
混频数据与中国宏观经济周期测定
2018-10-23 06:02郭建伟
中央财经大学学报 2018年10期
郭建伟
一、引言
自2010年中国超越日本成为世界第二大经济体以来,中国经济总量保持了持续增长的态势,但经济增速从高速增长转为中高速增长。中国经济进入了“新常态”。在经济 “新常态”下,反映中国宏观经济走势的投资、消费、出口、信贷等主要指标的波动差异性日益明显,而供给侧结构性改革便是中国围绕“三去一降一补”五大重要领域实施的差异化宏观调控政策。中国共产党第十九次全国人民代表大会报告指出:“我国经济已由高速增长阶段转向高质量发展阶段”,“着力构建市场机制有效、微观主体有活力、宏观调控有度的经济体制”,“创新和完善宏观调控,发挥国家发展规划的战略导向作用,健全财政、货币、产业、区域等经济政策协调机制”。这反映了宏观经济周期的波动走势受GDP、工业增加值、贷款规模、固定资产投资等诸多指标影响;同时,这些指标数据在发布时间上的差异使其形成了频度 (月度、季度、年度等)不同的非平衡数据。由于混频指标数量众多,所以总体上看,这些指标数据集的波动走势还会表现出与经济周期波动相联系的协同性和差异性。利用混频数据测定经济周期就是要从多指标数据中提取反映中国宏观经济波动一致性走势的不可观测动态因子,从而测定经济周期拐点和划分经济增长的不同阶段。
在上述宏观经济调控目标和混频指标数据特征分析的背景下,对经济走势进行前瞻性分析不仅具有学术研究意义,而且具有宏观调控决策的参考价值。首先,利用混频数据测定中国宏观经济周期扩宽了数据选用的范围。本文不仅可以选用货币和产业等多个方面的混频指标数据,而且对于同一个指标数据的选用也不限于相对数据,还可以选用绝对数据。其次,虽然各个同频指标、混频指标均能一定程度上反映宏观经济的波动趋势,但各个指标之间的波动走势差异也是明显存在的。这就需要一种方法能够提取各个指标的有效信息,综合反映宏观经济的波动走势,而利用混频数据测定中国宏观经济周期可以实现这一目标。最后,利用混频数据中各个指标的有效信息生成的动态因子体现了较好的实效性,具有宏观调控政策决策的参考价值。例如,2017年1月底或2月底时,反映宏观经济波动走势的一些月度指标数据已经公布,但GDP等季度指标数据仍未公布。此时,利用混频数据提取的动态因子可以提前1~2个月预测2017年1季度GDP的数据。由于1—2月份的动态因子含有反映宏观经济波动走势的有效信息,所以预测的2017年1季度GDP数据真实性较好。这表明最大程度地从多指标混频数据中提取有效信息和排除无效信息干扰,提高了测算动态因子的精准度,也一定程度上体现了本文的研究意义之所在。具体的解决思路是在选用经济波动协同性较强的指标数据的同时,将传统分析方法难以利用又与宏观经济协同波动相关的指标数据也纳入混频数据分析模型。
混频数据分析方法主要有混频向量自回归模型、混频数据抽样模型和混频动态因子模型等方法。混频向量自回归模型 (MF-VAR)延续了VAR模型的基本思想和分析思路。其传统方法为Harvey(1989)[1]的VAR-MA模型。该方法将所有指标都视为统一频度的月度指标,而将季度指标视为存在大量缺失值的月度指标。 Mariano 和Murasawa (2010)[2]结合状态空间分析方法将VAR-MA模型进行拓展后建立了一个典型季频度-月频度混频数据的分析框架。但是,MF-VAR的主要特征在于两个方面:一是选用的混频指标限于频率倍数为固定值 (如季频和月频的倍数为3);二是混频指标地位需进行区分 (一般季频指标设定为被解释变量,月频指标设定为解释变量)。显然,这两大特征也存在限制该方法进一步拓展的问题。对于月度和周度混频数据,其VAR模型中解释变量的系数将不能再设定为固定不变的3;同时,事先设定为VAR模型中的被解释变量和解释变量也使得混频指标具有差异性的地位,难以避免分析中存在主观因素的影响。 即便是郑挺国和王霞 (2013)[3]、Alvarez等 (2016)[4]的最新研究,也未能克服上述不足之处。
混频数据抽样模型 (MIDAs)预测分析方法是由Ghysels等 (2004)[5]基于分布滞后模型提出来的,其本质上是参数化的回归分析。权重或滞后系数通过特定方式参数化是MIDAs模型的一个关键特征,包括指数Almon多项式、Almon多项式、Beta多项式和步函数多项式4种权重函数形式。这些权重的参数化描述函数非常灵活,不仅不同的参数可以被赋予不同的权重,而且参数估计还会自动决定权重获取形式(缓慢、快速和跳跃),故而便于进行模型拓展分析。Galvao (2007)[6]、Guerin 和 Marcellino (2011)[7]就分别将MIDAs模型拓展为平滑转移ST-MIDAs模型和马尔科夫区制MS-MIDAs模型。需要改进的是,MIDAs模型存在权重或滞后系数表达式较为复杂的问题,特别是多频度多指标的情况下,其权重或滞后系数的测算将变得难以处理。虽然刘汉和刘金全(2011)[8]验证了 MIDAs 模型的精度较好,Foroni和Marcellino (2013)[9]也验证了相通情况下 MIDAs模型和混频动态因子模型的分析结果差异不大,但是MIDAs模型仍存在和MF-VAR模型类似的问题:难以进行多频度多指标混频数据的综合分析。
混频动态因子模型 (MF-DFM)最初源于Stock和Watson(1988)[10]提出的多指标动态因子模型。然而,Stock和 Watson (1988)[10]的研究对于指标的选用还限于使用同频数据,特别是对同频指标中的一些经济波动协同性弱的指标通常进行剔除处理。此后,Mariano和 Murasawa (2003)[11]提出了状态空间形式下多个季、月频度指标的静态单因子模型。混频数据多因子模型是由 Giannone 等 (2008)[12]、Doz等(2011)[13]提出来的,主要为多个月频度指标预测季频度指标数据。对于频动态因子模型的多频度数据分析,Aruoba等 (2009)[14]做出了基础性贡献: 其选用了日、周、月和季频度的混频数据进行分析,并采用扩展卡尔曼滤波实现了模型估计,以分析和预测美国的宏观经济状态;同时,该研究成果已被美国费城联邦储备银行采用,每周发布反映美国经济状态的ADS指数。采用扩展卡尔曼滤波的一大作用在于估计过程支持混频数据为非平衡的 “锯齿型”数据,这使得混频数据的选用不需要进行 “掐头去尾”式的平衡化处理。栾惠德和侯晓霞 (2015)[15]便是在Aruoba等 (2009)[14]的研究基础上对中国实时金融状况进行了分析。两位学者选取2个日度和4个月度混频指标提取了反映中国金融状态的一致性指数,分析了中国金融市场流动性宽裕或紧张情况。
综合各类混频模型的评述,笔者认为选用混频动态因子模型测定中国宏观经济周期是最为合适的。其原因在于该方法存在以下研究贡献或创新之处。首先,MF-DFM模型结合扩展的卡尔曼滤波技术可以有效地利用多频度多指标混频数据提取反映中国宏观经济波动走势的月度动态因子。一是对指标数据进行调频处理。一些指标数据频度为月度时,难以反映出与宏观经济波动走势的一致性,而经过调频处理后则可以被选用,例如固定资产投资额在不同频度下的波动特征 (图1)。二是对混频数据进行无差异设定,在一定程度上避免了主观因素对指标地位的影响。这表明,在MF-DFM模型中,各个指标的地位均是相同的,后文中对应的参数初始赋值是相同的。三是选用具有 “锯齿型”特征的混频数据,有效提升了动态因子含有更多从混频数据中提取的有效信息。其次,借助ROC曲线分析技术可以判定概率方差法比CH准则法识别经济周期拐点的精准度更高,从而得到宏观经济波动走势更具有时效性的分析结果。一是对于周期拐点测定不一致的情况,概率方差法比CH准则法提前1个月份,有效向前推移了宏观调控的决策时间。二是概率方差法源于测算虑子概率邻域内的方差极大值识别经济周期的拐点,比CH准则法以固定值(0.35和0.65)识别经济周期拐点更合理和更精准。综合来看,本文的方法在混频数据选用和处理时,提升了混频数据中有效信息的提取;在利用月度动态因子分析宏观经济波动走势时,比利用季度GDP指标分析宏观经济波动走势提前了1~2个月的时间,体现了动态因子具有较好的时效性和宏观经济调控决策的参考价值;在经济周期拐点识别结果存在差异时,概率方差法比CH准则法提前了1个月,也具有较好的时效性和更符合宏观调控政策的前瞻性要求。
二、模型框架
(一)混频动态因子模型
1.混频动态因子模型的基本形式和改进。混频动态因子模型的基本形式可以将与宏观经济协同波动的任意一个时间序列指标表示成因子模型的方程形式。 Aruoba 等 (2009)[14]考虑了滞后项和因素wt对混频指标的共同影响,认为混频动态因子模型的基本形式是将混频指标表示为不可直接观测的动态因子αt、滞后项和因素wt形式:
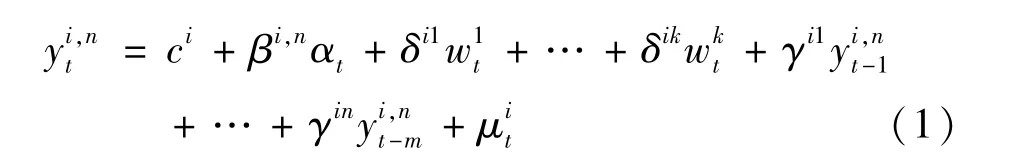

其中,εi,n为白噪声,,et:N(0,1);i取值1、2、3、4,分别表示指标频度为月度、季度、半年度和年度等混频指标的频度;n表示特定频度对应的指标个数。
混频动态因子模型表达形式的转化和估计。当混频指标个数多于其频度数 (n>i>2)时,混频动态因子模型便具有多频度、多指标的特征。为了简化分析,设各频度指标个数相同,从而与式 (2)相类似的因子方程将达到n个,或者说可以得到包含ni个因子方程的线性方程组。线性方程中的参数可以用向量表示为测量方程和转移方程的系统矩阵。于是,多频度、多指标混频动态因子模型就可以利用系统矩阵改写测量方程和转移方程表达形式。式 (4)和式(6)是利用系统矩阵改写测量方程的一般形式和简化形式;式 (5)和式 (7)是利用系统矩阵改写转移方程的一般形式和简化形式。


其中,εt: (0,Ht),ηt: (0,Qt);Zt、Tt、Ht、Rt和Qt是在特定元素位置含有参数的系统矩阵。为便于分析,式 (4)表示混频指标yi,nt为存量指标时的形式,T表示矩阵转置符号。
混频动态因子模型表达形式的转化还包括引入矩阵Wt对状态空间形式的测量方程进行转化。这种转化的目的是为了使卡尔曼滤波能够处理含有缺失值的混频数据,从而实现模型的估计。矩阵Wt为ni×ni矩阵,元素仅包括0和1。当混频指标观测值存在时,系统矩阵Wt对角线对应位置的元素赋值为1;观测值不存在时,其对角线对应位置元素赋值为0。于是,对yt、Zt、εt和Ht矩阵进行=转化处理后,可以得到混频动态因子模型转化后的新测量方程。借助卡尔曼滤波技术可以实现混频动态因子模型的BFGS法动态估计,得到动态因子数值、各参数估计值和对数似然估计值等。
(二)经济周期拐点的概率方差测定方法
1.虑子概率值的测算。设动态因子能够反映宏观经济高速增长和低速增长的两个区制,且由区制st控制。当st=0时,宏观经济处于高速增长状态的区制;当st=1时,宏观经济处于低速增长状态的区制。于是,可以利用马尔科夫两区制转移模型建立动态因子αt,以及区制st和st-1的联合分布函数F(αt,st,st-1|αt-1)和对数似然函数 lnL:
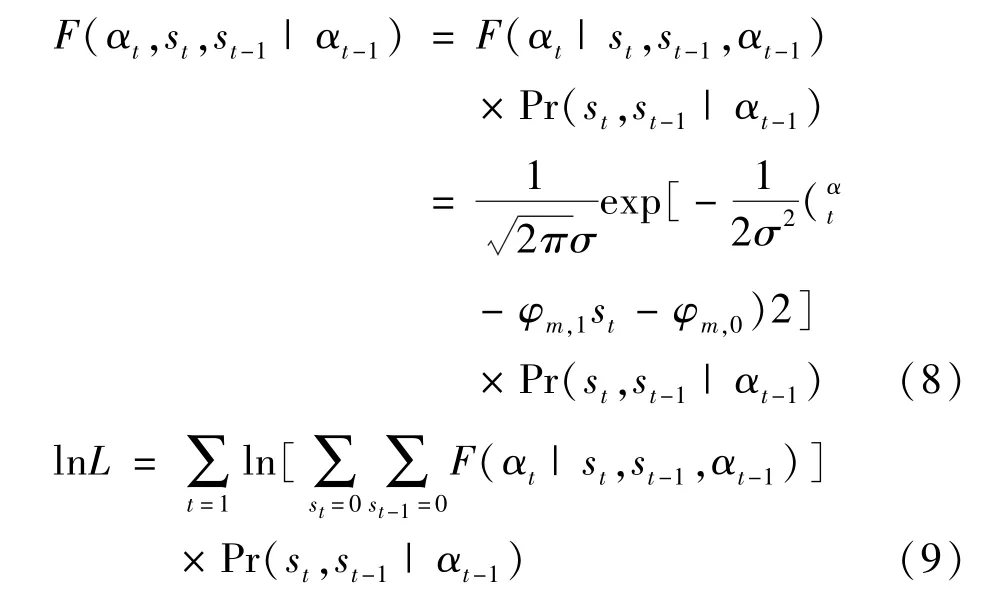
通过求取对数似然函数,虑子概率值Pr(st|αt)可以通过式 (10)和式 (11)来实现递归计算。
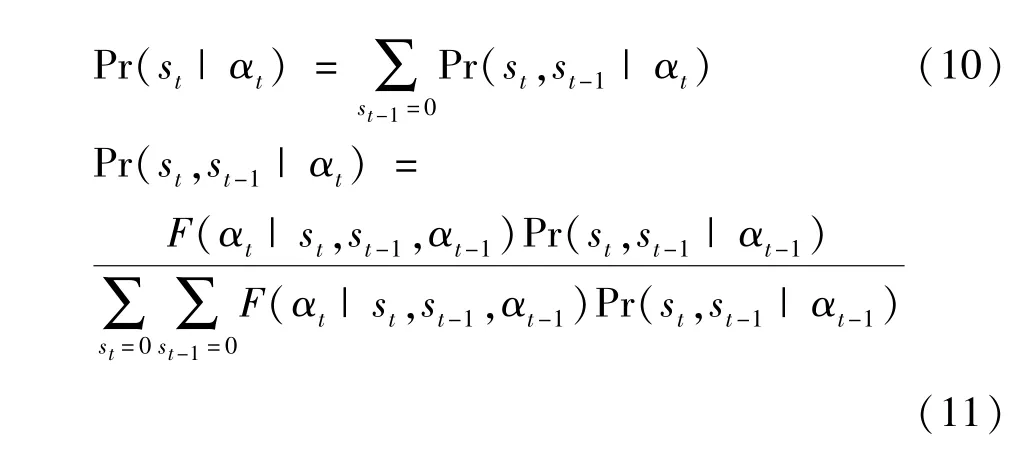
2.虑子概率邻域内方差极大值测定。假设向量θ= (μ0,μ1,φm,0,φm,1,σ20,σ21,p11,p00),则虑子概率的方差及其对数似然函数可以表示为。按照Hamilton (1989)[16]和Alvarez等 (2016)[4]的思路,在一定条件下,虑子概率和对应的概率方差可以表示为:

三、实证分析
(一)指标说明和数据处理
1.指标说明。
首先,混频指标选取15个经济和金融指标,见表1。从指标的绝对或相对属性看,指标中有GDP等8个绝对指标和GDP同比增长率等7个相对指标。这与郑挺国和王霞 (2013)[3]仅利用月、季两频度指标相对数据测定中国宏观经济周期有所不同。从指标的频度属性看,混频指标中有12个月度指标、2个季度指标和1个年度指标;经过调频处理后,转变为3个月度指标、3个季度指标、5个半年度指标和4个年度指标。从指标的经济或金融属性看,有9个经济指标和6个金融指标。虽然已有文献对经济周期的测定除了选用经济类混频指标外,还选用了金融类指标,但金融类指标 (特别是信贷规模等指标)对经济周期的影响还没有达成共识。例如:潘敏和张依茄 (2013)[17]认为,我国商业银行的信贷总量增速呈现出显著的逆经济周期特征。 Bemanke 和 Gertler (1989)[18]、Stolz和Wedow(2011)[19]通过对不同国家商业银行信贷行为与经济周期的关联研究,验证了信贷变量也会表现出顺经济周期效应。同时,文中还选用了与宏观经济波动走势相关的M2和外汇储备的绝对指标和相对指标。此外,从表1中各混频指标的观测值数量和时间区间看,混频指标数据具有明显的非平衡特征。
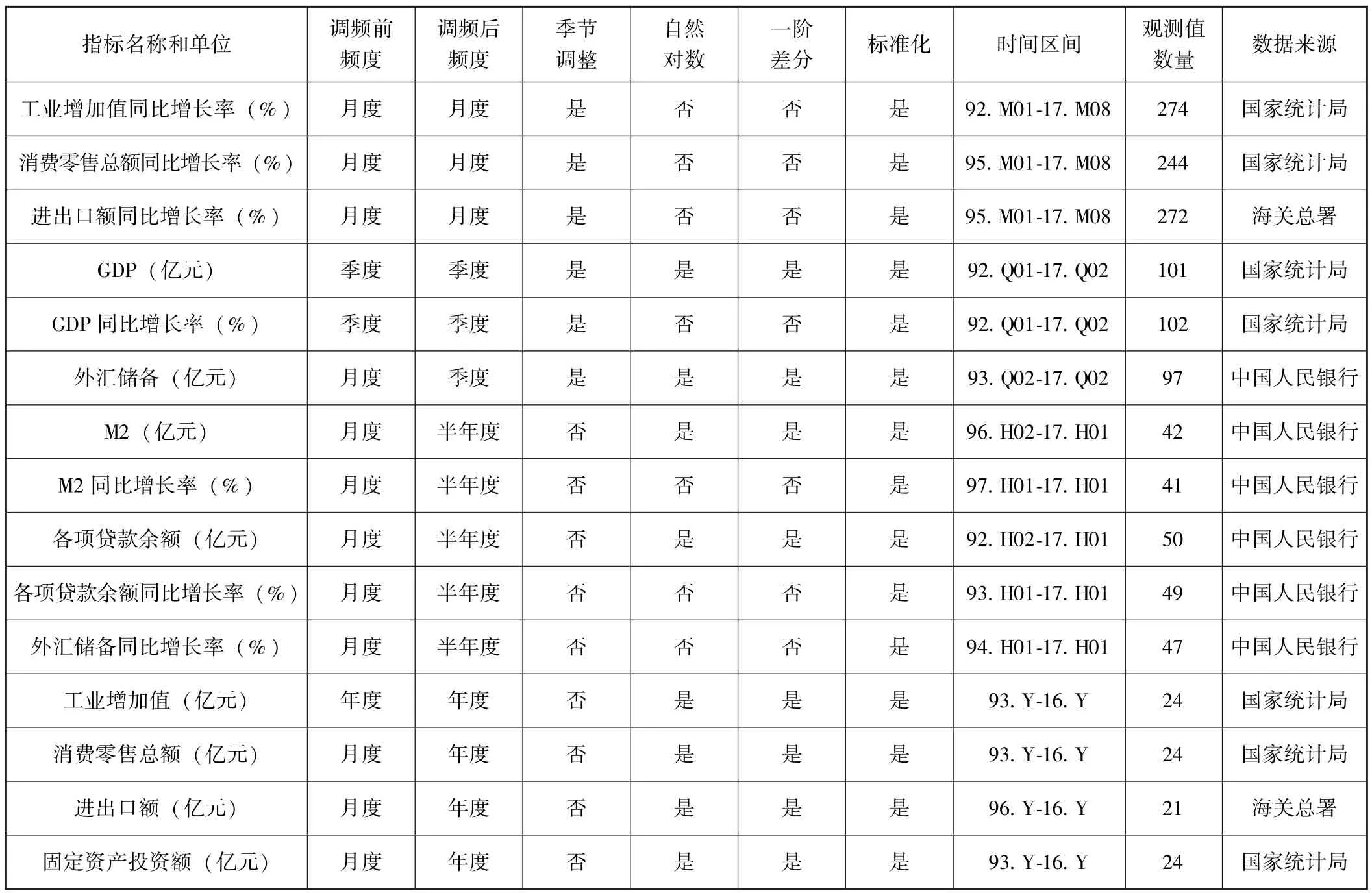
表1 混频指标及其处理
其次,收集GDP季度增长率 (主要是同比增长率和同比累积增长率)的实时数据。实时数据主要用于检验动态因子模型的稳健性。实时数据来源于2001年第1期至2017年第6期的 《中国经济景气月报》 《中国季度国内生产总值核算历史资料1992—2001》《中国季度国内生产总值核算历史资料1992—2005》《中国季度国内生产总值核算历史资料1992—2011》和2016年9月6日国家统计局官方网站 (http://data.stats.gov.cn/index.htm)发布的 “国家统计局关于公布季度国内生产总值核算数据主要修订结果的公告”中的1992—2015年度季度GDP修订数据,以及国家统计局官方网站发布的2012年第3季度至2017年第2季度我国GDP初步核算结果。对于2012年第3季度至2017年第2季度的GDP季度增长率,当 《中国经济景气月报》中报告的数据与国家统计局官方网站发布的数据不一致时,以后者数据为准。
GDP季度增长率实时数据包含纵向时间维度和横向序列维度。从纵向看,每1季度将向下方新增加1个GDP季度增长率数值;从横向看,每1季度将向右方增加1个GDP季度增长率序列。由于1992年是国家统计局对GDP季度增长率数据修订的纵向时间维度起始点,2001年是数据修订的横向序列维度分界点,从而设定纵向时间区间为1992年第1季度至2017年第2季度,横向序列区间为2001年第1季度至2017年第2季度。于是,GDP季度增长率实时数据是包含102个纵向时间维度和66个横向序列维度的季度实时数据集 (见图1)。其中,2006年第1季度至2011年第4季度为 《中国季度国内生产总值核算历史资料1992—2005》公布后的修正数据,共计24个横向序列维度的季度实时数据,该时期数据为GDP季度同比累积增长率,其余时期数据为GDP季度同比增长率。
2.数据处理。
数据处理主要包括调频处理、设定动态因子模型基准频度和缺失值处理等。首先,调频处理主要是将高频指标调整为低频指标,包括均值法和求和法。例如,M2和各项贷款余额由月度调频为半年度时采用均值法,而其余指标调频时采用求和法。调频处理的原因是指标频度较高时其波动的协同特征不突出,利用此类指标不利于分析中国宏观经济周期,而调频处理后,此类指标与宏观经济波动走势的协同性就较为明显了。例如,从固定资产投资额月度、季度、半年度和年度增速的走势 (见图7)可以看出,利用调频后的年度数据比月度、季度、半年度数据进行经济周期分析更合适。
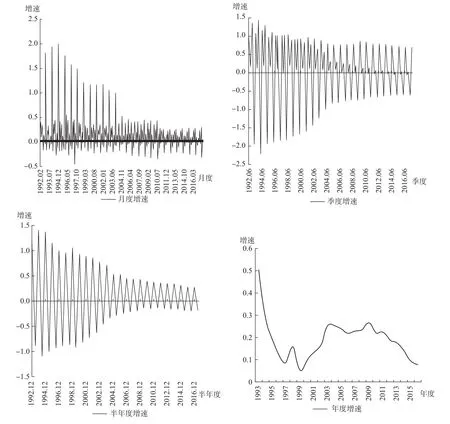
图1 月度、季度、半年度和年度固定资产投资额增速波动走势
其次,设定动态因子模型基准频度以月度为基准,将数据处理后的季度、半年度和年度指标统一“拉伸”为月度指标。1个季度、半年度和年度指标统一 “拉伸”后将分别形成3个、6个和12个月度指标。原低频指标数据视为同期间内对应月度指标最后月份的数据,其余月份的数据视为缺失值。例如,将月度设为基准频度后,从1992年1月至12月,季度指标 “拉伸”成月度指标后在3、6、9、12月有观测值,其余月份为缺失值;半年度和年度指标经过处理后分别在6、12月和12月有观测值,其余月份为缺失值。
再次,缺失值处理。从指标数据缺失值产生的来源看,一是设定动态因子模型基准频度使得季度、半年度和年度指标产生缺失值;二是对部分指标进行奇异值剔除处理出现缺失值;三是 “春节效应”导致部分指标存在缺失值。例如,表1中工业增加值同比增长率在1992年1月至2017年8月观测值数量为274个,剔除奇异值后形成34个缺失值;消费零售总额同比增长率在1995年1月至2017年8月观测值数量为244个,剔除15个奇异值和5个 “春节效应”形成的缺失值后共20个缺失值。其处理方法是基于混频动态因子模型和卡尔曼滤波,利用动态因子进行缺失值动态补充。将缺失值ymis,t+1视为上一期观测值yobs,t与权重πt的乘积,再加上动态因子αt+1的和(Brave 和 Butters,2011[20]),其递归公式为:ymis,t+1=πt·yobs,t+αt+1。 其中,当t表示低频指标同一样本期间内最后一个样本观测点时,πt取值为0;当t表示低频指标的频率倍差的其他样本观测点时,st取值为1; 动态因子αt+1服从AR(1)过程。 该种方法可以有效规避传统的缺失值补充方法可能导致补充的数据表现出趋势性递增 (或递减)特征而扭曲指标数据潜在的波动走势。文中的其他数据处理方法还包括季节调整处理、奇异值剔除处理、指标自然对数化处理、自然对数化指标差分处理、标准化处理等。
(二)动态因子的提取及其分析
1.动态因子的提取。
编制计算程序代码,可以提取反映宏观经济一致性走势的不可观测动态因子。首先,需要对状态空间形式下的系统矩阵进行设计。提取动态因子需要设计5个关键系统矩阵,并在系统矩阵特定元素位置植入数值和参数。设计Zt矩阵、Tt矩阵和Ht矩阵均为15×15矩阵,Rt矩阵为15×4矩阵,Qt矩阵为4×4矩阵。对于Zt矩阵,需要植入3个数值1和15个参数β11,β12,…,β44; 对于Tt矩阵,需要植入12个相同参数ρ和3个参数γ11,γ12,γ13(γ13表示第3个月度指标对应的参数,其余与此类似);对于Ht矩阵,需要植入12个参数σ21,σ22,…,σ44; 对于Rt矩阵,需要植入15个数值1;对于Qt矩阵,需要植入1个数值1和3个参数σ11,σ12,σ13。
其次,需要对参数赋予初始值。按照混频指标具有同等、无差异地位的原则对46个参数赋予初始值。15个参数β赋予的初始值是相同的,15个参数γ和15个参数σ初始值赋予方法类似,但是参数β、γ和σ的初始值大小是可以不相同的。由于设定公共因子αt服从AR(1)过程,所以,参数ρ初始值赋值可介于0.91~0.99之间,一般赋值为0.95。最后,测算得到了月度动态因子数据,时间区间为1992年1月至2017年8月,共计308个数值。同时,各个参数均总体上通过了5%水平上的显著性检验,见表2所示。估计结果表明,各指标均与动态因子正相关,15个参数β的估计值均为正值。对于15个参数γ的估计结果,除了M2的绝对指标对应的估计结果为负值外,其余均为正值。其原因可能在于相比较其他指标,M2绝对指标的标准差相对较大,整体上相对于其均值波动得更突出,与动态因子的整体一致性偏离也较突出,从而使得估计结果为负值。15个参数σ的估计值均为正值,符合其数值应为正值的数学意义。
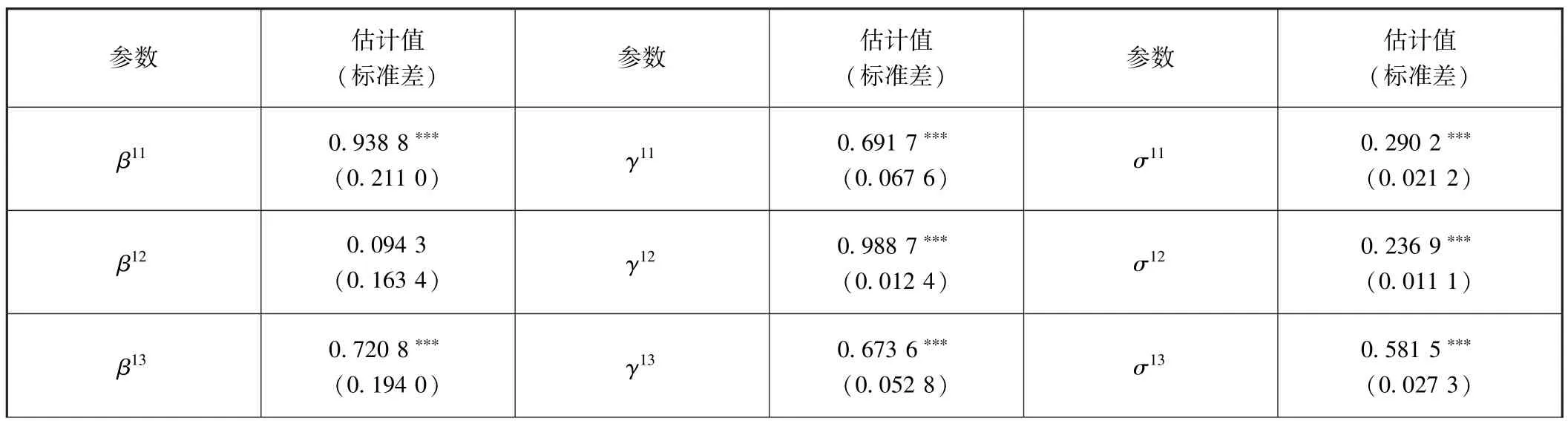
表2 混频动态因子模型参数估计结果
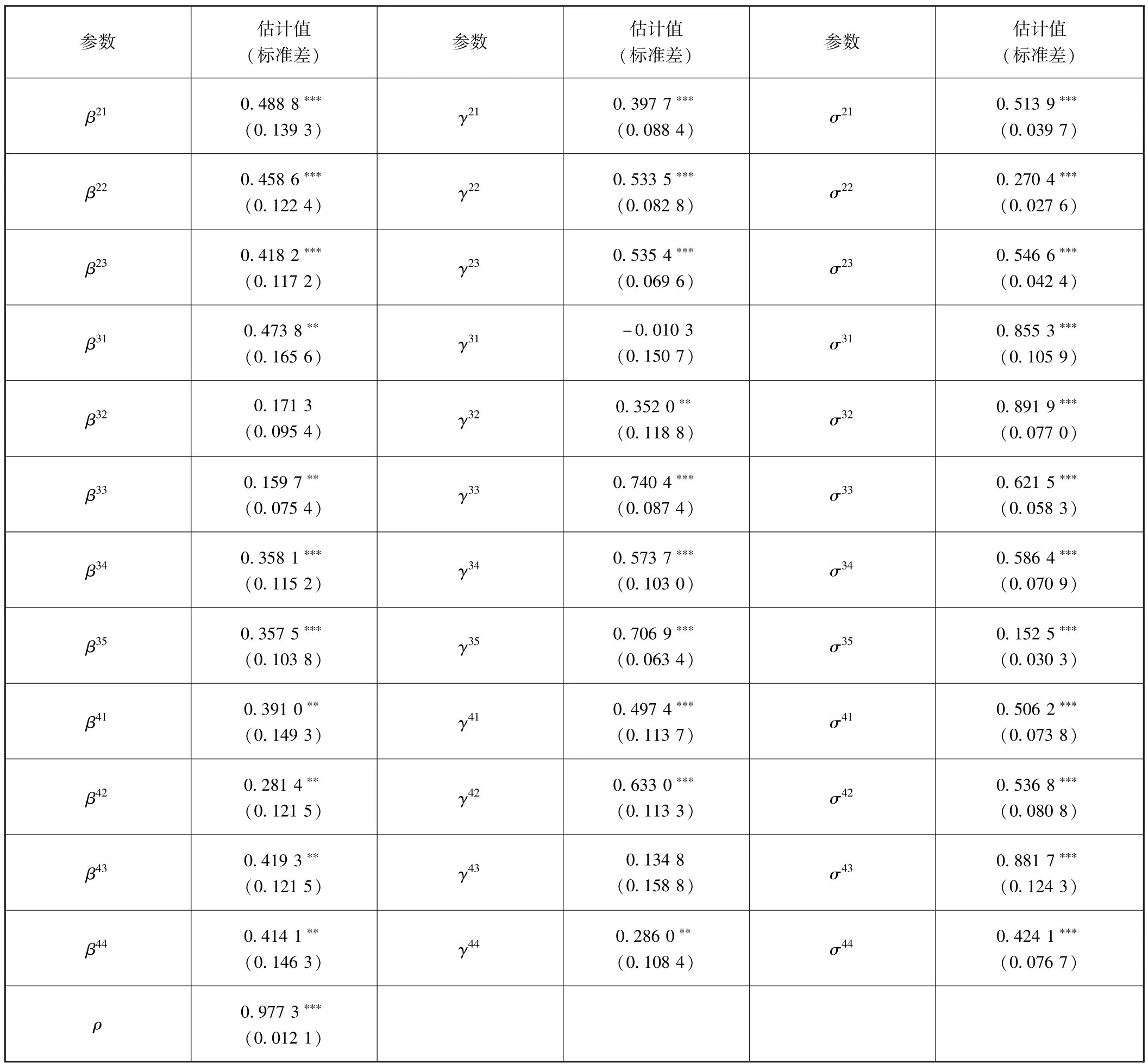
续前表
2.利用混频数据分析的有效性和动态因子的波动特征。
首先,图2报告了月度动态因子 (Fac:M)与月度工业增加值增长率 (Ind:M)、季度GDP增长率 (Gdp:Q)、半年度贷款增长率 (Loa:H)和年度固定资产投资增长率 (Inv:Y)的波动协同性和差异性。有些时间段混频指标与动态因子的波动协同性较为明显,有些时间段则波动差异性较为突出;这反映了模型提取动态因子时对混频数据利用的有效性。混频指标和动态因子的波动协同性表明动态因子提取了协同波动性弱的混频指标中的有效信息,其波动差异性则表明无效的干扰信息没有被提取到动态因子之中。波动差异性还表明对于波动协同性弱的指标,虽然调频处理可以弱化其差异性影响,但并不能完全消除 (如图2中半年度各项贷款余额同比增长率;Loa:H)。同时,即便存在部分指标经调频处理后仍表现出一定程度的波动差异性特征,但其并没有对利用混频指标提取动态因子起主导作用。
其次,图3报告了月度动态因子 (Fac:M)与国家统计局公布的月度宏观经济景气一致指数 (Acc:M)、先行指数 (Adv:M)和预警指数 (Cau:M)的波动走势。动态因子总体上比3种宏观经济景气指数表现出了更好的时效性,具有较好的研判宏观经济景气状态的参考价值。1992年1月至1998年4月、2007年6月至2010年3月,在宏观经济短期波动较为剧烈的时期,3种景气指数是围绕动态因子上下波动的,表明动态因子反映的宏观经济走势具有较好的有效性。在宏观经济波动平缓的时期,动态因子的波动走势基本形成了3种景气指数波动走势的 “包络线”。1998年5月至2007年6月,在宏观经济由低速增长转向高速增长的时期,动态因子总体上位于3种景气指数的上方,从而可以更早地预警宏观经济下行的开始时间;2010年3月至2017年8月,在宏观经济由高速增长转向低速增长的时期,动态因子总体上位于3种景气指数的下方,从而可以更好地预警宏观经济下行的触底程度。
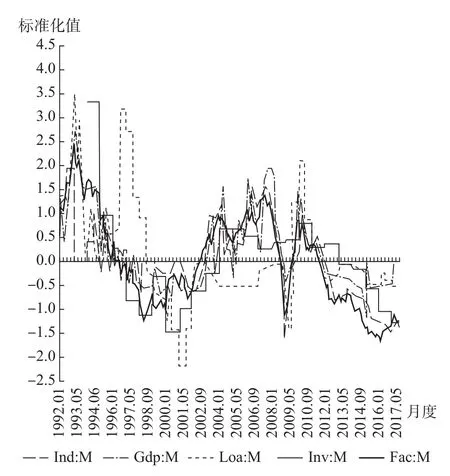
图2 动态因子与混频指标的时效性
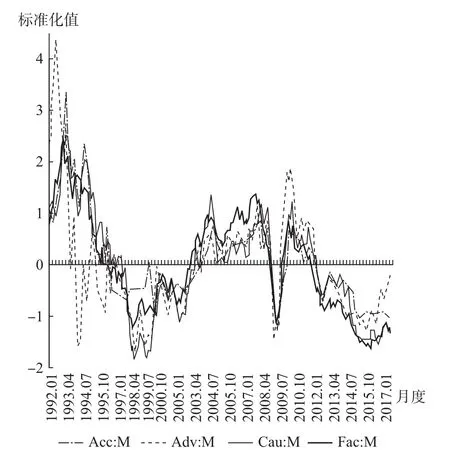
图3 动态因子与景气指数的时效性
(三)经济周期测定
精准划分的宏观经济的不同阶段对于提升宏观政策的调控效果具有重要参考价值,但关键在于如何根据动态因子精准测定经济周期拐点。Chauvet和Hamilton(2006)[21]提出基于动态因子测算其对应的滤子概率值,再将滤子概率值0.65和0.35作为经济周期由高速增长期转向低速增长期和由低速增长期转向高速增长期的拐点进行判定。这一方法被郑挺国和王霞(2013)[3]称为CH准则法。CH准则法测定经济周期较为简便,但也存在着拐点值确定的严谨性不足,难免产生存在经验性和主观性的质疑。由于虑子概率的一阶条件可以表示成其概率方差的某种形式,所以,通过虑子概率二阶条件测定经济周期的拐点便可以转化为通过其概率方差的一阶条件 (临域内极大值)进行判定。显然,概率方差法比CH准则法具有更严谨的数学基础;同时,借助计算机编制计算程序,概率方差法也能表现出较好的便捷性。
1.经济周期测定方法的精准性。
概率方差法和CH准则法对经济周期测定的精准程度可以通过ROC曲线分析方法进行判定。ROC曲线分析方法常用于医学领域的疾病诊断,能够很容易地查出任意临界值时对疾病的识别能力;ROC曲线越靠近左上角,诊断的精准度就越高。本文借鉴该分析方法以判定概率方差法和CH准则法对经济周期测定的精准优劣。首先,对两种方法测定的经济周期进行量化。将概率方差法和CH准则法测定的高速增长期间内的动态因子值全部赋值为1;低速增长期间内的动态因子值全部赋值为0。其次,测算概率方差法和CH准则法对应的敏感度和 (1-特异性)两个指标的值。最后,绘制横轴为 (1-特异度),纵轴为敏感度的ROC曲线,然后利用ROC曲线分析结果比较两种经济周期测定方法的精准度。一是比较ROC曲线下的面积值 (RUC)的大小。RUC的值一般介于0.5~1.0之间。当RUC=0.5时,说明经济周期的测定方法完全不起作用,没用意义;当RUC的值处于0.5~0.7之间时,说明经济周期的测定方法有较低精准性;当RUC的值介于0.7~0.9之间时,说明经济周期的测定方法有一定精准性;当RUC的值介于0.9~1.0之间时,说明经济周期的测定方法有较高精准度。二是比较约登指数 (VROC;敏感性+特异性-1)的最佳临界值 (VROC∗)的大小。最佳临界值越大,经济周期测定方法的精准度越高。
2.经济周期的测定结果。
首先,1992年1月至2017年8月,两种方法均测定出5个经济周期拐点、3个高速增长期和3个低速增长期,其时间区间也基本一致 (见表3、图4和图5)。高速增长期月份数与低速增长期月份数之比约为1.1∶1(表4)。测定结果也与动态因子曲线被0轴划分的上、下部分基本一致;动态因子与0轴的交点与测定的经济周期拐点也基本一致。由于2011年9月 (经济周期拐点,2011年3季度GDP同比增长率为9.4%)以后的动态因子值均为负值,且距离0轴距离较远,所以,还没有发现宏观经济由低速增长期转向高速增长期的经济周期拐点,可以预测中国宏观经济还将处于低速增长时期。
其次,从经济周期拐点的判定看,两种方法测定的部分经济周期拐点完全一致;对于周期拐点测定不一致的情况,概率方差法比CH准则法提前1个月,有效向前推移了宏观调控的决策时间,从而更符合宏观调控政策的前瞻性要求。
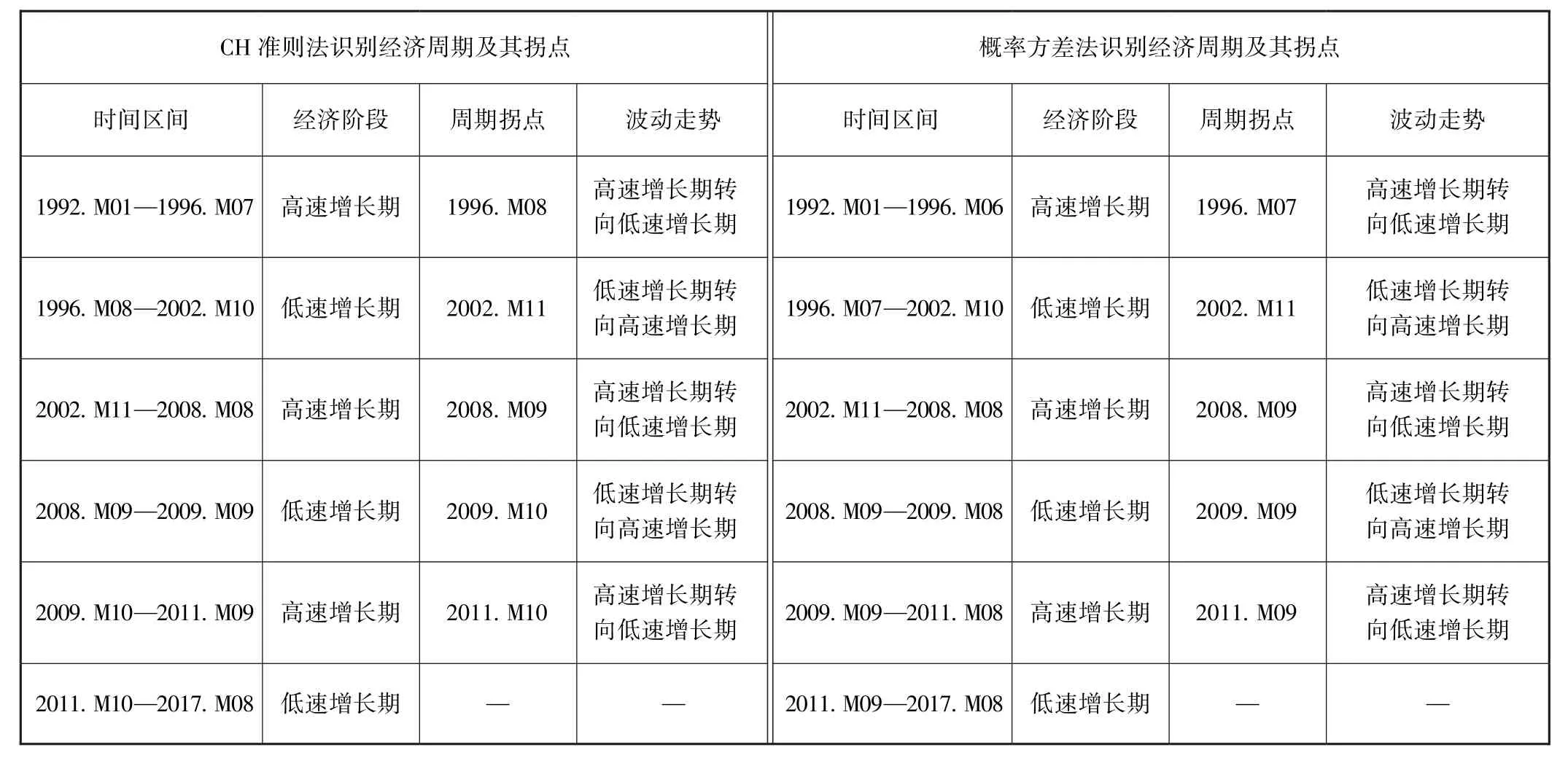
表3 CH准则法和概率方差法对经济周期的识别结果
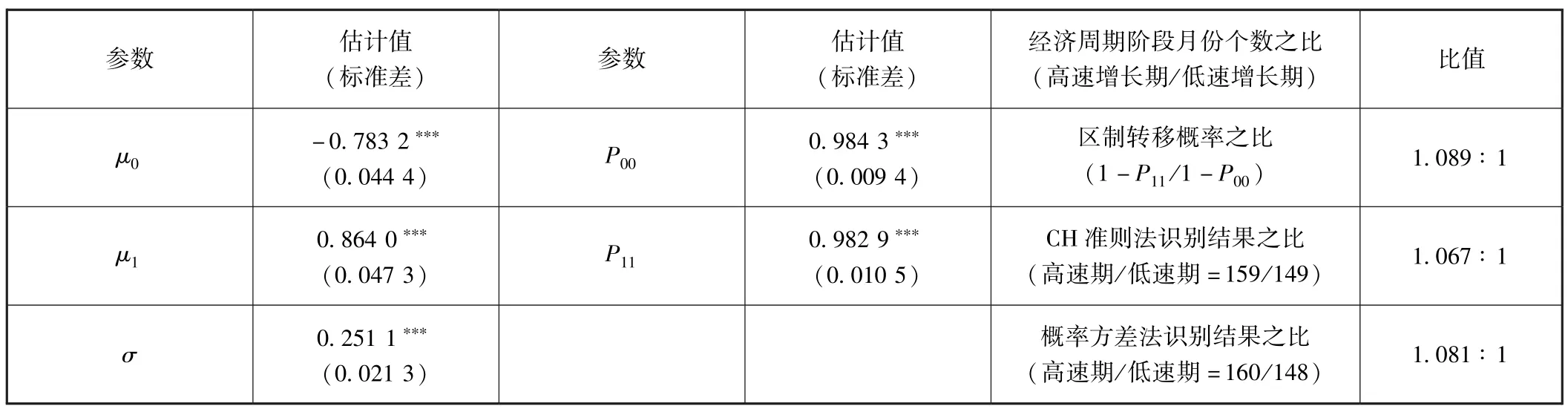
表4 马尔科夫区制转移模型参数估计结果
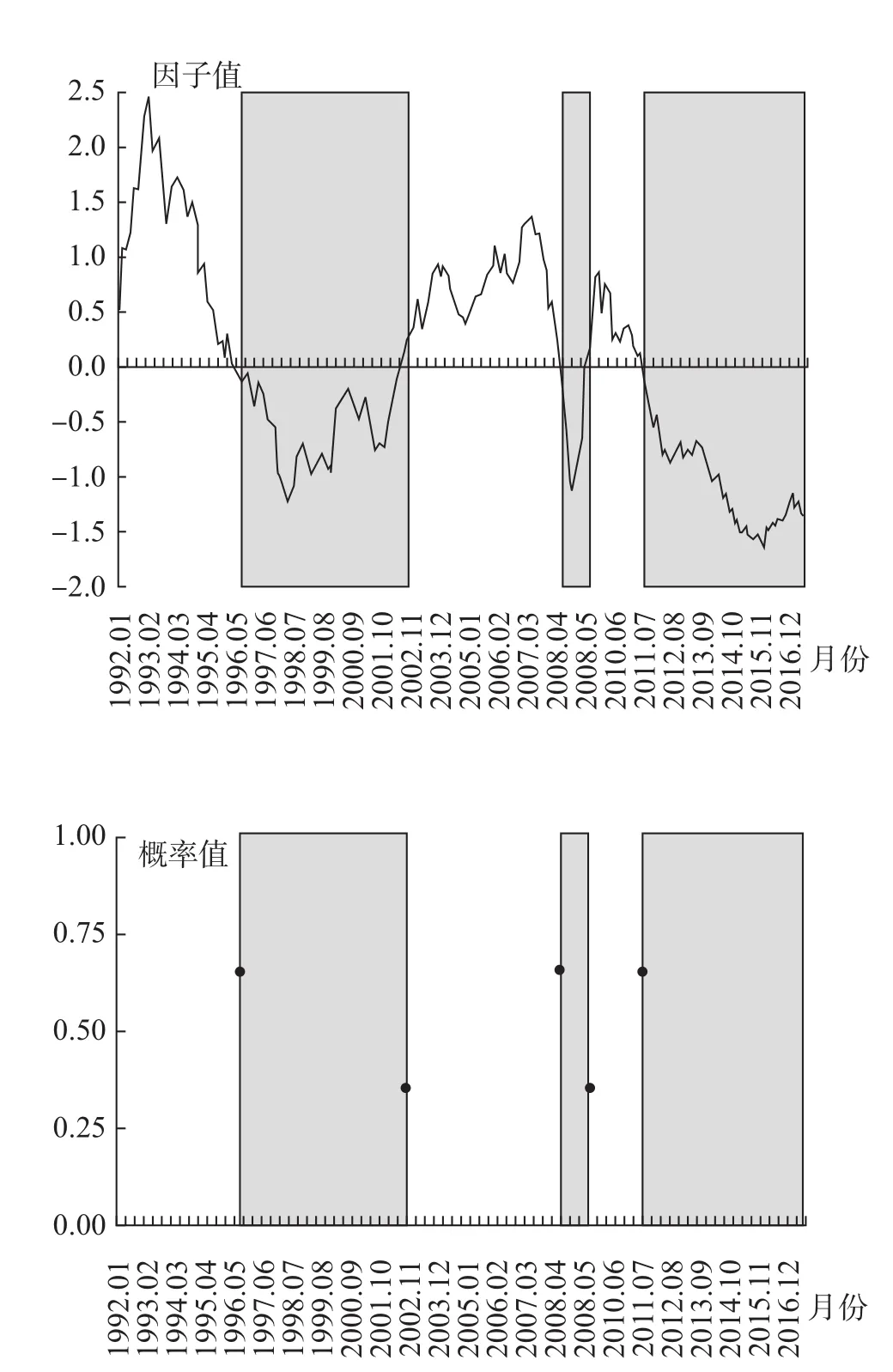
图4 CH准则法下经济周期拐点对应特殊概率值
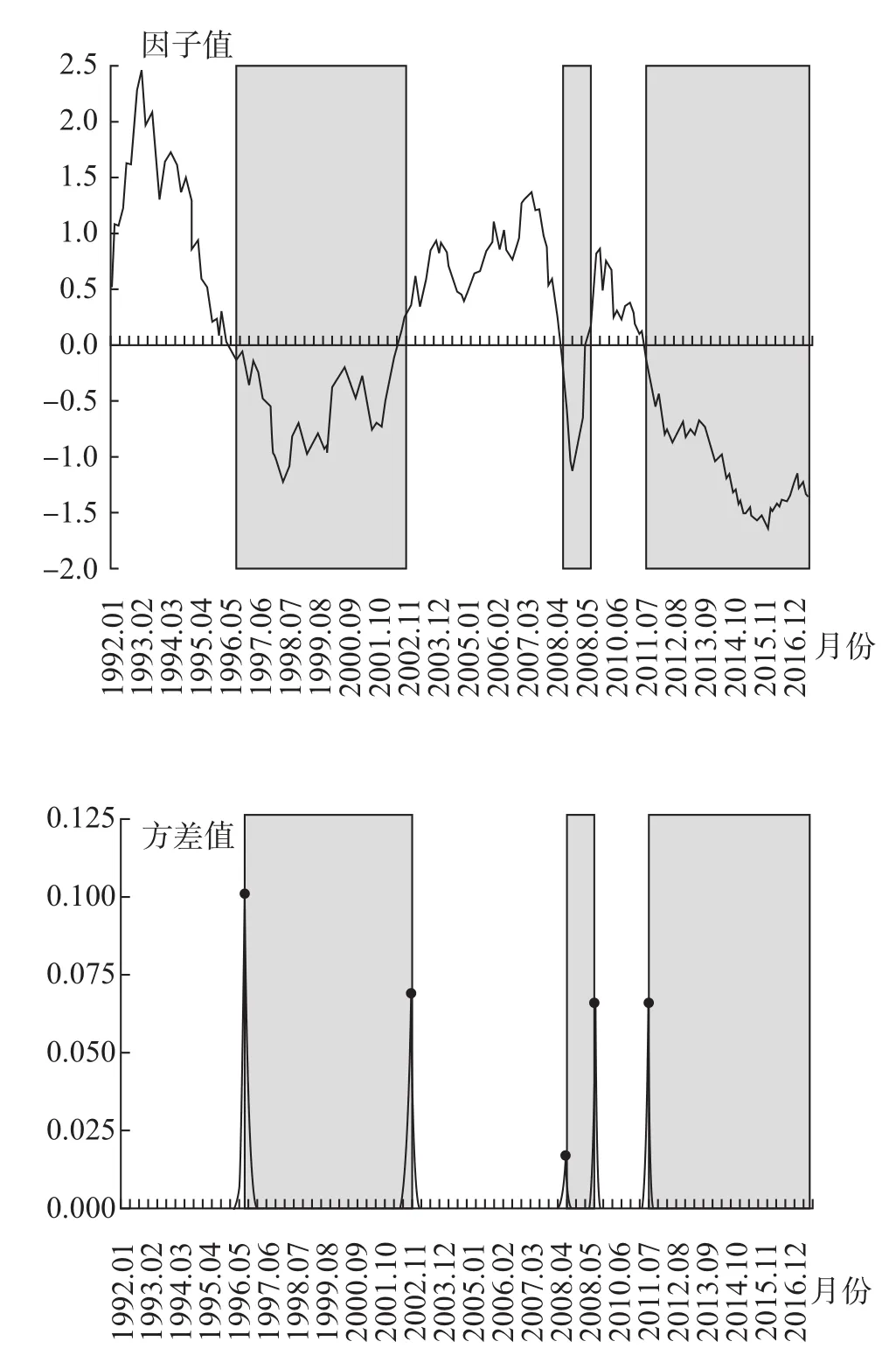
图5 概率方差法下经济周期拐点对应方差极大值
再次,两种方法测定结果的精准性比较。从ROC曲线下面积RUC值的大小来看,概率方差法和CH准则法对应的RUC值分别为0.996和0.994,表明概率方差法对经济周期的测定精准度高于CH准则法。从约登指数的最佳临界值VROC∗的大小来看,概率方差法和 CH准则法对应的VROC∗值分别为0.949和0.929,也表明概率方差法比CH准则法具有更高的经济周期测定精准度 (见图6和图7)。
最后,经济周期测定的具体结果。经过比较可知,概率方差法比CH准则法得到的经济周期测定结果更精准。3个经济高速增长期为:1992年1月至1996年6月、2002年11月至2008年8月、2009年9月至2011年8月;3个经济低速增长期为:1996年7月至2002年10月、2008年9月至2009年8月、2011年9月至2017年8月。这一测定结果与郑挺国和王霞 (2013)[3]利用月度、季度混频数据测定中国经济周期的研究结果差别不大。
(四)模型稳健性分析
模型稳健性分析主要检验混频动态因子模型的稳健性和可靠性。对66个GDP季度增长率实时数据序列 (见图8)进行处理,并依次替换混频动态因子模型中的GDP季度同比增长率指标,可以提取得到66个动态因子实时数据序列 (见图9)。比较图8和图9可以看出,GDP季度增长率实时数据序列和动态因子实时数据序列的主要波动走势特征是一致的,反映了混频动态因子模型具有较好的稳健性;同时,动态因子实时数据序列的波动走势比GDP季度增长率实时数据序列的波动走势更紧凑,波动协同性更突出,反映了混频动态因子模型具有较好的可靠性。
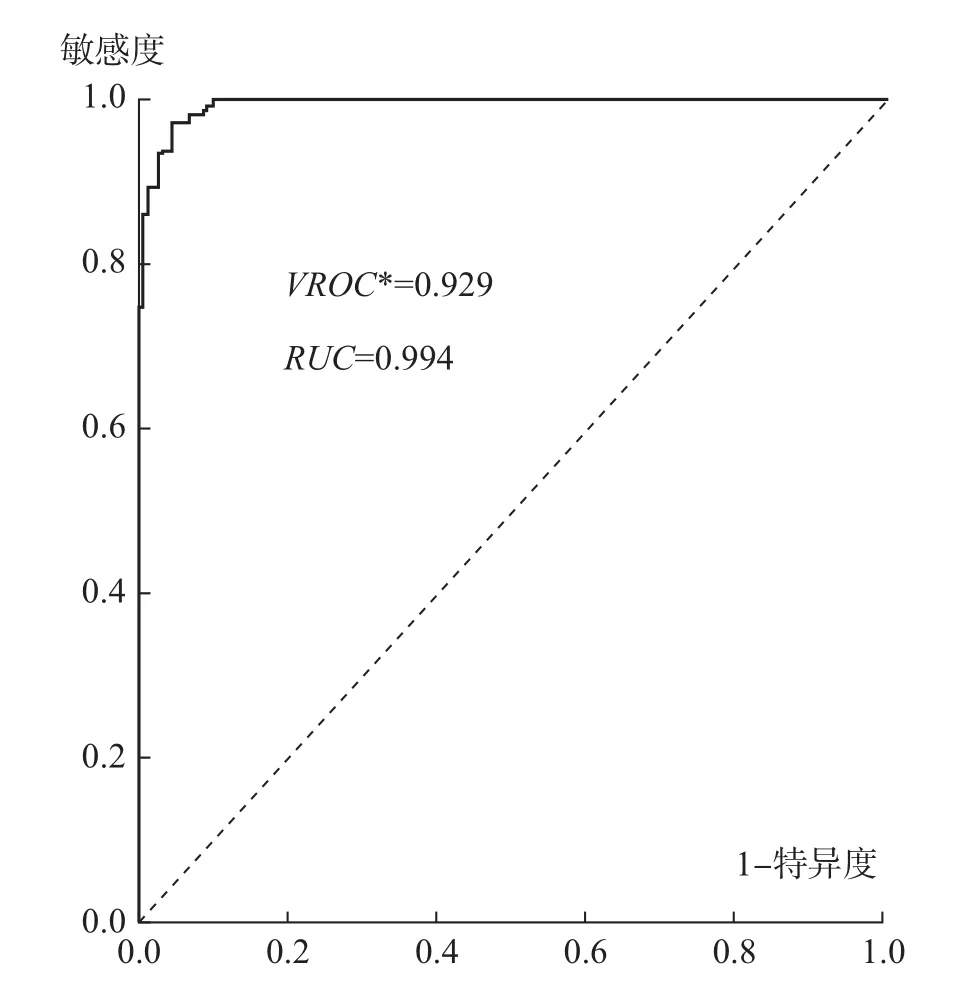
图6 基于CH准则法的ROC曲线
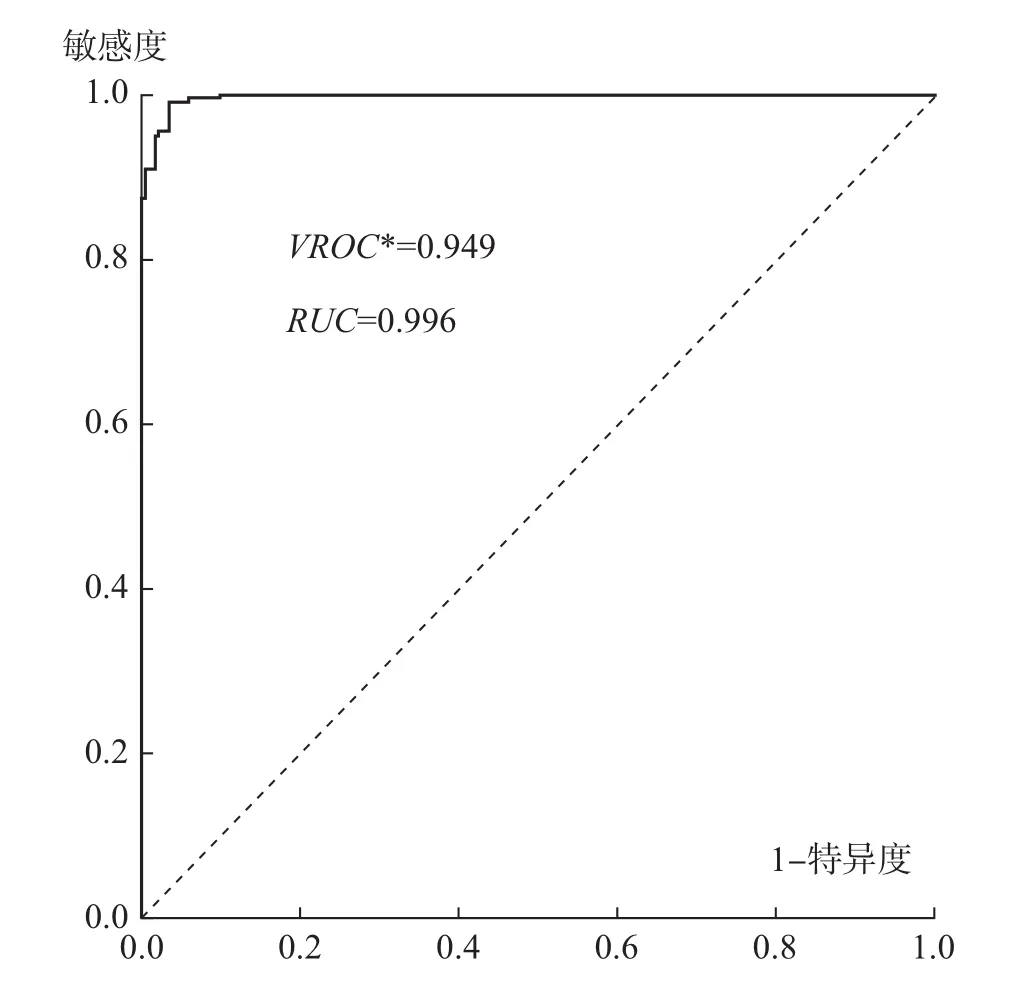
图7 基于概率方差法的ROC曲线
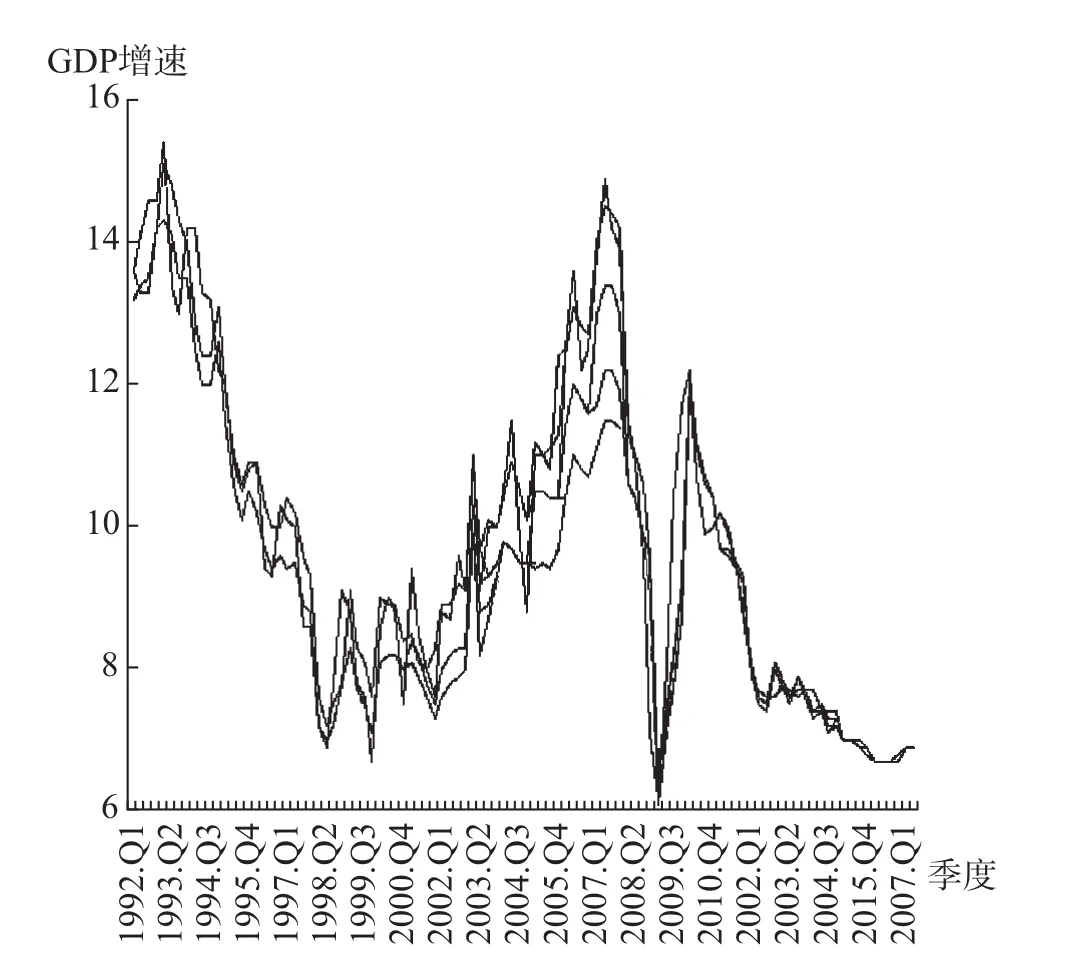
图8 GDP季度增长率波动走势实时数据

图9 动态因子波动走势实时数据
四、研究结论
利用经过数据处理后的3个月度指标、3个季度指标、5个半年度指标和4个年度指标,结合改进的混频动态因子模型和经济周期测定的概率方差法,本文对1992年1月至2017年8月期间的中国宏观经济周期进行了分析。主要研究结论如下:
第一,混频动态因子模型利用混频指标进行分析具有突出的优势。该模型支持利用多频度、多指标、非平衡数据进行分析;支持波动协同性弱的指标经调频处理后被采用,并能够有效提取此类指标数据中的有效信息和排除无效信息;能够提取更有效反映宏观经济波动一致性走势的不可观测动态因子。
第二,概率方差法测定中国宏观经济周期具有更好的精准度。该方法和CH准则法均能够测定出5个经济周期拐点,以及3个高速增长时期和3个低速增长时期。利用ROC曲线对两种方法的分析结果进行比较发现概率方差法的测定精准度更高。3个经济高速增长期为1992年1月至1996年6月、2002年11月至2008年8月、2009年9月至2011年8月;3个经济低速增长期为1996年7月至2002年10月、2008年9月至2009年8月、2011年9月至2017年8月。由于2011年9月以后,还没有发现宏观经济由低速增长期转向高速增长期的经济周期拐点,所以可预测中国宏观经济还将处于低速增长时期。
第三,利用实时数据检验了混频动态因子模型具有较好的稳健性和可靠性。
猜你喜欢
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
纺织科学研究(2021年1期)2021-03-19
——入侵植物响应人为扰动的适应性进化方向探究
发明与创新(2021年2期)2021-01-19
——《资本主义经济危机与经济周期:历史与理论》评介
山东社会科学(2020年1期)2020-01-16
中国外汇(2019年18期)2019-11-25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
初中生世界·九年级(2017年10期)2017-11-08
妇女之友(2017年3期)2017-04-20
经济研究导刊(2016年27期)2016-12-30
