
面向手写汉字识别的残差深度可分离卷积算法
2018-11-19 10:58陈鹏飞应自炉朱健菲商丽娟
软件导刊 2018年11期
陈鹏飞,应自炉,朱健菲,商丽娟
(五邑大学 信息工程学院,广东 江门 529020)
0 引言
脱机手写汉字识别(Offline Handwritten Chinese Character Recognition, HCCR)被广泛应用于历史文档识别、签名识别和手写文档转录等领域。由于汉字种类繁多,不同的人有不同的书写风格,而且相似汉字极易被混淆等,造成了脱机手写汉字识别难度较大。传统的脱机手写汉字识别方法主要包括数据归一化、特征提取和分类器识别3个部分。其中,较为有效的特征主要有Gabor特征和Gradient特征[1],常用的分类器有二次判别函数(Modified Quadratic Discriminant Function, MQDF)[2]、支持向量机(Support Vector Machine, SVM)[3]等。传统方法中,文献[4]采用鉴别特征提取(Discriminative Feature Extraction, DFE)和鉴别学习二次判别函数(Discriminative Learning Quadratic Discriminant Function, DLQDF)方法取得了传统方法中最高的识别准确率,但其性能并未超过人类平均水平[5]。近几年,深度学习技术在计算机视觉、语音识别、自然语言处理等领域取得了显著成功[6]。采用深度学习的脱机手写汉字识别方法取得了很大突破[7]。2013年,富士通团队采用多列深度卷积神经网络(Multi Column Deep Convolutional Neural Network, MCDNN)获得了ICDAR(International Conference on Document Analysis and Recognition)脱机手写汉字识别比赛第一名,识别率为94.77%[5]。Zhong等[8]提出HCCR-GoogleNet,采用领域方向特征和卷积神经网络(Convolutional Neural Network, CNN)方法,将识别率提高到96.74%。最近,Zhang等[9]提出基于directMap和convNet的方法,进一步将识别率提高到97.37%。基于深度学习技术的脱机手写汉字识别方法研究已经取得了较多成果,但是因拥有较高的计算复杂度和较大的模型容量,制约了其将模型部署到移动端等计算资源和存储容量有限的设备。
降低卷积神经网络(Convolution Neural Network,CNN)计算复杂度和模型容量的研究主要有改进CNN模型本身结构和优化现有预训练模型。在改进CNN模型中,文献[10]提出Fire结构的SqueezeNet网络大大降低了模型容量;针对移动设备设计基于深度可分离卷积的MobileNet网络,减少了模型的计算复杂度[11]。在优化现有模型的方法中,低秩扩展方法通过分解卷积层降低计算复杂度[12];Guo等[13]提出网络剪枝方法用以压缩CNN模型。目前,针对大规模脱机手写汉字识别模型加速和压缩的研究相对较少。Xiao等[14]提出基于全局监督低秩扩展(Global Supervised Low-rank Expansion, GSLRE)与自适应去权重(Adaptive Drop-weight, ADW)的方法计算复杂度和模型容量问题,该方法首先通过GSLRE进行逐层训练,然后利用ADW方法对预先训练的模型进行权重裁剪,在降低计算复杂度和模型容量方面效果较为明显,但是模型训练较为复杂。受MobileNet网络结构启发,本文提出一种基于深度可分离卷积的残差卷积神经网络模型,降低计算复杂度和模型容量。通过深度可分离卷积改进残差卷积神经网络,可以训练更深层的网络模型,在保证模型识别准确率的同时,实现较小的模型容量和计算复杂度。本文方法主要通过改进网络结构减小模型容量和计算复杂度,降低网络模型训练难度。
目前,基于深度学习的脱机手写汉字识别方法都通过softmax 损失函数进行监督训练,softmax 损失函数能够优化类别间差异,但是忽略了类内紧凑性,通常导致分类性能降低。为了解决这一问题,引入一种在人脸识别中较为有效的中心损失函数[15],通过联合softmax损失函数与中心损失函数监督训练CNN网络模型,优化类别间差异和类内紧凑性,从而提高模型识别准确率。
1 研究方法
1.1 深度可分离卷积
深度可分离卷积是指将标准卷积分解为一个逐深度的卷积和一个1×1标准卷积(逐点卷积)。逐深度卷积对应着每一个输入特征图的通道,1×1逐点卷积负责将逐深度卷积提取的特征进行融合。通过特征提取与特征融合分离可以有效地降低计算复杂度和模型容量。图1显示了标准卷积和深度可分离卷积的结构。
假设一个标准卷积层的输入特征图为X,大小为M×H×W,其中M是输入特征图通道数,H和W是输入特征图的高和宽;输出特征图为Y,大小为N×H′×W′,其中N是输出特征图通道数,H′和W′是输出特征图的高和宽;卷积核为F,大小为C×K×K×N,其中,K是卷积核的大小。卷积步长和补边为1,由卷积的定义可知:
(1)
其参数量和计算复杂度分别为:
C×K×K×N
(2)
C×K×K×N×H′×W′
(3)
图1(a)显示了标准卷积的详细结构。
深度可分离卷积中,每个卷积核对应一个输入特征图,所以根据深度可分离卷积的定义,有以下公式:
(4)
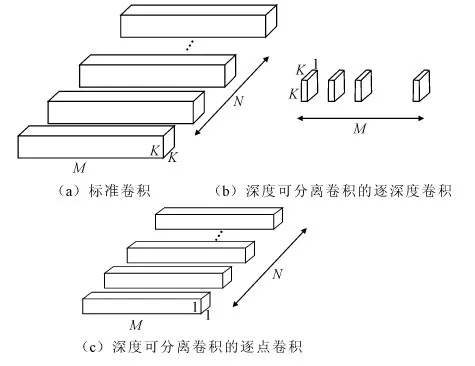
图1 标准卷积与深度可分离卷积结构
为了保证有相同的输出特征图,在深度可分离卷积后面加入一个输出特征图为N的1×1标准卷积,其参数量和计算复杂度分别为:
C×K×K+C×1×1×N
(5)
C×K×K×H′×W′+C×H′×W′×N
(6)
图1(b)、图1(c)分别是深度可分离卷积的逐深度卷积和逐点卷积的详细结构。
使用深度可分离卷积,相比标准卷积,其计算复杂度和参数量都减少相同倍数。由式(2)和式(5)可知:
(7)
由式(3)和式(6)可知:
(8)
所以,当深度可分离卷积核K的大小为3时,相比标准卷积,其参数量和计算复杂度减少8~9倍。
1.2 基于残差学习的深度可分离卷积神经网络
受ResNet[16]的残差结构启发,本文设计了基于深度可分离卷积的残差结构单元。图2描述了两种主要的分支结构。在分支结构中,第一层1×1卷积主要用来降低深度可分离卷积的输入通道数;第二层使用3×3深度可分离卷积代替,以减少参数和计算量;最后一层1×1卷积用于匹配快捷路径分支的通道数。其中,图2(a)的深度可分离卷积分支结构步长为1,通道融合采用逐通道相加操作;图2(b)深度可分离卷积分支结构步长为2,将快捷路径分支使用平均池化代替,在通道融合方面,采用通道串接的方式增加通道数。在每个卷积层中,使用批量归一化层(BatchNorm, BN)[17],BN层能够加速网络模型收敛。

图2 深度可分离卷积残差结构
本文提出一个使用深度可分离卷积残差结构单元构成的CNN网络结构,详细网络结构如表1所示。在构建的网络结构中,第一层Conv1使用标准的卷积滤波器;网络结构主要集中在3个阶段(Stage2-4),每个阶段的输入通道数会增2倍,期间通道维数保持不变;随后使用全局池化得到一个1 024维的深度特征,使用标准卷积滤波器Conv5层降低输出通道的维数为256,最后输出3 755个类别。模型复杂度计算的是浮点乘加操作次数,模型容量是网络结构所有参数的总和。
1.3 联合损失函数
脱机手写汉字识别使用softmax损失函数作为网络模型训练时的优化目标,softmax损失函数会优化类别间差异,但是忽略了类内紧凑性,从而使得分类误差较大。为解决该问题,引入中心损失函数优化类内紧凑性。中心损失函数也常用于人脸识别、验证等任务中,用来减少类内变化。联合softmax损失函数和中心损失函数训练网络模型,可以同时增加类别间差异和减小类内变化,使模型学习到具有判别性的深度特征。softmax损失函数公式如下:

表1 CNN模型结构
(9)
在式(9)中:xi∈Rd表示属于yi类别的第i个深度特征,d表示特征的维度;W∈Rd×n表示最后一个全连接层的权重,b∈Rn是偏置项;m和n分别表示批处理数量和类别数量。
中心损失函数会学习到每个分类类别的中心,其公式表示如下:
(10)
在式(10)中,cyi∈Rd表示第yi类别的深度特征中心。
联合softmax损失函数和中心损失函数训练网络模型,能够有效增加类别间差异和减小类内变化,使得模型具有更高的鲁棒性和识别准确率。联合损失函数公式表示如下:
L=LS+λLC
(11)
在式(11)中:损失函数L可以通过随机梯度下降法(Stochastic gradient descent, SGD)进行训练;参数λ是用来平衡两个损失函数的参数,当λ=0时,只有softmax损失函数作为监督训练的损失函数。图3详细描述了采用中心损失函数和softmax损失函数联合训练的网络结构。输入图像是经过归一化处理的图像数据,网络结构使用表1描述的结构,最后将网络结构的输出结果作为损失函数输入。其中,中心损失函数使用Conv5层的输出特征,维度是256;softmax损失函数使用FC层的输出特征,维度是3 755。带有权重参数λ的中心损失函数结果与softmax损失函数结果作为联合损失函数结果输出,使用随机梯度下降方法对整个网络的权重进行学习和更新。

图3 联合softmax损失函数与中心损失函数的网络结构
2 实验与结果分析
2.1 数据库及数据预处理
实验数据采用CASIA-HWDB(Institute of Automation of Chinese Academy of Sciences Offline Chinese Handwriting Databases)数据库作为脱机手写汉字识别的实验数据。该数据库含有中科院自动化研究所采集来自1 020名不同书写者的超过300多万个手写汉字样本,汉字类别包含GB2312-80一级常用汉字3 755个类别[18]。CASIA-HWDB1.0数据库包含来自420名书写者的1 609 136个手写汉字样本,汉字类别为3 866类(包括GB2312-80GB2312-80一级常用汉字中的3 740类)。CASIA-HWDB1.1数据库包含来自300名书写者的1 121 749个手写汉字样本,汉字类别为3 755类。CASIA-HWDB-Competition数据库包含60名书写者的224 419个手写汉字样本,汉字类别为3 755类。本文实验采用GB2312-80的3 755类汉字,将CASIA-HWDB1.0和CASIA-HWDB1.1作为训练集数据,CASIA-HWDB-Competition作为测试集数据。数据库参数见表2。

表2 脱机手写汉字数据集
CASIA-HWDB数据样本均被归一化到32×32大小,尺寸小的样本图像可以进一步减小网络模型的计算复杂度。CASIA-HWDB数据样本提供了以白色(灰度值为255)为背景的灰度图像数据。为了减少背景值的计算,将原图像数据背景和前景灰度值反转,即将白色背景变为黑色背景(灰度值为0),前景部分的灰度值范围为[1,255]。图4是数据预处理的详细示意图。

图4 数据预处理
2.2 训练参数设置
本文采用深度学习框架tensorflow进行实验验证。实验采用带动量(momentum)的随机梯度下降法进行参数更新,权重参数W使用损失函数的负梯度▽L(W)和先前的权重更新值vt学习。网络模型权重更新表达式如下:
vt+1=μvt-α▽L(W)
(12)
Wt+1=Wt+vt+1
(13)
其中,μ是动量,α是学习率;t+1和t分别表示两个不同时刻,vt+1表示更新值。

表3 训练参数设置
2.3 损失函数实验结果分析
为了比较单损失函数和联合损失函数对网络模型的优化结果,设置两组不同的实验。第一组网络模型A(Model A)只采用softmax损失函数作为监督训练损失函数,第二组网络模型B(Model B)采用联合的softmax损失函数和中心损失函数作为监督训练损失函数。模型A采用上文中的训练参数设置进行模型训练,图5是模型A在训练过程中、在验证集数据上的准确率结果。
为了加速训练过程,采用迁移学习[19]方法,在模型A训练结果基础上对模型B进行微调训练。进行微调训练时,需要对上文一些训练参数进行修改,以适应新的训练过程。针对模型B的训练,基本学习率降低到0.000 01,使模型迭代变化较慢。训练的最大迭代次数设置为100 000,在迭代50 000次时,基本学习率降低10倍,其余训练参数与模型A的训练参数保持一致。
参数λ是中心损失函数在联合损失函数中的权重,设置参数λ的范围为0.000 1~1,训练13组不同参数λ的模型B,测试不同参数λ下模型B的识别率,结果如图5所示。其中,当参数λ=0时,表示未使用中心损失函数,只有softmax损失函数作为监督信号。结果表明,联合的损失函数测试准确率都高于只使用softmax损失函数的结果。
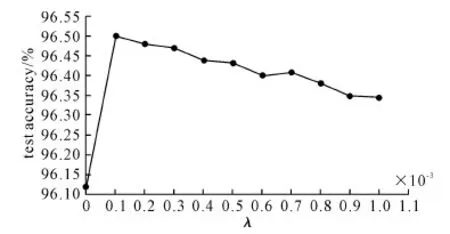
图5 不同参数λ下模型测试准确率
2.4 模型容量与计算复杂度结果分析
模型计算复杂度主要来自卷积运算操作,模型容量是可学习的权重参数总和。根据式(2)和式(3)可以计算标准卷积层的参数量和计算复杂度,根据式(5)和式(6)可以计算出深度可分离卷积层的参数量和计算复杂度。每一种方法的计算复杂度主要统计卷积层和全连接层的浮点乘加运算;模型容量统计卷积层和全连接层的权重参数,每个权重参数默认使用4个字节单精度浮点数表示。
表4详细介绍了几种不同的脱机手写汉字识别方法。在ICDAR-2013脱机手写汉字识别比赛中,来自Fujitsu的团队获得比赛第一名,采用多个模型集成的方法,模型存储容量为2.402GB[5]。HCCR-Gabor-GoogleNet方法是首次超越人类平均水平的脱机手写汉字识别方法,其单模型的准确率提高到96.35%,10个集成模型的准确率提高到96.74%[8]。随后,Zhang等[9]提出基于方向特征+卷积神经网络的方法,进一步将识别准确率提高到97.37%。基于ResNet网络+空间变换的方法,也取得了97.37%的准确率[20]。相比传统方法,基于深度学习的方法基本取得了突破性的性能提升。但是,一般基于深度学习模型的算法模型容量和计算复杂度都较高,很难部署到计算资源和容量受限的设备上。
针对计算复杂度过高和模型容量过大的问题,本文提出基于深度可分离卷积的脱机手写汉字识别方法。该方法在计算复杂度和模型容量方面相比传统卷积神经网络方法都有很大优势。本文提出的模型A,模型容量有20MB,主要计算复杂度为127M FLOPS,在保持较低计算复杂度和模型容量的情况下,测试准确率为96.12%,达到了主流测试水平。通过引入中心损失函数优化模型A,进而得到优化后的模型B,识别准确率进一步提高到96.50%。

表4 脱机手写汉字识别方法性能比较
3 结语
通过使用深度可分离卷积和联合损失函数改进残差网络结构,本文提出一个高效的脱机手写汉字识别模型,使得模型更容易被部署到计算资源和存储容量受限的移动端设备上。基于深度可分离卷积的残差卷积神经网络通过将标准卷积操作分离为特征提取和特征融合两个部分,有效减少了模型的计算复杂度和模型容量。而且,基于残差结构的网络模型采用瓶颈结构,使得计算复杂度进一步降低。在此基础上,引入中心损失函数,通过学习每一类的类别中心,使类内特征更加紧凑,联合softmax损失函数可以学习到更具判别性的深度特征。实验结果表明,网络模型在达到主流识别准确率的同时,所用方法拥有较低的模型容量和计算复杂度。
猜你喜欢
实用临床医药杂志(2021年7期)2021-05-18
作文成功之路·小学版(2020年7期)2020-08-24
中国现代医药杂志(2019年6期)2019-07-31
中国惯性技术学报(2019年6期)2019-03-04
中国民间疗法(2019年24期)2019-02-12
电子制作(2018年18期)2018-11-14
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
自动化学报(2016年8期)2016-04-16
火控雷达技术(2016年3期)2016-02-06
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
