
中国二氧化碳排放峰值的情景预测及达峰特征
——基于粒子群优化算法的BP神经网络分析
2018-11-26 03:30:16段福梅
东北财经大学学报 2018年5期
段福梅
(东北财经大学 统计学院,辽宁 大连 116025)
一、 问题的提出
近年来,随着中国在全球经济体系中的地位愈加重要,能源消耗量和温室气体排放量更是迅速增长。为了积极应对全球气候变化,推动世界各国切实采取措施降低二氧化碳排放,2014 年11 月12 日,中国政府与美国政府在北京联合发表了《气候变化联合声明》,声明提出:“中国计划2030 年左右二氧化碳排放达到峰值且将努力早日达峰,并计划到2030 年非化石能源占一次能源消费比重提高到20%左右。”这个目标在2015年中国向联合国提交的“国家自主决定贡献”及气候变化巴黎大会中都得到了重申。二氧化碳排放达到峰值既体现着中国经济的发展方式发生了根本转变,也意味着国内资源限制和环境污染状况得到积极的改善,低碳技术达到更高水平,更是粗犷的发展方式向绿色低碳转型的重要标志,这将会对中国经济和社会产生重大而深远的影响。
以中国实现碳排放达到峰值的宏观目标为背景,碳排放达峰预测也得了学术界的广泛关注。二氧化碳排放峰值预测包括预测模型和情景设计,预测模型有STIRPAT模型、IAMC模型、IPAT模型、GPR模型、灰色预测模型、时间序列分析和组合模型等,情景设计依据目前已有研究、政策对未来经济、社会和技术发展路径的预期,通过赋予模型参数不同数值实现,将参数输入模型,进而进行碳排放预测,由于所使用的模型和考虑的情景不同导致得出的结论也不同。邓小乐和孙慧[1]运用STIRPAT模型预测西北五省区碳排放峰值,研究发现在碳排放下降速度与经济发展不能同步增长时,2030年前不能出现峰值;渠慎宁和郭朝先[2]运用STIRPAT模型预测中国碳排放峰值,研究发现技术对峰值的影响较为重要;柴麒敏和徐华清[3]运用IAMC模型对中国碳排放总量控制和峰值的四种路径及情景进行深入分析,得出了碳排放出现峰值需要的条件;席细平等[4]运用IPAT模型研究发现在经济社会发展的同时保持能源强度和碳排放强度合理下降,江西省的碳排放峰值到达时间约在2032—2035年;聂锐等[5]运用IPAT模型与情景分析相结合,研究发现低碳情景是江苏省发展最现实、最合适的方案;方德斌和董博[6]运用GPR模型预测中国“十三五”时期碳排放趋势,研究表明与其他方法相比,GPR具有明显的精度优势,中国能够实现2020年碳排放强度较2005年下降40%—45%的目标;纪广月[7]首先利用灰色关联法筛选指标,其次运用BP神经网络预测中国碳排放,达到了良好的预测效果,预测相对误差小于1%;赵成柏和毛春梅[8]运用ARIMA和BP神经网络组合模型预测中国碳排放强度,碳排放强度的时间序列的数据结构分解为线性和非线性残差部分,预测中国没有达到2020年碳排放强度较2005年下降40%—45%的目标;Dietz和Rosa[9]运用IPAT模型和环境库兹涅茨曲线,利用131个国家的截面数据,研究发现碳排放总量在人均 GDP 轴上呈现倒U型。
目前关于中国碳排放达峰的研究为碳排放峰值预测提供了较好的研究方法和研究思路参考。同时,大部分研究主要基于传统计量模型进行碳排放峰值预测,而二氧化碳排放的影响是一个复杂多变的非线性系统,传统计量模型在预测二氧化碳排放峰值时受到模型选择、变量选取和参数估计等影响,造成预测精确性较差。BP神经网络具有很强的非线性、自组织、自学习能力,能够很好地处理非线性信息[10]。目前BP神经网络在汽车车速预测[11]、交通流量预测[12]、房价预测[13]、气象预报[14]等方面应用广泛,而很少有研究利用BP神经网络预测二氧化碳排放。因此,本文利用BP神经网络预测二氧化碳排放峰值,并对不同情景模式下二氧化碳排放达峰特征进行分析。
二、二氧化碳排放影响因素的筛选
(一)数据来源
二氧化碳排放受人口、经济发展、能源消费和科技进步等方面的影响,本文初步选取的影响因素为:人口(万人)、人均GDP(元/人)、城市化率(%)、工业增加值比重(%)、非化石能源消费量比重(%)、能源强度(吨标准煤/万元)和研发强度(%)[1],其中研发强度是全国技术市场成交额占GDP的比重。
本文选取1988—2014年的数据,数据来源于《中国统计年鉴》《中国能源统计年鉴》和国家统计局网站。人均GDP是以1988年为基期计算的实际GDP;能源强度中的GDP是以1988年为基期计算的实际GDP,二氧化碳排放量是根据相关公式计算得出。
目前中国80%以上的二氧化碳排放来自于能源消费的排放,已有研究大部分将地区能源消费总量造成的二氧化碳排放量作为该地区实际的二氧化碳排放量[4]。本文也将中国化石能源煤炭、石油、天然气排放的二氧化碳作为中国实际的二氧化碳排放量。计算公式为式(1):
(1)
其中,煤炭、石油、天然气的碳排放因子采用席细平等[4]、方德斌和董博[6]以及赵成柏和毛春梅[8]研究中使用的碳排放因子的平均数,即煤炭燃烧过程碳排放因子为0.7276,石油燃烧过程碳排放因子为0.5666,天然气燃烧过程碳排放因子为0.4367。
(二)二氧化碳排放影响因素的筛选——基于灰色关联分析
灰色关联主要考察参考序列与若干比较序列的曲线相似程度确定联系紧密程度[15],故本文可使用灰色关联分析法确定与二氧化碳排放联系紧密的影响因素,参考序列为二氧化碳排放量,具体步骤如下所示:
第一步,对各变量进行无量纲化处理。对人口、人均GDP、城市化率、非化石能源消费量比重和研发强度用式(2)变换,对工业增加值比重和能源强度用式(3)变换。

(2)

(3)
其中,Xi={Xi(1),Xi(2),…,Xi(n)},i=0,1,…,7,X0为二氧化碳排放序列。
第二步,计算参考序列与比较序列的关联系数和关联度,分别为式(4)和式(5):

(4)
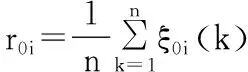
(5)
其中,ξ0i(k)为参考序列与比较序列在某一时刻的关联系数,ρ为分辨系数,一般取0.5;r0i为参考序列与比较序列之间的关联度。
根据上述步骤计算出的二氧化碳关联度分别为人口(0.7132)、人均GDP(0.8875)、城市化率(0.8982)、工业增加值比重(0.6104)、非化石能源消费量比重(0.7998)、能源强度(0.7082)、研发强度(0.8017)。将影响二氧化碳排放的各因素的关联度由大到小排列为:城市化率、人均GDP、研发强度、非化石能源消费量比重、人口、能源强度、工业增加值比重。最终选取城市化率、人均GDP、研发强度、非化石能源消费量比重、人口、能源强度作为影响二氧化碳排放的主要因素。
三、中国二氧化碳排放峰值预测模型
(一)BP神经网络基本原理
BP神经网络能学习和存贮大量的输入—输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用梯度下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP神经网络模型拓扑结构包括输入层、隐含层和输出层,可以将BP神经网络看成一个非线性函数,网络输入值和输出值分别为该函数的自变量和因变量。典型的BP神经网络是含有一个隐含层的神经网络结构。根据BP神经网络模型的拓扑结构,设置本文二氧化碳预测模型,具体步骤如下:

第二步,网络的初始化。输入层、隐含层、输出层之间的连接权值wij、wjk,隐含层阈值a,输出层阈值b,其初始值由网络随机给定;初始学习率η(0)=0.1,误差精度ε=0. 001%,迭代次数M0=100;激励函数、传递函数、输出函数选用系统默认设置。
第三步,输入样本和测试样本的确定。本文将1988—2010年数据作为训练样本,2011—2014年数据作为测试样本,为消除样本数据的差异,需要对数据归一化处理,处理后的数据取值范围为[0.1,0.9],具体公式为式(6):

(6)
其中,xij第i个影响因素的第j个观察值,xmax、xmin分别为第i个影响因素的最大值和最小值。
第四步,网络拓扑结构的确定。高玉明和张仁津[13]通过比较在相同样本集和训练次数下各隐含层节点的均方误差值,选取均方误差值最小的网络进行仿真测试。本文选取迭代次数为3次。
当n1=7或12时,网络训练后的均方误差值很小,但当n1=7时,BP神经网络陷入局部最优,故确定隐含层节点数n1=12,即确定的网络拓扑结构为6-12-1。
第五步,根据确定的网络结构进行网络训练,训练结束后对测试样本进行仿真测试,预测二氧化碳排放量。
(二)中国二氧化碳排放预测的模型训练和仿真测试——基于BP神经网络
使用Matlab进行BP神经网络的构建、训练和仿真测试,经过多次训练,将预测值和实际值的相对误差较小的网络为作为最优网络模型,即确定了最优的连接权值和阈值,使用该网络对二氧化碳排放量进行预测。仿真预测结果如表1所示。
表1 BP神经网络仿真预测结果

年 份实际值(亿吨)预测值(亿吨)相对误差(%)201188.849383.7103-5.7839201290.786591.05550.2962201393.319092.1903-1.2096201494.034793.2752-0.8078
由表1可知,2011—2014年预测的平均相对误差仅为2.0244%。本文对1988—2014年二氧化碳排放的实际值和预测值进行Mann-Whitney检验和Kolmogorov-Smirnov检验,P值均大于0.8000,远大于显著性水平,则两样本中位数无差异,显示了由模型得到的预测值与实际值非常接近,表明模型的拟合效果较好。
基准BP神经网络也存在一些缺陷和不足:首先,网络的收敛速度慢,需要较长时间训练;其次,BP算法会使误差为局部最小值,而不是全局最小值,造成网络训练达到全局最优的假象。而粒子群优化算法能对BP算法进行优化,克服基准BP神经网络的缺点。
(三)基于粒子群优化算法的BP神经网络原理
粒子群优化算法(PSO算法)用于求解优化问题。算法中的每个粒子代表问题的一个潜在解,粒子的特征由位置、速度和适应度值来表示,每个粒子对应一个由适应度函数决定的适应度值,其值的好坏代表粒子的优劣[16]。
将粒子群优化算法应用于BP神经网络,具体算法流程为:确定待优化BP神经网络的拓扑结构、初始权值和阈值;对初始权值和阈值进行编码,编码方式有两种,即向量编码和矩阵编码,本文采用向量编码,假设有N个待优化的权值和阈值,即群体中的每个粒子被编码成由N个权值和阈值构成的N维向量;将训练得到的误差指标函数值作为适应度函数值;计算每个粒子的适应度值;将每个个体的适应度值与其相应个体极值的适应度值进行比较,如果更优则将其作为个体极值;将每个个体的适应度值与全体极值的适应度值进行比较,如果更优,则将其作为全局极值;更新粒子的速度和位置;当满足终止条件时,将粒子解码,得到最优权值和阈值并赋给神经网络;对BP神经网络进行训练。
(四)中国二氧化碳排放预测的模型训练和仿真预测——基于粒子群优化算法的BP神经网络
根据设置好的参数,将训练样本输入对网络进行训练,粒子在迭代寻优过程中的适应度随着进化代数逐渐减小,进化45次以后适应度值达到最小,说明粒子群优化算法具有较强的寻优能力。通过粒子群优化算法优化后,进行网络训练和仿真测试,具体结果如表2所示。

表2基于粒子群优化算法的BP神经网络仿真预测结果
由表2可知,2011—2014年预测的平均相对误差仅为0.9736%,低于BP神经网络预测的相对误差。由该模型得到的预测值与实际值非常接近,同样由两独立样本检验得两组数据没有显著差别,说明网络的泛化能力强,也表明该模型的拟合效果优于BP神经网络。
为了验证粒子群算法优化BP神经网络的优势,本文选取了GM(1,1)、STIRPAT模型(分别运用岭回归、偏最小二乘回归)两种预测模型作为对照,这三种模型同样使用1988—2010年数据进行训练,对2011—2014年的二氧化碳排放量进行预测,结果如表3所示。由表3可知,神经网络的预测精度高,因而基于粒子群算法优化的BP神经网络能更准确地预测二氧化碳排放量。

表3不同预测模型的预测值及相对误差
四、中国二氧化碳排放峰值的情景设定
通过建立基于粒子群优化算法的BP神经网络模型,结合情景分析法就可以预测未来二氧化碳排放量。本文参考谌莹和张捷[17]设置情景的方法,将影响二氧化碳排放的各因素的预测结果分为高、低两种情景,如表4所示。在对各因素预测时参考中国已发布政策及未来发展目标,使预测结果尽可能准确。本文以2015年为预测基础年,预测周期设置到2050年,分为七个阶段[18],分别为:2016—2020年、2021—2025年、2026—2030年、2031—2035年、2036—2040年、2041—2045年和2046—2050年。

表4 2016—2050年各变量的发展速率 单位:%
第一,人口。中国1988—2014年人口呈现上升趋势,但中国人口增长率整体呈下降趋势。2015年中国人口达137 462万人。国家卫生计生委指出全面开放二胎政策后,预计2030年中国总人口达14.50亿人,并且随后出现人口负增长,2050年总人口为13.80亿人,本文将该预测结果作为人口高速增长的预测值;中国社科院人口与劳动经济研究所研究认为,中国人口将会在2025年达到14.13亿人的峰值,而到2050年中国人口数量将会比2015年还低,故本文将该预测结果作为低速增长的预测值。
第二,人均GDP。已预测出未来中国总人口数,通过预测不变价GDP即可得到人均GDP的预测值。2014年中国GDP增长率为7.30%,按可比价格计算,2015年中国GDP增长率为6.90%。根据目前的经济形势,中国应主动适应经济发展新常态,坚持供给侧改革,实现经济“稳中求进”,因而在未来发展过程中,中国GDP增长速率不会上升。本文将毕超[19]研究中的GDP增长率作为GDP高速增长的预测值;将国家统计局核算司的预测[20]作为GDP低速增长的预测值。
第三,城市化率。中国城镇化进程推动了交通、建筑业和工业的能源需求,2015年中国城市化率为55.77%,与发达国家还有较大的差距。国家新型城镇化规划(2014—2020年)发展目标为:常住人口城镇化率达到60%左右。本文将毕超[19]对中国城市化率水平的预测作为城市化率高速增长的预测值;将张妍和黄志龙[21]的预测作为低速增长的预测值。
第四,非化石能源消费量比重。新能源的发展成为世界发展的必然趋势,中国将加大对非化石能源的投资,促进非化石能源的进一步发展。2015年中国非化石能源消费量比重达到12%。毕超[19]根据中国一次能源消费结构测算出非化石能源比重,本文将其作为高速发展的预测结果;《2050年世界与中国能源展望》中指出中国2050年煤炭、石油、天然气消费比重分别为37%、14%、18%,即非化石能源比重为31%,本文将其作为低速发展的预测结果。
第五,能源强度。《IEA世界能源展望报告2015》指出,中国能源强度已经进入一个大幅度下降的阶段。2015年中国能源强度为2.49吨标准煤/万元。李虹和娄雯[22]测算出“十三五”规划期间单位 GDP能耗的低速率和高速率年均下降率为2.46%和4.36%,本文分别将其作为低速和高速下降的能源强度下降率,本文假定各情景的下降率在各阶段中递减。
第六,研发强度。《技术市场“十二五”发展规划》明确提出,到2015年技术合同成交额突破10 000亿元,研发强度达1.48%。本文将“十二五”期间中国研发强度作为低速增长时第一阶段的年均增长率,第二至第七阶段增长率递减;高速增长的年均增长率根据低增长率设定。
五、中国二氧化碳排放的峰值预测
利用基于粒子群优化算法的BP神经网络对中国未来二氧化碳排放量进行预测,将不同的情景组合输入网络,预测64种情景下中国2015—2050年二氧化碳排放量,其中变量顺序为人口、人均GDP、城市化率、非化石能源消费量比重、能源强度和研发强度。根据二氧化碳排放的预测结果,将64种情景划分为8种情景模式,具体结果如表5所示。
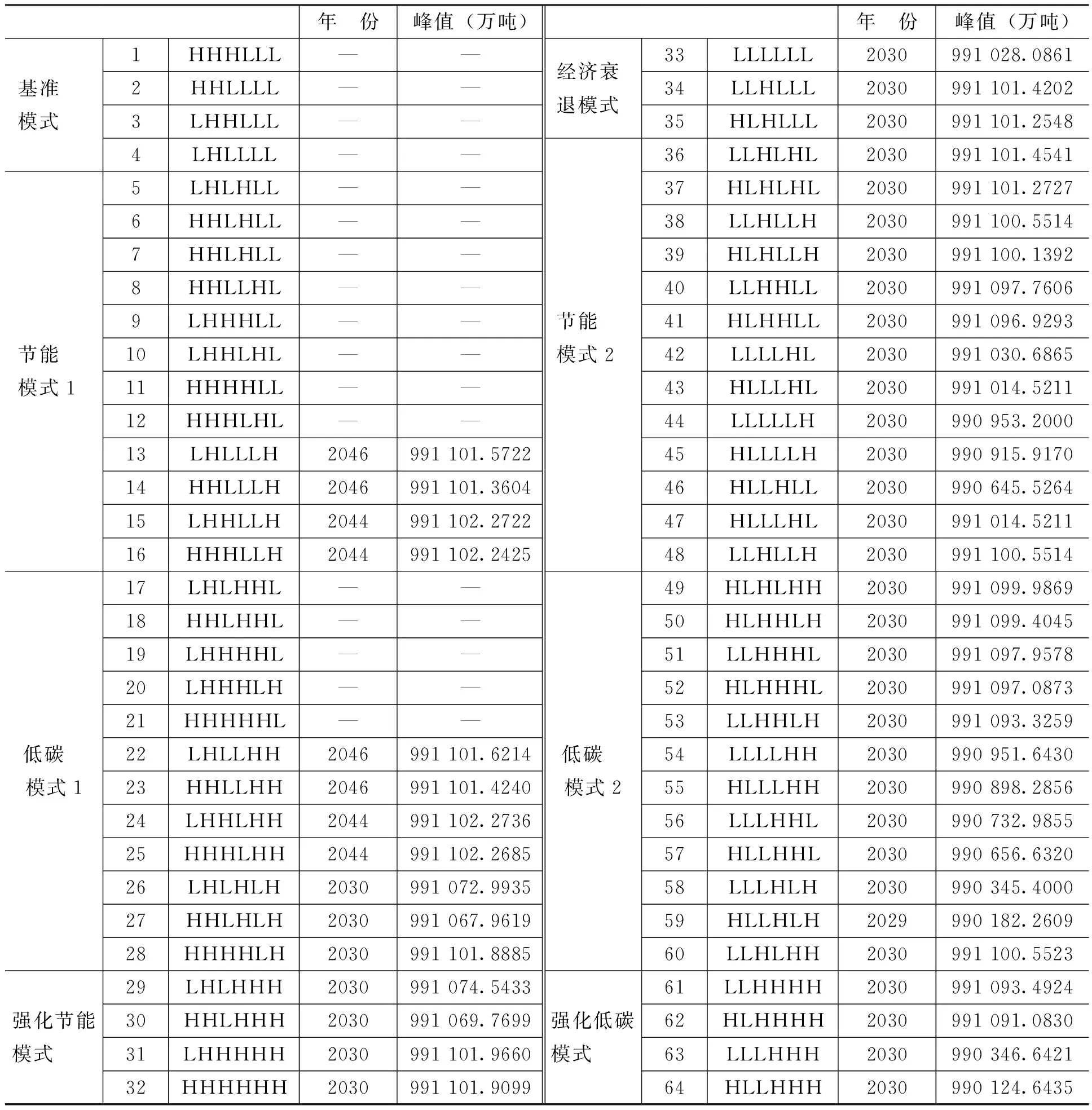
表5各情景模式下的二氧化碳排放预测值
注:H表示各因素高速增长;L表示各因素低速增长;—表示该情景在2050年内没有达到峰值。
(一)2030前实现碳排放达峰的情景分析
低碳模式2中的情景59能够在2030年前实现碳排放达峰,达峰时间为2029年,峰值为990 182.2609万吨。该情景下中国人口在2030年达峰,GDP与城市化率以低速率增长,其增长率分别为4.50%、0.60%,能源强度以低速率下降,但非化石能源消费量比重与研发强度均已高速增长,达峰时非化石能源消费量比重达19.58%,研发强度达4.97%,中国采用该路径实现排放达峰需采取强有力的节能减排政策。
(二)2030年实现碳排放达峰的情景分析
第一,经济衰退模式下中国二氧化碳排放量在2030年达到峰值,峰值为991 101万吨左右。经济衰退模式强调各因素均以低速率发展,该模式下二氧化碳排放虽已达峰,但与节能模式2相比,人均GDP同样低速增长,节能模式2的能源技术水平更高,二氧化碳排放峰值较小,故不采取该种模式来实现碳排放达峰。
第二,节能模式2下中国二氧化碳排放在2030年达到峰值,峰值为990 600—991 100万吨,该模式强调人均GDP低速增长,政府及企业节能意识加强,主要驱动因素为能源技术水平。节能模式2与节能模式1最大的区别是人口和GDP的增长速率较低,说明人均GDP对二氧化碳排放影响作用较大,中国在实现经济低速稳定增长时,着力于节约能源、降低能源消耗,采用新兴能源代替能耗高、效率低的能源,二氧化碳排放可达峰。
第三,低碳模式2下中国二氧化碳排放在2030年达到峰值,峰值为990 182—991 100万吨,该模式强调人均GDP低速增长,实行全方位的节能减排,主要驱动因素为能源技术水平。低碳模式2与低碳模式1的区别同样为人均GDP,低碳模式2下二氧化碳排放峰值低于节能模式2,说明相对于节能模式2,发展全方位的节能减排能使得二氧化碳峰值有所下降。
第四,强化节能模式下中国二氧化碳排放在2030年达到峰值,峰值为991 069—991 102万吨,该模式强调人均GDP高速增长,节能减排强度与强化低碳模式相同,经济发展与能源技术水平共同驱动。该模式下,影响二氧化碳排放的促进因素和抑制因素都高速增长,但该种情景很难达到,这是由于在转变经济发展方式时,中国GDP很难再以高的增速增长,而人口在全面开放二胎后会有短暂的增长,即人均GDP很难以高速增长,城市化率也会受一定影响。
第五,强化低碳模式下中国二氧化碳排放在2030年达到峰值,峰值为990 124—991 093万吨,该模式强调人均GDP低速增长,节能减排强度强于低碳模式,主要驱动因素为能源技术水平。人均GDP低速稳定增长,经济发展方式实现快速转变,其中能源强度快速下降是节约能源,降低消耗的结果,加大技术投资力度及新能源的开发使用使得研发强度和非化石能源消费量比重快速增长。强化低碳模式与低碳模式2下的二氧化碳排放趋势类似,其中情景64峰值最小,但该种模式发展也不切合实际。
(三)2030年后实现碳排放达峰的情景分析
第一,基准模式下二氧化碳排放在2050年前未达到峰值。该模式强调中国按目前发展趋势并且不采取任何强制措施进行减排,主要驱动因素是人均GDP,依旧以经济增长来促进社会发展,能源强度及技术发展以历史趋势发展,发展速率较慢。基准模式以中高速发展经济为目标尽快完成工业化进程。因此,需要采取一定措施来控制影响二氧化碳排放的各因素的增长率。
第二,节能模式1大部分情景下中国二氧化碳排放量在2050年前未达到峰值,情景13—16二氧化碳排放在2044—2046年达峰。该模式强调人均GDP高速增长,主要驱动因素为经济发展。政府及企业有节能意识,认识到通过减少化石能源消费、降低能源消耗、提高技术水平、加大开发新型能源的投资能够实现节能减排、低碳发展的目标,然而践行力度较差。由情景5—16可知,仅能源强度或非化石能源消费量比重快速发展,经济保持高速增长时,二氧化碳排放在2050年前不能达峰;而在仅研发强度快速增长,促进二氧化碳排放的各因素都保持高速增长时,二氧化碳排放在2050年前能够达峰,达峰时间为2044—2046年,峰值为991 102—991 103万吨。分析可知,人口对二氧化碳排放的影响较小,甚至出现在人口高速变化情景下二氧化碳排放量要小于低速变化情景,这是由于使用神经网络训练后只能体现出高的预测精度,不能够体现各因素如何影响二氧化碳排放。
第三,低碳模式1大部分情景下二氧化碳排放量在2030年不能达到峰值,其中情景26—28可达峰。该模式强调人均GDP高速增长,实行全方位的节能减排,经济发展和能源技术水平共同驱动。情景17—21二氧化碳排放在2050年前未达峰,其特点是经济增长的速度仍高于抑制二氧化碳排放因素的发展速度;而情景22—25二氧化碳排放在2044—2046年达峰,峰值小于节能模式1;情景26—28下二氧化碳排放在2030年达峰,峰值在991 000万吨左右。中国必须在增长经济的同时加大对技术市场的投资,积极开发新型能源来代替能耗高的化石能源。
综上所述,中国的发展模式可选择节能模式2,这是最现实可靠的方案,但是以减缓经济增长为代价,即控制GDP的增长速率,抑制二氧化碳排放的因素高速率增长,以较低的、稳定的经济增长来达到经济发展方式的转变。上述结果表明了人均GDP、城市化率、非化石能源消费量比重、研发强度对二氧化碳排放的影响较大,人口、能源强度影响较小,该结果与灰色关联结果大致相同。因此,在经济快速发展的同时,大力发展可再生能源、增加技术成交额,即加快实现科技向生产力的转换,推动能源结构调整,提高能源利用效率,使二氧化碳排放尽早达峰。
六、不同情景下碳排放达峰的特征分析
(一)不同情景下碳排放趋势分析
选取8种模式下代表情景,观察不同情景下2015—2050年二氧化碳排放量,分析可知,经济衰退模式、节能模式2、低碳模式2、强化低碳模式的二氧化碳变化趋势较明显,其在达到峰值后二氧化碳排放均以较大的速率下降,低碳模式2与强化低碳模式在达峰后排放总量快速下降,但实现该目标有较大难度;基准模式、节能模式1、低碳模式1下二氧化碳未达到峰值,但二氧化碳排放量变化不明显,强化节能模式下二氧化碳虽达到峰值,其二氧化碳排放减少较少。
(二)不同情景下碳排放达峰的人均二氧化碳排放分析
不同发展模式下人均二氧化碳排放也会存在差异,二氧化碳排放达峰并不意味着人均二氧化碳排放能达到峰值,本文选用8种模式下代表情景的人均二氧化碳排放量,并以此与二氧化碳排放达到峰值国家的人均二氧化碳排放对比。分析可知,基准模式、节能模式1、低碳模式1、强化节能模式下中国人均二氧化碳没有达到峰值,且人均排放在6.5—7.5吨/人;经济衰退模式下人均二氧化碳排放在2045年后达峰,晚于总量达峰年份;节能模式2下人均二氧化碳排放达峰年份也晚于总量达峰年份,2040年人均碳排放水平下降,2050年人均排放低于6吨/人;而低碳模式2、强化低碳模式下人均碳排放水平在总量达峰时也出现峰值,峰值与其他模式相比略小,并且在达峰后迅速下降,2045—2050年,人均碳排放水平达到3—4吨/人,与全球平均水平相当。根据柴麒敏和徐华清[3]文中所列的国家和地区人均排放峰值,大部分工业化国家人均二氧化碳排放超过10吨/人,美国的人均二氧化碳峰值甚至达到22.2吨/人,绝大部分工业化国家人均排放峰值早于总量峰值。
(三)不同情景下碳排放达峰的二氧化碳排放强度分析
不同情景下GDP增长速率不同,使得二氧化碳排放强度也略有不同,分析可知,中国二氧化碳排放强度的未来总体趋势大幅度下降,到2020年,各种情景模式下都能达到2009年哥本哈根会议之前设定的二氧化碳排放强度目标,即中国单位国内生产总值二氧化碳排放量比2005年下降40%—45%,同时也实现了2030年二氧化碳排放强度下降60%—65%的目标。本文设置的各种情景模式在2020年下降幅度达到50%左右,2025—2035年,基准模式、节能模式1、低碳模式1、强化节能模式下二氧化碳排放强度下降幅度大于其他模式;2035年后,低碳模式2、强化低碳模式下二氧化碳排放强度下降幅度较大;2050年的二氧化碳排放强度相当于2005年的10%。
七、主要结论
本文基于1988—2014年中国能源二氧化碳排放量、人口、人均GDP、城市化率、非化石能源消费量比重、能源强度、研发强度等变量建立二氧化碳排放预测模型,通过对比岭回归法、偏最小二乘回归、GM(1,1)模型、BP神经网络和基于粒子群优化算法的BP神经网络的预测精度,选择出最优模型即基于粒子群优化算法的BP神经网络预测二氧化碳达峰情况,本文的研究结论如下:
第一,与传统计量预测模型相比,基于粒子群优化算法的BP神经网络预测效果最佳。该预测模型测试集的相对误差均值为0.9736%,与其他模型相比预测准确性更高,说明基于粒子群优化算法的BP神经网络预测方法有较高的拟合优度,使用该方法预测二氧化碳排放更合理。
第二,基于粒子群优化算法的BP神经网络预测中国能源二氧化碳排放量在节能模式2下(2030年达到峰值)最符合现实情况。节能模式2下经济增速相对于常规路径累计减少3.70%,能够较为平稳地转变经济发展方式,实现向低碳经济的转型,但实现该目标需要实施举措满足该模式下各变量的新变化。
第三,人均GDP、城市化率、非化石能源消费量比重、研发强度对二氧化碳排放的影响较大,人口、能源强度对二氧化碳排放的影响较小,该结果与灰色关联结果大致相同。若经济发展处于较低速率,而非化石能源消费量比重、能源强度、全国技术市场成交额相对较快速增长时,中国二氧化碳排放能够在2030年达到峰值;若经济发展速率快,而抑制因素增长较慢时不能实现在2030年达到峰值的目标。因此,若中国根据设置好的路径发展时,能够实现目标,即在经济快速发展的同时,应加大非化石能源的消费,并增加技术成交额,即加快实现科技向生产力的转换;减少化石能源的消费,提高能源利用效率,开发并利用新型、清洁能源;人口对二氧化碳排放影响较小,可适当放宽政策,以防中国人口老龄化加重。
第四,中国人均二氧化碳排放达峰时间晚于总量达峰时间,达峰时人均排放水平为6.5—7.5吨/人,低于完成工业化的国家的人均碳排放水平。各种情景模式均可实现2020年中国单位国内生产总值二氧化碳排放量比2005年下降40%—45%,2030年二氧化碳排放强度下降60%—65%的目标。
猜你喜欢
少先队活动(2022年9期)2022-11-23 06:55:52
哈哈画报(2022年8期)2022-11-23 06:21:32
小学科学(学生版)(2021年5期)2021-07-22 02:40:08
中国经济周刊(2021年10期)2021-06-06 08:49:10
中国人口·资源与环境(2020年10期)2020-12-23 07:00:32
学生天地(2020年18期)2020-08-25 09:29:24
人物画报(2019年4期)2019-10-26 01:19:31
中国医药指南(2019年25期)2019-10-22 05:25:38
通信电源技术(2016年6期)2016-04-20 06:21:16
通信电源技术(2016年5期)2016-03-22 01:09:44
