
用于秸秆燃料热值估计的图像分析系统设计
2018-11-28 09:09,,,,
计算机测量与控制 2018年11期
, ,,,
(1.浙江工业大学 信息工程学院,杭州 310023; 2.嘉兴新嘉爱斯热电有限公司,浙江 嘉兴 314016)
0 引言
秸秆可以替代煤炭、石油和天然气等矿物质燃料产生电力,不仅减少人类对矿物能源的依赖,保护国家能源资源,而且通过严格控制秸秆的高效燃烧将有效降低我国PM2.5浓度,减轻能源消费给环境造成的污染[1]。目前欧美国家建立了较为完善的秸秆类农业废弃物燃烧发电厂,证明秸秆直燃发电具有显著的能源效益和环境效益,而且回收废弃秸秆增加了农民收入,从经济上保证农民不再乱烧秸秆,目前秸秆燃烧技术在我国发展十分迅速。
不同于煤炭、石油和天然气等矿物质燃料,不同品种和产地的秸秆具有不同固定碳、挥发份、水分、灰分等成分比例,加上回收时预处理手段和当地气候的影响,造成了秸秆燃料品质的差异很大。由于秸秆燃料品质的变化,导致燃烧单位质量秸秆的发热量也随之发生改变,这给秸秆燃烧发电循环流化床锅炉的燃烧效率控制和发电过程控制造成了不利的影响。因此,在实际秸秆燃烧发电过程中,为了更好的控制秸秆循环流化床锅炉燃烧效率,提高秸秆燃料的发电效率和发电安全性,需要对送入循环流化床锅炉燃烧发电的秸秆燃料进行热值计量操作,并将计量结果及时反馈给秸秆燃烧发电过程控制系统。
目前秸秆燃烧发电过程燃料热值计量方法仍然采用化学检验方法为主[2], 在秸秆燃料购买后进厂入库时取样,然后烘干秸秆燃料样本,收集蒸发的水蒸气,得到秸秆燃料的含水率,再燃烧烘干的秸秆燃料样本,结合用化学试剂测定的成分组成,建立样本绝干料的热值,进而计量本批次秸秆燃料的热值。但目前这些方法和装置不能实现燃烧发电的所有秸秆燃料的热值的在线计量,而且操作周期长,应用过程复杂,计量实效性低,远远不能满足现代秸秆燃烧发电过程的高品质燃烧控制要求。因此,近年来相关学者对于这个具有挑战性的难题做了一些探索性研究,以满足现代秸秆燃烧发电过程对秸秆燃料热值的在线实时计量的迫切需要[3]。
本文结合秸秆燃烧发电过程中的实际需求,设计了一套针对秸秆燃料热值在线实时计量的图像分析系统。不同于传统的化学检验方法,本系统定制了一套基于深度学习U-Net[4]网络的图像分割算法来实现秸秆燃料分类功能,更进一步地,良好的分类结果为秸秆燃烧发电过程中的热值估算以及后续的燃料量的在线自动调整控制提供了参考依据。
1 系统硬件设计
根据秸秆燃料图像分析系统的设计需求,本文设计的系统框架如图1所示。
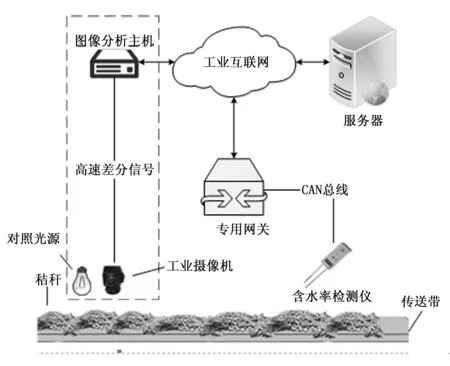
图1 秸秆燃料图像分析系统框架
系统包括工业摄像机、图像分析主机、服务器和工业互联通信网络总线、含水率检测仪,其中含水率检测仪本文不作任何介绍,但最后的含水率参数通过工业互联网返回给主机用于在线计算燃料热值。
图像分析系统硬件设计如图1虚线框所示,主要包括工业摄像机和图分析主机两部分。
1.1 工业摄像机的设计
工业摄像机的设计主要包括ISP处理板和摄像头板两部分。
ISP处理板选用TI公司开发的针对高清视频处理的高性价比DaVinci系列多媒体处理器DM365,主频最高可达300 MHz,芯片内部包含一个视频处理子系统,有独立的视频处理前端和视频处理后端组成,提供了成熟的图像处理功能,能够针对多种类型的图像传感器进行图像质量上的优化。
摄像头板选用Aptina公司的CMOS传感器 AR0135搭配M12接口,焦距为6 mm的定焦镜头,最大图像传输率能达到720p@60fps,采用全局曝光的方式,能够有效地避免因传送带快速运动而引起的“拖影”和“果冻现象”,进而拍摄出清晰的秸秆燃料图片。
此外,经过ISP处理后的图像数据通过一根双绞线以串行的方式传送至图像分析主机。
1.2 图像分析主机的设计
图像分析主机的设计主要包括核心板以及接口板两部分。
1.2.1 图像分析核心板的设计
图像分析核心板采用TI公司的一款浮点双DSP C66x+双ARM Cortex-A15工业控制及高性能音视频处理器AM5728。
AM5728处理器最高主频为750 MHz(DSP)+ 1.5 GHz(ARM),ROM为4 G/8 GByte MMC,片上 L3 RAM 高达2.5 MB,双 DDR3/DDR3L 存储器接口 (EMIF) 模块,最高支持 DDR3-1066,每 EMIF 支持高达 2 GB。支持全高清视频(1080P@60fps),多个视频输入和视频输出,具有 DMA 引擎和多达 3 条管线的显示控制器。同时拥有丰富的外设接口:集成千兆网,PCIe,GPMC、USB、UART、SPI、SATA、I2C、DCAN及工业控制总线等接口。
此外,核心板体积极小,大小仅为80 mm×70 mm,底部为工业级精密B2B连接器,0.5 mm间距,稳定,易插拔,防反插,关键大数据接口使用高速连接器,保证信号完整性。核心板是最主要的信号处理分析核心,高速信号分布密集,采用了十层板层叠设计,同时预留一大块裸铜散热区。
1.2.2 图像分析接口板的设计
图像分析接口板,主要负责与外设进行交互。板上除了常用的HDMI,USB,SATA,UART接口外还集成了4 G模块,用于连接工业互联网,以达到和系统中的其他设备进行通信的目的。
4 G模块选用一款Neoway的基于高通平台的 4 G 全网通工业级模块N720,搭载ARM Cortex-A7处理器,具有超宽工作温度低至-40℃高至+85℃,静电能力达到 8 KV;支持国内移动/联通/电信三大运营商的2 G/3 G/4 G 网络制式。N720通过USB虚拟串口与主控芯片AM5728进行通信。
2 系统软件设计
在硬件系统的基础上,软件开发需要完成的任务包括各模块的驱动编写、图像的采集和处理、工作状态的检测、训练标注平台的设计、图像分割算法的实现以及秸秆热值的计算。图像分割算法和秸秆热值估算将单独在后两小节实现与分析。整个系统的运行流程如图2所示。

图2 系统运行流程
2.1 ISP图像处理
图像传感器经过曝光得到的图像数据为原始数据(Raw Data),由于保存的图像信息量较大,无法直接传递给后续算法处理,所以需要经由ISP处理[5],在格式上,质量上对图像进行优化。ISP图像处理主要流程如图3所示。

图3 ISP处理流程
2.2 工作状态检测算法
本系统利用了感知哈希算法[6]计算并比较图像的相似度来检测运送秸秆燃料的传送带是否处于工作状态,同时根据工作状态来关闭图像分析系统中的一些功能模块,进入待机模式,等待下一次工作,以此降低整个系统的功耗和网络流量消耗。工作状态检测算法的流程如图4所示。
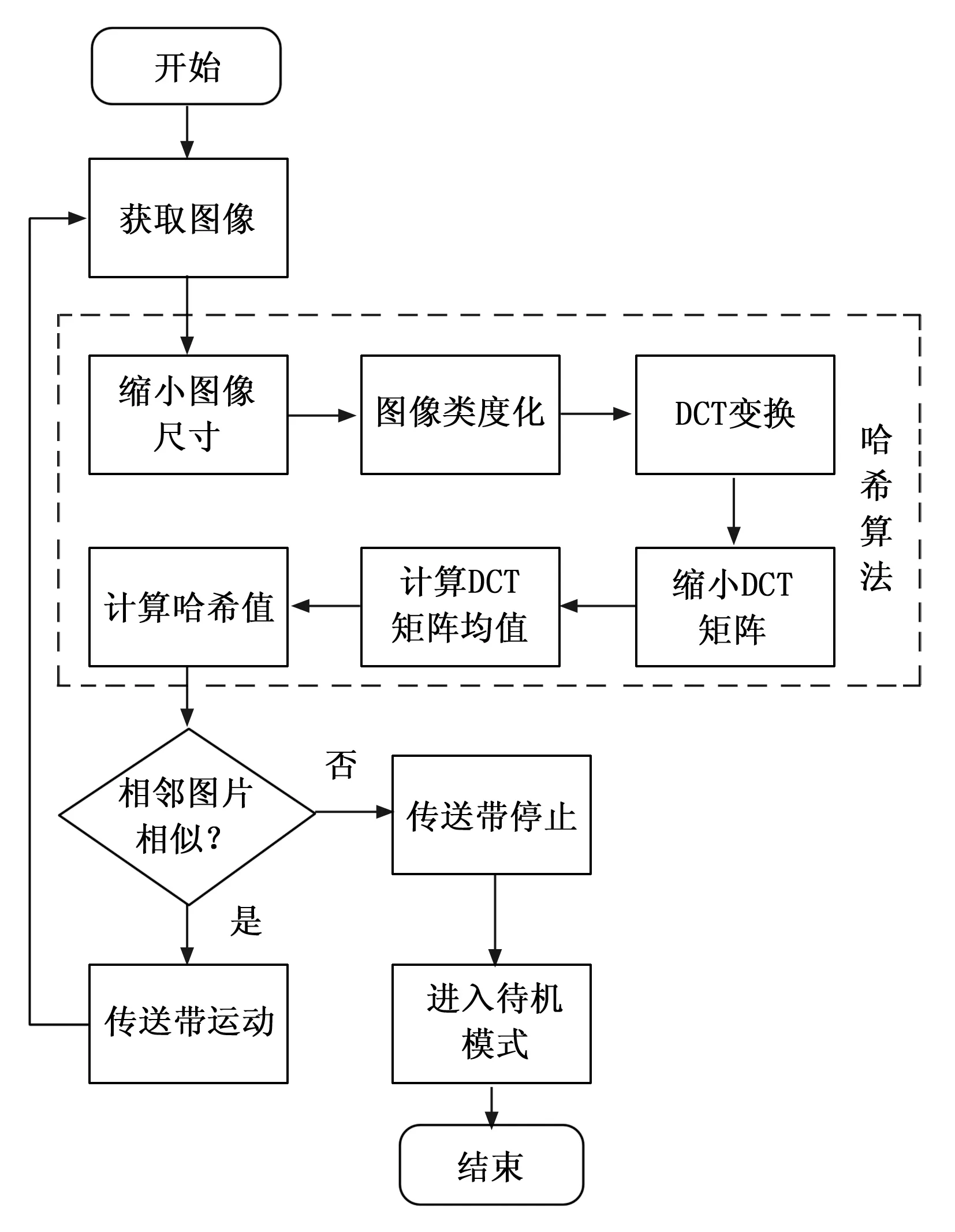
图4 系统运行流程
本系统在算法中通过DCT变换,利用DCT低频系数之间的相关性构造哈希[7]。通过计算8x8DCT的矩阵的均值与64个数进行比较,大于等于DCT均值设为1,小于DCT均值的设为0。最后得到一个64位的哈希值作为每一张图片的“指纹编码”,通过比较这个“指纹编码”来比较两张图片的相似度,进而判断工作状态。
2.3 训练标注平台
训练标注平台用ruby on rails框架开发。结构如表1所示,主要由数据存储模块、任务管理模块、标注功能模块、登录管理模块、标签组管理模块、训练管理模块组成。

表1 各模板类别识别时间
为了方便拓展,训练标注服务器被设计成分布式结构,其架构如图5所示。

图5 标注训练服务器分布式架构
标注平台首先将用户或者设备上传的图片数据按照不同的标签组标识的任务分发给不同的标注人员,形成标注队列,当用户标注提交任务完成后,返回给平台形成审核队列,当分发任务人员审核通过后,即可发布训练任务,形成一个训练队列,由训练服务器轮询认领任务。
Master程序主要实现任务认领,下载相关的图片数据包,返回训练进度,Worker程序主要用于训练,生成训练结果,当Worker程序训练完成时,会通知Master程序将训练结果返回给平台,在训练平台中形成训练结果队列,以供给用户展示结果。
3 分割算法
在燃料秸秆的分割算法中,核心算法主要由两个部分组成:图像数据增强算法和语义分割算法。图像数据增强是指对现有的图像数据进行各种变换操作,以达到数据扩展的效果。语义分割是将采集到的图像输入到U-Net改进网络中,先集后经过编码器、解码器、归一化等多种操作得到语义分割图像。
3.1 图像数据增强算法
深度学习是基于数据的算法,数据越多,其效果就越好,并且数据集越大,模型过拟合的可能就越小,可以说是有百利无一害。而由于语义分割的数据集标注成本较高,故我们引入了数据增强算法来对已有的标注数据集进行扩张。
3.1.1 随机修剪
随机裁剪就是指在原图像上随机裁剪指定大小的图片用于训练,假设原始图像为256×256,裁剪得到224×224的图片进行输入,这可以使我们的数据集扩张1024倍。设定一个图片大小,在原始数据集上的随机位置裁剪下该大小的图片用于训练。本系统设定的裁剪大小为 512×512。
3.1.2 PCA Jittering
首先按照RGB三个颜色通道计算了均值和标准差,对网络的输入数据进行规范化,随后我们在整个训练集上计算了协方差矩阵,进行特征分解,得到特征向量和特征值,用来做PCA Jittering[8]。对秸秆燃料数据集做PCA jittering的效果如图6所示。

图6 施加PCA jittering效果图
PCA jittering是利用主成分来给RGB像素值加偏差的处理方式,PCA jittering操作就是在训练数据上执行PCA找到主成分,然后为每个训练图像添加多个找到的主成分。
3.2 语义分割算法
语义分割[9-10]是整个系统的核心,通过深度学习方法来对秸秆燃料进行分割,以分割的结果计算得到秸秆的占比,最后通过占比和各组分的热值估算出当前燃料堆的热值是本算法研究的主要方向。
尽管我们采用了图像数据增强来对数据集进行扩张,但是由于,其场景比较单一,各张图片内容会比较相似,所以实际数据集还是会偏小。因此我们选择U-Net结构作为算法的核心架构。U-Net结构的网络在小数据集上也能训练得到一个较好的模型,并且相对于逐像素点分类的其他网络,其网络速度更快。
3.2.1 网络结构
原始的U-Net网络[4]在编码器侧使用了典型的卷积[11-12]网络架构,每次重复两个卷积层和一个池化层,深度略显不足,而深度可以使模型拟合能力指数增长[13]。
编码器部分主要是为了提取图片的特征,而图像分类网络在图片特征提取方面的效果非常不错,谷歌最近发布的Mobilnet V2[14]是一个轻量网络,在速度上超过了许多网络,并且效果很好,所以我们选择MobileNet V2网络来作为编码器。优化后的的网络结构如图7所示。图片输入网络后的步骤描述如下:

图7 U-Net网络结构
步骤一:对输入进行卷积得到特征图。
步骤二:复制一份特征图,对其中一份特征图继续前向卷积操作,保留另一份准备进行copy操作。
步骤三:重复步骤一、二4次。
步骤四:将前向得到的特征图同之前保留的特征图融合并进行卷积操作,重复4次。
步骤五:得到最后的输出图。
一般而言,卷积层越多,提取的特征越高级,即从提取线慢慢变成提取物体特征,具体提取的效果可以由网络根据给定数据自动拟合
3.2.2 Loss函数
损失函数是用来评估预测结果与真值之间的差异程度,损失值越小,说明模型的效果越好。这里我们采用交叉熵函数作为网络的loss函数。
交叉熵损失函数公式如式(1)所示:
(1)
其中:n为训练数据的个数,x为训练输入,y为期望的输出,a为实际的输出。其导数公式如式(2),式(3)所示:
(2)
(3)

根据导数可以看出,在使用交叉熵作为损失函数时,权重的学习速率可以被控制,也就是可以被结果的误差控制。那么当误差大的时候,权重更新就快,当误差小的时候,权重的更新就慢。
3.2.3 优化算法
优化算法主要是通过改善训练方式来帮助模型最小化损失函数。我们选择Adam算法[15]作为网络训练的优化算法。Adam算法是在深度学习领域非常流行的算法,是一种可以替代传统SGD算法的优化算法,它能计算每个参数的自适应学习率,在非凸优化问题中有着许多优势。
4 热值估算
在以下估算过程中,为方便叙述,将秸秆燃料主要分为三类:小麦秸秆、玉米秸秆、木头。
计算步骤如表2所示。

表2 秸秆燃料热值估算步骤
4.1 占比计算
4.1.1 表面积占比
用数据增强后的秸秆燃料数据集来训练网络,训练1 000个epoch后得到可以使用的语义分割模型。将秸秆图像输入模型,得到一张的特征图,不同维度预测的是不同种类物体的位置信息。我们将同位置不同维度的像素值大小视为该维度代表的种类的置信度,根据每个点在所有维度上的像素最大值的维度值,得到秸秆分割图,即一张的特征图。
P(m,n)=arg maxi(F(m,n,i))
(4)
其中:m,n表示坐标信息,i表示输出特征图的第i维,P(m,n)代表坐标(m,n)的像素值,F(m,n,i)表示在(m,n,i)位置的像素值。
对于处理得到的特征图,每一个像素值就代表一种物体。在本文中,0代表小麦秸秆,1代表玉米秸秆,2代表木头,3代表背景。最后我们通过统计不同像素值的个数做计算得到各个物体的占比。
4.1.2 总体占比估算
通过分割算法得到的占比仅仅是表面积占比,不代表总体占比。在实际应用中,我们不需要每隔几秒就反馈一次占比给控制系统,因此针对燃料堆放不均匀,上下层次混乱等问题,本文通过累加法计算一段时间内的平均占比来降低随机性,以此提高估算的精度。时间T的取值过小,过大都会影响系统的稳定性。

(5)
4.2 含水率问题
除了占比的问题,实际热值估算中还需要考虑含水率对热值的影响。
由于秸秆燃料的库存量通常很大,而且存放周期也较长,因此即使是同一批次秸秆燃料,经过长时间存放后,由于含水率的变化它们的燃烧热值都将发生很大的改变和不同。
通过含水率检测仪在线测量秸秆燃料的含水率并返回给图像分析主机,读取服务器中对应秸秆燃料的成分组成和组分的热值[3],采用秸秆热值计算公式计量秸秆燃料的热值,热值计算公式参见式(5):
Q=q(1-0.01w)-a1w
(6)
其中:Q表示单位质量某一类秸秆燃料的热值,单位J/kg;w表示当前时间段内秸秆燃料的含水率,单位%;q表示秸秆燃料的决干料的热值,单位J/kg,计算参见式(6):
q=a1qC+a2qH+a3qS+a4qN-a5qO
(7)
其中:qC、qH、qS、qN和qO分别表示秸秆燃料中中碳、氢、硫、氮和氧的质量含量,单位%;系数a1、a2、a3、a4和a5分别表示对应秸秆燃料中对应成分的单位质量的热值,单位J/kg。
4.3 热值估算公式
综上所述,结合平均占比计算公式和热值估算公式得到一段时间T内总热值的估算公式如式(7)所示:
(8)
5 系统测试
5.1 分割效果
输入测试集到U-Net网络中,得到特征图,以像素值来区分不同的类别。在本实验中,像素值0代表小麦秸秆,1代表玉米秸秆,2代表木头,3代表背景,由于不同的像素值在视觉上无法给人直观的感受,所以我们对像素值进行了编码,将4个像素值以不同的RGB值映射到图片中。其中,黑色为小麦秸秆部分,红色为玉米秸秆,绿色为木头,黄色为背景。效果展示如图8所示。

图8 分割算法效果图
5.2 算法性能测试
本文对基于改进U-Net网络的分割算法进行了量化测试,分别以150张人工标注过的图片和300张人工标注过的图片作为训练集对算法进行训练,挑选30张为训练图片进行测试,计算每一种成分的平均精度,平均重合度,结果如表3,表4所示。
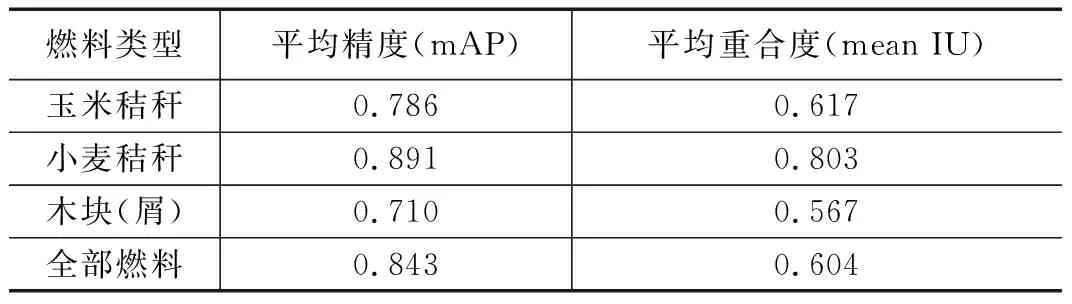
表3 训练集为150的算法性能
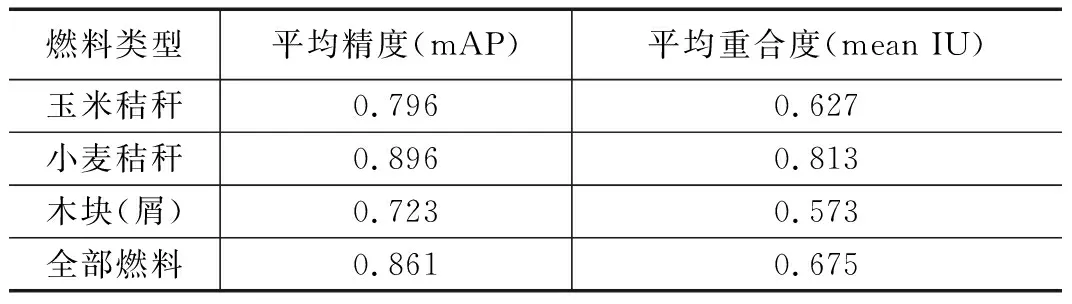
表4 训练集为300的算法性能
通过比较,可以明显的得知几个结论:
1)小麦秸秆的分割效果最好,玉米秸秆次之,木块的分割效果较差。
2)训练集的大小影响分割效果,一般而言,训练集越大,分割效果越好。
3)训练集中每种成分的多少也会影响最后的分割效果,例如训练集里小麦秸秆比例大,所以最后小麦秸秆的分割效果最优。
4)平均精度和平均重合度越大,分类结果越准确,最后得出的热值估值也就越精确。
6 结束语
本文针对秸秆燃料燃烧发电时的实际需求,设计了用于秸秆燃料热值估计的图像分析系统,先后介绍了该系统的硬件和软件系统,加入了传送带工作状态的检测机制,设计了用于标注训练秸秆数据的平台,提出了基于改进U-Net网络的图像分割算法,并通过大量实验验证了该算法的精确度。系统测试结果表明,在训练集大于300以上时,算法的平均精度达到0.86以上,平均重合度达到0.68左右,算法稳定性和适应性较好,能根据秸秆燃料的成分不同,训练出不同的模型。
但是由于秸秆燃料堆放不均匀,层次复杂等问题,得到的表面积占比不足以代表最后的占比,后续将针对如何选择一个合理的T值使秸秆燃料占比估算的过程最优化进行研究,并结合实际应用场景,基于大量实验数据,给出一个合理的时间阈值T,优化整个系统的精确度。
猜你喜欢
林业与环境科学(2022年2期)2022-07-12
昆钢科技(2022年2期)2022-07-08
英语文摘(2021年8期)2021-11-02
小学科学(学生版)(2021年5期)2021-07-22
军事文摘(2020年14期)2020-12-17
今日农业(2020年19期)2020-11-06
吉林农业(2019年20期)2019-11-23
建材发展导向(2019年10期)2019-08-24
中国新技术新产品(2016年19期)2016-12-12
安全(2015年7期)2016-01-19
