
基于版本控制的中文文档到源代码的自动跟踪方法
2018-11-22 09:37刘洪星李勇华
计算机应用 2018年10期
沈 力,刘洪星,2,李勇华,2
(1.武汉理工大学 计算机科学与技术学院,武汉 430063; 2.武汉理工大学 交通物联网技术湖北省重点实验室,武汉 430070)(*通信作者电子邮箱liyonghua@whut.edu.cn)
0 引言
软件通常被定义为文档和程序的集合,在软件的开发、使用以及维护阶段都会产生大量的文档,而这些文档含有丰富的信息,并且和源代码之间存在紧密的联系。需求跟踪(Requirement Traceability)是指在软件开发周期中向前或向后的描述和跟踪软件开发元素的能力[1]。其中,文档与源代码之间的跟踪关系显得尤为重要,它在程序理解、软件开发、软件维护、变更分析和软件复用等方面有重要的作用,所以建立文档和源代码之间的跟踪链成为软件工程中的重要内容。
文献[2]将信息检索 (Information Retrieval, IR)技术与代码的调用关系及数据依赖关系相结合,提高了基于信息检索的自动跟踪能力;但代码依赖关系获取过程比较耗时,并针对了特定的程序语言。文献[3]研究了利用自然语言语义在获取自动化跟踪链时的潜在好处,比较了向量空间模型等几种信息检索及其改进方法,论证了明确的语义方法要好于潜在的语义方法;该方法的使用过程中需要大量语义分析,特殊领域需要特殊领域词典等工具支撑。文献[4]提出了一种基于IR和非文本技术自动结合的需求跟踪方法,首先确定直接的跟踪链,即通过IR方法计算文档与代码之间的跟踪链,通过改进的IR方法计算文档语句之间的跟踪链,通过加权的非文本方法计算代码类之间的跟踪链;然后确定非直接的跟踪链,即根据上一步跟踪链关系建立一个权重矩阵,通过矩阵乘法找出非直接的跟踪链;最后通过设定阈值获取文档与源代码之间的跟踪链。该方法相对于直接耦合的方法提升了精确度。文献[5]在标准用户反馈的方法上提出了一种自适应的反馈方法,该方法利用软件结构以及先前划分的正确链和错误链来决定是否以及如何使用反馈,相对标准的反馈方法表现更好;但目前仅测试于规模较小的项目,还需进一步验证。文献[6]分析了在利用文本和代码结构相结合的方法来提取跟踪链过程中的优缺点,提出利用软件工程师在对候选链进行分类时提供的反馈来规范使用结构化信息的方法,结果表明该方法优于纯粹的基于IR的方法和结合文本与结构信息的方法,但过程中需要大量的人工干预。文献[7]通过定义24个特定的变化场景,通过上一个版本的需求文档、代码和跟踪链与当前版本的需求文档、代码进行比较,得出当前版本的跟踪链;但是该方法局限性比较强,需要上一版本的跟踪链,可操作性比较低。
上述研究大多数是利用基于文本词汇信息的信息检索模型来建立源文件和目标文件之间的跟踪链,而软件文档通常由自然语言书写,源代码由代码语言书写,因此使用传统的信息检索模型建立软件文档和源代码间的跟踪链时,存在精度过低的问题。虽然有的研究注意到代码的结构信息,但忽略了中文文档语义和代码版本更新记录等有效信息,并且当前关于中文文档与源代码间可追踪关系的研究较少。
针对以上问题,本文提出一种基于版本控制的中文文档到源代码的自动跟踪方法。该方法在利用传统的信息检索技术建立中文文档与源代码跟踪链的基础上,加入对源代码版本信息和中文软件文档语义信息的分析,以便提高可追踪性跟踪链的精度。
1 本文方法
基于版本控制的中文文档到源代码的自动跟踪方法结构如图1所示。其中包含4个主要的处理阶段:数据获取与处理、文本信息检索、版本控制信息处理及跟踪关系推荐,而启发式规则用来辅助进行文本信息检索。该方法在进行文档到代码跟踪关系推荐时,首先需要获取数据并进行预处理,然后结合文档到代码的启发式规则,使用信息检索模型计算文档和源代码间的相似度,同时从版本更新信息中获取描述语句与源代码映射关系文档,计算软件文档与映射关系文档间的相似度,最后结合这两者的相似度得分得出文档到代码的跟踪链列表。

图1 基于版本控制的中文文档到源代码的自动跟踪方法结构Fig. 1 Architecture of automatic tracking method from Chinese document to source code based on version control
1.1 相关定义及启发式规则
1.1.1 句法分析与语义分析
中文文档、版本控制信息中的描述语句以及源代码中的注释信息通常是一些简单句句型,而简单句的基本句型由命令式的祈使句和表示条件、位置和修饰动词的状语构成,因此提出如下定义。
定义1 句法分析。软件工程文档中的简单句Sip由0~N个介词短语Spp、0~N个名词短语Snp和1个动词短语Svp构成。句法结构分析规则如下:
Sip=Svp|S1+Svp|S2+Snp
S1=Spp|S1+Spp
S2=Snp|S2+Snp
定义2 语义分析。简单句Sip可由四种短语结构成分组成,可以表示成一个多元式的语义结构形式,即Sv=(Act,Pla,Dep,Con),其中:
Act为“动作”,由中心谓语动词和中心宾语(即不包含修饰词的部分)组成。
Pla为“位置”,是指Act执行的位置,通常是单个名词短语或介词“在”的中心宾语。
Dep为“凭借”,是指Act执行的凭借,用来修饰动词,通常是介词“根据”“用”的中心宾语。
Con为“条件”,是指Act执行的条件,通常是介词“当”“只有”之后的条件子句。
根据定义1、定义2,推导出下列语义分析规则:
规则1Act推导规则。
当简单句Sip中直接存在动词短语Svp,且Svp直接由动词短语Svp1或者由其他成分So和动词短语Svp1构成,Svp1可以是动词Wv或动词及名词短语Snp的形式,那么该动词短语Svp1即为Act:
∃Svp∈Sip∧(Svp=Svp1∨Svp=So+Svp1)∧
(Svp1=Wv∨Svp1=Wv+Snp) ⟹Svp1∈Act
规则2Pla推导规则。
A)当简单句Sip中直接存在名词短语Snp时,认为Snp为Pla:
∃Snp∈Sip⟹Snp∈Pla
B)当简单句Sip中直接存在由介词Wp引导的介词短语Spp,其中介词Wp属于引导Pla的介词集合Cpp,Spp由Wp和名词短语Snp构成,有些Spp中还存在表示Pla的名词Wn,Wn属于表示Pla的名词集合,则认为名词短语Snp属于Pla:
∃Spp∈Sip∧(Spp={Wp+Snp|Wp∈Cpp}∨Spp=
{Wp+Snp+Wn|Wp∈Cpp∧Wn∈Cnp}) ⟹Snp∈Pla
规则3Dep推导规则。
当简单句Sip中存在动词短语Svp,Svp由介词短语Spp和动词短语Svp1构成,Spp由介词Wp和名词短语Snp构成,其中Wp处于表示Dep的介词集合中,则名词短语Snp属于Dep:
∃Svp∈Sip∧Svp=Spp+Svp1∧
Spp={Wp+Snp|Wp∈Cpd} ⟹Snp∈Dep
规则4Con推导规则。
A)当简单句Sip中直接存在由介词Wp引导的介词短语Spp,其中介词Wp属于引导Con的介词集合Cpc,Spp由Wp和名词短语Snp构成,而Snp由简单句Sip2、标记词Wdec和名词Wn构成,其中Wdec属于标引词集合Cdec,Wn属于表示Con的名词集合中,则简单句Sip2属于Con:
∃Spp∈Sip∧Spp={Wp+Snp,Snp=Sip2+Wdec+
Wn|Wp∈Cpc∧Wn∈Cnc∧Wdec∈Cdec} ⟹
Sip2∈Con
B)当简单句Sip中直接存在由介词Wp引导的介词短语Spp,其中介词Wp属于引导Con的介词集合Cpc,Spp由介词Wp和方位词短语Slcp构成,Slcp由简单句Sip2和方位词构成,其中Wlc属于方位词集合,则简单句Sip2属于Con:
∃Spp∈Sip∧Spp={Wp+Slcp,Slcp=Sip2+
Wlc|Wp∈Cpc∧Wlc∈Clc} ⟹Sip2∈Con
例句1“在装卸作业预确报界面,当选中船舶单选框时,根据船舶名称和航次查询船舶预确报”。
对例句1使用Stanford-parser工具[8]进行句法分析,结果呈树形结构,如图2所示。其中根节点IP表示整个句子;孩子节点表示句子的成分,如PP为介词短语,PU为符号,VP为动词短语等;叶子节点呈现句子中每个词的词性,如P为介词,NN为名词,VV为动词等。

图2 例句1句法结构分析图Fig. 2 Syntactic analysis of sentence 1
根据语义分析规则,例句1转换成对应的短语结构如表1所示。
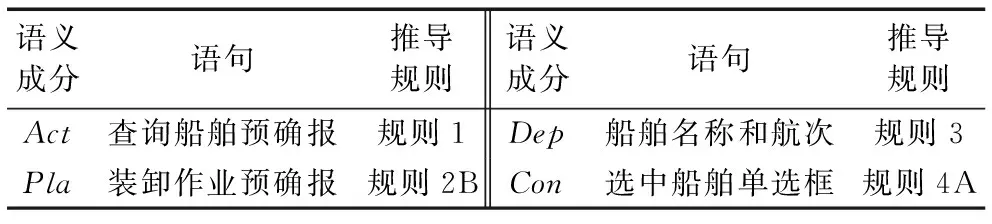
表1 例句1语义结构Tab. 1 Semantic structure of sentence 1
1.1.2 文档到代码启发式规则
当文档或描述语句中存在表“凭借”的介词短语时,该介词短语中名词个数与方法中参数个数相等;当文档或描述语句中存在表“条件”的介词短语时,源代码方法中存在分支结构或循环结构。规则如下:
规则5 介词短语与代码结构的映射规则。
A)表“凭借”的介词短语:
∃Snp∈Dep∧(Snp=Wn∨Snp=Wn+Snp) ⟹
num(Wn|Wn∈Snp)=num(mp)
其中:mp表示方法参数;num(x)表示x的个数。
B)表“条件”的介词短语:
∃Sip∈Con⟹ ∃Sbra∨∃Scir∈method
其中:Sbra表示分支结构;Scir表示循环结构;method表示方法。
根据源代码特点,常见动名词和源代码之间存在相应的启发式规则:
规则6 常见动名词启发式规则如表2所示。

表2 常见动名词启发式规则Tab. 2 Heuristic rules of common verbs and nouns
1.2 版本控制信息处理
在软件开发和维护的过程中,通常会使用版本控制软件来辅助开发人员进行代码的管理;软件版本迭代时,将会存在大量的版本更新信息。版本更新信息通常包含版本号(Revision)、作者(Author)、日期(Date)、描述语句(Message)、改动文件的索引(Index),本文方法主要提取版本控制信息中的版本号、描述语句和改动文件的索引。
版本描述语句通常会包含本次代码修改的主要内容,并且基本都是由介词短语、名词短语和动词短语构成的简单句。根据版本控制信息的特点,结合定义1和定义2,可以得出如下假设:
假设1 在版本描述语句中:
如果存在Pla,则该Pla与类名存在关联关系,即
∃Snp∈Pla⟹ conj(Snp,CN)
其中CN表示类名。
如果存在Act,则该Act与方法名存在关联关系,即
∃Svp∈Act⟹ conj(Svp,MN)
其中MN表示方法名。
还存在一些对检索帮助不大的工作性动词。
例如,在例句1中,表示Pla的名词短语“装卸作业预确报”对应本次版本提交中的类,而表示Act的动词“查询船舶预确报”对应本次版本提交中的类中修改的方法。
通过算法1得到版本控制信息与源代码之间的映射文件。
算法1 版本控制信息中描述语句与源代码关联算法。
输入 版本控制信息;
输出 版本控制信息映射文档。
1)提取版本控制信息,对版本更新描述语句进行分词、去停用词等,提取本次更新相关的代码的类和方法。
2)根据定义1,并用Stanford-Parser工具对其进行句法分析。
3)根据定义2对版本描述语句进行语义分析,得出相应的多元式表达形式(Act,Pla,Dep,Con)。
4)对处理后的版本描述语句运用假设1得出和相关类存在关联关系的名词或名词短语,以及和类中相关方法存在关联关系的动词或动词短语,并写入版本控制信息映射文档中。
5)重复步骤1)~4),如果在写入过程中发现同一类或方法的关键词中已存在相同词语,则将该词语频次加1,直到所有版本控制信息处理完毕。
6)输出版本控制信息映射文档。
算法1的思想是提取版本控制软件中的版本更新关键信息,将版本描述语句中的关键词与本次提交代码的类和方法关联起来,形成版本控制信息映射文件。
例如,使用svnkit工具[9]从版本控制软件中提取版本更新关键信息,并获取本次更新修改的类中的方法,以XML文件的形式保存如图3所示,包括了版本号和版本更新信息等。
图3 版本更新关键信息Fig. 3 Key information of version updating
对版本更新关键信息进行处理。首先,对logmes中版本更新描述语句进行预处理(分词、去停用词等),并运用定义2和相关语义分析规则得出版本描述语句的多元组表达形式Sv=(Act,Pla,Dep,Con),其中,Act=“保存”、Pla=“提运单办理”、Dep=Null、Con=“件数和重量均为0”;然后,提取本次更新关键信息中源代码的相关信息:
类名:CTOS.BusinessSystem.CargoBill_ADD。
方法名:buttonAddTYD_Click。
最后,根据假设1得出版本控制信息中描述语句与源代码之间的映射关系如表3所示。

表3 版本更新信息中映射关系Tab. 3 Mapping of version updating information
1.3 文本信息检索及启发式规则运用
文本信息检索主要包括对预处理后的数据构建词频-逆文本频率(Term Frequency-Inverse Document Frequency, TF-IDF)倒排索引表、文本相似度计算两个过程。
构建目标文档索引表的结果是生成一个m×n的标引词-文档矩阵A,m是所有软件文档中出现的标引词个数,n是文档的数量,其中第j行文档向量dj=(w1, j,w2, j,…,wn, j),wi, j表示第i个标引词在第j个文档中的权重,权重计算采用TF-IDF模式与启发式规则结合的方式。
采用向量空间模型对文档和源代码进行相似度计算,将每一条文档语句当作查询向量,设查询向量q=(w1,w2,…,wn),将所有源代码文档当作目标查询文档,对查询向量和源代码文档向量dj计算余弦相似度,如式(1)所示,其中wi为q中标引词的权重,wi, j为dj中标引词的权重。
(1)
对查询文档向量和源代码文档向量分别进行相似度计算,得到相似度列表。对每一条查询语句及存在相似度关系的源代码采用启发式规则,对相似度得分进行修正。
1.4 跟踪关系推荐
根据以上分析,本文提出如下关联关系提取算法。
算法2 基于版本控制信息的文档到源代码关联关系提取算法。
输入 项目文档、源代码、版本控制信息映射文档;
输出 文档与源代码文件的相似度列表。
1)对文档进行文本提取,以句子为最小粒度进行切分,并进行预处理(分词、去停用词)后,存入XML文件中。
2)提取项目源代码,以方法为最小粒度,以索引+方法文件的形式保存。
3)提取源代码中类名、方法名以及注释内容,对类名和方法名进行词型规范化,并映射成文字,对注释内容进行预处理。结合处理后的类名、方法名和注释内容形成表示方法的关键信息。
4)使用向量空间模型结合代码检索规则对文档条目和源代码关键信息进行相似度计算,得出文档和源代码间的相似度Score1。
5)计算文档与版本控制信息映射文档之间的相似度Score2。
6)分别赋予步骤4)和步骤5)计算出的相似度不同的权重值(a,b),不同权重下两者之和即为文档与源代码文件间的相似度Score=aScore1+bScore2。
7)以文件的形式输出相似度列表。
算法2的思想是利用向量空间模型计算出中文文档和源代码间的相似度得分,然后根据启发式规则进行修正,再结合源文档和版本控制信息映射文件之间的相似关系,得出文档与源代码文件的相似度列表。由于版本控制信息中的描述语句与本次提交的源代码之间具有较高的相关性,故文档与版本控制信息映射文档间的相似度具有较大的可信度,从而a的取值应小于b,故选取a的取值范围为[0,0.5],b的取值范围为[0.5,1]。由于不同文档的书写风格以及涉及到的软件实现方式不同,a和b的取值均不是固定值,需要通过训练集训练得到,步骤如下:
1)从测试数据集中随机选取若干数据作为训练集,一般为数据集的前5%或不少于5条数据;
2)对训练集开始训练,取初始值a=0,b=1,步长λ=0.05开始计算所有a、b取值下的精确度和召回率;
3)选取训练结果中精确度和召回率最高的a、b取值作为实验权重值。
例如,从中文文档中提取语句“在装卸作业预确报界面,当选中船舶单选框时,根据船舶名称和航次查询船舶预确报”,对其进行预处理,得出多元组表达形式如表1所示。提取项目相关源代码关键信息,以索引(GY.SDD.4)+文本(4.txt)的形式保存,提取关键信息:
类名:CTOS.BusinessSystem.YQ_Main。
类注释:装卸作业预确报界面及相关功能。
方法名:queShipYQB。
方法注释:船舶预确报查询。
提取由算法1得出的版本控制映射文档中相关信息:
类名:CTOS.BusinessSystem.YQ_Main。
关键词:装卸作业预确报#2、预确报#5。
方法名:queShipYQB。
关键词:查询船舶预确报#1。
计算出文档与源代码之间的相似度得分Score1=0.759 9,文档与版本控制信息映射文档之间的相似度得分Score2=1,通过训练集训练得出权重最优值a=0.35,b=0.65,综合得分Score=0.916 0。
2 实验
2.1 实验数据集
由于目前公开的相关实验数据集大多针对英文文档,并且无法获取其完整的版本更新记录,故实验采用作者参与开发的、现已正式运行的重庆果园港生产业务管理系统作为实验对象,选取软件设计文档作为源素材,软件源代码作为目标素材,并提取了软件开发及维护过程中版本控制软件中的版本更新记录,作为跟踪方法的测试集。
经过粒度划分等处理,共得到具有实际含义的设计文档语句857条,提取了项目类文件365个,这些类中包含的方法2 872个,从版本控制软件中提取了系统开发和维护过程中版本更新信息2 806条。由于软件文档和代码数量较多,本实验从系统众多功能模块中选取了商务模块的源素材,通过人工整理出了38条具有关联关系的跟踪链作为实验结果集。
2.2 实验过程
1)源素材处理。
对素材中提取出的中文语句进行预处理,包括分词、去停用词等。本实验采用ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)词法分析系统[10],提取系统中的数据库表名和字段名等作为用户词典,对中文素材进行分词。采用哈尔滨工业大学发布的中文停用词表,去掉一些对文本内容识别作用不大的词。
2)源素材和目标素材文本相似度计算。
对中文语句采用Stanford-Parser进行句法分析,根据定义2及相关规则对句法分析后的语句进行语义分析,并采用TF-IDF模型和代码检索规则对源素材(设计文档语句)和目标素材(源代码关键信息)进行权重分配,利用向量空间模型计算其相似度得分,根据规则5和规则6判断源素材和目标素材中源代码结构之间的关系,从而修正源素材和目标素材之间的相似度得分Score1。
3)版本控制信息处理及源素材和版本控制信息映射文档间相似度计算。
根据假设1得出版本控制信息映射文档,计算源素材中Pla和Act与版本控制信息映射文档中类与方法相关的关键词之间的得分,综合得出源素材和版本控制信息映射文档之间的得分Score2。
4)基于版本控制信息的中文文档和源代码间的相似度计算。
根据算法2中权重值a、b的确定规则,从实验数据中选取8条中文文档语句和所有源代码素材,并给出正确的跟踪链关系,作为训练集;然后,取初始值a=0,b=1,步长λ=0.05,采用a递增、b递减的方式进行训练;最后,得出最优取值a=0.35,b=0.65。最终得分Score=aScore1+bScore2,根据分数排序得出相似度列表。
2.3 结果分析
本实验与传统信息检索方法中的向量空间模型(Vector Space Model, VSM)方法[11]及文献[4]方法进行对比,采用相似度阈值法过滤实验结果,采用信息检索中最通用的查准率[11]、查全率[11]以及F2measure[12]来度量不同方法所得出的跟踪关系的质量。相似度阈值法即为设定一个相似度分数阈值,当实验结果分数大于该阈值时才选取该结果,小于该阈值时则舍弃,而查准率和查全率均在选取的结果中计算,因此实验结果中的查全率会随着阈值的增大而降低,查准率会随着阈值的增大而升高。在本实验中,当阈值大于0.2时,三种方法查准率虽然会有所提高,但是查全率显著降低,F2measure的值也会显著降低,对比意义不大,因此本文选取0.2作为最大阈值,实验结果的平均值如表4所示。

表4 实验结果平均值Tab. 4 Average value of experimental result
由于实验方法不同,三种实验在相同阈值下的横向对比意义不大。根据实验结果平均值可以看出,三种方法的综合评判指标F2measure值均在阈值为0.2达到最大,为了更好地说明实验效果,选取阈值为0.2时的实验数据,使用R工具[13]自动生成箱线图,从图4所示的箱线图可以清晰地显示数据的离散度、中间值等,图中离散的圆点表示数据的异常值,上下两条横线分别为数据的上下边缘,表示数据的整体范围;中间矩形的上下两边为上下四分位数,表示数据集中在这一范围中;矩形中的横线表示数据的中位数,表明数据总体的中间值。从图4可以看出,在查准率方面,三种方法的整体范围和下四分位数均相同,本文方法的上四分位数高于其他两种方法,中位数与文献[4]方法相同,略高于VSM方法;在查全率方面,三种方法中位数相同,文献[4]方法浮动范围稍大;在F2measure方面,三种方法下四分位数相同,本文方法中位数高于其他两种方法,并且本文方法的数据集中区域略高于其他两种方法。结合实验数据和箱线图可以看出在查全率方面本文方法与其他两种方法相差不大,在查准率和综合评价指标方面,本文方法在中间值和整体范围方面均优于其他两种方法。

图4 实验结果箱线图Fig. 4 Box-plot of experimental result
3 结语
本文提出了一种基于版本控制信息的中文文档到源代码的自动跟踪方法。该方法首先提取以句子为最小粒度的中文文档及以方法为最小粒度的源代码关键信息,结合自定义的文档到代码的启发式规则,利用向量空间模型计算出中文文档与源代码之间的相似度得分;然后结合中文文档与版本更新信息之间的相似度关系,调整中文文档与源代码之间的相似度得分,确定中文文档与源代码之间的跟踪关系。对于相同的测试对象,本文方法相对于传统的基于信息检索的方法,提高了精确度和召回率;但是当中文文档中存在大量的结构化图形描述时,本文方法效果不太理想,这是今后需要研究的内容。
猜你喜欢
疯狂英语·初中天地(2021年8期)2021-11-20
现代信息科技(2021年21期)2021-05-07
高中生·天天向上(2018年2期)2018-04-14
农家书屋(2016年11期)2016-12-23
世界汽车(2016年9期)2016-09-29
小学生·多元智能大王(2014年6期)2014-07-09
外语教学理论与实践(2014年1期)2014-06-15
小雪花·初中高分作文(2009年8期)2009-11-16
初中生·博览(2004年3期)2004-03-07
