
Software Defect Prediction Method Based on Rule Knowledge Extraction Model
2018-11-15 08:07CHAIHaiyanYANRanHANXinyuTANGLongli
CHAI Haiyan(), YAN Ran( ), HAN Xinyu(), TANG Longli()
China Shipbuilding Software Quality&Reliability Testing Center,Beijing100081,China
Abstract:The software defects are managed through the knowledge base,and defect management is upgraded from the data level to the knowledge level.The rule knowledge is mined from bug data based on a rule-based knowledge extraction model,and the appropriate strategy is configured in the strategy layer to predict software defects.The model is extracted by direct association rules and extended association rules,which improve the prediction rate of related defects and the efficiency of software testing.
Key words:knowledge base;software testing;defect prediction;association rule
Introduction
To improve the software quality, software testing is carried out to identify and correct software defects prior to the go-live, which has a direct impact on the quality of software. However, the current defect analysis is still based on the data-level analysis and prediction, its contribution to the value of software testing would be limited. It will essentially facilitate the improved working level and efficiency of software testing by introducing the knowledge base architecture into software defect management, upgrading the level of defect analysis from data management to knowledge management, extracting the rule knowledge through machine learning and artificial intelligence, and generating a strategy report that can suitably instruct the software testing. The knowledge in the knowledge base can be divided into three layers: factual knowledge layer, middle layer and strategy layer. In the three layers, the middle layer is a rule process based on factual knowledge, while the strategy layer is a rule based on middle-layer knowledge. Software defect is predicted by mining the rule knowledge from bug data through a double-level association rule-based model and by configuring the corresponding strategy in the strategy layer. This double-level model will run prediction on two levels (direct association rule, and extended association rule) to increase the number of defect predictions in the single-level association rule and improve the efficiency of software testing[1-2].
1 Defect Analysis and Knowledge Base
As already defined in ISO 9000, a software defect means “a failure to meet the requirement that is related to the intended or specified use”. No developer can assure that there is no bug in the designed software, no matter how experienced he is. Software is accompanied with bugs throughout its lifetime, whenever the triggering condition is satisfied, a bug will be triggered to cause immeasurable losses. The exact purpose of software testing is to identify bugs prior to the go-live.
Defect analysis tracks and analyzes a variety of bugs generated during the software development and testing. Its efficiency can be improved with recording, assorting and statistical analysis of bugs using electronically assisted method[3-8]. However, the current defect analysis is only limited to statistical measurement of bugs. A lot of methods are available for the classification of bugs, such as “Classification for Software Anomalies” proposed by IEEE, “Orthogonal Defect Classification” proposed by IBM, Chinese military has also established the applicable standards to define and classify bugs, for instance, the classification of software errors as defined in “GJB 2786A-2009 General Military Software Development Requirements”.
Knowledge base stands at the core part of artificial intelligence. The knowledge in the knowledge base can be divided into three layers: factual knowledge layer, middle layer, and strategy layer. In which, the middle layer is a rule process based on factual knowledge, while the strategy layer is a rule based on middle-layer knowledge.
Artificial intelligence cannot merely focus on the process method, and actually descriptive method is also important as experience. Many related researches are involved in defect analysis, the majority of these researches intend to optimize the defect analysis from the perspective of algorithm optimization, but this research direction is too limited. The defect analysis management can be upgraded from bug data management to knowledge management throughout the process of software development testing by introducing knowledge base into software defect management.
Machine learning is a subject of artificial intelligence science, which enhances algorithm performance based on experience of data and algorithm learning. The learning strategies used for machine learning can be divided into four types: machine learning, instructional learning, learning by analogy, and learning by instance. The traditional defect management system is upgraded to software testing expert system through knowledge base and machine learning algorithm.
2 Defect Management System Function Architecture
In the software defect management system based on knowledge base data mining, bugs are managed through the knowledge base architecture, and the defect management is upgraded with the three-tier knowledge architecture from data level to knowledge level. In this thesis, the proposed defect management system carries out software testing defect management from four aspects: bug data management, bug rule knowledge mining, defect prediction, and bug strategy knowledge configuration. Meanwhile, bug data management corresponds to the factual knowledge layer as contained in the knowledge base, bug rule knowledge mining corresponds to the middle layer as contained in the knowledge base, and bug strategy knowledge configuration corresponds to the strategy layer as contained in the knowledge base.
Factual knowledge layer is the basic layer of the knowledge base and its knowledge sources from the peripheral interactive systems or related personnel. As the data acquired by the factual knowledge layer is involved throughout the process of software development testing, its data quality and quantity determines the system availability and effectiveness.
Software development is asystematic project, bugs can be attributed to many factors and involve every process of the software development project. For the system, complexity of software functions, code quantity, software architecture and other factors are associated with software defects. In view of the software development process, request communication, document quality, or revision history as involved in the development process will determine the number of bugs in the software. From the development project management, irrational project schedule, unscientific management of PM personnel process, less experienced developer, or large turnover of developers may also cause software defects. From the software development company, company size, qualifications, or subcontracting is associated with the software quality. For third-party testing company, although it is unlikely to control the software development process, acquiring information and data related to software development and understanding the software development progress will be of great significance to the software testing. The related data can be collected and managed through the customer relation management system.
Similarly, software testing is also a systematic project and software development project which determine the number of software defects. Software testing determines the number of detected bugs. Undetected defects will cause quality issue with a variety of risks. In view of the software testing process, testers, testing documents, design of test cases, use of bug history data will be associated with the number of detected bugs, which also determines the software quality.
A lot of bug related data have been accumulated during the software development and testing process, the efficiency of software testing can be improved through effective management and use of such massive data. Because defect management is involved throughout the process of software development and testing, the acquisition of bug data also needs to be involved throughout the process of software development and testing.
Factual knowledge layer has allowed testers to share and acquire the knowledge related to software testing through query interfaces. However, the factual knowledge layer has a massive amount of data and is only suitable for querying scenarios. The rule knowledge base in the rule knowledge layer is formed with data mining based on factual knowledge layer and through machine learning algorithm. The knowledge in the factual knowledge layer only states facts, while the knowledge in the rule layer is the empirical rule formed through intelligent extraction and refining of factual knowledge.
The prediction of software and the configuration of the corresponding strategy based on the knowledge in the rule knowledge base precisely result in the formation of knowledge in the strategy layer that is valuable to software testing.
The knowledge in three layers of the knowledge base increase the value of testers from layer to layer, the factual knowledge layer only provides the relevant personnel with description of factual knowledge. The rule knowledge layer can provide the summarized rule experience through machine learning algorithm and based on factual knowledge. In contrast, the strategy knowledge layer predicts defects in a software project to be tested, provide the corresponding testing strategy report to present testing related suggestion to the relevant testers.
For example, factual knowledge records software development company, developers, number of module branches, number of module code lines, and bug information, a rule knowledge can be obtained by extracting these data through the machine learning algorithm, “Mr. Zhang working at a company has developed a program module with more than 900 code lines and over 10 branches has a greater probability of causing bugs”. A software project to be tested will produce a defect prediction report and a design instruction report of test cases through the strategy knowledge layer.
The core functions of this software defect management system based on knowledge base data mining are achieved by nine modules: factual knowledge database, data preprocessing module, machine learning algorithm module, rule extraction module, rule knowledge datebase, defect prediction module, strategy knowledge datebase, account permission management and query interaction subsystem.
Factual knowledge database is fundamental to defect prediction management. Factual knowledge database stores the data related to software defect generated during the software testing. The data stored in factual knowledge database sources are from the input entries by testers, salespersons, managers and the acquisition from related systems. Factual knowledge data includes bug history data, project management data, and custom service management data. Bug history data sources are from the bug tracking system, project management data sources from the input entries by testing managers and software development company. Customer data sources are from the customer relation management system. Software testing company have many customers and the related customer relation management system records customer related information.

Fig. 1 System function module block
Data preprocessing module performs extract transform load processing based on the data stored in the factual knowledge database to form a basic factual data table. The factual data table consists of two types of fields: bug identification field, and testing attribute field. Bug identification field is used to identify the defect type, testing attribute data is a dimensional attribute associated with test cases and test bugs.
Machine learning module uses the basic factual data table output by the preprocessing module as input entries and outputs a rule tree through the machine learning algorithm. Rule extraction module extracts bug rule based on defect management objective to form rule knowledge. Rule database stores rule knowledge. Software prediction module predicts software based on the rule in the rule knowledge datebase, strategy knowledge base configures the corresponding defect management strategy for the predicted result.
3 Rule Knowledge Mining Based on Double-Level Association Model
3.1 Double-level association rule mining model
The knowledge in the factual knowledge layer exists in the form of data that describes facts. All factual layer knowledge in the defect management system is bug-related data. The data consists of defect description, classification and other related attributes. The association rule between bugs can be identified through the knowledge mining association rule, and then the corresponding strategy can be configured. For example, when a bug is identified, the detection rate of bugs can be improved by identifying related bugs and designing appropriate test cases according to the association rule. In the defect management system, the factual knowledge layer describes bugs by dividing them into two types of fields: defect type and bug attribute. More details are shown in Table 1.
The double-level association rule mining model runs mining on the association rule between defect types and that between defect type and bug attribute respectively. Software defects can be predicted with the association rule between defect type and bug attribute, and the prediction of defect types can be extended with the association rule between defect types.

Table 1 Factualknowledge table
XandYmeans attribute and type item set respectively,XTandYTare type item sets, then the double-level association rule set will beRZ,
RZ={X→ZT:X→YandYT→ZT,Y∈YT}.X→Yis an association rule between bug attribute and type, which means that the test item conforming to the attributeXwill have a greater probability of occurring typeYbug.YT→ZTis an association rule between bug types, typeYTbug after occurring will have a greater probability of occurring typeZTbug.
Step 1 Calculate all high support item sets with support degree beyond the threshold. The association rule support of attribute type is expressed in Eq. (1).
(1)
whereXandYare the attribute and type item sets respectively. |E| means total number of events. If the support of the item setCthat contains itemAin the factual type table is greater than the specified support, as shown in Eq. (2), thenC(AT) is referred to as the high support item set. The high support item set that containsKitems is denoted asFk.
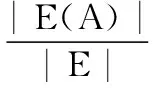
(2)
Step 2 For each frequent item setF, calculate the confidence level of all non-empty subsetsF′ ofF, as shown in Eq. (3).
(3)
IfCRis greater than the user-specified minimum confidence threshold, then the association rule of attribute type is generated:R:F′→(F-F′)
Step 3 Calculate all high support item sets with support greater than the threshold. The association rule support of attribute type is expressed in Eq. (4).
(4)
whereYTandZTare the attribute and type item sets respectively. |E| means total number of events. If the support of the item setCthat contains Item AT in the factual type table is greater than the specified support, as shown in Eq. (5), thenC(AT) is referred to as the high support item set. The high support item set that containsKitems is denoted asFk.

(5)
Step 4 For each frequent item setF, calculate the confidence level of all non-empty subsetsF′ ofF, as shown in Eq.(6).
(6)
IfCRTis greater than the user-specified minimum confidence threshold, then the association rule of content type is generated:RT:F′→(F-F′).
Step 5 Calculate the correlation coefficient betweenRandRT. Select the
3.2 Defect prediction and strategy report generation process
The factual ruleknowledge is processed through the rule knowledge mining process to obtain the rule knowledge, by which the defect prediction can be made to output the defect prediction report. However, defect prediction is not the ultimate goal, only by taking an appropriate countermeasure for the predicted defect could the value of rule knowledge be realized. Defect prediction and strategy generation are controlled by the strategy knowledge layer. The input to the strategy knowledge layer is software project documentation data, while its output is defect prediction report and strategy generation report.
Defect prediction and strategy report generation process mainly includes five steps: project data association, rule matching, defect report generation, strategy rule retrieval, and strategy report generation, as shown in Fig. 2.
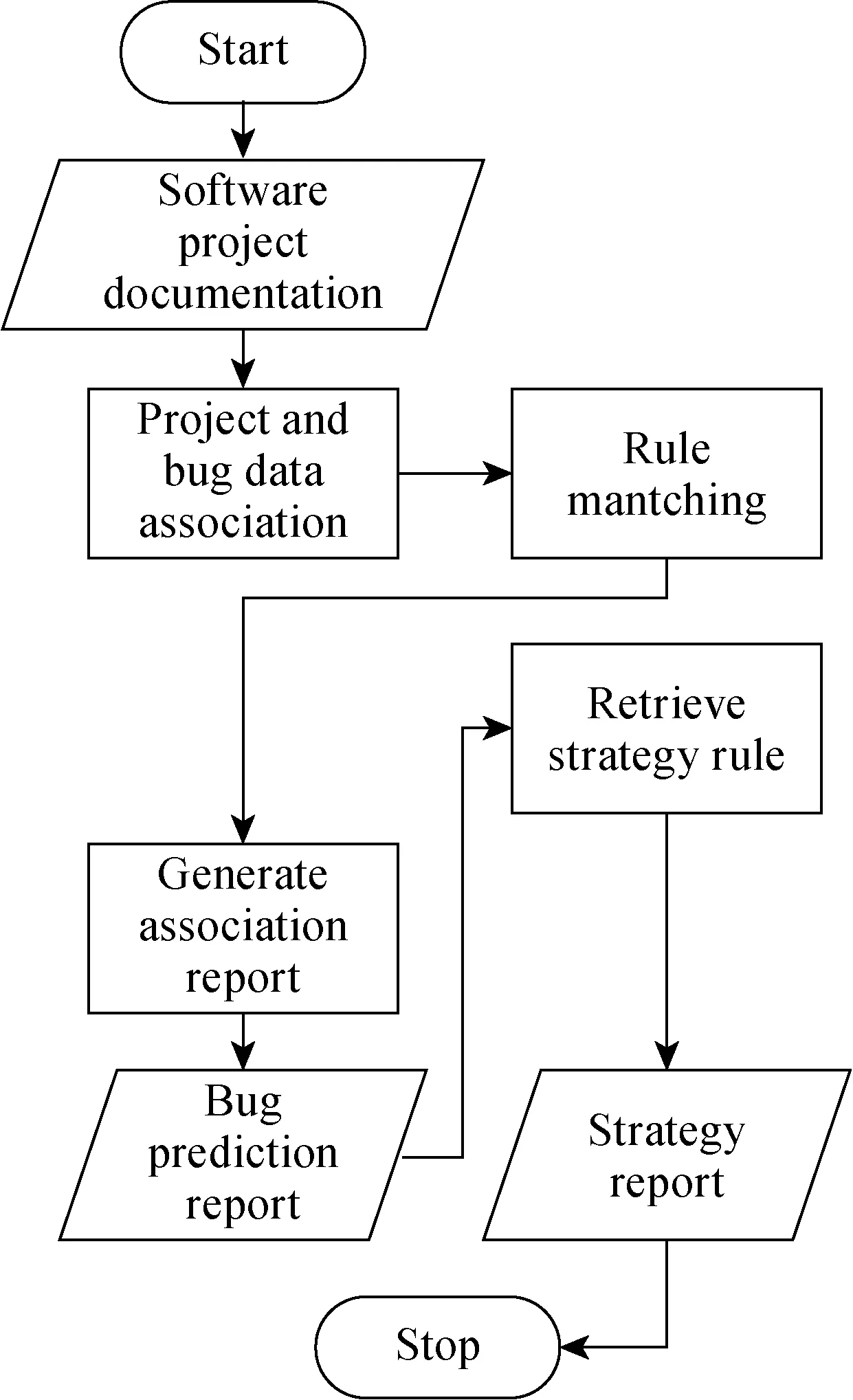
Fig. 2 Defect prediction and strategy report
Step 1 Upon the completion of development, deliver the software to testing company or department, store the data related to software project into the defect management system. The priority is to associate the project data. Data association means the identity linkage between the project data under test and the data in factual knowledge base in the defect management system. Match the company customer data, bug history information, testing history information and other attribute data corresponding to the software project.
Step 2 Match the associated project attribute data and the rules in the rule knowledge layer. In the rule matching process, the priority is to runX→Ymatching process according to the attribute prediction software defects of the software under test, namely according to theRrule. Then runYT→ZTmatching process,Y∈YT.
Step 3 Run defect prediction on the software project and generate a defect report according to the rule knowledge in the rule knowledge layer. The purpose of this defect report is to predict and analyze the probability of a specific module bug in the software and its defect type.
Step 4 The defect report only predicts the risk of module, the appropriate countermeasure for the risk of each module needs to be further generated, namely strategy report. The generation of strategy report is based on strategy rule. The purpose of strategy rule retrieval is to match the strategy rule for each defect type. The strategy rule is based on the staffing of testing project managers. If adequate data is accumulated, strategy rule may also be generated through machine learning. Generate a strategy report based on the matched strategy rule. The strategy report indicates the strategy corresponding to every predicted defect and instructs the generative density of test cases, test user design plan and other test actions.
The classical algorithm for correlation analysis is Apriori. Apriori algorithm can be applied to knowledge extraction, which is a typical single-level knowledge extraction model[5]. The history data of rule base were analyzed, and the comparison of these two models was shown in Fig. 3. The defect prediction rate of the two-level knowledge extraction model was increased by 29%.

Fig. 3 Comparison of the two models
4 Conclusions
This software defect management system uses the three-tier knowledge base architecture to perform knowledge-based management on the data related to software defect that is generated during the software development and testing. In this paper, a knowledge extraction model from the factual knowledge layer to the rule knowledge layer in the system is designed, namely the double-level association rule extraction mode. The factual knowledge is extracted with double-level rule to form the rule knowledge, so as to increase the number of predicted defects, and improve the working efficiency of software. Subsequent work will focus on the defect risk evaluation rule in the rule knowledge layer and the automatic generation model of test case density strategy in the strategy knowledge layer.
 Journal of Donghua University(English Edition)2018年5期
Journal of Donghua University(English Edition)2018年5期
- Journal of Donghua University(English Edition)的其它文章
- Characterization of Oxygen Plasma Modified Polyimide Fibers Interfacial Adhesion Performance by Single Fiber Fragmentation Test
- Measuring Quality of Economic Growth Incorporating Environment and Social Welfare:a Total Productivity Approach with an Application on China
- Reliability Modeling of Phased Mission System with Phase Backup by Stochastic Petri Net
- Research on Software Structure Analysis Technology and Reliability Evaluation Method of Warship Equipment
- Effect of Knowledge about Workers’ Psychological Contract Imbalance on Organizational Performance
- Improved Weight Function for Nonlocal Means Image Denoising