
基于高光谱和卷积神经网络的鲜枣黑斑病检测
2018-11-06 12:38:30孙海霞张淑娟刘蒋龙陈彩虹李成吉邢书海
山西农业大学学报(自然科学版) 2018年11期
孙海霞,张淑娟,刘蒋龙,陈彩虹,李成吉,邢书海
(山西农业大学 工学院,山西 太谷 030801)
黑斑病是一种由真菌浸染而引发的鲜枣常见病,黑斑病果表面出现褐色至黑色的大小不一的不规则病斑,病变组织为浅黄色或褐色,果肉变苦变硬[1,2]。目前,消费者对水果的营养性、安全性的要求逐渐提高。黑斑病枣果的质量下降,经济价值降低,严重影响枣果的定质定价。
病害检测是水果安全检测的一项重要内容。目前,黑斑病果的分选主要采用人工识别的方式,效率低且难以精确分选。高光谱成像技术具有快速、无损、实时等优点,已成功应用于柑橘[3]、苹果[4]等水果病害检测中。在鲜枣外部品质检测中,主要针对鲜枣外部损伤[5]、虫害[6]、裂纹[7]进行了相关研究,以实现各类缺陷和完好样本的分类。在光谱建模方面,由于不同年份下,果树的生长环境等存在一定差异,会影响果实的质量,致使果实的光谱响应存在一定差异,但对鲜枣外部缺陷特征识别的影响还不确定。在建模方法中,卷积神经网络作为一种典型的深度学习技术,可抽取更多的抽象特征,在图像处理等方面已很好的被应用[8,9]。高光谱成像中光谱通道数量多、空间变异性大,Chen等[10]将卷积神经网络(Convolutional Neural Networks,CNN)用于高光谱分类中,从而使水果CNN高光谱检测有了可行性依据。
为实现鲜枣黑斑特征的高效稳定识别,本研究利用高光谱成像技术,采集不同年份的完好和黑斑鲜枣的光谱信息,通过全部波段和特征波段,采用偏最小二乘判别分析(Partial Least Squares-Discriminant Analysis,PLS-DA)和误差反向传播神经网络(Back Propagation Neural Networks,BP-NN)进行单一年份和联合年份的病害判别,寻找稳健的识别模型。然后,采用连续投影算法(Successive Projections Algorithm,SPA)提取特征波长并建立判别模型。最后,进行主成分分析,针对主成分图像采用BP-NN和CNN建立病害判别模型。
1 材料与方法
1.1 试验材料
2016年和2017年的鲜枣收获期,在山西省太谷县小白村果园采集黑斑和完好壶瓶枣样本,采后当天运达实验室。然后筛选样本,每年试验中分别选定240个试验样本,其中120个完好样本、60个轻度黑斑样本、60个重度黑斑样本。将黑斑区域颜色浅,黑斑分布分散,黑斑面积小于50%的样本定义为轻度黑斑枣。黑斑区域颜色深,黑斑分布集中,黑斑面积大于等于50%的样本定义为重度黑斑枣。每年试验中,按照3∶1的比例,采用Kennard-Stone算法[11]划分校正集和预测集。因此,本研究中校正集样本为360个,预测集样本为120个(60个完好样本,30个轻度黑斑样本,30个重度黑斑样本)。
1.2 仪器设备
试验中采用北京卓立汉光公司开发的“盖亚”高光谱分选仪,波段范围为900~1 700 nm,主要有Image-λ-N17E光谱相机、4个35 W的溴钨灯、计算机、电移动平台、暗箱组成。为避免信息过度饱和与成像失真现象,设置曝光时间t=0.13 s,样本与镜头的距离h=200 mm,传送带移动速度v=7.2 mm·s-1。为了消除光强变化和暗流对成像的影响,光谱采集前进行黑白板校正[12]。
1.3 统计分析
本研究采用SPA提取特征波长,采用PLS-DA、BP-NN、CNN进行数据建模。SPA[13]是一种以较小信息量表达大量数据的降维方法,能有效消除数据间存在的共线性问题并避免重叠信息的重复提取。
PLS-DA[14]是将偏最小二乘法和线性判别分析法相结合的多变量统计分析方法,采用交叉验证得到最优主成分个数,然后进行线性判别分析,解决回归分析中自变量多重共线性的问题。本研究中,根据交互检验选取主成分,设定最多主成分数为10,做10折交互检验。
BP-NN[15]是按照误差逆向传播算法训练的多层前馈神经网络,具有任意复杂的模式分类能力和优良的多维函数映射能力,解决了简单感知器不能解决的异或等问题。本研究中,设定网络隐层和输出层激励函数分别为tansig和purelin函数,网络训练函数为trainlm函数,隐层神经元数设为6。网络迭代次数为1 000次,期望误差为0.0001,学习速率为0.1。
CNN[16,17]的基本结构包括特征提取层和特征映射层,是在BP神经网络基础上的改进。在CNN中,某个神经单元的感知区域来自于上层的部分神经单元,同一特征平面实现权重共享,权值共享降低了网络的复杂性,降低了过拟合的风险。本研究中,CNN的结构包括输入层,2层卷积层和降采样层,全连接层,输出层,基本结构见图1。输入图像大小为28×28,特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,1层卷积的特征图数量为6,2层卷积的特征图数量为12,卷积核大小为5×5,降采样层采用2×2的临域相连接,学习效率为1,批训练样本数量为10,每批训练中迭代次数为720。
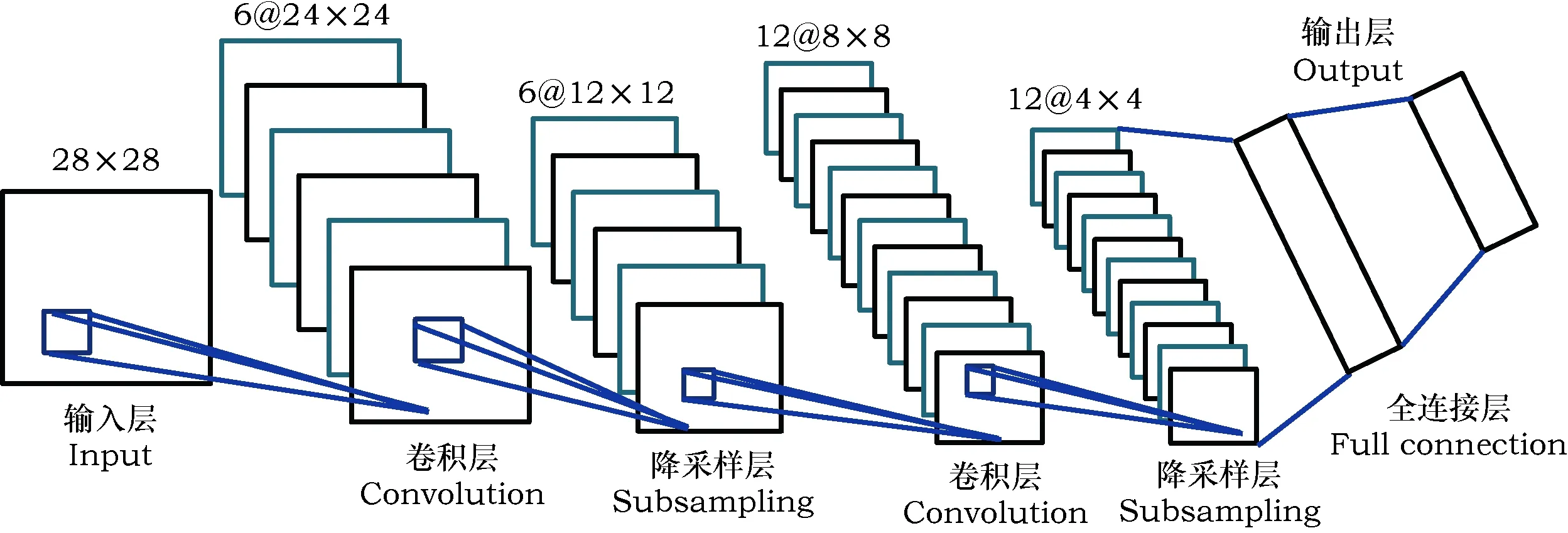
图1 CNN结构Fig.1 CNN Structure
2 结果与分析
2.1 光谱分析
提取样本感兴趣区域内的光谱信息,并计算其平均值,作为每个样本的光谱信息。2016年和2017年,所采集到的完好枣、轻度和重度黑斑枣的平均光谱曲线见图2。由于900~940 nm、1 660~1 700 nm含有大量的噪声,因此选择940~1 660 nm范围内的光谱进行分析。同一类别中,2016年和2017年的光谱曲线变化趋势一致,但是反射率存在一定的差异,特征吸收峰出现轻微偏移。完好枣在980 nm左右处和1 224 nm左右处有明显的水分子吸收峰。黑斑病果,果肉变硬,味道变苦,内部成分变化。在960~1 380 nm范围内,完好枣、和黑斑枣的光谱曲线有较大差异,与病害发生中的果实内部水分含量和碳水化合物的变化有关。
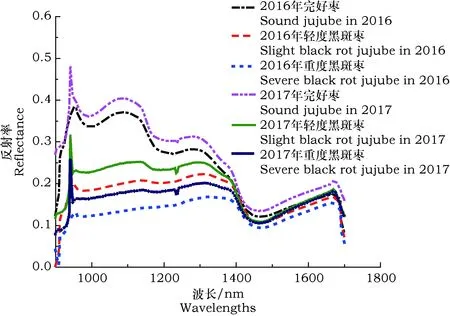
图2 样本的平均光谱曲线Fig.2 Average spectral curves of samples
2.2 基于光谱信息的识别模型建立
为研究不同年份下的样本所建校正模型的预测性能,针对全波段光谱,分别用2016年、2017年的校正集样本建立PLS-DA、BP-NN模型(表1)。单一年份所建的BP-NN校正模型在预测相同年份的样本时,判别正确率为100%。2016年BP-NN模型预测2017年样本时,正确率为95.0%(3个轻度黑斑病的样本被判别为完好枣)。2017年BP-NN模型预测2016年样本时,正确率为96.7%(2个完好枣被判别为黑斑枣)。2016年PLS-DA模型预测2016年样本时,正确率达到98.3%(1个轻度黑斑样本被判别为完好样本);预测2017年样本时,正确率为95.0%(3个轻度黑斑样本被判别为完好样本)。2017年PLS-DA校正模型,预测2017年样本时,判别正确率为100%;但预测2016年样本时,判别正确率仅为66.7%(20个完好枣被判别为黑斑枣)。单一年份校正模型预测时,主要出现轻度黑斑枣和完好枣的错误判别。由于黑斑程度低时,样本内部组分的改变少,所引起光谱响应的差异性小,且不同年份下完好样本的光谱响应也存在一定差异性,导致完好枣和轻度黑斑枣易判别错误。不同年份所建模型对当年样本判别时取得好的预测结果,但对其它年份样本的预测结果较本年份低。两年联合建立的BP-NN和PLS-DA校正模型得到相同结果,综合判别正确率均为99.2%;预测2017年样本时,均有1个轻度黑斑样本被判别为完好样本。但是单一年份建模时,BP-NN模型的预测性能均好于PLS-DA模型。因此,在鲜枣黑斑特征识别中,BP-NN较PLS-DA有更好的预测效果。联合年份的预测效果较单一年份好,表明年份是校正模型稳定性的一个影响因素,主要由于不同年份下的生长条件(如光照、温度等)差异导致同类样本的光谱信息存在差异,单一年份所建校正模型预测其它年份同类样本时易出现错误识别;同时联合年份所建校正模型,样本的增多也适度提高了模型的性能。
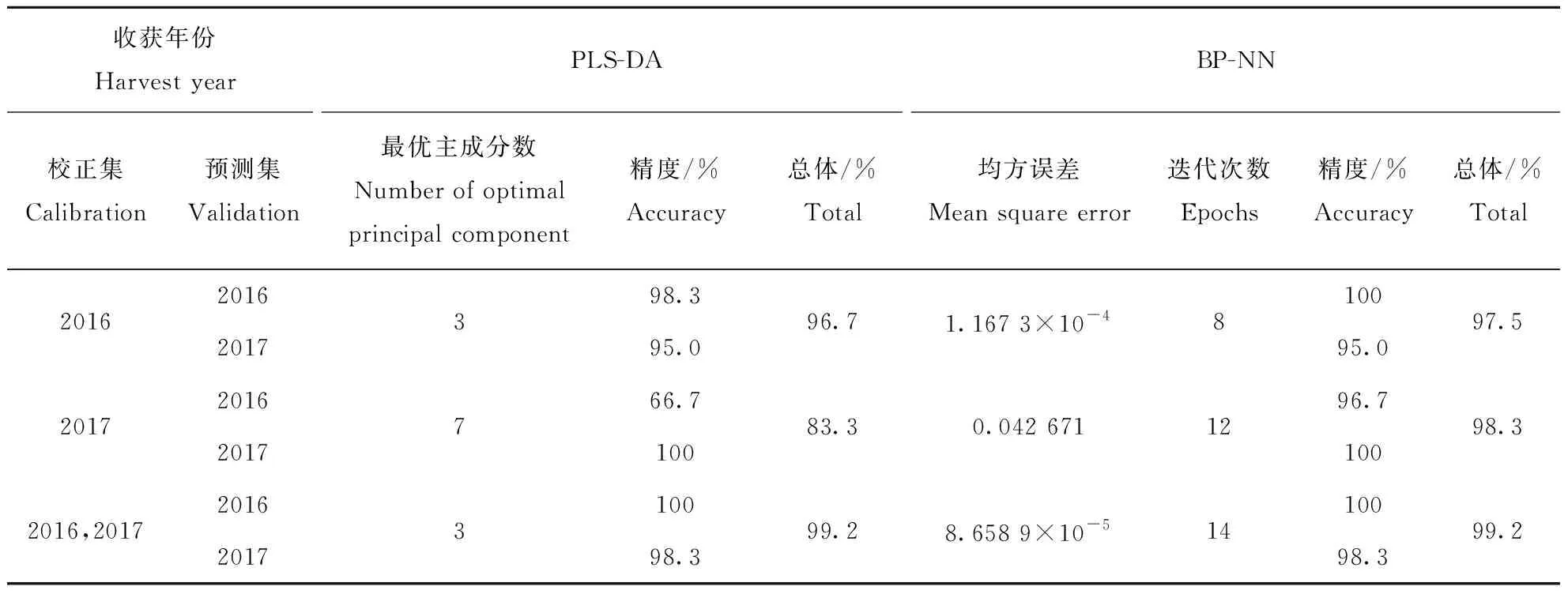
表1 基于全波段的PLS-DA和BP-NN模型的判别结果Table 1 The results of PLS-DA, BP-NN models based on full wavelengths
针对两年联合光谱数据,采用SPA提取特征波长,当RMSE为0.11818时,提取到8个特征波长,分别为1 291、1 094、1 367、947、1 469、1 422、969、1 520 nm,其重要程度依次递减。然后采用BP-NN建立检测模型,当均方误差为0.0016013,迭代次数为18时,SPA-BP-NN模型的判别正确率为100%。表明特征波长较全波长建模效果好,该研究的全波段中存在一定噪声。因此,有效变量信息选择、运算速度提高、算法稳定性与可靠性,也是模型稳定性的一个重要影响因素。
2.3 基于图像信息的CNN识别模型建立
对SPA提取到的8个特征波长所对应的图像进行主成分分析,累计贡献率见表2。典型样本的主成分图像见图3,噪声从第4个主成分图像开始严重。而前3个主成分的累积贡献率已达到99.1%,可以很好的解释样本信息变量。因此,选择前3个主成分进行分析。PC1的图像中样本和背景的对比明显,PC3图像中病害区域和完好区域对比明显。因此,选择两年所提取到的28×28感兴趣区域的PC3的图像进行分析。提取每个样本PC3图像的灰度值并将数据归一化,采用BP-NN和CNN建立分类模型。
基于主成分图像所建立BP-NN和CNN模型的判别结果见表3。BP-NN模型在均方误差为0.99343,迭代次数为3时,判别正确率达到78.3%,13个完好枣(2016年3个,2017年10个)被判别为黑斑枣,13个黑斑枣(2016年7个,2017年6个)被判别为完好枣。CNN判别中,随着学习次数的增加,均方误差整体上呈下降趋势,当迭代次数为15 393时基本收敛到稳定值。当迭代次数为25 920,均方误差为0.0059时,有8个完好枣(2016年6个,2017年2个)被判别为黑斑枣,有4个黑斑枣(2017年4个)被判别为完好枣,判别正确率为90.0%。CNN模型的判别正确率明显好于BP-NN,在基于高光谱成像技术的农产品质量检测中有较好的应用前景。基于光谱信息的SPA-BP-NN黑斑鲜枣识别和基于图像信息的CNN识别均取得好的结果,未来的研究将在此基础上,建立适用于工业生产中在线分选的稳定模型。
表2前8个主成分的累积贡献率
Table2 Accumulative contribution rate of the first eight principal component
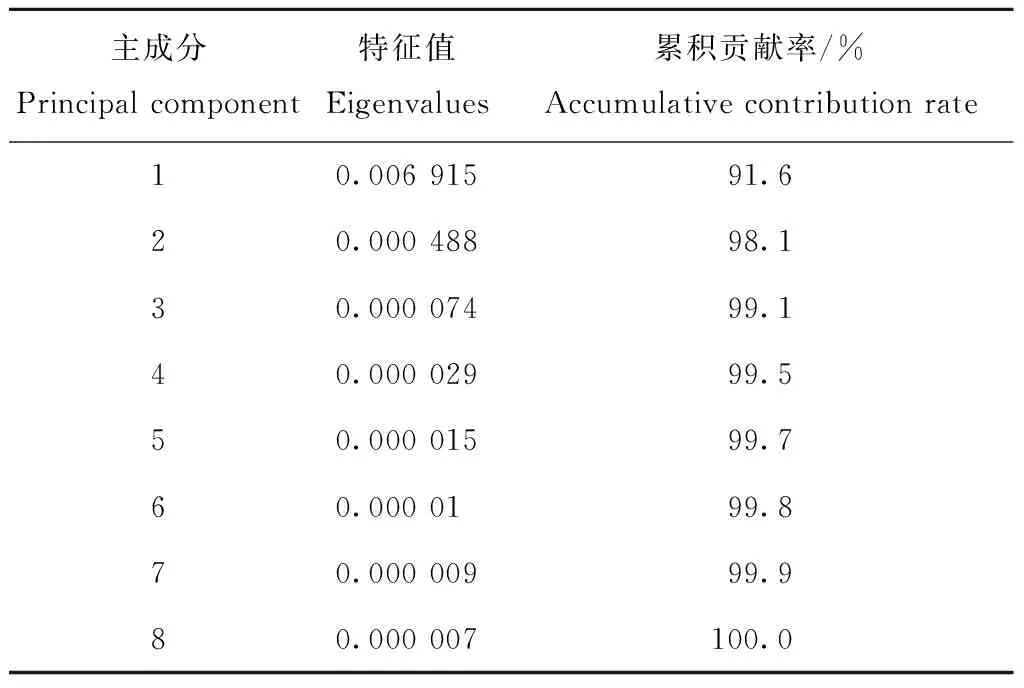
主成分Principal component特征值Eigenvalues累积贡献率/%Accumulative contribution rate10.006 91591.620.000 48898.130.000 07499.140.000 02999.550.000 01599.760.000 0199.870.000 00999.980.000 007100.0

图3 黑斑样本的主成分图像Fig.3 Principal components grayscale of diseased samples
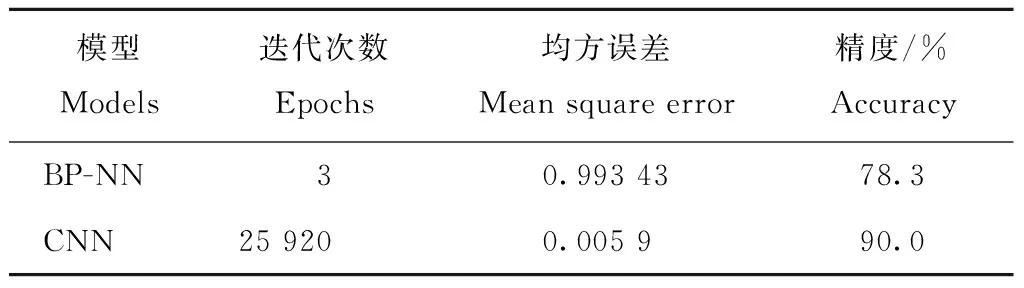
表3 BP-NN和CNN模型的判别结果Table 3 The results of BP-NN, CNN models
3 结论
本研究基于高光谱成像技术进行黑斑鲜枣识别,采用PLS-DA和BP-NN建立全波段的识别模型。单一年份所建校正模型,对其他年份的样本进行判别时,均比对相同年份样本的判别准确率低;联合年份所建的校正模型均比单一年份所建校正模型的整体判别准确率高,且PLS-DA和BP-NN模型的判别准确率都达到了99.2%。但单一年份所建模型中BP-NN较PLS-DA的判别精度高。表明收获年份是一个影响光谱校正模型的重要因素。基于联合年份的光谱信息,采用SPA提取特征波长,建立SPA-BP-NN模型,识别准确率为100%,明显好于全部波段所建模型。基于SPA提取的特征波长获得主成分图像,采用BP-NN和CNN建立识别模型,判别准确率分别为78.3%和90.0%。基于光谱信息的SPA-BP-NN和基于图像信息的CNN黑斑鲜枣识别均取得好的结果。因此,高光谱成像技术和CNN在农产品的分类中具有很好的应用前景,为进一步设计分类装置并实现工业生产中实时在线分选提供了理论基础。
猜你喜欢
当代水产(2022年2期)2022-04-26 14:25:48
今日农业(2021年19期)2022-01-12 06:16:40
小猕猴智力画刊(2021年11期)2021-11-28 21:30:15
当代水产(2020年4期)2020-06-16 03:22:52
当代水产(2020年4期)2020-06-16 03:22:46
女子世界(2017年8期)2017-08-07 11:34:05
中老年健康(2016年12期)2017-01-18 21:49:57
儿童故事画报·自然探秘(2016年4期)2016-06-24 08:32:32
科学启蒙(2016年5期)2016-05-10 11:50:30
上海预防医学(2014年2期)2014-06-03 10:19:06
