
TMS320C6000 DSP汇编软件流水的教学研究
2018-10-26 05:56:40石磊,孙倩
电气电子教学学报 2018年4期
石 磊, 孙 倩
(鲁东大学,1. 信息与电气工程学院,2. 数学与统计科学学院, 山东 烟台264025)
0 引言
数字信号处理器 DSP(digital signal processor)是将传统的基于硬件设计的数字信号处理变成软件设计,其中TI公司的TMS320C6000芯片是高校教学以及工程应用中较为常用的一款高端的DSP型号。在DSP的教学过程中,教师和学生往往注重DSP的C语言编程以及对外设的使用,因为学会这些就可以很容易地使用C语言来操作DSP的外设且比较容易获得成就感。但是DSP是一个算法处理芯片,软件优化是其更重要的内容,因为DSP上运行的可能是实时的图像或者视频处理软件[1~2]。
软件优化中汇编代码的软件流水是其核心,TMS320C6000系列DSP的开发工具比如CCS(Code Composer Studio)的编译器里可以设置自动进行软件流水[3~5]。但是想要真正理解DSP的CPU内核架构以及理解DSP的软件优化,学会汇编代码的软件流水是非常重要的。
汇编代码的软件流水较为复杂,在教学过程中,选择一个好的实例来讲好此内容是非常具有挑战性的。为此,我们以有限冲击响应(FIR)的线性汇编代码为例来讨论DSP的汇编软件流水方法。首先是编写有限冲击响应的C语言代码,并根据C语言代码将其改为线性汇编代码;然后根据线性汇编代码进行软件流水[5];再比较未进行软件流水以及进行软件流水代码的不同性能,最后是教学效果评估以及总结。讲解此内容的目标是让学生能够理解软件优化的思想和掌握汇编软件流水的方法,难点在于软件流水中编排表的建立。
1 C语言代码转换为线性汇编代码
有限冲击响应公式为

可以简写为

实现此式的C语言函数为
int fir_example(short h[], short x[],N)
{
int y1=0,y2=0,i;
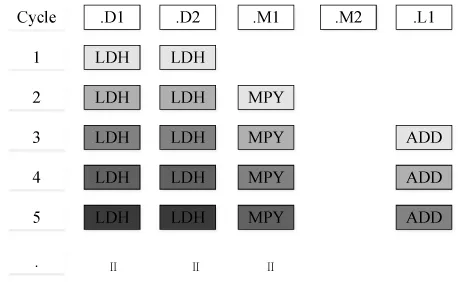
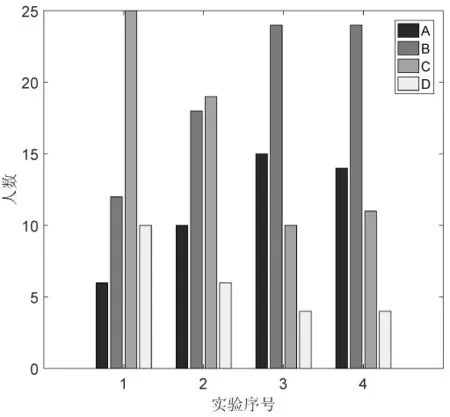
for (i=0; i y1+= h[i]*x[i]; y2+=h[i+1]*x[i+1];} return y1+y2; } 根据TMS320C6000系列DSP的CPU内核特点可知,CPU的数据读取通路至少支持一次读取32位的数据,也即支持LDW汇编指令,那么我们使用LDW指令,一次读取两个short类型(16位)的数据,使用MPY和MPYH指令分别对读取的32位数据进行低位相乘和高位相乘,也即对读取的两个short类型数据分别进行相乘。这样可以使循环的次数减少一半。 将此C语言函数中for循环部分用线性汇编代码改写变成: loop: LDW *h++,hi; LDW *x++,xi; MPY hi,xi,pi_1; MPYH hi,xi,pi_2; ADD pi_1,y_1,y_1 ADD pi_2,y_2,y_2 [cnt] SUB cnt,1,cnt; [cnt] B loop; ADD y_1,y_2,y TMS320C6000系列DSP都是支持超长指令字(VLIW)的,8个32位指令的取指包组成一个VLIW,最多一个CPU时钟周期执行8条指令,也即CPU的8个功能单元全部都在执行指令。软件流水是对循环代码进行编排,使得循环迭代代码能够并行执行,其目的是上一次循环未完成时就开始下一次循环迭代。对于加载(LDH指令)两个半字数据,相乘(MPY指令)之后并进行累加(ADD指令)这样的循环代码,其软件流水执行过程如图1所示: 图1 软件流水指令执行 图1最左一列代表时钟周期,最上一行代表指令使用的功能单元,这里我们不考虑指令完成需要的时钟周期。相同底色的指令代表是同一个循环,这样在第3个时钟周期,循环的四条指令就可以同时运行了,大大提高了程序运行的效率,也即在一个时钟周期内,充分利用每一个功能单元,进行下一次或者下下次数据的加载以及数据的相乘来提高程序的性能。 汇编的软件流水需要以下步骤:资源分配、画相关图、建立流水编排表以及写流水代码[5],以下分别加以介绍。 资源分配就是对汇编指令使用的功能单元以及DSP可用的功能单元进行分析,对于FIR的线性汇编代码,我们可得表1: 表1 资源分配表 从表1中可得,在一个循环周期内,所有的汇编指令都有相应的功能单元使用,没有两条指令使用同一个功能单元的情况,也即有可能将一个循环所有的指令在一个时钟周期内安排执行。 相关图展示了指令以及数据的执行流程,可以用于分析程序的循环或者分析指令的相关性。画相关图需要画出节点以及通路。节点是数据流入和流出的点,包括数据变量、分配的寄存器、使用的指令和功能单元;通路指示数据流的方向,其旁边的数字是指令完成需要的周期数。FIR程序的相关图如图2所示: 图2 FIR程序相关图 由图2可知,变量hi和xi的读取,分别使用LDW指令,执行此指令需要5个周期;hi和xi变量的低16位和高16位分别相乘,使用MPY和MPYH指令,完成需要2个周期;然后分别进行累加,使用ADD指令,需要1个周期。SUB指令对循环计数变量cnt进行减1计数,当计数不为0则使用跳转指令B进行跳转,跳转指令需要6个周期。分配功能单元时尽量平分A组和B组的功能单元,同时变量使用相应组侧的寄存器。 根据2.1节资源分配的分析可知,可以在一个循环周期内编排这些指令。根据图2找到最长的数据通路来编排周期,最长的数据通路为LDW->MPY->ADD或者LDW->MPYH->ADD,需要的时钟周期为5+2+1=8。在建立编排表的过程中,需要从最长的数据通路开始建立,并且从第一个时钟周期就开始编排指令,对于跳转和循环计数指令可以使用倒推的方法来安排。其中软件流水编排表如表2所示: 表2 软件流水编排表 对于表2来说,每一行代表CPU内核的某一个功能单元,每一列代表一个循环中某个时钟周期。需要注意LDW需要5个周期才能执行完毕,所以MPY和MPYH指令安排在第5周期。MPY和MPYH需要2个周期才能执行完毕,所以ADD指令安排在其后2个周期处。跳转指令B需要6个时钟周期才可以完成,所以倒推至第2周期安排。如表2中灰色部分所示。 在表2中每一个时钟周期还有很多功能单元没有用到,因此需要进行完全流水的编排。为了实现完全流水的编排表,则还需要确定最小的迭代间隔,也即相邻的两次循环迭代开始之间必须要间隔的最小时钟周期数。如果一次循环里有N条指令占用同一个功能单元,则最小迭代数至少为N,对于FIR的代码来说,一次循环里的指令都有相应功能单元使用,不存在多个指令占用情况,因此迭代间隔为1。那么下次迭代和上次迭代可以只隔一个周期,则可以将LDW指令填充每一个周期, MPY和MPYH等指令都可以相应进行编排,如表2所示。其中指令的下标代表某一次迭代,下标相同的代表同一次迭代。 表2中最后一列是包括了所有循环指令的一个周期,进行循环迭代即是执行此周期的代码。对于循环内任意一次迭代,比如第n次迭代,正在执行的指令为:ADD指令进行第n次迭代的相加,MPY和MPYH指令进行第n+2次迭代的乘,LDW指令进行第n+7次迭代的数据读取,SUB指令进行第n+6次迭代的减1,B指令进行第n+5次迭代的跳转。 根据表2依次写出每个周期的软件流水汇编代码,如下所示: ;第0周期 LDW .D1 *A4++,A2;第0次迭代的hi加载 || LDW .D2 *B4++,B2;第0次迭代的xi加载 || MV .S1 A6,A1;设置循环次数 || ZERO .L1 A7;清零y_1 || ZERO .L2 B7;清零y_2 ;第1周期 [A1] SUB .S1 A1,2,A1;第0次迭代的减循环次数 || LDW .D1 *A4++,A2;第1次迭代的hi加载 || LDW .D2 *B4++,B2;第1次迭代的xi加载 ;第2周期 [A1] SUB .S1 A1,2,A1;第1次迭代的减循环次数 || [A1]B .S2 LOOP;第0次迭代的跳转 || LDW .D1 *A4++,A2; 第2次迭代的hi加载 || LDW .D2 *B4++,B2; 第2次迭代的xi加载 ;第3、4周期和第2周期代码一致,这里省略 ;第5周期 MPY .M1X A2,B2,A6;第0次迭代的乘积pi_1 || MPYH .M2X A2,B2,B6;第0次迭代的乘积pi_2 ||[A1] SUB .S1 A1,2,A1;第4次迭代的减循环次数 ||[A1]B .S2 LOOP;第3次迭代的跳转 || LDW .D1 *A4++,A2;第5次迭代的hi加载 || LDW .D2 *B4++,B2;第5次迭代的xi加载 ;第6周期和第5周期代码一致,这里省略 ;第7周期 LOOP: ADD .L1 A6,A7,A7;第0次迭代的累加y_1 || ADD .L2 B6,B7,B7;第0次迭代的累加y_2 || MPY .M1X A2,B2,A6;第2次迭代的乘积pi_1 || MPYH .M2X A2,B2,B6;第2次迭代的乘积pi_2 || [A1]SUB .S1 A1,2,A1;第6次迭代的减循环次数 || [A1]B .S2 LOOP; 第5次迭代的跳转 || LDW .D1 *A4++,A2;第7次迭代的hi加载 || LDW .D2 *B4++,B2;第7次迭代的xi加载 ADD .L1X A7,B7,A4 对于第1节中线性汇编代码,如果不进行软件流水优化,直接语句对应改成汇编代码,那么对应的一次FIR计算循环,需要两个LDW指令进行32位数据读取,MPY和MPYH指令进行32位数据的高低位相乘,两个ADD指令进行相应数据相加,以及一个SUB指令进行循环次数的减计数,还有一个B指令进行循环跳转,这8条指令是顺序执行的,没有充分利用CPU的8个功能单元。由于LDW需要5个时钟周期,MPY和MPYH需要2个时钟周期,B需要6个时钟周期,则一次FIR循环需要18个时钟周期,100次循环迭代需要1800个时钟周期。 对于软件流水后的汇编代码,因为能够充分利用CPU的8个功能单元,使得一次FIR计算循环的8个指令能够在一个时钟周期内并行执行。所以100次循环迭代则需要7+100=107个时钟周期,其中前7个周期用于软件流水的填充。同样100次的FIR迭代计算,软件流水后运行时间约为未进行流水代码运行时间的1/10,极大地提高了程序的运行效率。 “DSP原理与应用”是我校一门偏实践性的专业选修课程。由于对该领域应用缺乏了解,以及缺乏编程语言方面的训练,学生难以理解教学内容从而容易失去对该课程的学习兴趣。在该课程的教学过程中,我们采用了案例、实验以及理论相结合的形式授课,这样可以提高学生的学习兴趣,并取得了很好的效果。本课程设计了6次实验,前四次偏重DSP的软件设计,后两次是关于DSP外设的使用。前四次分别是CCS软件使用和C语言编程、线性汇编和汇编代码编写、软件流水优化、滤波器软件设计及优化。前四次实验整体是由简单到复杂,由基础到应用。实验成绩是根据实验情况以及实验报告进行打分,分为A、B、C、D四个等级,其中D为不及格。由于学生对开发环境的不熟悉以及之前没有较好的C语言编程训练,第一次实验成绩较差,之后随着理论和实验教学的深入以及学生编程能力的强化,学生实验成绩逐渐提升,如图3所示,代码软件流水为第3次实验,第4次实验由于是综合性设计实验,学生成绩为A和B的稍微少于第3次实验。通过本教学方法的实施,学生能理解DSP的CPU内核硬件和软件流水优化之间的关系,并能够在以后的DSP软件设计中有程序优化的思想。 图3 学生前4次实验成绩 本文以FIR为例给出了汇编代码软件流水的详细方法,通过资源分配、画相关图、建立流水编排表以及写流水代码四个过程完成软件流水。通过这样的教学案例及教学方法,学生对于TMS320C6000的CPU内核和流水线硬件内容以及软件优化方面的软件内容有了更深刻的理解,这为后续的DSP课程设计奠定了基础。2 汇编代码的软件流水
2.1 资源分配

2.2 画相关图

2.3 建立编排表

2.4 编写汇编流水代码
3 性能比较
4 教学效果评估
5 结语
猜你喜欢
数学小灵通·3-4年级(2021年9期)2021-10-12 05:47:46
小学生学习指导(低年级)(2020年10期)2020-11-09 09:21:58
文苑(2020年10期)2020-11-07 03:15:26
计算机教育(2020年5期)2020-07-24 08:52:56
电子制作(2018年16期)2018-09-26 03:27:08
天津诗人(2017年2期)2017-11-29 01:24:12
数学大王·中高年级(2017年2期)2017-02-08 15:52:55
山东工业技术(2016年15期)2016-12-01 05:31:45
学苑创造·A版(2016年4期)2016-04-16 17:57:51
视野(2015年6期)2015-10-13 00:43:11
