
深入浅出ELK
2018-11-07 02:47
网络安全和信息化 2018年8期
ELK简介
ELK的涵义
E代 表 ElasticSearch,是整个ELK的心脏,它负责索引的创建、搜索、分析以及数据的存储等工作,这个组将在后面做详细介绍。
L代表Logstash,是用来做数据采集、接收、处理和转发的工具,它讲采集来的数据经过分析和处理以后,将数据发送到ElasticSearch存储。它本身支持非常多的数据源。
K代表Kibana,作用是负责将ES中数据进行炫酷的展示。
整理概括一下整个ELK就是:
Logstash负责数据采集、分析和处理,然后将数据发送给ElasticSearch做进一步的存储、分析和搜索,最后Kibana讲ElasticSearch中的数据炫酷地展示出来。
ELK常用架构
ELK的常用架构如图1所示,使用Logstash Shipper在机器上采集相关的数据或日志,你可以理解为Logstash的一个agent,中间使用Redis做队列,也有很多的公司使用Kafka来代替Redis。
ELK在业界的使用情况
目前ELK比较活,社区也很活跃,有很业务都在使用,主要分为三类应用:
1.全文检索
如GitHub和维基百科。
2.日志监控类
比如腾讯云监控、斗鱼日志分析平台。
3.数据分析和查询
比如 :DELL,Sprint。
此外国外还有一些公司用ES来存储地理位置数据,如Foursquare公司,结合搜索和地理位置两者提供更优质的服务。
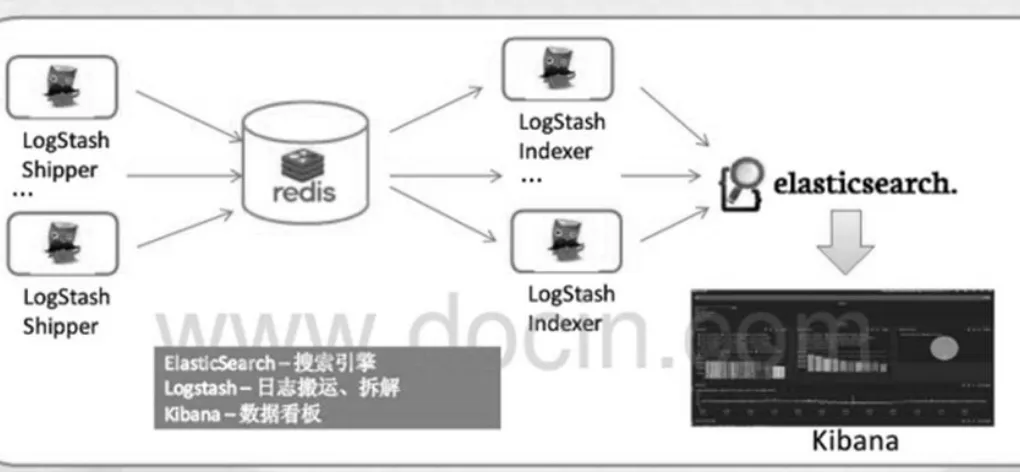
图1 ELK的常用架构
ES技术细节
ES技术细节部分主要介绍如下几个方面。
ES的特性
1.Base on Apache Lucense
Lucense是高性能的搜索引擎库,提供了查询引擎、搜索引擎和文本分析引擎。但使用Lucense成本很高,需要掌握很多关于搜索的知识。而ES使用Lucense作为底层架构,在其上做了大量的易用性、扩展性、容灾及性能方面工作,使得用户经过很少的配置就可以快速ES进行数据存储和检索。
2.Distributed and horizontally scalable
ES是分布式的,可以水平扩展,比如添加节点的时候能自动均衡数据。
3.Full-text search and powerful search
ES支持前文支持全文索引,并且搜索功能非常强大。
4.Document & Json
ES是基于文档的强大组件,交互数据全部采用Json标准格式。
5.Restful API

图2 ES集群组成
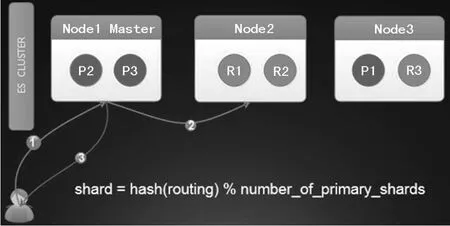
图3 ES的写入简图
6.Open Source
7.Query DSL
ES提供了基于JSON的query DSL查询语言,传统的SQL语句很容易转化成query DSL。后面做的关于MySQL和ES的性能比对也是将标准SQL改写成query DSL实现的。Translog为ES提供高性能以及数据安全保障。
ES集群组成
从图2中可以看到,ES集群是由多个节点组成,上图中有1个master节点和2个data节点组成,并且创建了1个索引,索引有4个数据分片和1个副本组成。
ES的写逻辑
如图3所示,ES的写操作分为两类,一类是涉及到路由变更的索引创建和删除(简称为索引的写入),另一类是基于文档的创建、更新和删除(简称为文档的写入)。
下面单独来进行介绍:
1.索引的写入
无论是索引的创建还是删除,都必须在master上进行。因此,如果写入的请求是发到了非master节点,该节点会讲对应的创建或者删除的请求转发给master,master会创建并修改元数据和路由信息,并将对应的修改同步到其他的候选的master机器上,至少需要需要一半以上的候选master返回后才算写入成功。
2.文档的写入
文档的写入的前提是所有的写入都必须先发送到主分片上,大致的步骤为:
(1)文档写入请求发送到任意的一个节点。
(2)节点根据shard =hash(routing) % number_of_primary_shards确定数据所在的分片及根据元数据确认主分片是在哪台机器。
(3)在主分片上执行写入操作和translog写入操作,并将请求发送到副本上进行写入和translog写入。
(4)默认是同步操作,必须主分片和副本分片都些成功财返回结果,也可以人为调整为异步操作,不过会有数据安全性问题。
注意:默认ES提供近实时的搜索,也就是说文档写入或更新后不是马上就能搜索出最新的变更,默认需要过1秒reflush后才能看到,如果业务对实时性要求非常高,也可将reflush的相关的参数设置为request,即有新的请求就执行reflush的操作,这种方式性能会较差。此外还可调用reflush的API手动进行reflush操作。
ES的读逻辑
ES的读逻辑如图4所示。
ES查询时如果指定了routing相关的值,就会只扫描确定的1个或少数文档,如果没有指定routing相关的值,就需要扫描所有分片。因此还会涉及到查询的拆分和合并的步骤。详情如下:
(1)查询请求发送到任意一个节点。
(2)如果指定了routing相关值,根据shard = hash(routing) % number_of_primary_shards公式就能直接计算出请求的数据所在的分片,然后将请求发送到对应的分片就OK。如果指定routing的相关值,那么会发送到对应查询涉及到的所有分片(这就是请求拆分)。
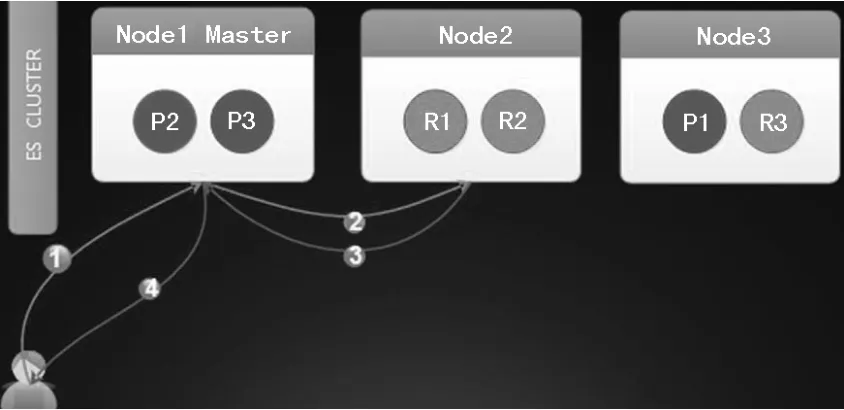
图4 ES的读逻辑
(3)如果查询只涉及到1个分片,查询的分片所在的机器返回查询结果到初始请求的节点,初始请求节点再将数据返回给业务。而如果查询涉及到多个分片,初始节点就会将请发送给多个分片并发查询,此时查询的分片所在的机器返回查询结果到初始请求的节点后,初始节点还需要再进行结果的合并。初始节点将合并后的数据返回个业务。
ES的容灾
ES有很完善的容灾机制,候选master一般有多个,data节点也有多个,因此节点异常的时候通过将访问切换到别的节点来容灾。具体流程包含如下几个流程:
1.故障发现
故障发现如图5所示。从图中可以看出,Master会去ping各个其他的节点,图中只画了datanode节点。而其他的节点也会去ping master节点,确认master节点是否正常。默认ping规则如下:
Discovery.zen.fd.ping_interval=1s 默认每隔1秒探测1次
Discovery.zen.fd.ping_timeout=30s 默认ping探测的超时时间为30秒
Discovery.zen.fd.ping_retry=3 默认重试3次
备注:以上参数可以根据自己的网络情况和业务需求进行调整。
2.节点切换
master节点切换:
当其他节点探测到master异常并达到重试次数后,候选节点会进行竞争,选master的具体规则如下。
(1)每次选举每个节点会把自己所知道的候选master节点根据nodeid进行一次排序,然后选出第1个节点,暂且认为它是master节点。
(2)如果对某个节点的投票数达到候选master数/2+1个并且该节点也选举自己为master,那么这个节点即为master。否则重新选举。
备注:之所以节点的投票数需要达到候选master数/2+1,是为了防止脑裂的问题发生。
data节点切换:
当master节点检测到某个data节点有异常时,操作大致如下。
(1)master剔除该data节点,如果ES数据配置了1份副本保存,此时不存在数据丢失的风险,集群状态为yelllow。如果数据没有配置副本保存,则存在数据丢失,集群状态为red。
(2)master对找出异常的data节点对应的所有的数据分片,如果是主分片,则将其他节点上的副本分片提升为主分片,全部主分片恢复后,异常data节点涉及的数据读写都恢复正常。
(3)业务恢复正常以后,master会将异常节点的数据迁移到正常的节点。
(4)当全部数据迁移完成后,集群状态恢复为green。

图5 故障发现
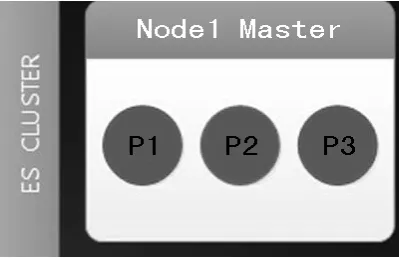
图6 一个节点的ES Cluster
ES的扩容
ES设计成能让你灵活地扩缩容模型,当添加或减少data节点时,ES会自动对数据进行均衡。如下几个简图能让你几秒钟了解ES的扩容问题,下面几个图的索引设置为number_of_shards=3&& number_of_replicas=1,即索引为3个分片且每个分片有1个副本。
1.一个节点的ES Cluster
从图6中可以看到虽然设置了1个副本,但是datanode1只分配了3个主分片。这是因为ES认为如果副本和主分片在1台机器上和没有副本的效果一样,当那台机器异常时,数据一样丢失。因此ES没有在那台机器上分配副本分片。
2.扩容一个节点后的ES Cluster
从图7中,可以看到添加1个节点后,data节点2分配了2个副本。
3.再扩容一个节点后的ES Cluster
如 图 8,data节 点 1上的P1被移动到data节 点 3,data节 点 2上的R3被移动到了data节点3,这是因为添加节点后,ES会自动均衡数据。
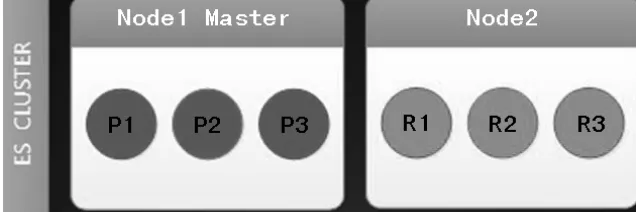
图7 扩容一个节点后的ES Cluster

图8 再扩容一个节点后的ES Cluster
ES让人惊喜的功能
做为一个运维人员,在学习ES的时候,遇到了很多让人惊喜的功能,整理出来和大家共享。
ES的group功能
ES的group功 能 和HBase的group功能类似,可以将某些节点放到某一个group中,从而实现业务之间的隔离。
比如要将重点业务和普通业务隔离开来的话,就可以将重点业务放到指定的某个组,这个组不存在过保的设备,负载也比较低。而将普通业务放到普通的组中,这各组的设备由于比较老,故障率会比较高,组内的机器负载也会高一些。

图9 ES的group功能
如图9所示,分别包含 groupA和 groupB,其 中groupA中保存了某些索引,groupB中也保存着某些分片。ES有专门的参数控制索引可存储在某个group或节点,具体参数如下:

ES部落节点功能
ES从1.0版本开始支持使用部落节点(tribe node),所谓的部落节点,就是作为联合客户端提供访问多个ElasticSearch集群的能力。业务只需要访问部落节点,就可以获取多个ES集群的数据。并且可以通过部落节点写入数据,写入数据的时候部落节点会将写入请求转发到后端的集群节点进行数据写入。但是不支持创建索引的操作。
注意:如果部落节点对应后端的ES集群含有相同的索引名称就会出现莫名其妙的问题,因为ES的默认行为是从中选择一个。也就是说如果后端2个集群含有相同的索引名字,那么知会有一个索引会被访问到。
部落节点的图解如图10所示。
ES的IO流控功能
ES还有个比较好的功能就是IO流控的功能,这个功能对于分布式存储是非常必要的,比如可以限制文件合并的时候的IO,从而使系统更平稳地运行。ES主要有节点级和索引级两个限流机制。分别介绍如下:
1.节点级别限流sec

2.索引级别限流


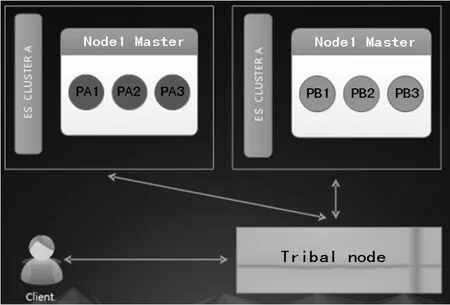
图10 ES部落节点功能
ES的慢日志功能
ES有类似于MySQL的慢查询功能,可以记录下慢的操作,从而让运维人员能通过慢的操作找到问题所在。
默认情况下慢日志是不开启的,分别有query、fetch、index三类动作定义,如下是一个query的慢日志定义:


上面设置的意思如下:
查询慢于10秒输出一个WARN日志。
获取慢于500毫秒输出一个DEBUG日志。
索引慢于5秒输出一个INFO日志。
ES的发现热点功能
ES有个查询集群热点线程的功能,这个功能在集群突然变慢的场景下特别有用,它将帮助你找到消耗资源最多的线程。热点线程的使用方法如下:

返回的结果中含有线程所在的节点信息、线程消耗资源的情况、线程名称以及相关的堆栈信息。
猜你喜欢
词学(2022年1期)2022-10-27
计算机工程与应用(2022年2期)2022-01-25
山西电子技术(2021年3期)2021-06-28
数学物理学报(2020年5期)2020-11-26
网络安全技术与应用(2020年1期)2020-01-07
通信技术(2019年9期)2019-10-09
网络安全和信息化(2019年8期)2019-08-28
计算机系统应用(2019年2期)2019-04-10
火控雷达技术(2018年4期)2019-01-15
现代电子技术(2015年2期)2015-09-18
