
基于遗传算法的聚类分析及其应用
2018-10-17 08:58:02
福建质量管理 2018年18期
(成都理工大学 四川 成都 610059)
一、前言
(一)研究目的和意义。数据挖掘技术的目的就是为了从错综复杂的大数据中挖掘出有用的知识和数据,进而应用到科学决策中(赵艳丽,2009)。聚类分析(Clustering Method)是一类无监督分类方法,是数据挖掘中极其关键的一个数据处理方式,使同一类内里对象之间的相似程度最小,不同类内对象之间的相似程度最大的目标(李荟娆,2014)。在地球化学数据的分析研究中,首要的是要研究地球化学元素的分布特征,再依据数据分类的方法找寻元素空间分布规律。
(二)国内外研究现状。k-means算法最早是由J.B.MacQueen于1967年提出来的,由于该算法不仅聚类时间快,而且聚类过程简单,效率高,随后该算法广泛的开始传播。但k-means算法也存在以下缺点:(1)聚类数据的要求很高;(2)初始聚类中心的选取不合适会导致聚类结果的不稳定;(3)需要人为的去确定分类数k;许多专家对上述问题进行了深入研究,已找出一些新的方法可以弥补k-means算法的缺陷。重点是通过以下两个方面来改进k-means算法。(1)传统k-means算法的k值被替换为人为确定的k值;(2)初始聚类中心选择的优化排除了聚类初始点对聚类结果的影响。
遗传算法最早由美国J.Holland教授在1975年提出的(刘建庄,1995)。其最显著的特点是能够直接对结构对象进行操作,并且没有函数连续性的定义,它具有隐式并行性和全局寻优能力。它应用在许多问题上表现出简单,通用,强大,适合并行处理等优点,是当前智能计算的核心技术之一。
近年来,k-means聚类分析和遗传算法的发展十分迅猛,并且基于k-means聚类算法和遗传算法已经扩展成一系列不同的算法,已被广泛的应用于生活。
(三)本文的主要研究内容。k-means算法的最主要的两个缺点是需要我们自己来确定分类数k以及初始聚类中心,因此在随机选取聚类中心点上会很大程度上让聚类结果接近于局部最优值。遗传算法最主要的特点是隐式并行性和有效利用全局信息,因此基于遗传算法的聚类分析具有很强的鲁棒性,很大程度上不会陷入局部最优,进而显著的提升算法的聚类效果。本文实验使用标准数据集来验证算法的有限性,通过与传统算法的结果进行比较分析,证实算法是可行的。我们从发现问题,提出问题,分析问题和解决问题四个角度出发,通过对其自身改进算法的研究,深入研究了该算法的优劣性,提出了一种基于遗传算法的k-means聚类算法。
二、实验结果与分析
(一)数据分析。地球化学数据处理指的是通过某些方法或软件对地球化学中的部分元素数据进行分析研究,绘制成图,得出结论的过程(管世明,2012)。本文就以地球化学元素作为聚类分析的数据对象,对地球化学采样数据进行了分析,这里选择了一组铜的数据,首先先对这组数据进行分析,如表1所示,发现个体差异值很大,最大值和最小值差异明显,如图1所示,最大值跟均值差异也很明显,所以很有可能对聚类产生影响,有可能产生异常值点。将数据代入遗传k-means聚类算法程序中进行分析,发现k值为4的时候聚类效果最好。

表1 元素特征
(二)结果分析。
利用surfer专业成图软件对聚类结果进行分析产生聚类图。把数据聚类结果做成分类图,不同的类别点用不同的颜色表示,从聚类结果图上可以明显的看出存在分布特征特别明显的几个区域,特征表现在:(1)图中区域内同一颜色的点属于同一个类;(2)图中种群拥有相当大的规模,有很大一部分的采样点,而其他位置上也有其他类的分布。利用聚类分析的优势,依据地球化学元素作为聚类分析问题的研究对象,能够直观的展示元素的空间分布规律,指示找矿有利地段。
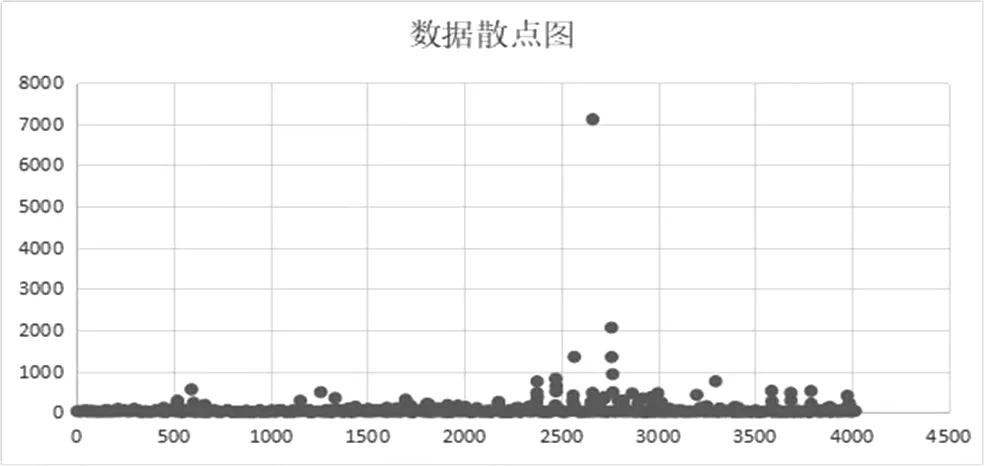
图1 原始数据散点图

图2 聚类分析图
结论
k-means聚类算法简单易行,聚类速度快,但是随机的初始化容易陷入局部最优解。遗传算法简单通用,鲁棒性高,适合并行处理,但是计算效率过低,同时对局部寻优的过程不佳。本文结合两种算法的优缺点,改进了遗传k-means算法。通过仿真实验和实际数据的处理验证了算法的有效性。
聚类分析的研究由来已久,本文只是截取庞大体系中的很小一部分开展研究,虽有成果,但仍有需要改进之处,如算法的效率方面仍可提高,结合神经网络或模糊聚类可能取得更好的效果,这些都是值得进一步研究的方向。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
电子测试(2017年15期)2017-12-18 07:19:27
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
统计与决策(2017年2期)2017-03-20 15:25:24
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
