
基于Hadoop的遥感影像业务管理系统设计①
2018-11-14 11:36王敬平
计算机系统应用 2018年11期
张 扬,谢 彬,王敬平,唐 鹏
(华东计算技术研究所,上海 201808)
1 问题分析
遥感影像作为一种特殊的数字图像,具有高分辨率,高覆盖范围,信息量大等特点.在环境监测,资源探测,灾害防护,城市规划,军事行动等方面具有极高的应用价值[1].
陕西某测绘所近些年一直使用单机文件系统如NTFS,进行遥感影像数据存储.随着影像数据不断积累,数据规模达到海量级别,传统解决方案不能满足海量存储需求,同时扩展性很差,不支持多用户数据共享.与此同时,科研人员在进行业务处理时,发现影像读取速度缓慢,进行影像聚类处理时,等待周期较长.
针对以上问题,本文基于Hadoop和三级缓存技术,设计了一套遥感影像业务管理系统,提供影像存储,算法注册,分布式计算的功能.系统测试结果表明,影像读取速度提升2倍以上,计算处理时间缩短三分之一以上.
本文将介绍以下内容: 第2节介绍相关研究状况,第3节是遥感影像管理系统架构设计,第4节介绍四个核心模块的实现原理,第5节给出系统测试方法和结果.
2 相关研究状况
关于如何存储和管理遥感影像数据,国内外学者和商业技术公司都进行了很多相关的研究.这些研究内容主要分为以下三种方式:
1) 采用传统文件系统,如NTFS,EXT,FAT,HFS等.首先将影像数据瓦片化,之后将瓦片数据根据空间位置信息,按照特定的目录结构进行存储.这种方式成本低廉,使用简单,但是容错性和扩展性差,不支持多用户数据共享,并发操作等.
2) 采取关系型数据库(RDBMS),如MySQL,Oracle等.首先将影像数据进行分块,之后将数据块转化成二进制大对象(Binary Large Object),进行入库管理.这种方式查询方式简单,支持多用户数据共享.但是关系型数据库对大对象(Blob)存取效率不高.其次,单个Blob对象一般最大支持4 GB的大小,限制了影像数据块规模.
3) 采用集中式文件系统,如ArcGIS Image Server等.这种方式技术成熟,易于维护.但是这种方式的扩展性较差,同时随着用户规模的增加,中央服务器很容易达到性能瓶颈.
本文采用HDFS分布式存储策略,将系统构建在廉价的PC机之上,具有高度的容错性,可扩展性,易于维护的特点[2,3].同时基于LFU缓存算法,设计了三级缓存模块,用来高速缓存影像数据.两种方式相互结合,前者解决海量存储的需求,后者实现影像数据的快速读取.
除此之外,关于如何处理影像数据,传统的解决方案是将处理算法运行在单一PC机之上.但是很多影像处理算法如K均值、ISODATA等,可以结合Map-Reduce这种分布式处理框架进行改进[4–7].本文设计了算法注册和处理模块,支持单机处理和MapReduce分布式处理两种运行模式.
3 系统架构
如图1所示,系统采用B/S架构设计,为用户提供友好的Web客户端.方便用户进行影像导入,计算处理等操作.

图1 系统架构设计
整套系统分为四个核心模块,分别是三级缓存模块,HDFS读写模块,算法注册模块以及计算处理模块.满足软件设计高内聚,低耦合的标准,每个模块功能如下:
1) 三级缓存模块: 缓存影像数据块和计算处理模块产生的临时数据,加速读取速度.
2) HDFS读写模块: 构建HDFS集群,对外提供读写接口.满足遥感影像海量存储和多用户共享数据的需求.
3) 算法注册模块: 获取算法元数据信息,导入MySQL数据库持久化.
4) 计算处理模块: 根据算法元数据,开启单机处理模式或者MapReduce分布式模式.
影像数据写入时,首先浏览器客户端与三级缓存模块和HDFS读写模块交互,确定写入路径.之后将影像数据从本地同时写入三级缓存模块和HDFS集群.最后客户端端接收到成功写入信号,关闭写入工作流.否则,重新发起写工作.
影像数据读取时,浏览器客户端首先与三级缓存模块交互,查找影像数据.如果查找成功结束读取工作,否则继续与HDFS底层存储模块交互,查找数据块.
算法注册时,浏览器客户端将算法包元数据写入MySQL,算法包同时写入三级缓存模块和HDFS集群.算法运行时,根据算法元数据,开启对应算法运行模式.
4 模块原理和实现
4.1 三级缓存模块
三级缓存模块在系统中功能为以下两点: (1) 缓存影像数据,提高影像读取速率.(2) 缓存影像处理过程中产生的临时数据,减少影像处理时间.
根据上述设计目标,本模块架构设计采用主从设计思想,共分为四个部分: Master、Salve、Client以及切割预处理.如图2所示.

图2 三级缓存模块架构
当影像文件写入Salve节点之前,先对文件进行切割预处理,将影像切割成很多128 MB大小相同的数据块,不足128 MB的数据按实际大小成块.例如一个500 MB的影像文件,会切割成三个128 MB和一个116 MB大小的数据块.
Master负责影像文件元数据管理.元数据采用Inode Tree形式,每个影像文件都是一个Inode.每个Inode记录着: 文件对应的数据块id、名称、大小,存储节点位置等信息.同时维护一张Mount表,记录每个文件三级缓存系统路径与HDFS文件路径的映射关系.例如三级缓存系统根路径”/”对应“hdfs://master:9000/ThreeCache/”.方便影像文件在三级缓存系统和HDFS集群中的映射管理.
Salve负责存储影像数据块,管理本地MEM(内存)、SSD(固态硬盘)和HDD(硬盘),三种硬件设备构成三层缓存结构,其读写速度依次递减.每个数据块根据LFU (Least Frequently Used)算法缓存机制,计算出热度值.数据块根据热度值,依次递减排列,缓存到MEM、SSD、HDD中.
如图3所示,在LFU算法中[8],每个数据块历史访问次数越多,热度值就越高.核心思想是根据历史访问频率来判定未来访问频率.同一影像文件对应的所有数据块具有相同的热度值.

图3 LFU缓存机制算法

算法1.LFU算法1.新加入数据块,放到缓存队列末尾.初始热度值为1.2.缓存队列中数据块每被访问一次,热度值增加1.3.队列重新排序,热度值依次递减.热度值相同的数据块,最近访问时间靠后的,排在前面.4.缓存队列满时,加入新的数据块,淘汰队列末尾数据块到低层次存储结构.5.低层次存储结构重复步骤1、2、3、4.6.三级存储结构满时,淘汰数据块.
Client作为客户端,负责向外提供文件写入和读取的访问接口.当发生影像文件读取时,三级缓存模块工作流程如下:
1) Client接收到影像文件读取请求,发送信息给Master,返回对应数据块位置信息.
2) 根据块位置信息,在Salve中查找.如果命中数据块,就合并数据块成文件发送给对话发起模块,之后Client结束对话.
3) 如果没有命中数据块,则说明数据块被淘汰,返回失败信息给Client.
4) Client当接收到返回的失败信息后,返回查找失败信息给对话发起模块,结束对话.
如果三级缓存系统中没有影像文件,只能向HDFS发起RPC请求,读取数据.同时该影像文件重新加载到三级缓存系统,更新热度值.重新排列缓存系统中数据块位置.
4.2 HDFS读写模块
HDFS读写模块与三级缓存模块都具有影像数据存储功能.但该模块功能在系统中作用是满足影像数据的海量存储需求.
实现方案是构造UploadFile,DownloadFile方法,方法中调用Hadoop提供fileSystem类getFileStatus,copyFromLocalFile,open,delete相关方法.如图4所示,当影像文件写入时,该模块工作流程如下:
1) Web前端获取影像名称,初始路径,目标路径.发送写入请求给HDFS读写模块.
2) HDFS读写模块接收写入请求后,调用UploadFile方法获取初始路径,和目标路径,写入configuration.再调用HDFS的copyFromLocalFile接口.
3) HDFS集群调用DistributedFileSystem对象,的create方法,返回FSDataOutputStream对象,创建一个文件输出流.
4) 调用DistributedFileSystem对象,与Name-Node进行RPC调用,在分布式文件系统创建目标路径.
5) 调用FSDataOutputStream对象,向DataNode开始发起写入请求.原始影像被分割成大小为64k的packet,包含校验码等发送出去.
6) DataNode与其他DataNode(副本放置)组成Pipeline依次传输Packet,写入成功后,返回写入ack信息.
7) DataNode全部写入成功后FSDataOutput-Stream调用close方法,关闭字节流.读写模块检测到写入成功后,发送信号给Web后端,结束整个写入任务.
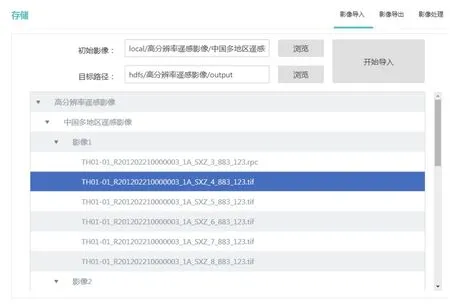
图4 影像导入界面
UploadlFile关键代码如下:


4.3 算法注册管理模块
如图5所示,算法注册模块提供影像处理算法包注册和管理的功能.由于MySQL数据库适合存储结构化数据,同时千万级别以下查询响应延迟低,所以将算法的名称、算法类型、算法包路径等元数据信息,保存在MySQL数据库进行持久化.算法包的数据量不适合使用MySQL,将分别写入三级缓存模块和HDFS模块.

图5 算法注册界面
主要工作流程如下:
1) 用户在浏览器端,填写算法名称,算法版本,算法简介,从本地文件系统选择要注册的算法包.
2) 注册保存后,后端将算法元数据信息发送给MySQL数据库,
3) 算法包信息同时发送给三级缓存模块和HDFS模块,进行写入操作.
4) 使用算法包时候,查询MySQL数据库表,得到算法包路径信息.
5) 根据算法路径信息,先向三级缓存模块查找,如果查找失败,最后调用HDFS的Java接口查找.
数据库表设计结构如表1.

表1 算法注册表结构
4.4 计算处理模块
计算处理模块提供影像处理的功能,支持单机和分布式处理两种模式.算法表结构中Is_MapReduce字段,决定该算法的处理模式.
单机处理模式跟传统ENVI,IMAGINE等软件计算处理方式相同,往往耗时较长.由于很多影像处理算法可以结合MapReduce进行改进,例如K均值,ISODATA[9–11].只要实现 Map 和 Reduce 两个函数,就可以采用分布式处理模式,如算法2.
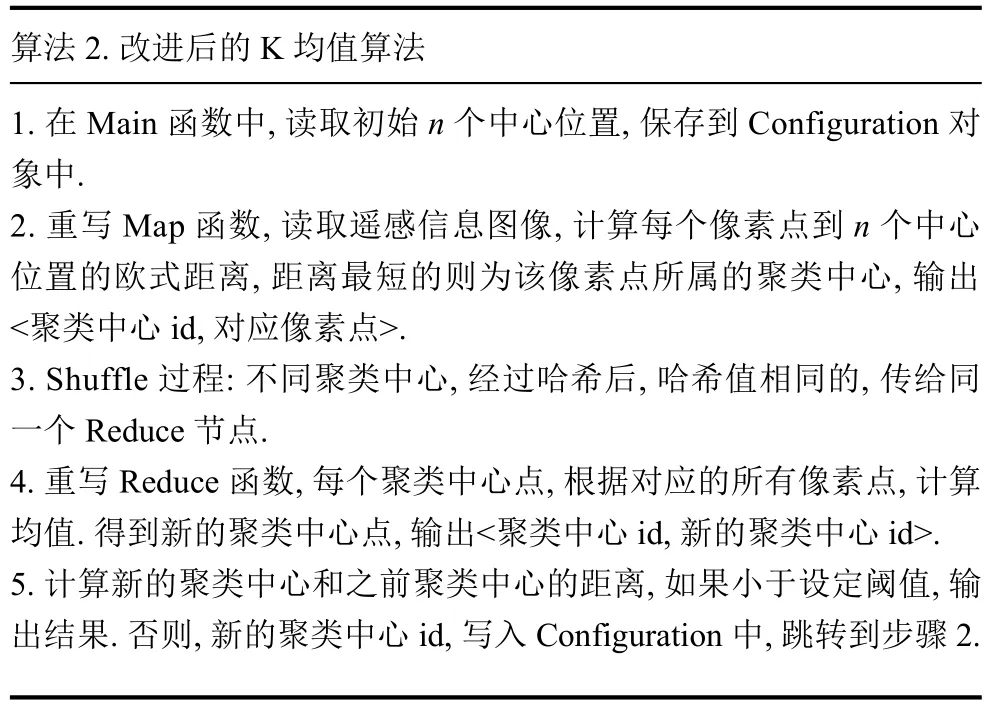
算法2.改进后的K均值算法1.在Main函数中,读取初始n个中心位置,保存到Configuration对象中.2.重写Map函数,读取遥感信息图像,计算每个像素点到n个中心位置的欧式距离,距离最短的则为该像素点所属的聚类中心,输出<聚类中心id,对应像素点>.3.Shuffle过程: 不同聚类中心,经过哈希后,哈希值相同的,传给同一个Reduce节点.4.重写Reduce函数,每个聚类中心点,根据对应的所有像素点,计算均值.得到新的聚类中心点,输出<聚类中心id,新的聚类中心id>.5.计算新的聚类中心和之前聚类中心的距离,如果小于设定阈值,输出结果.否则,新的聚类中心id,写入Configuration中,跳转到步骤2.
基于上述算法,该模块工作流程如下:
1) 计算模块接收到算法包元信息,根据 Is_Map Reduce值,若为真,开启分布式处理模式.
2) 解析算法包信息,开启多个Map任务,产生的新的键值对写入本地三级缓存系统,进行分区.
3) 新的键值对,按照分区序号通过Shuffle过程,发送给不同Reduce节点.
4) 不同Reduce节点,按照算法包实现的Reduce函数,产生新的键值对,写入三级缓存系统,输出结果.
5 系统性能测试
5.1 硬件环境
由6台普通PC机,千兆网卡,千兆交换机组成服务集群.一个作为NameNode主节点或三级缓存模块的Client和Master,其它作为DataNode或三级缓存的salve节点.其中主节点装载MySQL数据库,版本为5.7.20.节点配置如表2.
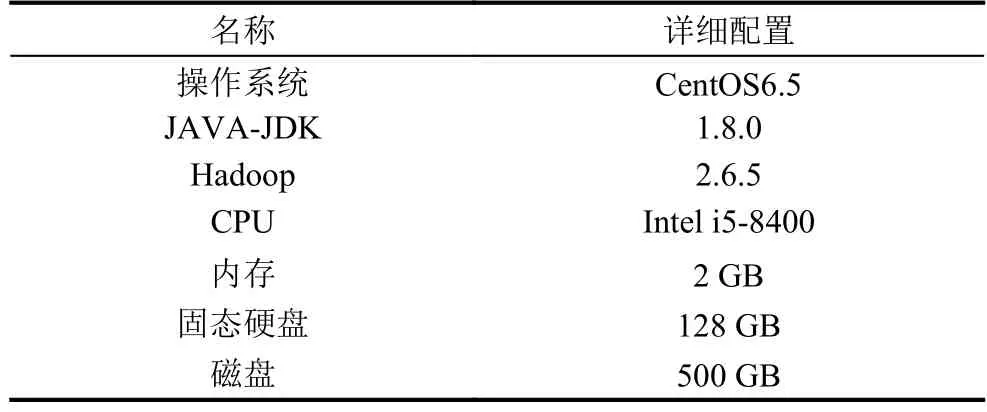
表2 集群软件及硬件配置
5.2 影像读取速度测试
测试条件采用145张TIFF格式的影像数据,单幅大小约为178 MB,总容量为25.81 GB.Hadoop配置文件hdfs-site.xml参数设定如下:
--块大小128 M
--副本数量为3
先直接使用HDFS hadoop fs-get命令,进行读取测试.再测试加入三级缓存模块后的读取速度测试.每种测试方法反复进行5次,记录耗费时间.测试结果如图6所示.

图6 影像读取速度测试
根据测试数据,计算出HDFS读取影像耗费时间平均为466.72 s,平均读取速度为55.30 m/s.加入三级缓存模块后,平均耗费时间为200.06 s,平均读取速度为129.01 m/s.实验结果表明,三级缓存模块可以将影像读取速度提升2倍以上,有效解决影像数据读取缓慢的问题.
另外注意到,三级缓存模块第一次读取耗费时间稍长,之后就趋于平稳.经过分析,原因是首次读取时,很多数据块可能位于底层次存储结构中.再次读取时,数据块热度值更新,在缓存队列中的位置发生前移.
5.3 影像聚类处理测试
分别输入178 MB、365 MB、712 MB、1424 MB的影像数据,模拟不同数据量对聚类时间的影响.再使用单个节点,模拟传统单节点聚类处理过程.最后分别使用2个,3个,4个,5个计算节点,模拟不同集群性能对处理时间的影响.
算法包中Main函数,调用JobConf中setNumReduce Task方法,将Reduce数量设置和计算节点数量相等.测试结果如图7所示.
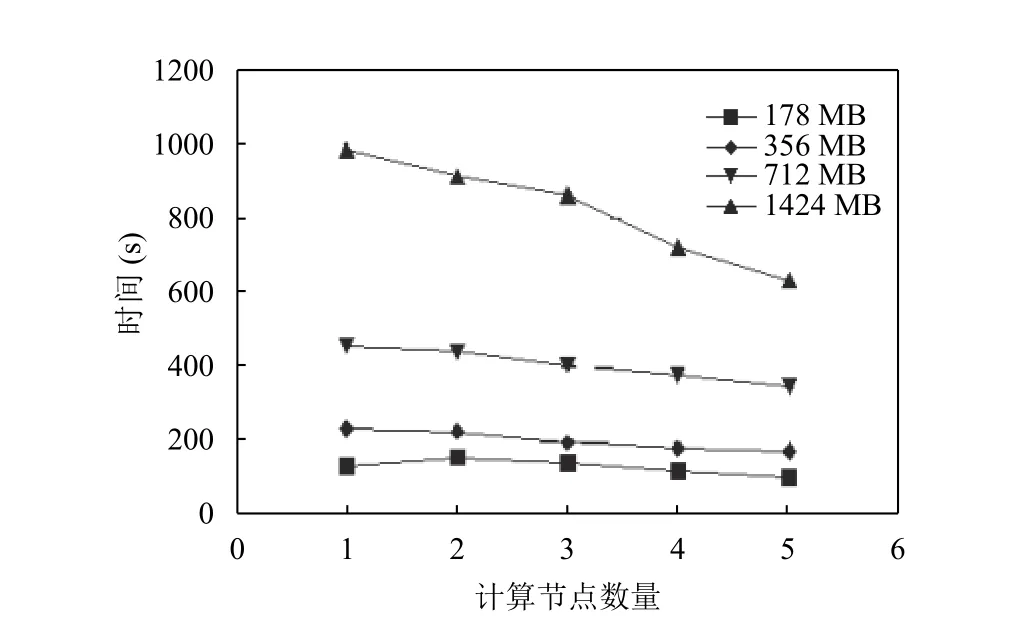
图7 聚类处理时间测试
根据实验结果发现,在数据量比较小的时候,随着节点数量增加,时间曲线下降不明显.尤其是当数据规模只有178 MB情况下,两个计算节点处理时间会稍许增加.这是因为开启多节点进行聚类处理,任务切割、网络通信时间会增加.数据规模不大情况下,反而导致整体时间开销增加.
随着输入数据量的增大,可以发现时间曲线下降效果较为显著.当达到1 GB数据规模时,时间开销较传统单节点处理方式,可以减少40%以上.
6 总结和展望
本文根据陕西某测绘所遇到的影像存储需求量大,读写速度慢,计算时间周期长,多用户无法共享数据等问题.基于Hadoop开源框架和LFU算法,构建了一套影像业务管理系统,提供影像存储,算法注册,影像处理功能.实验结果证明,该系统有效解决了上述问题,其中三级缓存模块显著提升了整体系统的性能.
由于算法注册模块是通用模块,同时支持基于单节点开发的算法包,以及基于MapReduce计算框架开发的算法包.之后工作,可以就ISODATA,Sobel边缘检测[12]等常见的遥感影像处理算法如何结合Map-Reduce框架,进行算法包的开发研究.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
成都信息工程大学学报(2022年3期)2022-07-21
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
火力与指挥控制(2020年1期)2020-03-27
World Journal of Diabetes(2019年3期)2019-04-16
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
互联网天地(2016年1期)2016-05-04
