
流计算与传感网集成的城市内涝模型实时感知研究
2018-10-16 08:21上官博屹
地理信息世界 2018年3期
上官博屹,乐 鹏
(武汉大学 遥感信息工程学院,湖北 武汉 430079)
0 引 言
地理模型实时感知是指在地理模型中通过接入实时或者近实时观测数据,实现对现实世界的实时动态过程模拟.城市内涝灾害实时感知对于智慧城市、应急响应等有着重要的意义.通过融合传感网技术、流计算技术、以及城市内涝计算模型,有助于城市内涝模型实时感知,为政府部门提供及时的信息决策支持.
传感网(Sensor Web)技术将具有感知、计算以及通信能力的传感器或是它们组成的传感器网络(Sensor Network)与Web技术结合,向外提供一系列标准访问接口实现了传感器资源的共享与互操作.传感网的概念最早由NASA的喷气推进实验室在1999年提出,用以定义一种特殊的无限传感器网络架构[1].2006年,开放地理信息联盟(Open Geospatial Consortium, OGC)针对传感网缺失统一标准的推广应用障碍,将其与面向服务的体系架构(Service Oriented Architecture, SOA)相结合,通过制定一系列的传感网服务规范和信息模型,推出了传感网实现架构(Sensor Web Enablement,SWE),为其资源共享和互操作提供了技术支撑[2-3].传感网技术的发展使传统的地理数据发现、获取和处理发生了巨大变革,为实现地理模型实时感知奠定了基础.流计算(Stream Computing)技术,即运用一定手段实时或近实时地对流式数据进行处理和分析,目前已经成为了一种新的计算机数据处理范式[4].2008年,IBM在推出其开发的高性能流数据处理平台"System S"时首次将流计算技术命名为"Stream Computing"而使其广为人知[5].但在这之前许多关于"Stream Processing"的研究已经在国内外展开,如MIT等三所大学在2003年开始合作研究并推出了Aurora系统,用于解决监测应用如环境监测系统、监视系统和跟踪系统中数据流的实时处理问题[6].近年来,随着流计算技术的发展,一系列开源的流计算系统被广泛推广和使用,如Yahoo于2010年开源了S4流计算系统[7],Twitter于2011年开源了Storm流计算系统[8],基于内存的分布式处理平台Apache Spark也于2013年推出了流计算模块Spark Streaming[9].同时在地理信息领域,研究人员则更加强调了运用流计算的方式对带有地理空间信息的数据流进行实时或近实时的处理和分析[10].由于传感器观测地理对象获得的数据天生可以视作流式的,将传感网与流计算系统进行耦合,将传感网观测数据流引入地理流计算模型中进行实时处理,可以有效地实现对现实地理事件的动态过程模拟和实时感知.而要实现针对城市内涝灾害的实时感知则需要建立有效的城市内涝灾害模型.现有的城市内涝灾害模型一般基于经验水文模型、数值模拟模型等.其中,经验水文模型发展较早,它基于人类对水文的多年观测经验,综合考虑了各种有关因素.美国水土保持局开发的水土保持局曲线数值模型(Soil Conservation Service-Curve Number, SCSCN)就是一个典型的经验水文模型,它虽然结构简单但是能充分考虑下垫面特征,只需降雨量和地表参数即可较精确地计算出降雨产流量[11].而数值模拟模型相比于经验水文模型能够更好地表现内涝的时空分布和动态变化.刘小生等基于GIS空间分析法和水力学数值模拟法提出了GIS"体积法"模型,该模型根据水从高处往低处流的物理特性及降雨滞留量和淹没水量体积相等的原理,利用数值高程模型(Digital Elevation Model,DEM)对洪涝淹没范围进行计算[12].结合SCS-CN模型和GIS"体积法"模型可以有效地在流计算环境下基于传感网降水量观测数据和城市地表数据对城市内涝灾害过程进行动态模拟.
本论文从实时数据计算与地理过程模型集成的角度出发,针对流计算模型、系统耦合架构等难点,提出了基于开放标准的传感网与流计算耦合架构、实时内涝信息流计算模型等方法,设计并实现了一种基于流计算的城市内涝位置感知原型系统.该系统以基于OGC SWE标准建立的传感网作为数据获取层、以OGC传感器观测服务(Sensor Observation Service, SOS)作为数据管理层、以Apache Kafka分布式消息发布/订阅系统和流数据发布程序作为数据转化层、以运行在Apache Spark分布式处理集群上的城市内涝流计算程序和相关数据库作为数据处理层,具有良好的互操作性、实时性和容错性.
同时,本论文通过实际搭建系统选择实验区域进行了相关实验和性能测试.该实验模拟实验区域遭遇约为1 mm/min的大暴雨,对可能产生的内涝灾害进行了近实时的模拟监测.实验证明了该系统具有优秀的可用性,同时性能测试表明该系统可以通过扩展集群资源不断提高计算性能,从而充分满足城市内涝灾害监测这一应用场景的处理需求.
1 传感网与流计算耦合架构
构建传感网与流计算耦合架构,使传感网实时观测数据流能够被流计算系统发现、获取和处理,是实现地理过程动态模拟的关键.如图1所示,本文以基于OGC SWE框架搭建的传感网、基于Spark Streaming搭建的流计算系统为例,提出了传感网与流计算耦合架构并应用于城市内涝模型实时感知,是本文提出的城市内涝模型实时感知原型系统的主要组成部分.
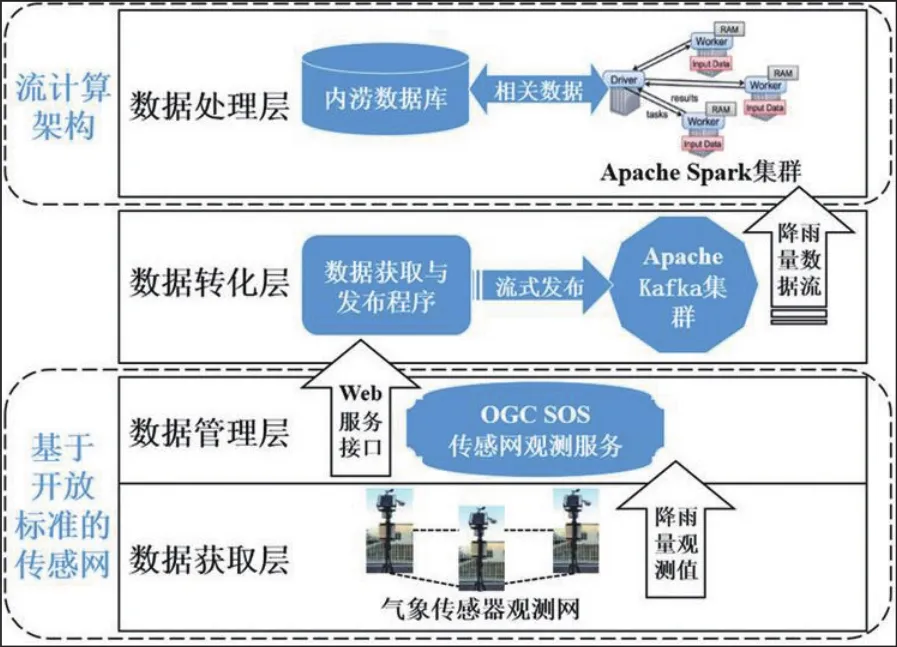
图1 传感网与流计算耦合架构Fig.1 Sensor Web and stream computing coupled architecture
该架构在逻辑上可以简单地分为四层:数据获取层、数据管理层、数据转化层以及数据处理层.其中,数据获取层和数据管理层组成基于开放标准的传感网架构,数据处理层为流计算架构.由于基于开放标准的传感网架构为确保数据的互操作性而通过Web服务以标准格式进行数据共享,这些数据一般为离散的XML格式文档,不能满足流计算系统对于流式数据的格式要求.因此,为解决传感网与流计算架构难以耦合的难点,本系统在两者之间加入了一个数据转化层,将从传感网中获取的数据转化成流式数据,从而可以传输到流计算系统中进行处理.
数据获取层负责降雨量数据的实时获取,由基于OGC SWE标准建立的气象传感网组成.传感网中的气象传感器通过网络进行连接并可利用Web技术进行远程管理.每个气象传感器对其负责的城市区域的降雨量进行实时观测,并通过数据管理层提供的接口对实时降雨量数据进行更新.
数据管理层负责以互操作的方式对气象传感器元数据和其观测的降雨量数据进行存储和管理.它使用数据存储系统来管理各个气象传感器的位置数据、属性数据和观测的每条降雨量数据,同时还基于OGC SOS标准搭建传感器观测服务,通过发布一系列Web服务来提供传感器数据和降雨量观测数据的更新和获取接口.
数据转化层负责从数据管理层获取降雨量实时观测数据并将其发布成适合流计算系统格式要求的流式数据进行传输.在这里,本架构基于分布式消息订阅/发布系统Apache Kafka[13]来进行实时降雨量观测数据的流式发布和传输,它允许用户发布和订阅流式数据并以高容错的方法保存每条流式数据.降雨量数据获取与发布程序通过调用数据管理层SOS提供的GetObservation接口不断获取当前所有传感器观测的最新降雨量数据,并通过Kafka集群不断地转化和发布为流式数据,最后传输给数据处理层中的流计算系统进行处理.
数据处理层负责对实时降雨量数据流进行接入,并基于城市内涝灾害模型进行近实时计算,从而及时获取内涝过程模拟结果.本系统使用Spark Streaming作为流计算引擎,通过搭建的Apache Spark高性能计算集群对实时观测数据流进行分布式处理和计算.基于Spark Streaming的城市内涝流计算程序以Kafka集群发布的实时观测数据流作为数据源,基于建立的实时内涝信息流计算模型,近实时地计算、分析出当前的城市内涝灾害情况.
将该架构运用到实际的城市内涝案例中,与实时内涝信息流计算模型组成城市内涝模型实时感知原型系统,其运行流程可以简单描述为:①数据获取层的气象传感网观测系统获取实时降雨量数据并将其不断通过SOS InsertObservation接口插入到数据管理层的数据存储系统中;②数据转化层的观测数据获取与发布程序不断通过SOS GetObservation接口获取实时降雨量数据并基于Apache Kafka集群发布成可被流计算系统接入的流式数据;③数据处理层的Spark Streaming城市内涝流计算程序订阅Apache Kafka发布的降雨量数据流并按批次进行分割,基于实时内涝信息流计算模型转化为分布式处理任务并在Apache Spark集群中进行快速的计算和分析,从而得到动态的城市内涝过程模拟结果.
2 实时内涝信息流计算模型
内涝信息流计算模型是城市内涝模型实时感知原型系统的核心,它负责接入实时降雨量观测数据流并基于流计算引擎以流计算的方式将实时降雨量观测数据和其他相关数据代入传统的城市内涝灾害模型中进行快速的处理、计算和分析,最终获得近实时的城市内涝灾害信息.
2.1 传统城市内涝灾害模型
本文使用的传统城市内涝灾害模型主要基于SCS-CN模型和GIS"体积法"模型.SCS-CN模型一般用于降雨产流量计算,其模型可以表示为[11]:
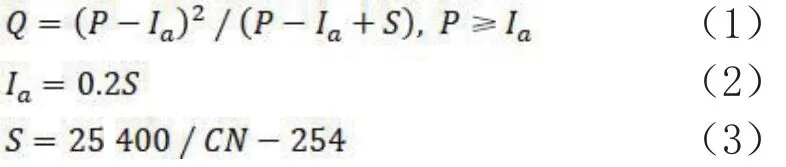
公式(1)中计算结果Q为降雨径流深度,单位为mm;参数P为计算时的当前降雨总量,单位为mm;参数S为降雨区域内当时雨水的最大可能滞留量,单位为mm;Ia是由植被拦截、土壤下渗等导致的降雨初损,单位为mm.由于S与下垫面的多种因素有关,变化范围非常大,不利于计算获取.因此模型引入了公式(3)中的无因次经验参数CN,可以通过查询当地的CN表得到,以求尽量准确地得到S的值.
而GIS"体积法"模型在已知降雨滞留量(产流量减排水量)后可用于洪涝淹没范围的计算,可以表示为[12]:

公式(4)中,N代表城市内涝积水区域DEM总栅格数;Δ σ代表DEM每一个栅格的实地面积;E(i)代表DEM第i小栅格的地形高程,其取值范围为1-N.因此,在已知降雨产生的城市内涝总积水量W和城市DEM数据后,就可以使用二分法计算获得区域中内涝水面高程Ewater,而城市区域中所有低于Ewater的区域就可视为被淹没区.
2.2 实时内涝信息流计算模型
由于在城市内涝模型实时感知这个应用场景下,城市内涝信息在较短时间内并不会产生太大的变化.因此,流计算系统对流数据的计算延迟只需要控制在秒级甚至分钟级.而Spark Streaming作为优秀的流计算引擎足以满足秒级或分级的计算延迟需求并能够提供更强大的数据吞吐量和容错支持.因此,在本文提出的原型系统中搭建了一个Apache Spark集群作为基础流计算框架和整个内涝信息流计算模型的核心.
本文建立的实时内涝信息流计算模型如图2所示,该模型的输入数据为流式数据格式的实时降雨量数据流,根据实际应用的需求将数据流按照一定的时间间隔分割成离散的数据批次.由于流式数据具有无限性,因此将流式数据分割成的数据批次也是无限的.每当到达一个时间点生成一个数据批次时,就需要对这个数据批次进行及时的处理和分析.

图2 实时内涝信息流计算模型Fig.2 Stream computing model of real-time waterlogging information
每个数据批次即是该时间段内计算模型接收到的降雨量数据,包含城市内各个区域中的传感器在这个时间段内观测到的降雨量数据.该模型将这些数据按照所属的区域分割成独立的数据块(分割区域时需要保证其互相影响的可能性较小),并分别传输到分布式计算集群的各个计算节点上进行并行计算.
在集群的各个计算节点上,该模型利用传统的城市内涝灾害模型对每个区域的内涝信息进行独立计算:①对该时间段内各个传感器观测到的降雨量数据求均值并累加之前时间段的降雨量可以求得区域当前降雨量的累计值;②基于SCS-CN模型,代入区域当前降雨量累加值以及根据区域下垫面特征查表获得的CN值,即可求区域当前降雨产流量;③将降雨产流量乘以区域面积并减去区域当前累计排水量就能获得当前区域内的总积水量;④通过GIS"体积法"模型,利用区域总积水量数据和数据库中存储的该区域DEM数据求解方程就可以计算得到区域内积水水平面的高程,而DEM中高程小于水面高程的区域即为内涝淹没区域;⑤该模型将这些内涝信息计算结果输出到数据库中进行保存,并可以通过GIS可视化软件利用DEM数据对城市内涝灾害过程进行动态可视化模拟.
3 实验结果与分析
为证明本文提出的方法的可行性,本文对城市内涝模型实时感知原型系统进行了环境搭建,并进行了相关实验.其中,证明系统可用性和方法可行性的预期效果是该系统对每批次降雨量观测数据的处理时间能够小于下一批次数据的产生时间.
3.1 实验环境和数据
本实验环境基于两台高性能计算服务器A和B.每台服务器具有93.4G运行内存、24个物理核以及200 GB存储硬盘,并且安装了Ubuntu 14.04.5操作系统和Java 8运行环境.原型系统在服务器B上安装了传感网管理平台Open Sensor Hub 1.1.0作为传感网实现[14],带有PostGIS插件的PostgreSQL 9.3作为数据库.并以A、B为两个节点搭建了Apache Spark 2.1.0测试集群和Apache Kafka 2.11测试集群.
本文选择了湖北省武汉市某区域作为实验区域,该区域面积约为51.4X104m2.为了充分利用分布式计算架构提高处理效率,本文根据该区域的地形特征将其分成70个子区域.该DEM数据总共具有3 473X4 983个栅格,将其根据划分的70个子区域分为70个子DEM数据,每个约有494X495个栅格.同时,通过查询相关数据,获得了每个子区域拥有的排水口数量以及它们的下垫面特征,并对照SCS-CN模型提供的CN值表获取了各个子区域的CN值.这些数据都被存储在PostgreSQL数据库中进行管理.
为了验证本文提出的城市内涝模型实时感知方法和原型系统的有效性,本文仿真该实验区域遭遇一场每min降雨量约为1mm且持续1 h的特大暴雨(传感网降雨量观测数据由Open Sensor Hub接入的虚拟气象传感器实时动态生成),利用搭建的实验环境对该区域内发生的城市内涝灾害进行实时感知.
3.2 实验结果和分析
在整个实验流程中,城市内涝信息流计算程序每分钟计算得到的各个区域的内涝信息都存储在数据库的内涝信息表中.如区域编号为9的子区域,它计算得到的每分钟近实时内涝信息在数据库中如图3所示.可以发现子区域9从10:13分开始就开始产生了内涝积水(volume列)并逐渐增多,积水水平面(elevation列)也不断增高(当无积水时积水平面高度为当前区域最低地表高程).

图3 子区域9内涝实时内涝信息Fig.3 Real-time waterlogging information of sub-region 9
在系统运行的同时,基于GIS可视化软件对实验区域的DEM数据进行三维可视化并叠加计算得到的实时城市内涝信息,如下图4所示.系统分别在降雨开始10 min后、20min后、30min后和60 min后对原型系统感知的当前城市内涝灾害状态进行了可视化.图中蓝色表示内涝产生的积水,棕色表示该区域的地形,颜色越深代表高程越高.观察可以发现,随着降雨时间的推移,研究区域中的低洼处首先出现内涝积水,接着逐渐向高处蔓延,最后几乎覆盖整个区域1/2的区域.
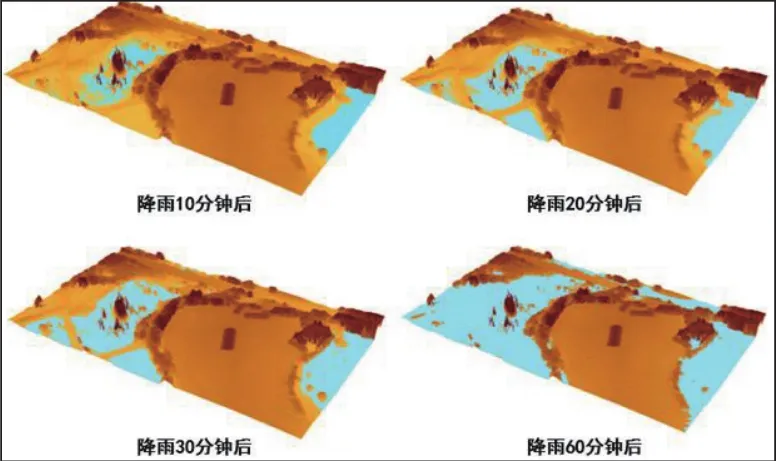
图4 实时城市内涝信息三维可视化Fig.4 3d visualization of real-time urban waterlogging information
实验对原型系统的整体计算性能进行了测试,通过对降雨量数据流分区数和集群资源的控制,对比系统每批次计算任务的处理性能.结果如图5所示,随着集群中核数的增加和内存数的增加,内涝流计算系统每批次任务的处理时间先快速减小后趋于平稳.而且当数据分区数为4时每批次任务处理最短时间稳定在16s左右,当数据分区数为70时最短时间稳定在4s左右.原因是Apache Spark集群数据处理效率与集群核数有关,一般一个核上只能处理一个任务,而随着集群核数的增加,数据能够在多个核中进行并行化计算从而提高了计算效率缩短了处理时间.同时,数据的分区数决定了计算时产生的任务数量,即4个分区产生4个计算任务,70个分区产生70个计算任务.因此当集群核数为4时数据分区为4的数据流已经能够完全并行化计算,于是再增加集群资源其处理时间也不发生太大变化.而数据分区为70的数据流则当集群核数超过24个后才趋于稳定.综上可以得出结论,该原型系统能够通过控制集群资源和数据流分区数对处理时间进行不断的优化从而使数据处理延时不断减小从而趋于实时化,具有良好的可扩展性.同时,对于该实验案例,每批次的降雨量数据的处理时间至少能控制在4s左右,远小于数据批次产生的时间1 min,因此该原型系统也具有良好的可用性,能够近实时地计算并模拟出城市遭遇暴雨发生内涝灾害的动态过程.

图5 每批次计算耗时与集群资源关系Fig.5 The relationship between computation time of each batch and resources of computer cluster
4 结束语
实时数据计算与地理过程模型集成是地理模型实时感知的基础,也是现代地理信息系统的主流发展方向.本论文为解决地理模型实时感知中的系统耦合架构、地理实时计算模型等难点,提出了基于开放标准的传感网与流计算系统耦合架构,并将其应用到城市内涝灾害的动态感知场景下,结合建立的实时内涝信息流计算模型,设计并实现了一种基于流计算的城市内涝模型实时感知原型系统.
原型系统的数据获取层基于OGC SWE标准建立气象传感网对气象数据进行实时观测、数据管理层基于OGC SOS标准进行传感网数据的管理和发布、数据转化层基于Apache Kafka分布式消息发布/订阅系统转化并发布传感网观测数据流、数据处理层基于Spark Streaming流计算引擎建立实时内涝信息流计算模型进行实时观测数据流的处理和分析.本论文通过选取具体的实验区域对原型系统进行了案例测试,实验结果表明整个原型系统具有良好的可用性和扩展性,验证了本文提出的城市内涝模型实时感知方法具有可行性.
在之后的研究中,本文提出的方法和原型系统需要进一步地应用到真实的城市内涝灾害场景中进行测试和分析,以改进计算模型提高其精度和性能,从而使本研究能真正地落到实处,为政府相关部门提供有效的信息决策.
猜你喜欢
传感技术学报(2022年7期)2022-10-19
今日农业(2022年15期)2022-09-20
数学小灵通·3-4年级(2021年6期)2021-07-16
电子制作(2018年23期)2018-12-26
公民与法治(2016年16期)2016-05-17
湖南水利水电(2015年2期)2015-12-24
中国舰船研究(2014年6期)2014-05-14
新疆农垦科技(2014年7期)2014-02-28
河南科技(2014年1期)2014-02-27
城市道桥与防洪(2014年11期)2014-02-27
