
Web在线爬虫的设计与实现
2018-10-19 03:55:48韩前进
软件 2018年9期
韩前进
Web在线爬虫的设计与实现
韩前进
(石河子大学 信息科学与技术学院,新疆 石河子 832000)
为了方便用户简单高效的获取互联网数据,提出一种结合Web技术与爬虫技术的在线轻量级网络爬虫。该爬虫可在Web页面上进行配置,用户提交配置到远程服务器,服务器端爬虫程序进行数据抓取分析,最后由Web应用将结果返回到页面进行预览,同时支持生成数据结果接口URL,方便用户调用服务器上爬虫程序爬到的数据。
网络爬虫;搜索引擎;Web技术
0 引言
随着信息社会的飞速发展,互联网已经达到了一个空前的规模。网络爬虫作为分析互联网有效数据的得力工具,同样也在不停发展。
以往用户想要采集获得互联网数据,要么寻找开源的爬虫,要么自己写爬虫,再或者花钱请专业公司进行数据采集。无论是选择寻找开源的爬虫还是自己写爬虫程序,都需要进行安装软件,配置环境,安装依赖,学习使用等一系列步骤,对有基础的用户来说,这没什么大不了,但对于没有基础的用户来说,这无疑是一道坎。选择自己写爬虫程序时,还需要耗费大量时间与精力去编写代码与调试代码。花钱请专门的公司进行数据采集,除了增加开销之外,还可能面临数据时效性低的问题。
Web在线爬虫以期方便用户简单高效获得互联网数据。它结合了Web技术与爬虫技术。用户只需要安装一个浏览器,在配置页提交相关数据,即可调用服务器上的爬虫程序。用户通过Web应用提供的配置面板,将必要配置提交到服务器,服务器爬虫程序根据配置进行数据请求处理,最后将结果返回。用户在登录的情况下可根据数据抓取结果选择生成数据接口URL,用户在自己的程序中请求数据接口URL得到数据,将获得的数据构造到自己的应用场景中。
本文将对Web在线爬虫实现的实现原理、抓取策略、工作流程等进行分析介绍。
1 Web在线爬虫原理
1.1 Web在线爬虫实现原理简述
动态网站中相似网页的网页结构都是有规律的。以京东为例,京东网站的每个产品详情页中,分析页面结构,可以看到产品名称的类名为sku- name。那么,如果想获得该产品的相关数据,用户只需给出目标网址,目标网页中数据所在的标签,使用标签选择器与属性选择器就可以得到该类名标签中的数据。根据这个特点,可以设计让用户自行观察网页结构,提供标签选择器与属性选择器,指定目标网页URL即可让爬虫抓取数据。
Web在线爬虫主要分为Web应用与爬虫程序两大模块。
Web应用是用户与爬虫程序之间“联络人”,负责中转用户调用爬虫的请求与返回爬虫处理后的数据结果。
爬虫基于Node.js平台[1],使用Superagent请求初始页面URL,获得整个网页,使用Cheerio根据用户配置中的标签选择器与属性选择器分析页面,得到目标数据。
为了满足用户调用爬虫爬到的数据的需求,Web在线爬虫支持生成数据接口,这是一个返回爬虫爬取数据的URL。Web应用负责与数据库交互,数据库保存用户的爬虫配置。生成数据接口时,将爬虫配置写入数据库,请求数据接口时,从数据库获得配置,将配置设置到爬虫中进行爬取数据。为了提高响应速度,可以将爬虫爬取结果保存到数据库中,设置定时任务,定时调用爬虫程序爬取数据,更新数据库。当用户请求数据接口,直接从数据库取出数据进行响应。
1.2 Web在线爬虫的结构
Web在线爬虫运行结构如图1所示。它分为用户、Web应用、爬虫程序与互联网四大模块。用户发起调用爬虫请求,Web应用接受请求并调用爬虫程序,爬虫向互联网发起请求,处理分析得到的数据之后,将结果递交Web应用,Web应用将结果反馈给用户。
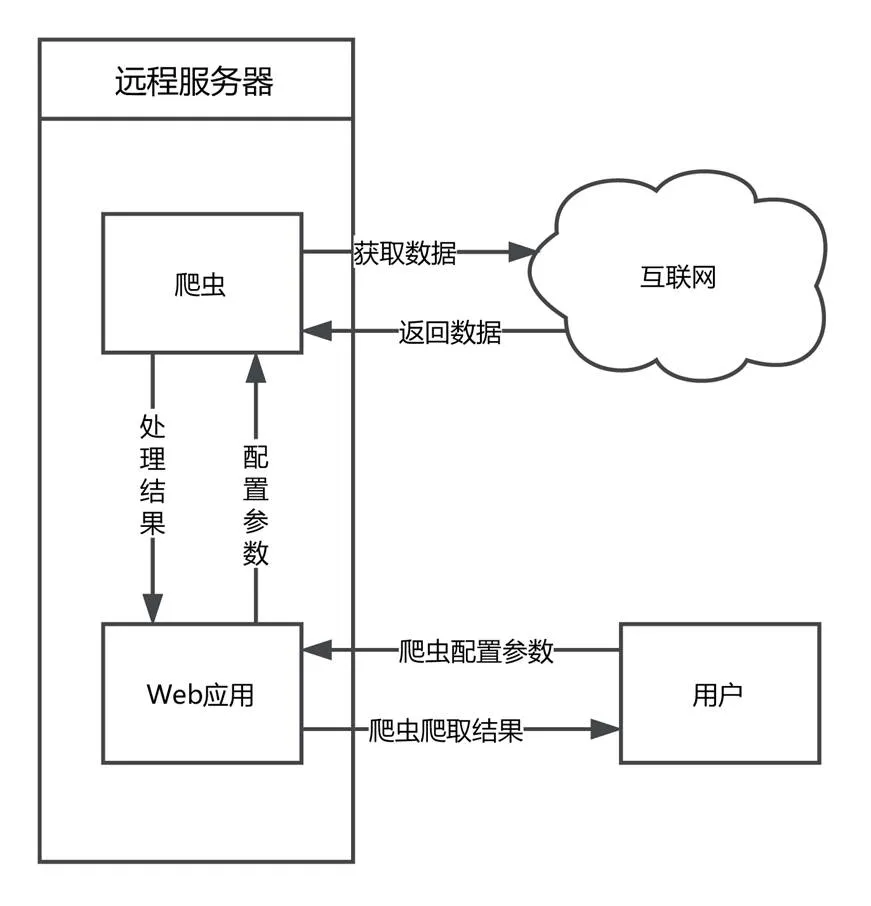
图1 Web在线爬虫运行结构
1.3 爬虫程序爬取过程
爬虫程序获得目标数据的过程如图2所示。从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足停止条件。
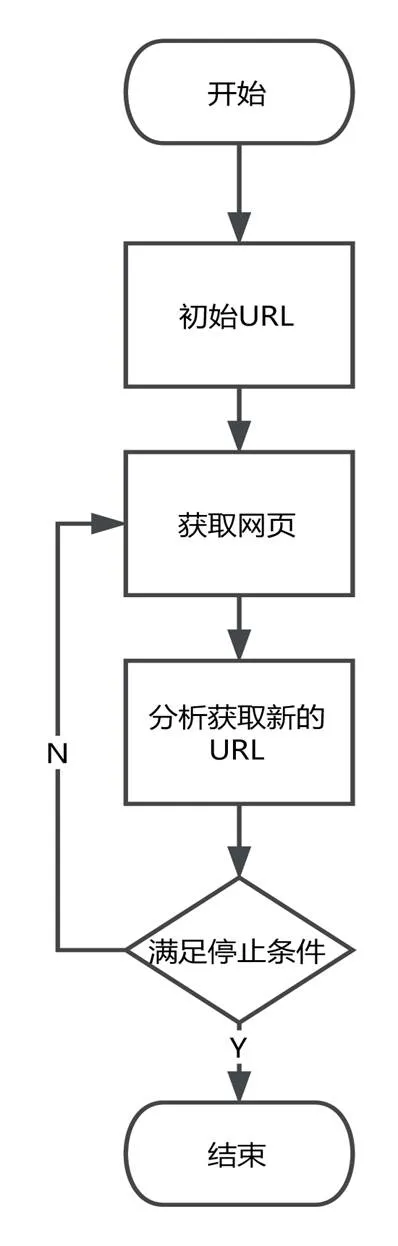
图2 爬虫获得目标数据的过程
1.4 爬虫程序获得中间URL
爬虫获得中间URL过程如图3所示,用户需要提供初始页面到目标页面的每一级a标签位置,以使得爬虫程序顺利找到目标页面。在目标页面,用户需要提供标签选择器与属性选择器以使得爬虫获得目标数据。
2 爬虫抓取策略
遍历策略[2]是爬虫的核心问题。在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取哪个页面,后抓取哪个页面。决定这些URL排列顺序的方法,叫做抓取策略。
爬虫策略主要有以下几种:
(1)深度优先遍历策略:
深度优先遍历测试是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路的链接之后,在再转入下一个起始页,继续跟踪链接。
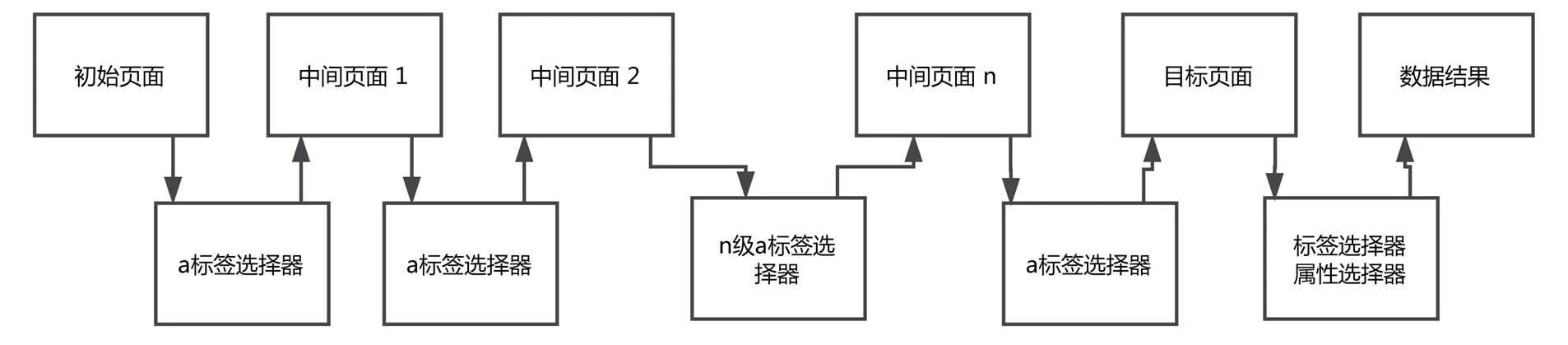
图3 爬虫获取中间URL的过程
深度优先策略不一定能适用于所有情况,深度优先如果误入无穷分枝(深度无限),则不可能找到目标节点
(2)广度优先策略
广度优先策略是按照树的层次进行搜索,如果此层没有搜索完成,不会进入下一层搜索。即,首先完成一个层次的搜索,其次在进行下一层次,也称之为分层处理。
广度优先遍历策略属于盲目搜索,它并不考虑结果存在的可能位置,会彻底地搜索整张图,因而效率较低,但是,如果尽可能的覆盖较多的网页,广度优先搜索方法是较好的选择。
(3)部分的PageRank的策略
对于已经下载的网页,连同待抓取URL队列的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取队列中的URL按照网页级别的值的大小排列,并按照顺序依次抓取网址页面。
(4)OPIC(在线页面重要性计算)策略:
在算法开始前,给所有页面一个相同的初始现金,当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
OPIC与PageRank的区别在于:PageRank的的的每次需要迭代计算,而OPIC策略不需要迭代过程所以计算速度远远快与PageRank的的的,适合实时计算使用。
Web在线爬虫系统采用广度优先搜索算法,用户在提供的配置面板中配置从初始页面到目标页面搜索路径,有效避免了广度优先搜索的盲目搜索问题。
广度优先搜索是一种简单直观且历史悠久的遍历方法。Web在线爬虫通过一个或一组URL为初始页面,通过用户指出的每层的URL(用户给出a标签选择器,利用cheerio分析HTML标签即可获取URL),逐层向下请求分析搜索,直到得到目标数据。
爬虫的广度优先搜索路径如图4所示,程序首先会从初始页面中分析获得所有到目标页面的一级URL,然后依次请求一级URL,得到网页数据,进行分析之后,再得到二级URL,再进行请求分析...请求分析到目标页面停止,此时在目标页面运用标签选择器与属性选择器即可获得目标数据。
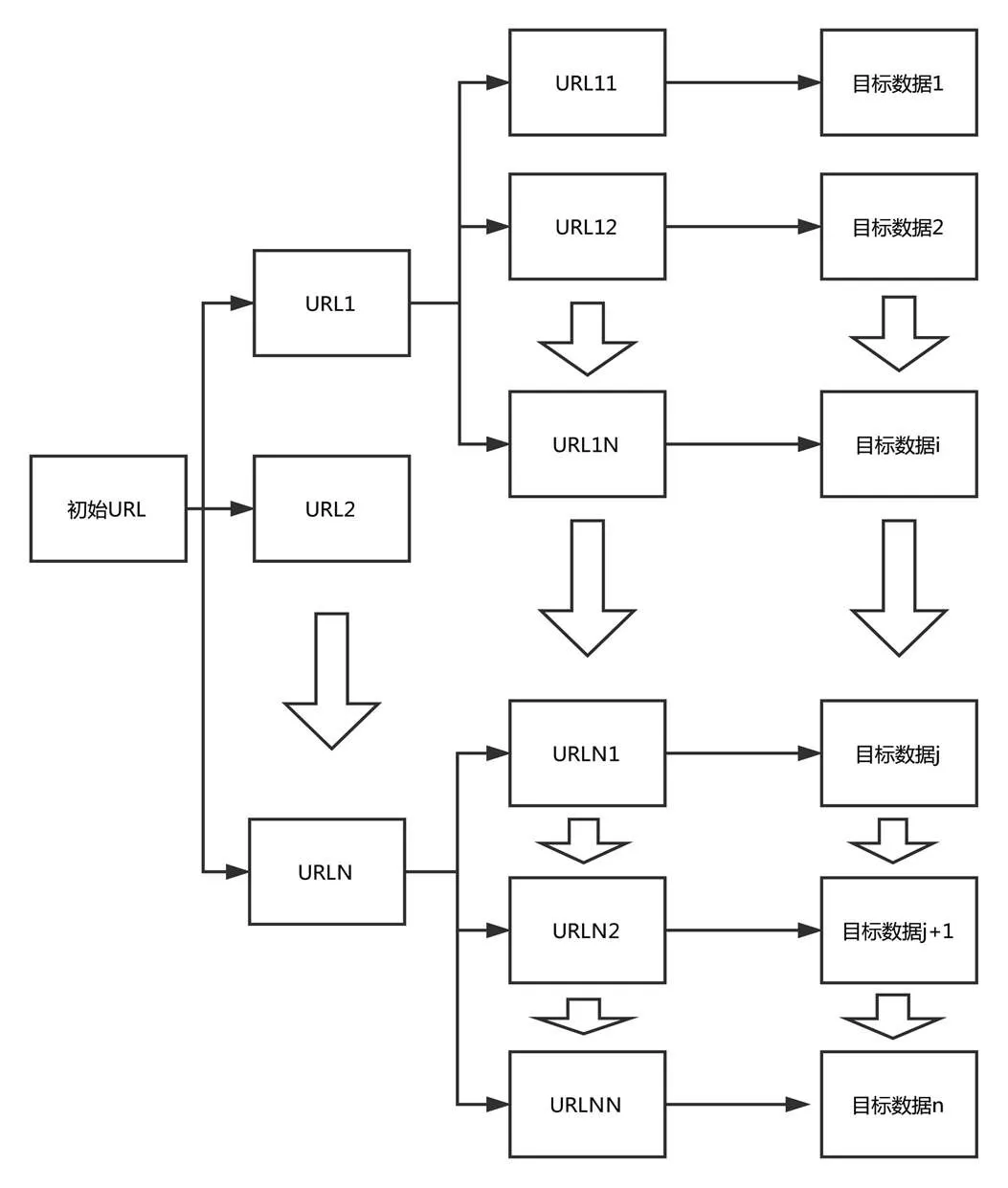
图4 爬虫的广度优先搜索路径
3 Web在线爬虫的工作流程
(1)用户发起URL请求,Web应用响应Web在线爬虫配置面板
(2)用户提交爬虫配置,Web应用将配置递交爬虫程序
(3)爬虫程序根据递交的配置,进行数据请求,处理分析,最后将处理结果递交Web应用
(4)Web应用将结果返回用户
(5)数据符合用户需求,用户发起生成数据接口请求
(6)Web应用判断用户是否登录,如果登录,数据库保存用户提交的爬虫配置,与数据处理结果,如果没有登录,返回登录提示。
(7)程序定时请求从数据库获得爬虫配置,调用爬虫程序,获得结果数据后,更新数据库中结果数据,保持数据库数据“新鲜”
(8)用户调用数据接口,Web应用取出数据库数据进行响应
4 Web在线爬虫实现
4.1 技术储备
Web在线爬虫后端采用Node.js平台,原因是Node.js轻量,生态丰富。前端使用Vue框架进行页面搭建。
采用Koa.js[3]Web开发框架。它具有轻量、表现力丰富、健壮的特点。
采用Superagent[4]请求库。这是一个轻量的、渐进式的Ajax API,是Node.js里一个非常方便的客户端请求代理模块,可读性较好。
采用Cheerio[5]。这是一个Node.js的抓取页面模块,是为服务器特别定制的,快速、灵活、实施的jQuery核心实现。适合各种Web爬虫程序。
采用Async[6]。这是一个流程控制工具包,提供了直接而强大的异步功能。基于JavaScript为Node.js设计,同时也可以直接在浏览器中使用。
采用MongoDB[7]。这是一个基于分布式文件存储的数据库。它支持的数据结构非常松散,是类似JSON的BSON格式。这种文档结构的存储方式,使用户能够更便捷的获取数据。
采用Vue.js[8]前端框架。这是一套用于构建用户界面的渐进式框架。
4.2 在线爬虫具体实现
(1)使用Koa.js Web开发框架,搭建Web应用。
(2)编写Web前端页面,负责用户填写提交爬虫配置。爬虫基本配置项有:1)初始页面URL。2)初始页面到中间页面n中每一级的a标签选择器。3)目标页面目标数据的标签选择器与属性选择器。
(3)将Web页面配置提供的a标签选择器压入队列。
(4)编写爬虫程序。Superagent请求库请求初始页面URL,根据用户提供的a标签选择器,使用Cheerio分析获得下一级页面的URL,将所有获得到的URL压入队列,递归调用Superagent,直到a标签选择器队列里,所有标签都分析完。此时,分析到目标页面,根据标签选择器与属性选择器,得到目标数据。
(5)将爬虫得到的数据存入数组,由Web应用返回给用户。
(6)为了增强爬取效率,使用Async异步请求库,进行并发请求。
(7)为了防止被目标服务器发现爬虫爬取数据。为Superagent设置请求头,使用HTTP代理池,代理访问请求。
(8)调用数据接口时,Web应用从数据库查找用户配置,再调用爬虫抓取数据,最后再返回结果。当调用数据接口频率过大时,会对服务器造成不小的压力。因此,将爬虫爬取的结果存入数据库,设置定时任务,定时调用爬虫程序,更新数据库中爬虫爬取的结果。当请求数据接口时,直接从数据库中找到数据,返回结果。
5 爬虫核心代码
5.1 爬虫主函数
//爬虫主函数,根据a标签选择器,得到下一级URL
function splider(urls) {
return new Promise((resolve, reject) => {
//async流程控制库,控制并发请求数量为5
async.mapLimit(urls, 5, function(url, callback) {
//superagent请求url
superagent.get(url).end(function(err, res) {
//服务器响应错误,或网络错误
if (err) {
reject(err);
}
//保存结果
var allurls = [];
//将服务器响应内容载入Cheerio
var $ = cheerio.load(res. text);
//分析过滤
$('#list a').each(function(idx, element) {
var $element = $(element);
var href = url.resolve (url, $element.attr('href'));
allurls.push(href);
});
//调用回调函数,将局部结果传递到回调函数中保存,回调函数内部将局部结果拼接。
callback(null, allurls)
}, function(err, result) {
if (err) reject(err);
//函数执行完毕,将结果 返回
resolve(result);
})
})
})
}
5.2 Web应用响应函数
//Koa.js处理Web请求
app.use(async function(ctx, next) {
//用户以get方式,请求/result路径
if (ctx.request.path === "/result" && ctx.request.method === "GET") {
//请求参数(内含爬虫配置参数)
const body = ctx.request.query;
try {
//响应用户爬虫的爬取结果
ctx.response.body = await splider (body.targetUrl);
} catch (e) {
//爬虫响应失败,返回错误提示
ctx.response.body = "Something was wrong " + e;
}
} else {
await next();
}
});
6 Web在线爬虫使用实例
爬取目标:豆瓣电影排行榜中每部电影的详细信息。
豆瓣电影排行榜如图5所示。
豆瓣电影的电影详情页如图6所示。
爬虫配置页面如图7所示。配置页中爬取深度指出初始页面到目标页面之间有几层,目标网址即初始页面URL,1级选择器是初始页面到目标页面的a标签选择器,2级选择器则为数据所在的普通选择器,输出结果格式中保存数据的属性选择器。
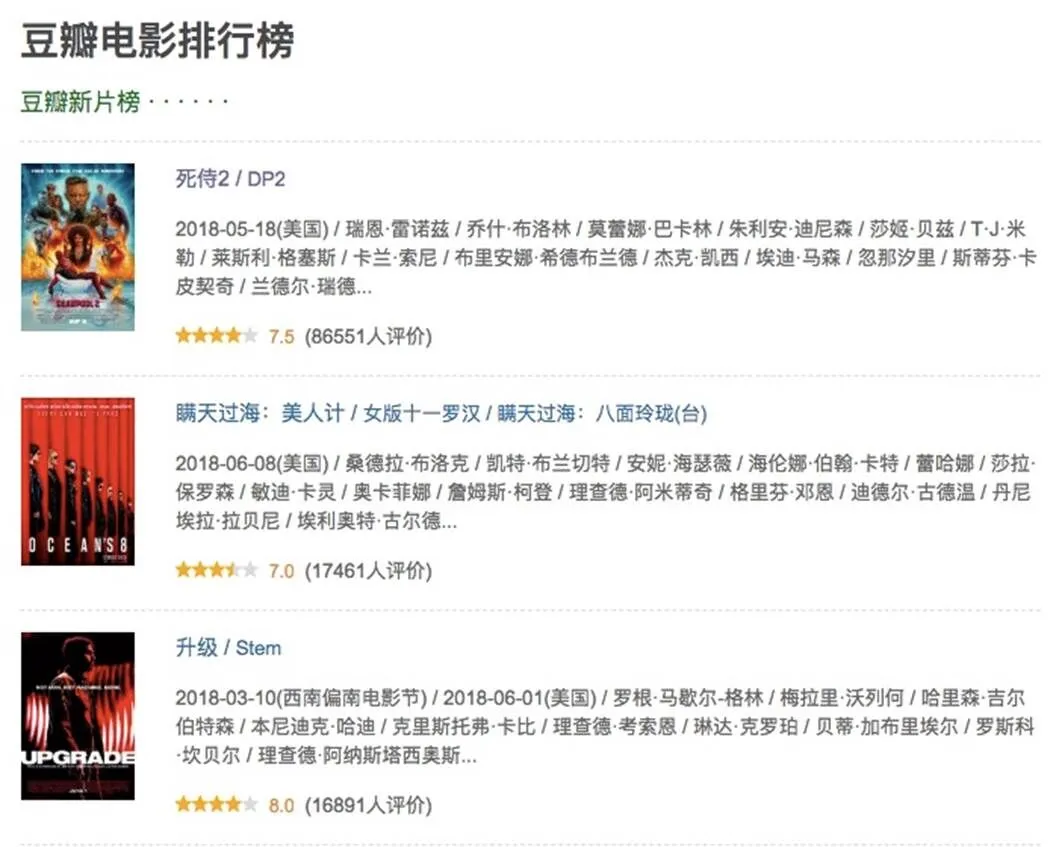
图5 豆瓣电影排行榜(部分)

图6 豆瓣电影的电影详情页
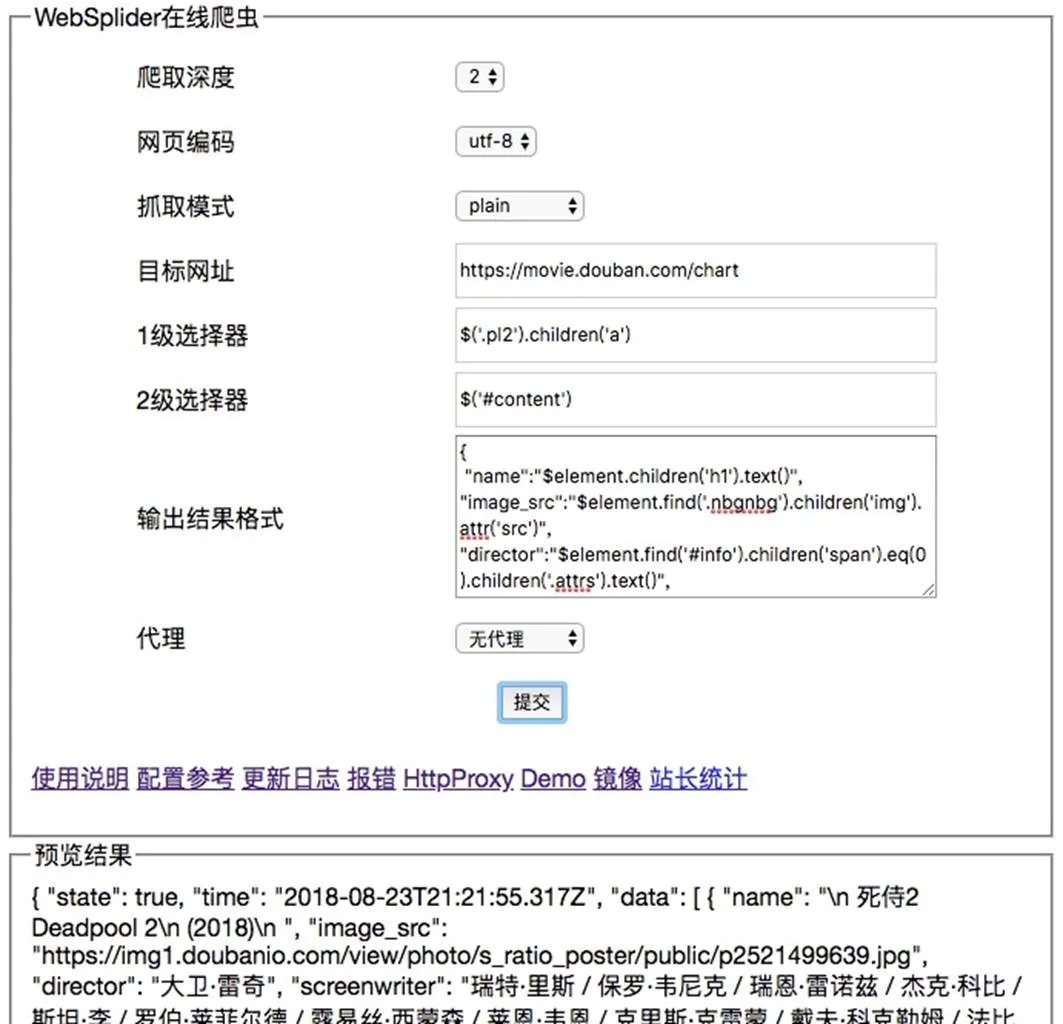
图7 在线爬虫配置页面
请求数据接口响应的爬虫爬取结果如图8所示。

图8 数据接口响应的数据
7 数据接口调用
7.1 数据接口
数据接口实例:http://www.domain.com/interface?name=tom&cid=123456
链接参数说明:
name参数指注册用户用户名。只有注册用户才能生成数据接口。
cid参数指当前用户的爬虫配置参数id,每个cid对应数据库中一个爬虫配置。
7.2 Java调用实例[9]
public static String sendGet(String url, String param) {
String result = "";
BufferedReader in = null;
try {
String urlNameString = url + "?" + param;
URL realUrl = new URL(urlNameString);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("accept", "*/*");
connection.setRequestProperty("connection", "Keep-Alive");
connection.setRequestProperty("user-agent", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;SV1)");
// 建立实际的连接
connection.connect();
// 获取所有响应头字段
Map
// 遍历所有的响应头字段
for (String key : map.keySet()) {
System.out.println(key + "--->" + map.get(key));
}
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result += line;
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result;
}
sendGet(‘http://www.domain.com/interface’,’name=tom&cid=123456’);
7.3 PHP调用实例[10]
function do_get($url, $params) {
$url = "{$url}?".http_build_query($params);
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
curl_setopt($ch, CURLOPT_TIMEOUT, 60);
curl_setopt($ch, CURLOPT_POSTFIELDS, $params);
$result = curl_exec($ch);
curl_close($ch);
return $result;
}
do_get("http://www.domain.com/interface", array('name' => 'tom','cid'=>'12345'));
7.4 Node.js调用实例
const request = require('request');
request('http://www.domain.com/interface?name= tom&cid=123456',function(error,response, body) {
if (!error && response.statusCode == 200) {
console.log(body)
}
})
8 结语
本文介绍了Web在线网络爬虫设计与实现,对在线爬虫原理进行了简要分析,并重点对爬虫实现的关键技术进行了讲解与实现。虽然市面上爬虫技术的数据采集系统有很多,但基本都需要进行安装软件、配置环境等一系列的过程,如果没有合适的爬虫程序,则还需要程序员手动编写代码实现自己的爬虫,而这期间,耗费的时间与精力不言而喻。Web在线爬虫简化了过程,只需要在Web页面上进行简单的配置,就可以利用服务器上的爬虫程序,获得爬取的数据结果。选择生成数据接口之后,用户在自己的程序中,利用HTTP请求库,请求数据接口获得数据,将数据构造到自己的程序即可。这大大方便了用户获取互联网上的数据。
没有一种爬虫程序适用所有应用场景。同样,对于Web在线爬虫来说也是如此,Web在线爬虫爬取的数据,是以HTTP报文的形式在互联网上传输,当Web应用响应的数据量过大,很容易造成响应超时、响应中断的结果。所以Web在线爬虫适合爬取传输一些数据量较小的数据。同时因为互联网数以亿计的网站中,网页结构千差万别,为了满足爬虫的通用性,爬虫并没有对Ajax动态响应的内容进行解析与处理,所以对于一些使用Ajax动态加载的网页无能为力。但是,这并不意味着Web在线爬虫没有实用价值。使用Web在线爬虫,可以用来监控目标网站数据,比如,我想知道北京到西安的某一个航班在10月的机票价格情况,可以使用Web在线爬虫爬取航空公司网站,生成数据接口之后,用户每天请求数据接口,将得到的数据保存汇总即可。同样,还可以用来监控自己在购物网站上喜爱的物品降价没有,自己追的剧更新没有等等。
[1] alsotang. 使用superagent与cheerio完成简单爬虫[OL]. (2014-10-27)[2018-07-5]. https://github.com/alsotang/node- lessons/tree/master/lesson3.
[2] neituime. 网络爬虫基本工作流程和抓取策略[OL]. (2015- 12-08)[2018-07-6]. https://blog.csdn.net/neituime/article/details/50218833.
[3] StrongLoop. Koa-next generation web framework for node.js [OL]. [2018-07-6]. https://koajs.com.
[4] visionmedia.SuperAgent-elegant API for AJAX in Node and browsers[OL]. [2018-07-6]. http://visionmedia.github.io/superagent/.
[5] cheeriojs. Cheerio[OL](2018-7-7)[2018-7-8]. https://github. com/cheeriojs/cheerio.
[6] caolan. async [OL].(2018-5-20) [2018-7-10]. https://caolan. github.io/async/.
[7] Dwight, Merriman, Eliot, Horowitz, Kevin, Ryan. MongoDB Documentation [OL]. [2018-7-10]. https://docs.mongodb.com/.
[8] Phan An, defcc, Jinjiang. Vue教程[OL]. [2018-7-10]. https: //cn.vuejs.org/v2/guide/index.html.
[9] 五指少年. java发送http请求[OL]. (2016-08-31) [2018- 07-10]. https://www.cnblogs.com/xrab/p/5825105.html.
[10] 小云云. PHP实现发送HTTP请求[OL]. (2018-03-27) [2018- 07-10]. http://www.php.cn/php-weizijiaocheng-390267.html.
Design and Implementation of Web Online Crawler
HAN Qian-jin
(Shihezi University, Shihezi Xinjiang, 832000, China)
In order to facilitate users to obtain Internet data simply and efficiently, an online lightweight web crawler combining Web technology and crawler technology is proposed. The crawler can be configured on the Web page, the user submits the configuration to the remote server, the server crawler program carries out the data capture and analysis, and finally returns the result to the page for preview by the Web application, and supports the generation of the data result interface URL, which is convenient for the user to call the data crawled by the crawler program on the server.
Search engines; Web crawler; Web technology
TP393.092
A
10.3969/j.issn.1003-6970.2018.09.018
韩前进(1996-),男,石河子大学信息科学与技术学院计算机科学与技术专业学生。
本文著录格式:韩前进. Web在线爬虫的设计与实现[J]. 软件,2018,39(9):86-92
猜你喜欢
电子工业专用设备(2024年1期)2024-02-29 02:24:46
房地产导刊(2022年10期)2022-10-18 08:03:52
现代信息科技(2021年21期)2021-05-07 02:54:12
商品与质量(2019年34期)2019-11-29 03:25:51
测控技术(2018年5期)2018-12-09 09:04:46
电子测试(2018年1期)2018-04-18 11:53:04
电脑与电信(2017年6期)2017-08-08 02:04:22
电子制作(2017年9期)2017-04-17 03:00:46
信息安全研究(2016年4期)2016-12-01 06:07:05
大学物理实验(2015年2期)2015-10-22 01:04:39
