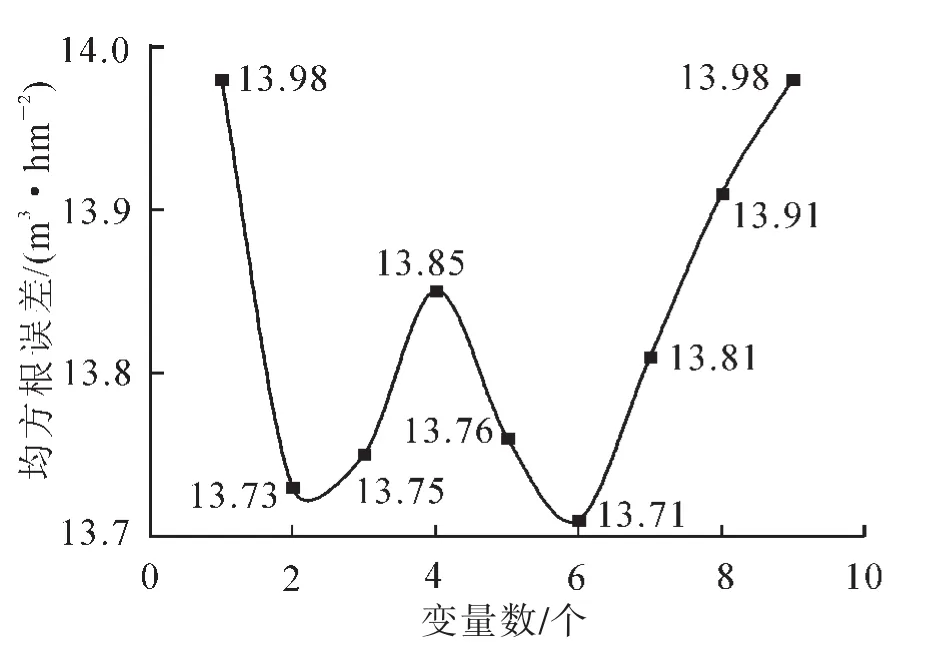
图3 建模变量优选Figure 3 Optimization of model variables
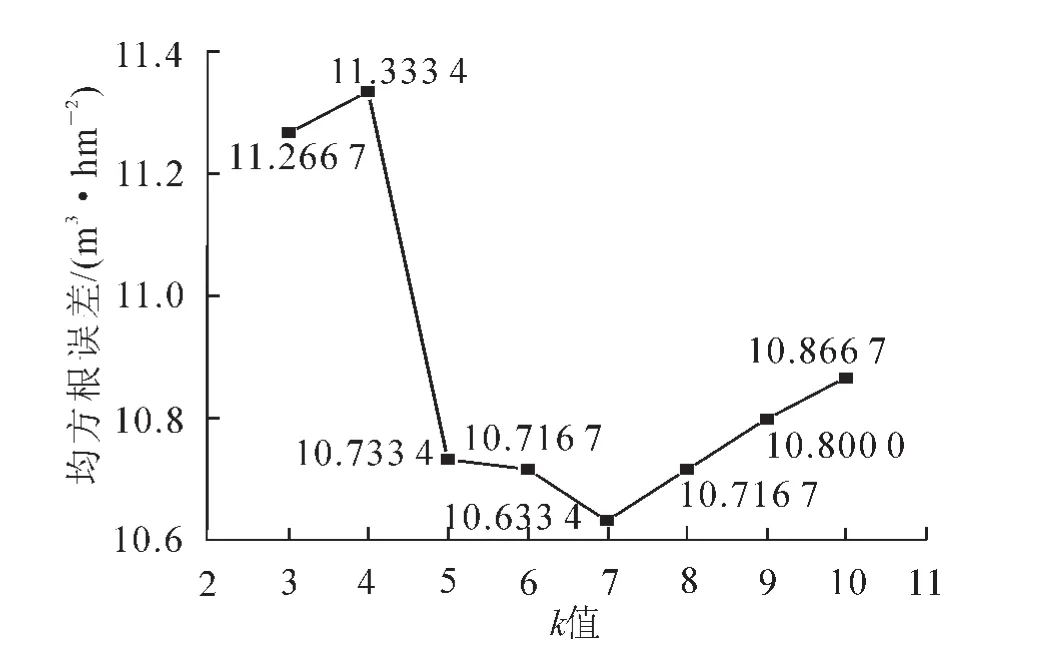
图4 均方根误差随k值变化的情况Figure 4 Situation of root mean square error with the different k values
3.2.3 模型验证 由表4可知:偏最小二乘回归法估测的森林蓄积量均方根误差为21.90 m3·hm-2,相对均方根误差为27.5%,偏差为17.23 m3·hm-2,基于k-NN方法的森林蓄积量估测的均方根误差为12.80 m3·hm-2,相对均方根误差为16.0%,偏差为 15.02 m3·hm-2。由此可知:基于非参数方法的k-NN方法估测效果要好于基于参数方法的偏最小二乘回归法,可作为延庆区森林蓄积量估测的方法。进一步对延庆区森林总蓄积量预测结果进行精度检验。以首都园林绿化政务网(http://www.bjyl.gov.cn/zwgk/tjxx/201604/t20160401_178533.html) 公 布的2015年延庆区森林蓄积量数据为实际值,对比分析基于2种方法反演的蓄积量预测值的差异(表5)。由表5可知:应用建立的偏最小二乘回归模型反演的森林蓄积量为266.22万m3,相对误差为50.45万 m3,估测精度为76.6%,应用k-NN方法反演的森林蓄积量245.98万m3,相对误差为30.21万m3,估测精度为86.0%。由此可知:基于k-NN方法反演全区森林蓄积量的估测结果要好于偏最小二乘回归法,估测结果可靠。

表4 2种估测模型的估测精度Table 4 Estimation accuracy of two models
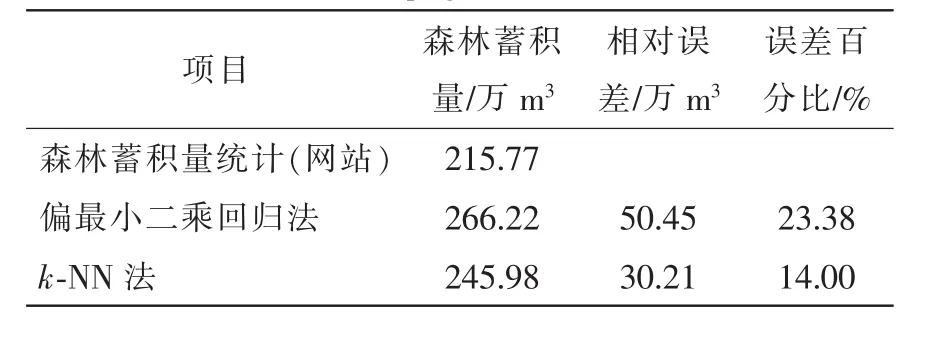
表5 延庆区森林蓄积量(FSV)估测误差比较Table 5 Comparison of estimation error of forest stock volume in Yanqing District
3.3 基于k-NN法的森林蓄积量反演
依据遥感影像分类得到的森林边界数据,应用k-NN方法建立的蓄积量估测模型对研究区森林蓄积量进行反演,得到延庆区森林蓄积量空间分布等级图(图5)。
4 讨论
基于偏最小二乘回归法的回归统计方法可以减少多重共线性的影响,提高模型构建的稳定性,保证估测的精度。以往的研究表明[3,27-28]:应用偏最小二乘回归法估测森林参数要好于其他常规的回归方法,可以在一定程度上提高待估参数的估测精度。k-NN方法作为一种典型的非参数方法,它不用考虑变量间的多重共线性的关系,具有一定的应用优势。本研究比较了这2种方法的估测效果,结果表明:在研究区内,基于k-NN方法的非参数方法的估测精度要好于基于偏最小二乘回归的参数方法,对全区森林蓄积量进行反演的估测精度达到86.0%。但本研究还存在以下问题:①研究应用的两景GF-1影像虽然只覆盖了很少的区域,但影像时相与其余影像时相存在差异,可能导致蓄积量估测结果产生偏差,但在本研究中忽略了其影响,此部分问题有待于进一步分析。②应用k-NN法进行蓄积量估测可以减少由影像的同物异谱和同谱异物带来的随机变化[11],但其高值低估和低值高估现象依旧是应用k-NN法基于像素级估测森林参数普遍存在的问题[11-12,35]。在本研究的估测过程中,随着k值的增大,蓄积量估计值分布空间呈现缩小的趋势。在后续的研究中,可考虑直方图匹配方[11]来提高k-NN法估测变量的精度。③本研究中的均方根误差随k值的增加呈现不规则的变化,这与KATILA等[37]和郑刚等[12]的研究中的均方根误差随k值的增大而减小的趋势不同。向安民等[23]应用GF影像估算森林蓄积量的研究中也出现了均方根误差随k值的增加出现不规则的变化趋势。这与GF影像上的椒盐噪声有很大关系,使得光谱信息与蓄积量值出现不匹配的现象,导致了均方根误差不规则的变化。
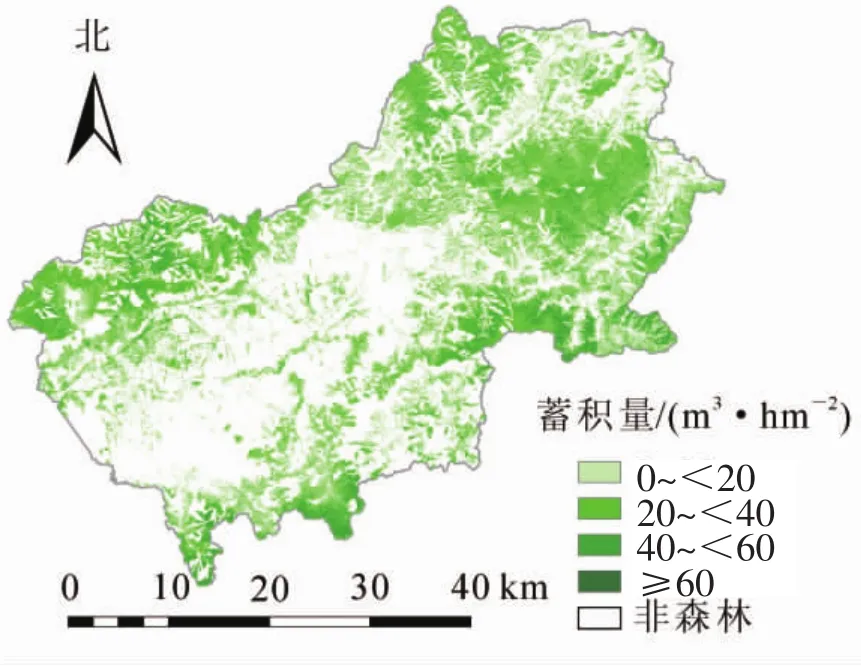
图5 延庆区森林蓄积量预测等级图Figure 5 Predicting map of forest stock volume in Yanqing District
5 结论
本研究应用GF-1 PMS影像数据提取了9种植被指数作为建模变量,采用平均残差平方和法对变量进行筛选,最终提取的SAVI,OSAVI,NDVI,GNDVI,GBNDVI和DVI等6个变量因子可以得到最小的平均残差平方和,作为蓄积量估测模型的变量。对比了偏最小二乘回归法(参数方法)和k-NN方法(非参数方法)估测森林蓄积量的效果。结果显示:k-NN方法的估测效果(均方根误差为12.80 m3·hm-2,相对均方根误差为16.0%,偏差为15.02 m3·hm-2)要好于偏最小二乘回归法(均方根误差为21.90 m3·hm-2,相对均方根误差为27.5%,偏差为17.23 m3·hm-2),并与首都园林绿化网公布的延庆区森林蓄积量结果进行了对比分析,基于k-NN方法反演的森林蓄积量估测精度达到86.0%,最后生成了延庆区森林蓄积量空间分布图。说明应用GF-1 PMS影像估测森林蓄积量是可行的。可以进一步在不同的县域范围应用GF-1 PMS影像估测森林蓄积量及相关的森林参数,对GF-1 PMS影像的估测潜力进行挖掘,这对推广应用国产GF-1 PMS影像具有重要意义。
6 致谢
感谢中国林业科学研究院资源信息研究所提供GF-1 PMS卫星影像数据。
猜你喜欢
中学生数理化·七年级数学人教版(2023年3期)2023-03-21 00:44:56
工会博览(2022年14期)2022-07-16 05:49:10
山东林业科技(2018年6期)2019-01-08 09:48:04
山东林业科技(2017年1期)2017-06-29 07:54:06
自动化学报(2017年2期)2017-04-04 05:14:28
教育家(2016年29期)2016-09-26 06:54:58
中学生数理化·七年级数学人教版(2016年2期)2016-05-30 21:20:57
林业与生态(2016年2期)2016-02-27 14:23:42
大众考古(2015年1期)2015-06-26 07:20:36
新高考·高二数学(2014年7期)2014-09-18 17:20:45
