
基于大数据的煤矿安全监控预警平台研究
2018-11-12 03:13韩建萍
数字通信世界 2018年10期
韩建萍
(山西能源学院,太原 030600)
随着信息通信技术的快速发展和信息化系统的建设,煤矿企业已经采集和积累了大量的数据。这些数据的有效处理和分析在煤矿安全生产中发挥着重要作用[1-3]。已有研究中,通过统一规划和建设,文献[4-5]已经实现了多个专业信息平台的数据共享,文献[6-8]已经实现了大量多源异构数据的分析,并应用到煤矿安全管理[8]。但是,已有研究中,不同时间尺度采样所获取的数据未得到充分挖掘和有效利用,尤其是历史数据的规律性研究、归档等大数据分析工作的成果与实时监控数据的联合分析能力需要进一步提高。为解决这个问题,本文提出了一种基于大数据的煤矿安全监控预警平台,有效地将大数据技术应用到了煤矿安全管理中。在数据处理层,本文提出了一种基于标签的单因素与多因素分级共享的大数据开放引擎架构,将实时数据与历史数据进行联合分析和挖掘,实现了分析模型的共享使用。根据真实应用场景下平台的性能要求,设计了煤矿安全监控预警平台的技术选型和技术架构。
1 功能需求分析
通过对已有研究分析可知,当前产生煤矿安全事件主要原因包括设备故障、管理失误、环境因素超标、从业人员操作失误等[2,6,7]。其中,管理失误、从业人员操作失误属于规范化管理范畴。本文主要研究如何对设备故障、环境因素超标进行实时预警,从而减少煤矿安全事故的发生。为了实现不同时间尺度采样所获取数据的充分挖掘和有效利用,本文提出了基于大数据的煤矿安全监控预警平台建设的原则为:事前实时预警,防患于未然;事后分析总结教训,杜绝再次发生;采用人工智能和大数据技术,实现快速智能化预警。
基于此,通过分析煤矿事故发生的因素,根据我国煤矿信息化水平和安全管理特点,确定了基于大数据的煤矿安全监控预警平台的功能需求包括:一是需要实现煤矿安全监控的数据采集和管理;二是需要实现煤矿安全事故的快速智能化预警。
2 平台架构
为满足平台的功能需求,通过分析煤矿事故发生的因素,本文设计了基于大数据的煤矿安全监控预警平台,平台架构如图1所示,包括数据采集层、数据优化层、数据处理层、数据应用层。
在数据采集层,通过与环境监控平台、设备监控平台、安全风险监控平台、井下传送平台等系统对接,实现毫秒级的数据采集,以便实时监控设备运行状态。需要采集的煤矿安全生产相关实时数据主要包括环境类数据、机器设备类数据。环境类数据主要包括瓦斯数据、空气含量数据、煤矿压力数据、煤矿水资源数据、电磁辐射数据、工作面开采速度等实时数据。机器设备类数据主要包括各种设备的功率数据、温度数据、使用时长等实时数据。为了更好地进行数据分析,需要获得采煤技术和操作规范等基础数据、区域地理和地质等基础数据、人员和设备基础信息等煤矿安全生产相关的基础数据作为辅助参考因素。
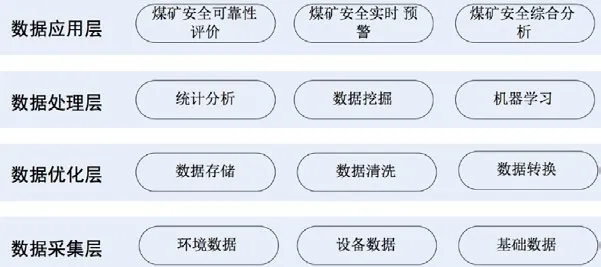
图1 基于大数据的煤矿安全监控预警平台
在数据优化层,主要实现数据的存储、清洗、转换。考虑到数据的类型多样、数据采集时间较短等特点,在数据存储时,采用分布式文件平台、NoSql数据库,确保数据存储平台的实时性和可靠性。在数据清洗时,采用填补空缺数据、平滑噪声数据、识别异常值等措施,确保数据的可用性。在数据转换时,通过制定数据转换的标准,明确煤矿数据交换内容和交换协议,将多个数据源的数据合并成一致的、无冗余的数据存储。
在数据处理层,采用统计分析、机器学习、数据挖掘等技术和算法,基于设备、环境的实时数据、历史数据,通过建立事故分析模型、可靠性评价模型、预警模型等,实现数据的统计分析和挖掘。为了提高数据处理结果的共用性并实现实时预警,根据煤矿安全事件的历史数据和相关因素,对设备、环境等建立标签,便于快速响应和发现安全隐患。数据处理层将在下一节进行详细描述。
在数据应用层,通过分析煤矿安全事件的关联关系,基于数据处理层的数据分析模型,实现煤矿安全可靠性评价、煤矿安全事故综合分析、煤矿安全实时预警,从而实现实时和非实时数据的有效利用,更好的确保煤矿安全。一是煤矿安全事故综合分析;二是煤矿安全可靠性评价;三是煤矿安全实时预警。为了便于管理,本文提出基于危险源的煤矿安全实时预警机制,可以将煤矿安全的预警分为自燃预警、设备故障预警、瓦斯浓度预警、水害预警等。
3 数据处理层关键技术实现
为了将历史数据的规律性研究成果与实时监控数据的进行联合分析,实现煤矿安全事故的快速预警,在实现数据处理层时,本文设计了一种基于标签的单因素与多因素分级共享的大数据开放引擎架构。该架构如图2所示,包括单因素标签层、关联分析和深度挖掘层、多因素分析模型层。一是单因素标签层:为了提高实时数据分析和响应速度,将设备和环境的相关因素中涉及安全的关键数据源抽取出来构成单因素。基于单因素的数据特征,构造出风险评级、事故发生率等标签,通过标签可以非常快速的反映煤矿安全关键因素的状态,实现煤矿安全的快速响应。二是关联分析与深度挖掘层:该层包含Apriori、FP-Growth、DMFIA等关联算法[9],以及逻辑回归、支持向量机、聚类、决策树等机器学习算法。

图2 大数据开放引擎体系结构
这些算法可以将大数据技术与瓦斯突出、煤矿水害、煤矿火灾等事故现象相结合,建立基于大数据煤矿灾害预警模型。三是多因素分析模型层:为了实现应用层的各项功能,充分利用单因素标签的已有知识,通过关联分析和深度挖掘的相关算法,综合多个因素标签的关系,生成可靠性评价模型、实时预警模型、综合分析模型等三大类模型。下面对单因素标签、多因素分析模型进行详细介绍。
3.1 单因素标签
通常来说,标签是对事物属性状态的一种结论性描述,是对属性状态的一种高度精炼,是一种把抽象数据进行形象化描述的方法,不但有助于相关人员对抽象数据进行理解,而且容易实现事物属性状态的快速共享[10-12]。为实现毫秒级的数据控制和对事故的快速预警,需要建立足够多的标签数据库。基于此,对于采集的数据源,抽取安全相关的危险源,梳理安全因素并建立标签,实现快速响应、资源共享。例如,在环境方面,建立水压、水位、涌水量、瓦斯含量、瓦斯涌出量、瓦斯压力、氧气浓度等危险源的单因素标签。在设备方面,建立水泵、变压器、通风机、采煤机、掘进机等危险源的单因素标签。这些标签作为煤矿环境和设备运行状态的虚拟代表,各种煤矿环境和设备的标签能够准确反映其运行状态。这样对于煤矿安全的实时预警起到非常关键的作用。本文提出的单因素标签包括事故发生概率标签、风险评级标签。
(1)事故发生概率标签。分析当前因素和事故发生数据,发掘事故发生概率与当前因素的内在关联关系,从而利用当前因素计算煤矿发生安全生产事故的概率。通过学习历史安全事故发生规律,建立当前因素的安全事故预测模型,并据此设定警戒区间,当超出预警区间时,则进行预警,以防范安全事故发生。例如:变压器故障事故发生率需要使用变压器额定负荷LR、实时运行负荷LT、环境温度、起始负荷以及不同边界下的主变过负荷剩余时间t等数据源。变压器故障事故发生率标签分类为正常、1级预警、2级预警、3级预警。当LTLR≤1时,事故发生率标签为正常;当LTLR>1且剩余运行时间t>30min 时,事故发生率标签为1级;当LTLR>1且剩余运行时间10min<t LTLR<30min时,事故发生率标签为2级;当>1且剩余运行时间1min<t<10min时,事故发生率标签为3级。
(2)风险评级标签。通过数据分析技术对煤矿安全生产历史数据进行分析,评估煤矿安全生产的风险等级。基于此对当前因素进行异常检测时,如发生风险评级预警,可及时进行防范,避免安全事故的发生。例如:以变压器为例,通过分析事故发生率标签、变压器组网、事故知识库等数据源,可以将风险评级标签分为正常、1级预警、2级预警。当事故发生率标签为正常时,风险评级标签为正常;当事故发生率标签为非正常、并且变压器组网包含后备电力时,风险评级标签为1级预警;当事故发生率标签为非正常,变压器组网不包含后备电力、且事故知识库中包含由此导致事故时,风险评级标签为2级预警。
3.2 多因素分析模型
预警模型已有较多研究成果,但是已有研究模型都比较独立,缺少共用[5-6,13]。为了实现应用层的各项功能,充分利用单因素标签的已有知识,通过关联分析和深度挖掘的相关算法,综合多个因素标签的关系,生成可靠性评价模型、实时预警模型、综合分析模型等三大类模型。例如:以通风系统可靠性评价为例,其需考虑通风系统、瓦斯监测系统、设备监测系统等多种因素和基础数据。通过共用单因素标签,可以快速生成所需的各种高层次模型。以煤矿水害的相关研究为例,可以通过分析水压、水位、涌水量等多种相关的单因素数据,采用关联分析算法和深度挖掘算法,建立突水水源判别模型、突水量等级预测模型、水害安全评价模型等基础模型。基于这些基础模型,可以快速生成应用层的水害实时预警模型,用于煤矿水害事故的实时预警[14-15]。
4 技术实现
在技术实现部分,基于对已有大数据平台的分析[3,5,16],结合煤矿的现场实际情况和大数据中流计算框架,提出了基于大数据的煤矿安全监控预警平台技术实现框架如图3所示。该技术实现框架包括前端采集层、前端工作站层、后端集群层。前端采集层主要实现与现有采集系统的对接。前端工作站层通过获取采集的数据,并根据本地规则、本地缓存,实时确定是否发出预警,实现煤矿安全实时预警的功能。后端集群层通过快速的数据存储、近实时状态调整、模型发现及状态调整,实现煤矿安全可靠性评价、煤矿安全综合分析的功能。在技术选型方面,本文采用Flume、kaf ka、HDFS构建采集架构,采用spark、spark streaming、storm构建计算架构,从而实现煤矿安全数据的高效采集,提高平台预警的实时性和准确性。下面对前端工作站层和后端集群层进行详细介绍。
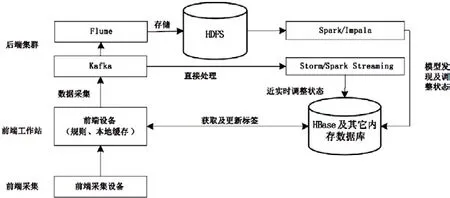
图3 平台技术实现
在前端工作站层,需要实现平台在毫秒级对事件作出可靠的响应。因为本地缓存可以实现亚微妙级别的数据获取延迟。为确保实时性,采用HBase 及其它内存数据库,实现快速地获取和更新数据。为了克服本地缓存的内存大小限制,通过配置HBase以保证能够在块缓存中找到所需要的数据,以分布式内存缓存方式在集群节点中分发数据。如图3所示,前端设备根据采集的数据生成单因素标签,并与HBase中的标签数据进行对比,可以快速判断是否进行预警。
在后端集群层,平台需要每秒处理数百万条数据。本文采取快速的数据存储、近实时的状态调整、非实时的模型发现及状态调整3个措施解决此问题:一是快速的数据存储:前端设备与后端集群之间,建立消息队列平台Kaf ka,由Kaf ka将数据发送给Flume,由Flume实现数据的HDFS存储。二是近实时的状态调整:为实现预警的实时性,通常需要在事件发生之后的若干秒到几分钟内完成进行响应。为实现近实时的状态分析,由Kaf ka将数据发送给Storm/Spark Streaming,通过快速计算的能力,实现近实时的事件分析。三是非实时的模型发现及状态调整:为充分利用历史事件数据,需要在事件发送后的若干小时或几天内完成历史事件的分析并挖掘其中隐含的原因和规律。本文采用Spark/Impala组件针对标签数据进行监督学习、无监督学习;例如,采用支持向量机和贝叶斯网络,针对标签数据的监督学习,可以区分风险数据;采用K-Means聚类算法能够对相似事件进行聚类,从而对特定的类别进行判定。
5 结束语
为解决煤矿安全的实时数据与历史数据未得到充分联合分析和挖掘的问题,本文分析了煤矿事故发生的因素,设计了基于大数据的煤矿安全监控预警平台。为了将实时数据与历史数据进行充分联合分析和挖掘,在数据处理层,本文提出了一种基于标签的单因素与多因素分级共享的大数据开放引擎体系架构。该架构不但可以结合实时监控数据进行实时响应,而且可以生成多种模型,便于应用层进行共享使用。通过分析可知,该平台能够提前发现、分析和判断影响煤矿安全生产的状态和可能导致事故发生的数据,及时发布安全生产预警信息,最大限度地降低事故发生概率。
猜你喜欢
江苏安全生产(2022年4期)2022-05-23
今日农业(2019年12期)2019-08-13
中国煤炭工业(2019年1期)2019-06-17
中国煤炭工业(2019年1期)2019-06-17
劳动保护(2018年8期)2018-09-12
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
现代园艺(2017年22期)2018-01-19
公民与法治(2016年10期)2016-05-17
火控雷达技术(2016年3期)2016-02-06
