
基于DMSP-OLS数据和可持续生计的中国农村多维贫困空间识别
2018-10-18 02:09潘竟虎赵宏宇董磊磊
生态学报 2018年17期
潘竟虎,赵宏宇,董磊磊
1 西北师范大学地理与环境科学学院,兰州 730070 2 中国科学院西北生态环境资源研究院,兰州 730000
贫困是一种贯穿整个人类发展历史进程的客观现象,也是现今世界各国尤其是发展中国家所要面对的共性问题[1]。贫困一词在不同的发展时期从物质条件到精神层面被赋予了不同的含义,国际上的贫困测度研究经历了从收入/消费视角的经济维度贫困测度,到涵盖收入、健康、教育、资源禀赋、居住、环境、区位和就业等经济和社会维度的多维贫困测度,再到包含自然、人文、生态环境要素的地理空间贫困研究的历程[2-3]。随着统计数据的精细化,扶贫瞄准精度的提高,以及遥感和地理信息技术的快速发展,国际农村贫困地理的研究日渐兴起[4]。按照瞄准尺度的不同,贫困识别可分为家庭或个体识别(适用于贫困人口数量少且分布较分散的国家)以及地理识别(适用于贫困面大、分布区域性特征明显的国家)两类[4]。地理识别是以不同尺度的地理单元为单位开展的贫困识别,至2016年底,中国农村贫困人口减少到4335万,但分布明显集中于生态脆弱地区,这决定了将来较长一段时期内,扶贫项目的瞄准必须将到户、到人的精准瞄准与区域瞄准相结合[5]。仅仅依靠统计数据测度贫困,缺乏空间地域视角,无法直观揭示贫困发生的地域特征和空间地理的影响机制。在国家大力实施“精准扶贫”的背景下,从空间视角识别贫困区并进行类型划分,提出差别化的扶贫对策,具有重要的理论和现实意义。
从地理学视角研究贫困问题成为当前贫困研究的热点[6],研究尺度上,正由关注宏观层面贫困陷阱的形成机理转向多尺度相结合综合研究多重动态平衡;研究视角上,越来越重视地理和空间的作用;研究方法上,重视区域贫困的定量测度和空间贫困的时空演化;研究内容上,集中于空间贫困陷阱识别、多维地理因素以及区域瞄准及评估[4,7]。但与经济学、社会学者相比,地理学贫困研究仍缺乏系统性和重大理论创新[3]。贫困县是国家扶贫、减贫、开发政策执行的重要单元,其贫困状况和致贫因素的辨识及测度是“精准扶贫”能否成功实施的前提。从1986年国家第一次确定贫困县名单以来,关于贫困县划定标准的质疑和争论就从未间断过。划分标准过于主观,依据的社会经济统计数据过于宏观,在现有央-地财税体制关系背景下,国家级贫困县背后实质上代表着巨大的利益,一些非客观的人情世故等因素必然存在和影响着名单。目前,中国贫困区域在空间分布上与生态脆弱区高度耦合,贫困区域和贫困人口向中西部农村收缩,且这种态势持续加强;另一方面,囿于自然环境且高度依赖农牧业的生计状况,又会引致地缘性贫困与生态贫困。在这种背景下,如何综合、客观地评价贫困县的多维度贫困状况,成为需要急迫解决的科学问题。此外,减贫效果的评价、多维贫困县的调整和退出机制建立,也需要借助多源空间数据,建立多维测度模型,以相对统一的标准客观地评价分析。
遥感数据尤其是夜间灯光影像因其宏观、动态、客观性等优势,为监测和评价区域贫困,尤其是数据缺乏地区的贫困状况,提供了一种客观高效的方法[8]。Elvidge[9]利用DMSP-OLS夜间灯光影像和人口统计数据绘制了全球贫困地图。Wang等[10]通过夜间灯光影像测算了中国省域贫困状况。潘竟虎等[11]利用NPP-VIIRS夜间灯光影像对中国多维贫困进行了空间识别。Jean等[12]将机器学习与夜间灯光影像相结合,预测了非洲统计数据缺乏国家的贫困状况。这些应用案例都说明夜间灯光影像可以很好地用于贫困状况测度。本文利用DMSP-OLS夜间灯光遥感影像和多源空间、社会经济数据,构建贫困测度模型,分析2002和2013年中国县域多维贫困的空间分布,识别多维贫困县,以期丰富区域空间贫困研究的技术方法,为精准识别贫困提供科学参考。
1 样本区、检验区与数据来源
1.1 样本区与检验区

图1 检验区(青海省)和样本区(宁夏回族自治区)位置示意图Fig.1 Location of testing area (Qinghai Province) and sample area (Ningxia Hui Autonomous Region)
本文以宁夏回族自治区作为研究的样本区,以青海省作为检验区(图1)。宁夏总面积约6.64万km2,受气候条件及地理环境的影响,干旱区占总面积的76%。黄土丘陵沟壑区是典型的贫困集中区,全区8个国家级贫困县中的7个都集中在黄土丘陵沟壑区。宁夏内部各县市的经济社会发展程度差异显著,北部的银川和石嘴山发展水平高,中部的吴忠和中卫次之,而南部的固原发展较为滞后。2015年,北、中、南人均GDP之比约为100∶43∶26,总体上区域发展极不均衡,作为样本区的代表性很强。青海省总面积72.1万km2,境内山脉高耸,地形多样,河流纵横。青海经济发展水平差异也较大,2015年海西州的人均GDP约为玉树州的5.7倍。海西州的农民人均纯收入10582元,接近全国平均水平,但仍有国家级贫困15个,这也说明了依靠单一的经济指标去识别贫困的局限性。
1.2 数据来源及预处理
美国国防气象卫星(Defense Meteorological Satellite Program,DMSP)上搭载了OLS(Operational Linescan System)业务型线性扫描传感器,最初设计是为了监测天气,由于该传感器具备特殊的光电放大能力,可以在夜间侦测到地表的微弱近红外辐射,捕捉到城市的夜间灯光和火光,即使车流发出的低强度灯光也可以探测到[13]。本文所用的2002年和2013年稳定灯光值的DMSP-OLS夜光数据获取自网址http://ngdc.noaa.gov/eog/dmsp/downloadV4composites.html,已经剔除了噪声污染所致的灰度值小于0的像元。为了研究多维贫困指数与灯光值之间的关系,本文提出了基于有效灯光值的平均灯光指数ANLI(Average Nighttime Light Index)和基于区域面积的平均灯光指数ARNLI(Average Regional Nighttime Light Index),但由于DMSP-OLS数据只有64个灰度级,在光照强度较强的区域会出现饱和现象,沿海地区的饱和现象最为显著。考虑到植被与城市建成区具有负相关性,城市建成区人类活动强烈,植被覆盖度低;农村广大地区建设用地分布少,植被覆盖多,本文引入MODIS NDVI和EVI数据,分别采用Zhang等[14]提出的基于NDVI 去除灯光饱和的VANUI指数,潘竟虎等[15]提出的NVI降饱和指数和卓莉等[16]提出的基于EVI的缓解饱和的EANTLI指数,经过比较,EANTLI指数可以削弱土壤背景和大气对植被指数的影响,且降低了NDVI易饱和的缺陷,对于城市化推进较快的地区,可以突出灯光差异,故本文采用EANTLI指数去除夜间灯光数据的饱和现象,有效地识别贫困区域。此外,由于多传感器获取的长时间序列DMSP-OLS 夜间灯光影像数据不同年度间缺乏连续性,本文采用不变目标区域法[17]进行校正,降低了DMSP-OLS 夜间灯光影像间的不稳定和不连续现象。
社会经济统计数据取自2003年和2014的《中国县域经济统计年鉴》,部分指标获取自相同年份的《宁夏统计年鉴》和《青海统计年鉴》。DEM从国际科学数据服务平台(http://www.cnic.cn/zcfw/sjfw/gjkxsjjx/)下载,为90 m的栅格数据。在ArcGIS软件中计算得到各县域的地形破碎度、平均高程、平均坡度和合成地形指数。NPP和EVI数据获取自网站https://ladsweb.nascom.nasa.gov,用于计算全局植被湿度指数GVMI(Global Vegetation Moisture Index)的MOD09A1产品亦从该网站下载,分辨率均为1 km。其中,NPP为MOD17A3年合成产品,EVI为MOD13A3 数据产品,采用最大值合成(MVC)。行政区划数据取自国家基础地理信息中心(http://www.ngcc.cn/),考虑到研究对象为农村贫困,为方便起见,将每个地级市的所有市辖区合并为一个统计。年降水量数据取自中国气象数据网(http://data.cma.cn/)。
2 研究方法
2.1 可持续生计指标体系
贫困地理识别的主要依据是空间贫困 理论,其观点是将收入、健康、消费、教育、资源禀赋、区位等多维度指标赋予地理属性,集成为地理资本,分析地理资本在空间上的集聚性(即空间禀赋),从而探讨空间贫困陷阱的存在与否[18]。由此可见,空间贫困与地理资本这两个集合名词涵盖了经济、社会、生态环境等多维指标于一体。将上述地理资本要素及贫困劣势在地图上表现出来,即所谓“空间贫困地图”,可以深入研究贫困的空间分异机制,提出针对性的减贫消贫策略。本文采用可持续生计分析框架(SLA)的思想构建多维贫困评价指标体系。SLA由英国国际发展机构(DFID)于2000年建立,SLA从贫困产生的多种原因出发,力图提供多种解决方案,是一种多维视角下的分析框架[19]。DFID的SLA将生计资本确定为5种资本,即金融、生态、人力、物质和社会资本,构建“生计五边形”,用于刻画不同资本的数量和结构组合。考虑到本文评价对象为多维贫困,而生态环境/背景脆弱性与生计资本之间直接或间接地存在着加强或削弱联系,因此,在SLA的多维框架下,本文引入了脆弱背景和环境指标,力图刻画各类生计资本间的平衡状况[19]。参考前人[1,6-7]相关研究,在空间贫困理论和SLA理论指导下,遵循数据的可获得性、动态性、指标的相关性、典型性、指标间的区分度等原则,考虑自然、生态、环境等非社会性因素对反贫困的作用,兼顾目前国家层面全面脱贫战略的核心监测指标,并考虑贫困与区位、环境、资源禀赋、经济、社会等要素间的动态影响、相互作用,提出了县域可持续生计空间测度的多维度指标体系候选集。
采用R聚类-变异系数方法筛选候选集中的指标,最终构建了由 6个目标层和30个指标层构成的县级可持续生计度量指标体系(表1)。在此基础上,对筛选后的指标进行无量纲处理,利用熵权法修正AHP的方法确定各指标的权重,这样既可以弥补主观赋权法主观性较强的弱点,尽可能地保证了权重的客观性,同时又兼顾了使用者对指标的偏好。根据已经建立的多维指标体系及修正后的指标权重,计算生计指数。各指标的统计数据单位不相同,数据偏差大,直接对其统计没有统计学意义。需对每个指标数据无纲量化处理,减小各指标之间的相关性影响程度。某些县区的单一指标会受统计误差的影响而远离标准值,例如,石嘴山市的能源消耗量的统计数据包含能源公司的能耗数据,这些超出标准值的统计数据会影响SLI计算的准确度。先对其进行修正得到指标统计矩阵,再对矩阵标准化处理,将每个指标的值都转化为一个无纲量值。
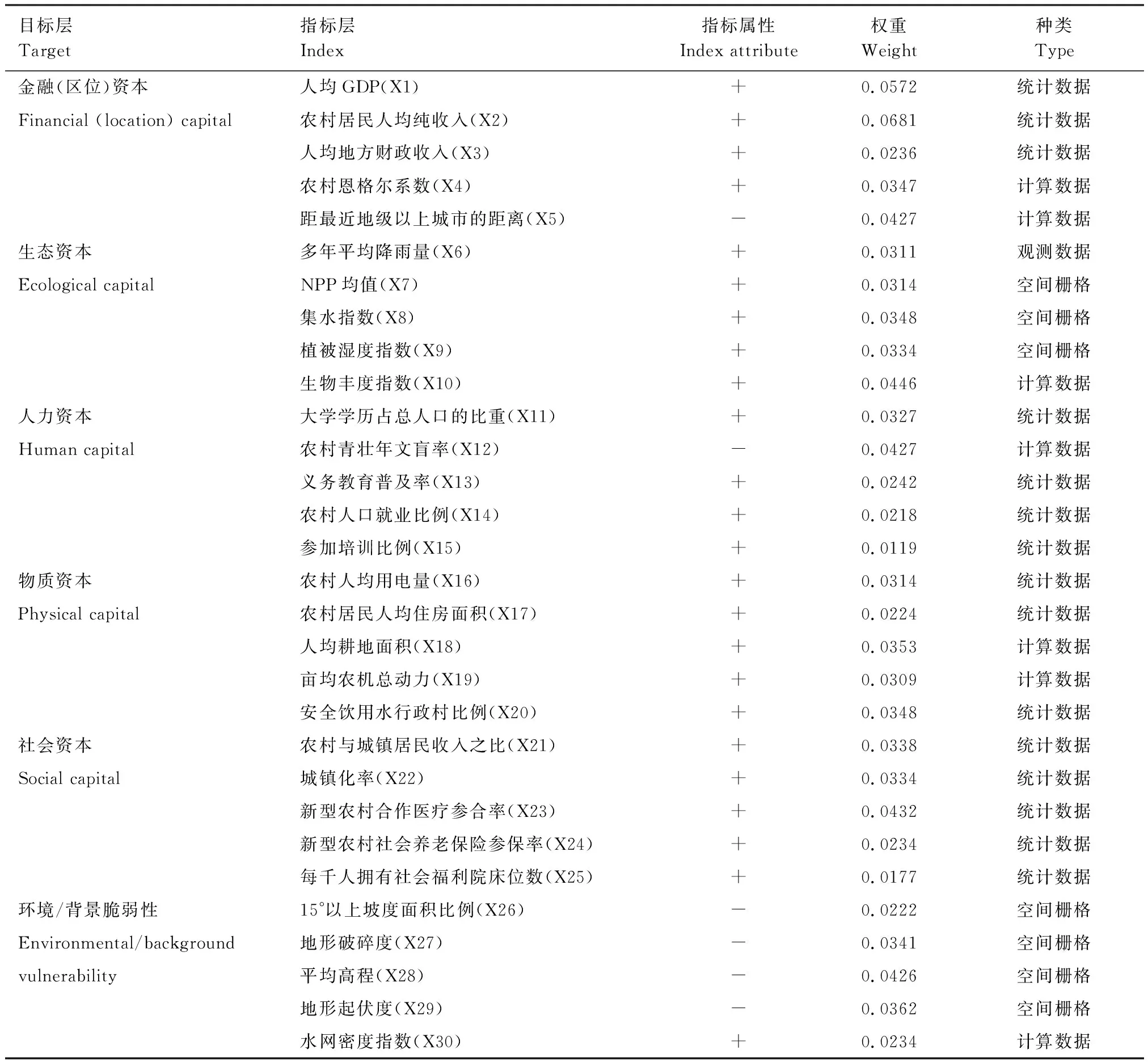
表1 县域可持续生计指标体系及其权重分配
注:表中的“+”号代表正向指标,越大越好;“-”号代表负向指标,越小越好
表1中,集水指数用于表征某个地区水资源的可获得性,计算式为[20]:
AW=CTI×AP/10000
(1)
式中,AW为集水指数,AP为年降水量。如果某地区地形平坦、集水面积大并且降水充沛,其集水指数就大。反之,若地形坡度大或集水面积较小,且降水又稀缺,则其AW就小。合成地形指数CTI(Compound Topographic Index,CTI)是上游汇流面积(FA)和景观坡度(slope)的函数,计算式为[21]:
CTI=ln(FA/tan(slpoe))
(2)
GVMI可以综合反映植被和土壤湿度信息,表征区域生态环境的好坏。计算式为[22]:
(3)
式中,NIR和SWIR分别为MODIS数据产品MOD09A1的近红外波段(波段2)和短红外波段(波段6)。MOD09A1数据产品空间分辨率为500 m,时间分辨率为8天合成。将500 m空间分辨率重采样为1 km,根据公式(3)得到相应8天的GVMI,再采用最大值合成法(MVC)得到月的GVMI,最后求得年平均值。
可持续生计指数的计算式为:
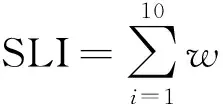
(4)
式中,SLI为可持续生计指数,xi为标准化后的第i个指标值,wi为第i个指标的权重。
生物丰度指数和水网密度指数根据国家发布的《生态环境状况评价技术规范(试行)HJ 192—2015》计算获得。
2.2 多维贫困测度
2.2.1 夜间灯光与生计指数的关系
以西部的宁夏回族自治区为样本区建立测度模型,其所辖全部县区用于整体建模。研究表明[8- 14,23- 24],夜间灯光的强度与区域经济发展存在显著的正相关关系,基于此原理,用区域灯光强度与生计指数拟合得出可持续生计评估模型。本文综合其他文献[8- 14]所使用的灯光指数,结合研究样区的特点,分别采用基于区域面积的平均灯光指数ARNLI(Average Regional Nighttime Light Index)和基于像元数的平均灯光指数ANLI(Average Nighttime Light Index)。计算式为
(5)
(6)
根据上述公式分别计算研究样本各县域的ARNLI指数和ANLI指数,对其进行分类评级。结果发现,灯光强度与县区经济的发展拟合度极好,在研究样本中有11个县,其中9个县区是国家级贫困县,其灯光强度显著低于非贫困县。图2为两个指标2013年的对比情况;图3为2002年的对比情况。

图2 宁夏2013年ANLI和ARNLI分级Fig.2 ANLI and ARNLI grading map of Ningxia in 2013ARNLI: 基于区域面积的平均灯光指数Average Regional Nighttime Light Index;ANLI: 基于像元数的平均灯光指数Average Nighttime Light Index

图3 宁夏2002年ANLI和ARNLI分级Fig.3 ANLI and ARNLI grading map of Ningxia in 2002
依据公式(3)计算出宁夏各县区的可持续生计指数SLI,绘制SLI分区图(图4),可以看出,SLI较高的县区大都分布在北部黄河灌溉平原区内,SLI较低的县区则集中在中部干旱台地黄土丘陵区和南部半干旱黄土丘陵、六盘山地区。为了判断SLI是否能反映贫困状况,将各县区的SLI排序,发现排在后10名的县区全都进入了新《纲要》中划定的集中连片特困区范围,这也从侧面验证了SLI可以用于测度多维贫困。
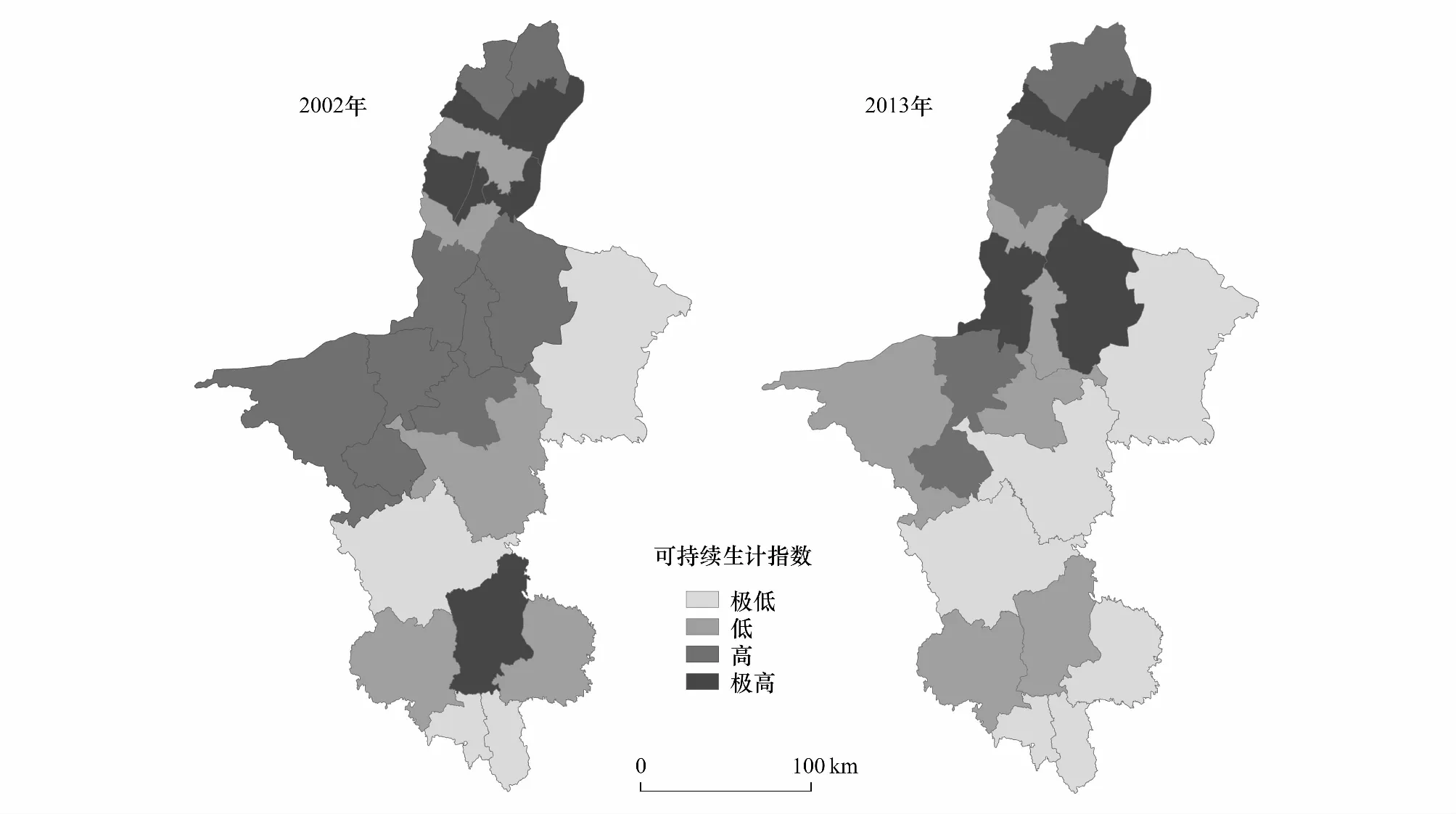
图4 宁夏的可持续生计指数分级Fig.4 SLI grading map of NingxiaSLI: Sustainable livelihoods index
各指标统计数据的年差异和权重对SLI指数的计算影响较大,若仅依靠一个模型模拟区域社会经济的发展是有局限性的。因此,本文分别采用线性、非线性、指数及对数等多种模型,将宁夏各县区的SLI与ANLI和ARNLI进行拟合,以便确定最佳的模型。结果发现指数和线性拟合程度较好,其中,指数的拟合效果最好,并且随着时间序列的演进拟合效果越好。图5是2013年SLI指数分别与ANLI指数、ARNLI指数的指数回归方程和线性回归方程,图6是2002年SLI指数分别与ANLI指数、ARNLI指数的指数回归方程和线性回归方程。经综合对比两个年份的回归结果,SLI指数与ANLI指数的拟合优度高于ARNLI指数,指数方程的拟合优度高于线性方程的拟合优度。利用T检验和F检验来检验回归方程的可信度。t检验和F检验对于一元线性模型是等价的,但对于指数模型解释变量的整体对于被解释变量的影响是显著的。ANLI与SLI的线性模型的显著性检测值为F=457.64,t=4.38,ARNLI与SLI的线性模型的显著性检测值为F=367.28,t=3.98,ANLI与SLI的指数模型的显著性检测值为F=657.64,t=6.43,ARNLI与SLI的指数模型的显著性检测值为F=467.28,t=5.28,F理论值为234,F实际值高于理论值,存在显著的正相关关系,t检测值也在置信区间内。综合分析判断,本文最终利用指数模型来建立SLI指数与ANLI指数之间的回归关系。

图5 2002年SLI与ARNLI和ANLI之间的回归结果Fig.5 Regression results between SLI and ARNLI, and ANLI in 2002
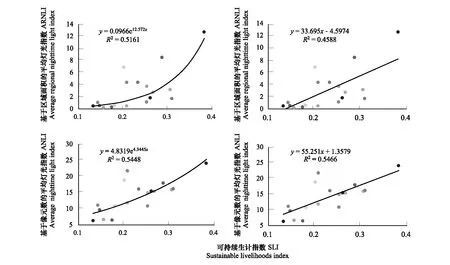
图6 2013年SLI与ARNLI和ANLI之间的回归结果Fig.6 Regression results between SLI and ARNLI, and ANLI in 2013
2.2.2 模型验证
构建的模型必须通过验证才能用于整体数据的统计估算。利用指数模型计算青海省各县区的理论SLI指数,用基于统计数据的SLI指数进行误差检验,采用平均相对误差来反映模拟的精度,计算式为
(7)
式中,ARE为相对误差,SLIe为根据指数模型估算的SLI指数,SLIa为根据统计数据计算的SLI指数,n为样本县区个数。

3 多维贫困的时空分布
3.1 县域可持续生计空间异质性格局
尽管贫困空间分布的栅格图可以直观、客观、宏观地表达地理位置上贫困的分布差异,然而,在具体的扶贫、减贫政策落实、执行时,不可能在栅格尺度上完成,而是需要将资金、优惠条件等分配到具体的行政单元上。在中国,县级行政区是组织与管理国民经济和社会发展最基本的单位,是城乡二元结构等区域差异问题、“三农”问题等的集中发生地,也是扶贫政策落实的基本单元,具有承上启下的关键作用。因此,本文求取各县域内栅格的平均SLI,并绘制可持续生计图(图7)。

图7 县域可持续生计指数的空间分布Fig.7 Sustainable livelihoods index of counties in China
2002年,全国2391个县区SLI的平均值为0.358,标准差为0.385;2013年全国各县区SLI的平均值为0.457,标准差为0.608。这说明11年间可持续生计水平提高了27.9%,而县域间的个体差异则有所扩大。按照可持续生计指数SLI的大小,采用自然断点分类,将中国全部县域划分为6个级别:极富裕、富裕、较赋予、较贫困、贫困和极贫困(图8)。结果发现,2002年和2013年,富裕区大都集中分布在珠三角、长三角、海峡西岸、环渤海、台湾省等地区,散布在成渝、关中、宁夏沿黄、呼包鄂榆、天山北坡、中原、哈大长、武汉、长株潭、滇中等城市群。极贫困区则主要集中在西藏、甘青川滇四省藏区、陕甘宁晋黄土高原地区、滇黔桂石漠化地区、云南沿边山区等。2013年与2002年相比,极富裕和富裕区的范围有所扩大,贫困和极贫困区的范围则大幅缩小。

图8 多维贫困分级Fig.8 Classification of multi-dimensional poverty in China
3.2 县域可持续生计空间依赖性格局
首先进行县域可持续生计的全局空间依赖性检验。依据各县区SLI 得分,利用Rook标准计算全局空间自相关测度的Moran′sI指数,采用999次随机计算以提高其运算的稳健性。中国县区在2002年的全局Moran′sI指数为0.636,P检验值0.0000,Z检验值125.0792,在1%的显著水平上拒绝原假设;在2013年的全局Moran′sI指数为0.579,P检验值0.0000,Z检验值108.5632,在1%的显著水平上拒绝原假设,说明中国县域可持续生计存在较强的空间依赖性,换言之,高SLI的县区往往相邻聚集,反之亦然,但11年间这种空间自相关特征在下降。
其次,进行县域可持续生计的局部空间依赖性检验,同样采用999次随机计算以提高其运算的稳健性。根据各县区SLI与相邻县区SLI的关系,可得到4种类型(图9):高-高(HH)、低-低(LL)、低-高(LH)和高-低(HL)。2002年(图9),HH、LL、LH 和HL显著的县区数目分别为446、638、134、11,LL型最多,约占全部县区的26.7%,反映出可持续生计差的贫困俱乐部成员的数量众多;空间上几乎全部分布在百色-扎兰屯一线以西的地区,较之著名的“胡焕庸线”(黑河-腾冲线)向东偏移约700 km。HH型的县区占总数的18.6%,分布较为规律,多分布在沿海地区,少数为中、东部地区的省会等大城市辖区。LH型的县区在HH型县区的外围分布,多为东南沿海省份内部发展相对落后的地区,以及省际边缘区,如湘粤赣、闽赣、湘粤、皖赣、鄂鲁豫交界等。HL型仅11个,全部是特大城市(重庆、成都、西安、郑州、石家庄等)周边的县区。区域经济均衡发展是相对的,而不平衡发展则是绝对的。在某些时段、某些地区中存在着越邻近中心城市边缘,其发展越受制约、越是落后的状况,当中心城市处于扩散时期时,这些邻近地区也未必“近水楼台先得月”,虽然这些县区与大都市区尽在咫尺,却没有受到大城市光环的照耀,成为了“大都市阴影区”。而从2013年来看(图9),HH、LL、LH 和HL显著的县区数目分别为239、154、65、15,除HL型县区略有增加外,其余3种类型县区的数量均大幅减少。LL型县区的数量减少最多,说明11年间减贫成效显著,除了面积大大减少外,在空间分布上,LL型县区由2002年的集中连片分布转变为离散化分布,较大的连片区主要位于西藏东部、四川西部、云贵高原、六盘山区、秦巴山区、武陵山区等。HH型的县区分布依然,更加集中在华东和华南沿海地区。LH型和HL型的分布规律与2002年相比变化不大。
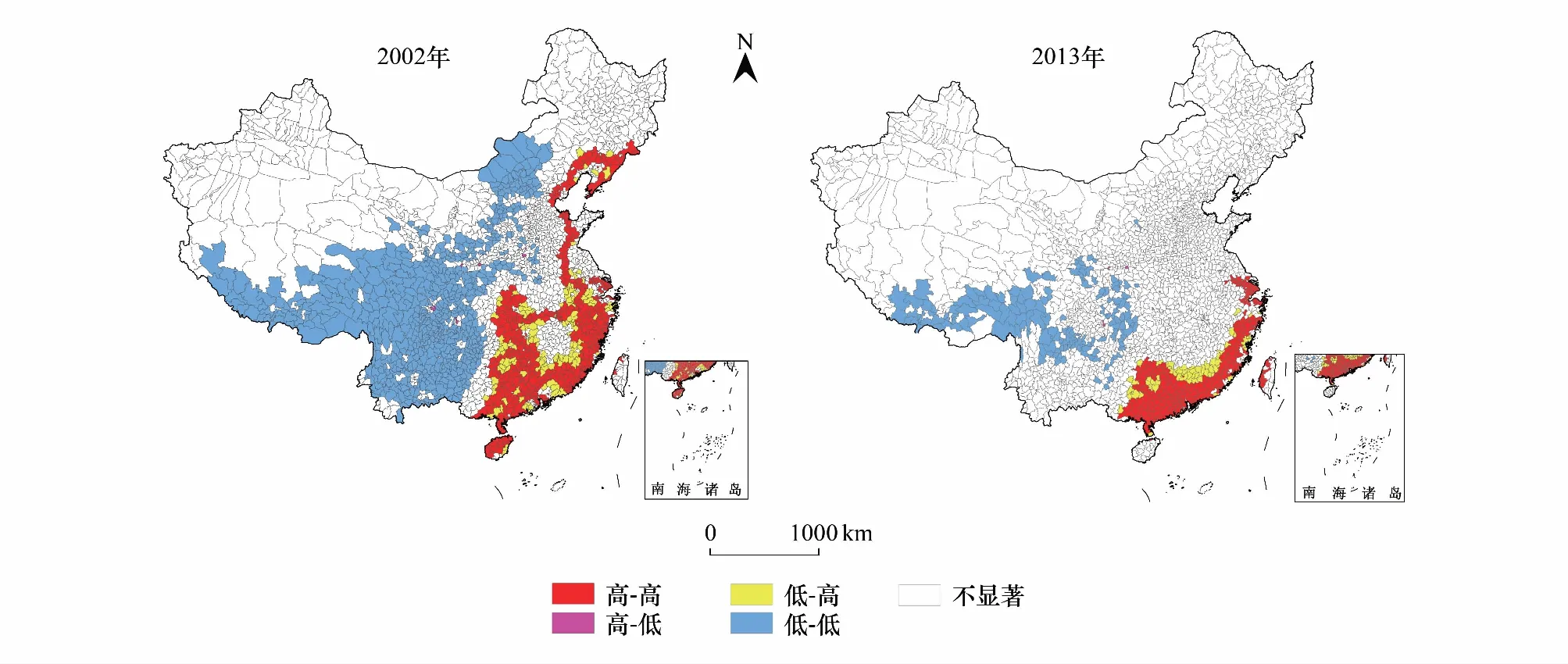
图9 2012年中国可持续生计的局部空间自相关的LISA图Fig.9 The LISA diagram of sustainable livelihoods index in China
3.3 多维贫困县的空间分布
3.3.1 总体分布特征
本文把依据可持续生计指数划分的极贫困和贫困区所属县区确定为中国的多维贫困县区(图10),2002年识别出的中国多维贫困县共642个,其中属于国务院扶贫开发领导小组办公室确定的国家级贫困县424个。2013年识别出的中国多维贫困县共612个,其中国家级贫困县421个。由图10可知,2002—2013年间,我国多维贫困县的集中分布态势并未发生显著的转变,多维贫困发生率较高的县区依然连片分布在中西部地区。具体来看,2002年,多维贫困县集中分布在青藏高原大部、云贵高原大部、川西、滇西山区、祁连山区、六盘山区、秦巴山区、武陵山区、内蒙古中部、南疆等地。2013年,多维贫困分布更为分散,贫困减少较明显的地区包括南疆、内蒙古中部、桂黔滇毗邻地区,在武陵山区、湘赣粤交界地带、东北、陕甘宁六盘山区等地,多维贫困有所推进。2013年,中国农村多维贫困县区总体上表现为东、中、西部岛状-块状-连片状3种地域类型:(1)东部平原、丘陵及革命老区孤岛型多维贫困区,包括大小兴安岭南麓、中朝中蒙交界区、辽西;淮河中上游地区、闽赣交界、罗霄山区、琼中等岛状分布的丘陵山区;(2)中部山地、丘陵、高原环境脆弱块状多维贫困区,空间上恰好表现为沿胡焕庸线两侧分布的态势,从东北地区经过燕山-太行山区、吕梁山区、大别山区、武陵山区、乌蒙山区、湘粤赣,延伸至滇桂黔石漠化区和滇西山区;(3)西部高寒、荒漠环境恶劣片状多维贫困区,包括蒙新寒旱区、青藏高原山地区、川西-甘南高寒区、黄土高原丘陵沟壑区等。

图10 中国多维贫困县空间分布Fig.10 Distribution of multi-dimensional poverty counties in China
3.3.2 空间变化
以2002年和2013年识别出的多维贫困县为研究对象,进行多维贫困区空间分布格局的演变分析。将两个年份上多维贫困县分为稳定型、调入型和调出型三类:稳定型,在两个年份上多维贫困识别中均位于SLI指数评估的贫困或极贫困县域;调入型,2013年评估中新加入贫困或极贫困县的“戴帽县”;调出型,2013年评估中SLI指数增加快,总体达到脱贫、不再进入SLI贫困、极贫困名单的“摘帽县”。统计结果显示,稳定型多维贫困县的数量为438个,占2013年全部贫困县的71.6%,调入型和调出型多维贫困县的数量分别为168个和134个,调入型贫困县占多维贫困县总数的27.4%。可以看出,中国多维贫困区11年间集中分布的态势并未发生明显改变。调出型多维贫困县最明显的地区是内蒙古中部、云南-贵州交界、湖南、湖北、山东等省份,内蒙古通辽、赤峰、鄂尔多斯、乌兰察布、陕北榆林、延安等资源富集地区的多维贫困县,依托煤电、石油、天然气、矿产品等的开发利用,旅游及特色农副产品加工等产业的带动,实现了县域的脱贫。值得注意的是,在东北地区、中部省域交界地带、海南等地出现了新的多维贫困县,这些地区应当是未来减贫消贫重点关注的地区。
4 讨论
中国农村贫困化在新时期表现为空间孤岛、投资递减、收入扁平、发展马太等多效应的叠加,多维度地科学评估,因地制宜地精准施策,自然变成新时期扶贫开发工作创新的关键问题和难题[28]。家庭真实属性特征对于中国扶贫政策的制定者来说,经常是无法准确观测到的,这在一定程度上限制了精准扶贫政策执行的有效性。就地理学视角而言,不同空间尺度之间存在相互嵌套、关联和影响的关系。微观尺度上的个人/家庭贫困必然受到中观和宏观尺度上的政策效应影响。今后很长的一段时期,中国对贫困地区进行地理识别和认定以安排和实施各种扶贫项目,仍然是必要的[29]。作为中国农村扶贫主要瞄准对象的贫困县,其贫困水平识别和判定是提高区域扶贫工作“瞄准度”的前提,也是现今贫困县全部“摘帽”和实现全面小康的先决条件。然而,尽管中央和各省区公布的新一轮贫困县退出或扶贫开发监测实施方案均提出面向“精准识别、全面脱贫”的思想,并着重考虑了社会经济发展和生态环境改善等多方面,但已有方案更多地仍停留在定性表述上[30]。本文引入可持续生计分析思想,构建了中国多维度贫困测度指标体系,采用DMSP-OLS夜间灯光影像,以宁夏和青海分别作为样本区和检验区,建立估算多维贫困的模型,开展了基于栅格和县域尺度的多维贫困空间识别。
由于本文利用夜间灯光影像和可持续生计指数进行多维贫困测度尚属探索性工作,缺陷和不足在所难免。首先,宁夏和青海分别作为样本区和检验区,尽管具有代表性,仍需要增加更多样本,特别是检验其在中、东部地区的适用性。其次,受现有夜间灯光数据空间分辨率的限制,尚不能实现更小尺度上的多维贫困精细判别。第三,受数据可获取性限制,可持续生计的测度指标体系可能遗漏一些重要指标,如外出打工者、公共服务水平等。尽管指标经过了筛选,但指标间的相关性仍不可避免地存在,如城镇化率本身就是一个复合指标,夜间灯光指数通常也用于测度城镇化水平,而城镇化水平本身与经济社会发展也具有很强的相关性,下一步工作可考虑采用主成分分析等指标去相关性的评价方法。最后,由于空间尺度效应和地区、城乡间的差异,本文得出的结论不一定适用于更大的国家尺度和更小的乡镇、村、家庭等尺度。此外,本文仅选择两个年份的截面数据开展多维贫困的识别,没有进行基于面板数据的扶贫减贫绩效监测。考虑到新一代夜间灯光影像NPP-VIIRS具有更高的空间分辨率,且提供辐射定标数据,不存在像元值的饱和溢出现象,今后的工作可尝试基于多源时空数据的多维贫困精准监测模型设计,或扶贫资源优化配置系统开发,以迎合贫困精准识别-精准帮扶-精准考核的国家减贫战略部署。
空间异质性是中国农村贫困的重要属性,所以扶贫减贫政策相应地也须因地制宜。各县区资源、人力、物质、生态等可持续生计资本和社会保障服务差异致使贫困空间分布格局发生变异。另外,各县区在社会经济发展中面临的致贫风险冲击暴露程度不同,也会产生环境/背景脆弱性差异。基于此,对多维贫困县,将来的扶贫、减贫理应遵循从区域到家庭再到个人、从宏观到中观再到微观的逐步协同、逐步精准的过程。将基于区域(region-based)的战略与基于个人(people-based)的政策相结合,方能实现扶贫、减贫的规划目标。可持续生计低-低的区县聚为“多维贫困俱乐部”,其周边县区可持续生计状况也低,提高生产生活水平面临诸多障碍,此类县区扶贫的重点是以制度建设为主,发展生产为辅。扶贫具体策略应坚决贯彻“绿水青山就是金山银山”的发展理念,采取就业扶持、易地搬迁、发展教育、生态补偿、社保兜底的“五位一体”方式,大力发展旅游业等生态绿色产业,实现整体脱贫。虽然经济发展是多维贫困县的主要致贫因素,然而随着经济的持续发展,经济的减贫效果会逐渐降低,而生态因素、环境背景脆弱性、社会发展的作用必然逐渐增强。因此,多维贫困县在后期的精准脱贫工作中,应充分考虑可持续生计发展的各项约束条件,有针对性地采取措施,补齐发展的短板,创造可持续生计发展的良性循环。
猜你喜欢
汉语世界(2022年4期)2022-08-08
今日农业(2020年23期)2020-12-15
今日农业(2020年22期)2020-12-14
今日农业(2019年10期)2019-01-04
中国报道(2018年11期)2018-12-22
人大建设(2017年10期)2018-01-23
重庆文理学院学报(社会科学版)(2017年5期)2017-10-23
人大建设(2017年5期)2017-04-18
林业与生态(2016年2期)2016-02-27
华南农业大学学报(社会科学版)(2015年2期)2016-01-11
