
Node.js异步编程模式探讨
2018-10-18 08:38周安辉
四川职业技术学院学报 2018年4期
周安辉
(内江职业技术学院,四川 内江 641100)
0 引言
Node.js是一个编写网络服务和网页应用的平台,采用C++语言编写,优化了Google V8引擎,能够高效地运行JavaScript代码,同时提供了文件、网络等众多系统级的API,有助于开发人员快速地构建高性能的网络服务及其应用。
Node.js围绕一个事件驱动的无阻塞I/O的异步编程模式而构建,代码执行无须阻塞等待某种低速的I/O操作完成而继续,充分利用了有限的资源,非常适合编写处理大量并发请求的后台网络服务。此外,服务器端与客户端的编写,统一使用JavaScript语言,受到开发人员的极大欢迎。
1 Node.js编程中的函数概念[2]
基于函数的传统编程,开发人员是相当熟悉的,大部分编程语言都使用,Node.js也不例外,但是要注意一些概念上的区别。在Node.js的编程中,要正确理解以下几个基本的函数概念,可以帮助我们掌握Node.js的编程模式。
1.1 立即执行函数
在Node.js中可以在定义一个函数后立即执行它。只需要简单地用()括号包裹函数,并调用它,如下所示:.
(function myData(){
console.log('myData was executed!');
})();
在 JavaScript中,if、else或 while语句体并不会创建一个新的变量作用域。如下所示:
var myData=123;
if(true){
var myData=456;
}
console.log(myData);//456;
在JavaScript中,只有使用一个立即执行函数会创建一个新的变量作用域。如下所示:
var myData=123;
if(true){
(function(){//create a new scope
var myData=456;
console.log(myData);//456;
})();
}
console.log(myData);//123;
1.2 匿名函数
一个没有名字的函数被称为匿名函数。在JavaScript中,你可以指派一个函数给一个变量。如果你打算把一个函数赋值给一个变量,你不需要使用命名函数。
以下两种方式定义一个内联函数,两者是等价的:
var foo1=function namedFunction(){
console.log('foo1');
}/*www.java2s.com*/
foo1();//foo1
var foo2=function(){//no function name i.e.anonymous function
console.log('foo2');
}
foo2();//foo2
1.3 首类函数
JavaScript语言拥有首类函数。首类函数意味着函数被当作对象一样的东西来看待,可以把它指派给一个变量。
高阶函数
因为JavaScript语言允许指派函给变量,所以能够传送函数给其他函数。高阶函数意味着使用其他函数作参数或者返回一个函数作结果。setTimeout是一个很常见的高阶函数例子,用法如下:.
setTimeout(function(){
console.log('2000 milliseconds have passed since this demo started');
},2000);
在Node.js运行这个代码,你会在两秒后才看见控制台日志消息。
在setTimeout中使用了一个匿名函数作为第一个参数,这让setTimeout成为一个高阶函数。
也可定义一个函数,显式传递给setTimeout,如下所示:
function foo(){
console.log('2000 milliseconds have passed since this demo started');
}
setTimeout(foo,2000);
1.4 闭包函数
这个概念是非常直观和简单。如果一个函数定义在另外一个函数的内部,内部函数要访问外部函数声明的变量。如下所示:
function outerFunction(arg){
var variableInOuterFunction=arg;
function myValue(){
console.log(variableInOuterFunction);
}
myValue();
}
outerFunction ('hello closure!');//logs hello closure!
即使外部函数已经返回,内部函数还是能够访问外部作用域的变量。因为该变量仍然被内部函数绑定,并不依赖于外部函数。如下所示:
function outerFunction(arg){
var variableInOuterFunction=arg;return function(){
console.lo(variableInOuterFunction);
}
}
var innerFunction = outerFunction('hello closure!');
innerFunction();
2 Node.js的标准回调编程模式
Node.js异步编程采用后续传递风格(continuation-passing style,CPS),编写的CPS函数有一个显式的“后续”函数作为额外参数,在调用CPS函数计算出返回值时,并不表示函数结束,而将CPS函数的返回值作为“后续”函数的参数,继续调用“后续”函数,显示地将流程控制权传递给“后续”函数。
2.1 回调函数
在后续传递风格的编程中,每个函数在执行完毕后都会调用一个回调函数,将程序继续进行下去。如你所见,在JavaScript就是采用这种方式编程,例如Node.js中,将input.txt文件加载到内存并显示出的例子:
var fs=require('fs');
fs.readFile ('./input.txt',function(err,data){
if(err){
console.log(err.stack);
return; }
console.log(' 文件内容: ',data.toString());
});
console.log('Reading file...');
执行这段代码,首先会显示'Reading file...'字符串,然后等待回调函数的结果返回后,才会显示文件内容,这是一种典型的异步执行模式。
注意:内联匿名回调函数的第一个参数是一个错误对象,如果有错误发生,其为Error类的一个实例,这是Node.js中应用CPS编程的一个通用模式。
2.2 链式回调函数
使用异步方法并不能保证执行次序,下面的例子是我们经常犯的错误:
var fs=require('fs');
fs.rename('/tmp/hello','/tmp/world',(err)=>{
if(err)throw err;
console.log('renamed complete');
});
fs.stat('/tmp/world',(err,stats)=>{
if(err)throw err;
console.log(`stats:${JSON.stringify(stats)}`);
});
fs.stat?可能在fs.rename之前被执行。要保证流程控制权的正确执行次序,正确的做法是采用链式回调函数,如下所示:
var fs=require('fs');
fs.rename('/tmp/hello','/tmp/world',(err)=>{
if(err)throw err;
fs.stat('/tmp/world',(err,stats)=>{
if(err)throw err;
console.log(`stats:${JSON.stringify(stats)}`);
});
});
3 事件驱动编程模式
Node.js大量使用事件来决定程序的流程控制权,使它与其他采用“事件驱动编程”相似技术相比较,Node.js就显得更快更高效。Node.js一旦启动了它的服务器,它仅是简单地初始变量,声明函数,然后就只需等待事件发生。
标准回调模式是单事件工作模式,在异步函数返回其结果时触发调用回调函数。如果是在函数的执行中发生了多个事件或事件重复发生,这种模式就不是很理想了,而事件驱动模式则在这种情形下很好工作。一般而言,在需要请求的操作完成后要重获流程控制权,采用标准回调模式,而当多个事件发生或事件重复发生时,要决定流程控制权,采用事件驱动模式。本质上,可以把Node.js标准回调模式视为特定的单事件驱动编程模式。
在事件驱动模式编程中,侦听事件的函数充当观察器,只有事件发生器发射一个事件被观察到时,它的侦听器的回调函数才开始执行。
3.1 事件发生器内置事件类型的侦听
下面的代码,create_websever.js用于创建一个web服务器,ex2_event.js演示请求web页面时,并对response发射的data与end内置事件类型进行响应:
create_websever.js文件如下所示:
const http=require('http');
const hostname='127.0.0.1';
const port=3000;
const server=http.createServer((req,res)=>{res.statusCode=200;
res.setHeader('Content-Type','text/plain');
res.end('Hello World ');
});
server.listen(port,hostname,()=>{
console.log(`Server running at http://${hostname}:${port}/`);
});
ex2_event.js文件:
var http=require('http');
var options={
host:'127.0.0.1',
port:3000,
path:'/'
};
var req=http.request(options,function(res){res.setEncoding('utf8');
res.on('data',function(data){console.log('some data from the response',data);
});
res.on('end',function(){console.log('response ended');
});
})
req.end();
3.2 自定义事件类型的侦听[1]
Node.js?使用events模块和?EventEmitter?类实现自定义事件类型编程。通过?EventEmitter?类来绑定事件与事件侦听器,可以实现多个自定义事件类型的发射和侦听。如下代码所示:
//Import events module
var events=require('events');
//Create an eventEmitter object
var eventEmitter=newevents.EventEmitter();
//Create an event handler as follows
var connectHandler=function connected(){console.log('connection succesful.');
//Fire the data_received event
eventEmitter.emit('data_received');}
//Bind the connection event with the handler
eventEmitter.on('connection',connectHandler);
//Bind the data_received event with the anonymous function
eventEmitter.on ('data_received',function(){
console.log('data received succesfully.');});
//Fire the connection event
eventEmitter.emit('connection');
console.log(“Program Ended.”);
3.3 对“error”事件的处理
在Node中,事件发生器采用通用接口服务各种类型的事件,但是“error”事件除外,大部分Node事件发生器在程序产生错误时都要产生“error”事件。如果不监听该事件,“error”事件发生时,Node事件发生器会抛出一个未捕获的异常,显示一个堆栈追踪,而且Node进程会退出。
最佳实践是始终侦听“error”事件,如下所示:
var myEmitter=new(require('events').EventEmitter)();
myEmitter.on('error',(err)=>{
console.log('whoops!there was an error');
});
myEmitter.emit ('error', new Error('whoops!'));
4 理解Node.js事件轮询[5]event loop
Node.js的event loop,后台采用Libuv[4]高性能的事件轮询模型,负责调度回调函数队列的执行,是实现非阻塞I/O异步编程的关键机制。当Node.js启动时,将初始化event loop,处理那些可能做异步API调用、定制计时器或调用process.nextTick()的输入脚本,然后开始处理event loop。
event loop包括六个循环阶段,如下图1所示:
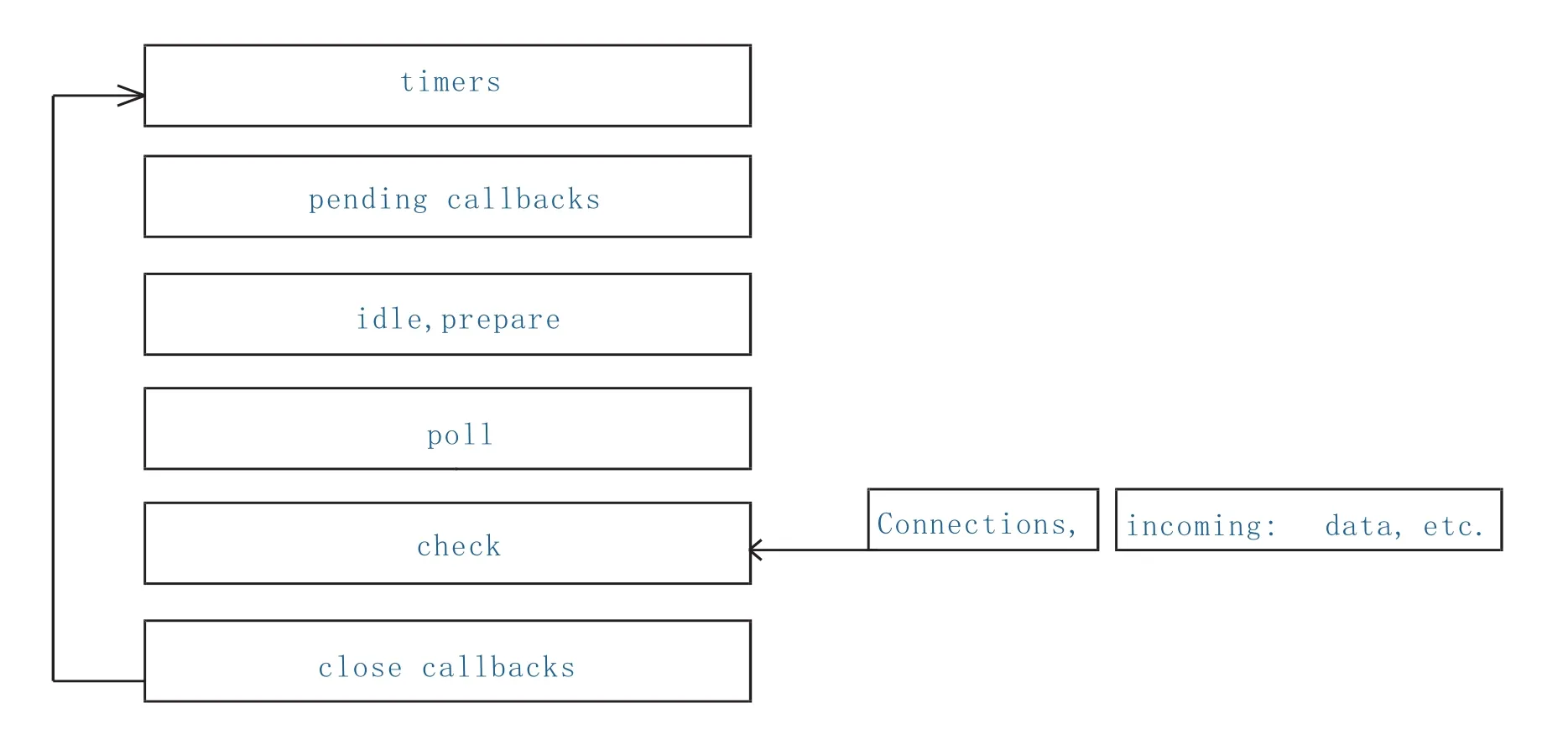
图1 六个循环阶
每个阶段都有一个可执行的回调函数的FIFO队列。尽管每个阶段具有自己特殊方式,通常,当事件循环进入一个给定的阶段,它将执行这个阶段的任何特定操作,然后执行在这个阶段的队列中的回调函数,直到队列为空或者回调函数数量达到上限,event loop会进入到下一下阶段,等等,细节可参考官方文档[3]。
5 小结
Node.js后续传递风格的编程,看上去很丑陋,并且与传统的编程思维模式相违背,让人入手时难以适应,只有当你深入理解事件轮询event loop的基本原理后,对于Node.js后续传递风格的异步编程会有较大帮助,并且会逐步喜欢上它的简明与高效。
猜你喜欢
今日农业(2021年19期)2022-01-12
数学物理学报(2021年1期)2021-03-29
数学物理学报(2020年6期)2021-01-14
哈尔滨轴承(2020年1期)2020-11-03
商品与质量(2019年34期)2019-11-29
测控技术(2018年5期)2018-12-09
数学物理学报(2018年5期)2018-11-16
汽车观察(2018年10期)2018-11-06
中山大学法律评论(2018年1期)2018-03-30
信息安全研究(2016年4期)2016-12-01
