
基于PyTorch的机器翻译算法的实现
2018-10-15 05:58李梦洁
计算机技术与发展 2018年10期
李梦洁,董 峦
(新疆农业大学 计算机与信息工程学院,新疆 乌鲁木齐 830000)
0 引 言
在机器翻译中,如何选择更有效率更适合翻译的模型一直都是深度学习中研究的热点之一。近年来,很多深度学习、人工智能领域的研究者不断探索改进实现机器翻译的相关模型,反复进行了大量的实验。随着人工智能的发展,机器翻译相关技术得到了不断的改进创新,使得机器翻译走向了更前沿的水平。
Treisman和Gelade提出了注意力机制方法[1],它是可以模拟人脑注意力的模型,并可通过计算注意力的概率分布来突显输入中某一个输入对于输出的影响作用。简单来说,就是当人们观察一幅图片时,首先注意到的是图片中的某一部分,而不是浏览全部内容,之后在观察的过程中依次调整注意的聚焦点。这种注意力机制的方法对于传统模型具有良好的优化作用。因此,文中在序列对序列网络模型上运用注意力机制,以提高序列对序列的自然方式下的系统表现。
1 研究现状及意义
1.1 机器翻译
机器翻译(machine translation)即自动翻译,是在自然语言方面实现两种语言之间相互转换功能的过程[2]。即研究怎样通过计算机来实现多个自然语言之间的转换,是人工智能的终极目标之一,也是自然语言处理领域尤为重要的研究方向之一[3]。机器翻译技术的持续发展,特别是近年来涌现的神经机器翻译,使机器译文质量明显提高,也迎来了机器翻译应用的发展高潮。互联网社交、跨境电商和旅游以及更多细分垂直领域中,机器翻译正在帮助人们跨越语言障碍,应对大数据翻译需求。现如今,机器翻译技术在不断完善,并在政治、经济、文化方面的交流中起到了至关重要的作用。
1.2 深度学习框架
深度学习是机器学习的一部分,是机器学习中一种基于对数据进行表征学习的方法。它可以模仿人的大脑结构,高效处理特别复杂的输入数据,提取数据中的抽象特征,达到智能学习的效果[4]。深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。
目前研究人员正在使用的深度学习框架有TensorFlow、PyTorch、Caffe、Theano、Deeplearning4j、ConvNetJS、MXNet、Chainer等,深度学习框架在很多领域应用广泛,如语音识别、自然语言处理等,并获取了极好的效果。
文中实验使用的深度学习框架是PyTorch。PyTorch是Facebook推出的人工智能学习系统,虽然底层优化是在C的基础上实现,但基本所有框架都是用Python编写,因此源码看起来较简洁明了。相对于其他框架,它有可以支持GPU、创建动态神经网络、Python优先等特点。相对于Tensorflow,PyTorch更加简洁直观,因此在训练机器翻译模型的实验上选用该框架。
2 相关技术研究
2.1 基于短语的统计机器翻译
统计机器翻译(statistical machine translation,SMT)的核心思想如下:在建立一定数据的平行语料库后,对其进行统计分析,从而构建相关模型来进行机器翻译。统计机器翻译步骤如下:首先为语言的产生构造合理的统计模型,其次定义要估计的模型参数,最后设计参数估计算法。
假设用字母y代表源语句,那么机器翻译的模型会在目标语句中找寻一个概率相对最大的句子m,m表示为:
m=argmaxep(m|y)
(1)
2.2 基于神经网络的机器翻译
神经机器翻译(neural machine translation)是一种新兴的机器翻译方法[5-7]。与传统的包含许多单独调整的小组件的基于短语的翻译系统[8]不同的是,神经机器翻译试图建立和训练一个单独的大的神经网络,这样就可以读取一个句子并且能输出一个正确的翻译[9]。
目前最受研究者欢迎的是基于人工神经网络的机器翻译:一个通过训练可以从语料库中学习并由很多神经元组成的深度神经网络。实现两个语言之间的翻译即为先输入源语言,在神经网络中训练后得出目标语言的过程。通过模拟人脑能达到先理解后翻译的功能。这种翻译方法最大的优势是翻译出来的语句较为通顺,比较符合语法规范,便于大众理解。相比其他的翻译技术来说质量上有了显著提高。
最常用的神经网络是循环神经网络(recurrent neural network,RNN)。该网络通过学习能够将当前词的历史信息存储起来,以词的整个上下文作为依据,来预测下一个词出现的概率,克服n-gram语言模型无法利用语句中长距离上下文信息的缺点[10]。循环神经网络由Socher在句法解析时采用[11],Irsoy和Cardie将循环神经网络进行深层组合,成为一个典型的三层结构的深度学习模型[12]。循环神经网络被证明在解决序列化的问题上效果突出,能够用到上下文的信息,在机器翻译等领域取得了不错的效果。但是循环神经网络在求解过程中存在梯度爆炸和消失问题[13],并且对长文本的效果不佳。后期提出的长短时记忆神经网络(long short-term memory,LSTM)有效地解决了长序列问题。
传统的神经网络结构是由输入层、隐藏层和输出层组成的。层与层之间有密切的联系,但每层之间的节点没有连接。RNN即一个序列当前的输出与前面的输出有关,具体的表现形式如图1所示。
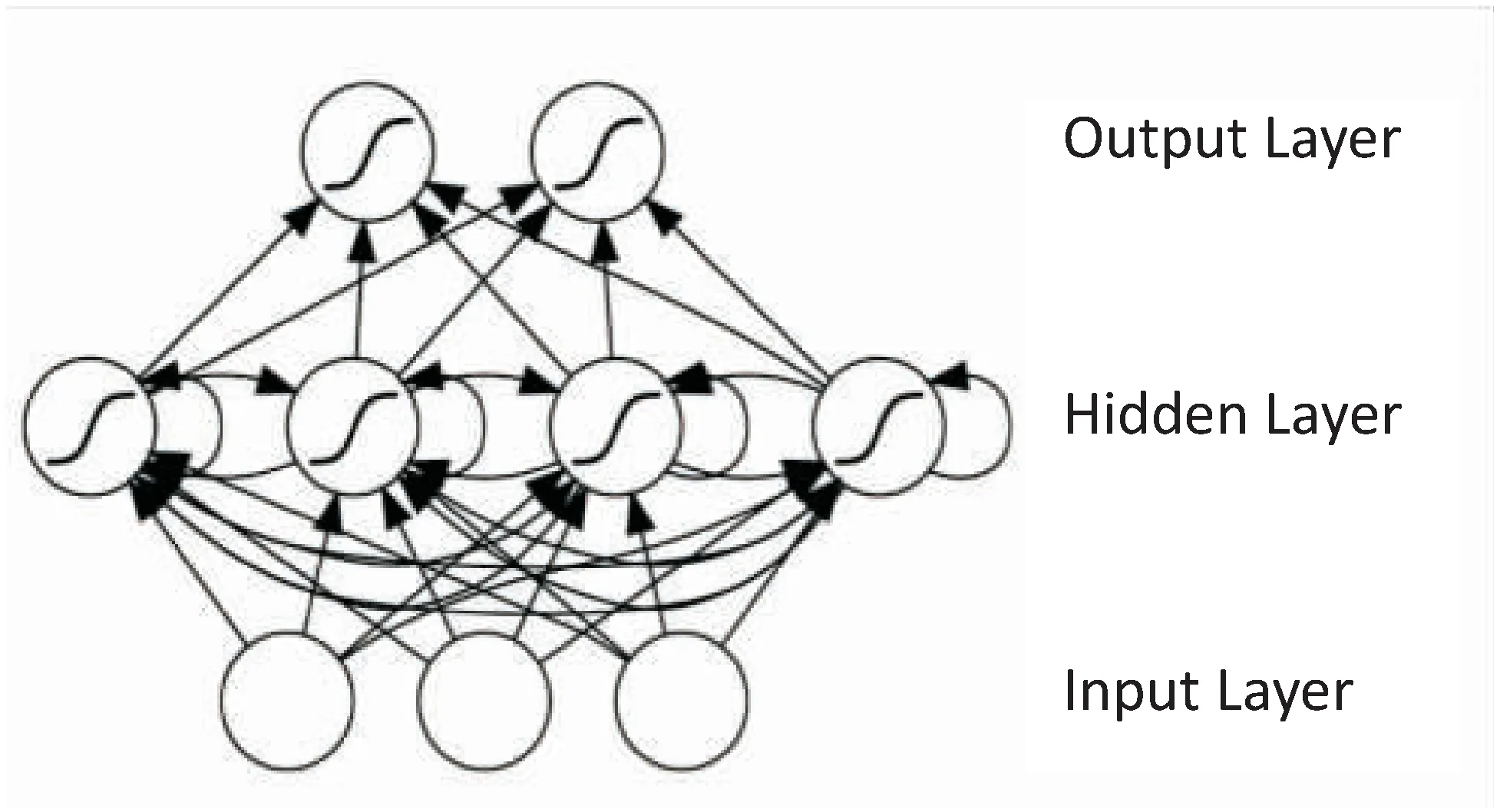
图1 RNN语言模型结构
2.3 注意力机制
注意力(attention)是指人的心理活动指向和集中于某种事物的能力。注意力机制(attention mechanism)是基于人类的视觉注意力机制。简单来说,视觉注意力机制就是:当人们观察一幅图片时,首先注意到的是图片中的某一部分,而不是浏览全部内容,之后在观察的过程中调整注意的聚焦点。因此,神经网络领域中的注意力机制就是通过这个原理得来的。
在普通的编码解码(encoder-decoder)网络结构中把输入序列的所有重点信息压缩到一个固定长度的向量,但操作过程中有信息损失,在处理较长句子特别是超过固定长度的句子时效果会越来越差,模型能力会逐渐降低。随着句子长度的増加,encoder-decoder神经网络的性能也跟着不断变差[7]。为了解决这个问题,Yoshua Bengio等在神经网络中通过模拟注意力机制实现英语到法语的翻译,输出序列中每输出一个元素,都通过权重参考输入序列信息,这样就可实现输入序列与输出序列之间的对齐。注意力机制的核心思想是:将输入的源语句传入编码器后由编码器生成一个输出,此时给输出加入权重向量后作为解码器的输入。注意力机制分为随机注意(stochastic attention)机制和软注意(soft attention)机制[14]。深度学习中的注意力机制更像是存储器访问,在决定权重大小前,需要访问输入序列隐藏状态的所有细节。
该实验使用的是由两层循环神经网络组成的序列对序列网络(sequence to sequence network)模型,同时在模型中加入了注意力机制(attention mechanism)。
3 实验设计
3.1 数据来源和处理
实验使用英法数据集进行模型的训练和测试,数据形式为英法的对照语句对。将处理好的数据导入到语言模型包中后开始训练该模型。
该实验的技术路线图如图2所示。
图2 技术路线图
3.2 算法实现
实验将输入的数据序列定义为X,其中每一个单词为x。那么一个输入序列语句就表示为(x1,x2,…,xT)。通过RNN模型翻译后得出的输出语句序列定义为Y,那么一个输出序列语句就表示为(y1,y2,…,yT)。该实验使用的序列对序列网络是由2个隐藏层、256个隐藏节点、2个RNNs组成的神经网络模型,用来训练处理好的数据文本,以达到英语和法语相互翻译的效果。
从处理数据开始,实验的步骤依次为:
第一步:将输入语句和目标语句在网络层中加入索引,并将生僻字单独存储在一个字典里;
第二步:将以Unicode字符形式存储的数据文件转换成以ASCII形式存储的文件,并且使所有内容小写,同时修剪大部分标点符号;
第三步:将存储数据的文件分成行,然后拆分成对,分别为英语对照法语的形式,并根据数据的长度和内容标准化文本;
第四步:将数据导入模型中进行训练。
此次实验使用序列到序列模型(The seq2seq model)。该模型是由两个RNN网络即encoder和decoder组成,编码器读取输入序列X并且输出单个向量,解码器读取该向量以产生输出序列Y。其中,将编码器encoder作为一个网络,将解码器decoder作为另一个网络,并将注意力机制加入decoder中。其模型结构如图3所示。
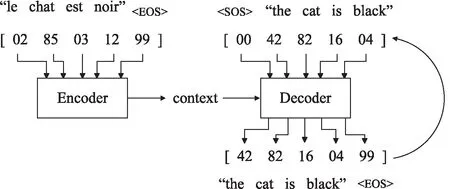
图3 序列到序列模型结构
在训练数据时,首先通过编码器输入源语句序列(x1,x2,…,xT),然后解码器会给第一个输入语句一个开始符号
ht=sigm(Whxxt+Whhht-1)
(2)
经过RNN模型产生的输出序列为(y1,y2,…,yT)。其过程通过迭代式2和式3完成:
yt=Wytht
(3)
4 实验结果与分析
4.1 实验结果
通过训练模型得到了训练结果和翻译结果。数据经过处理后,最终筛选出75 000个词进行实验,通过对比输出的目标语句和准确语句可以看出,翻译效果还是不错的。
训练语句的进度和平均损失如图4所示。
以图5到图6两个简单的句子为例,x和y轴分别表示源语句和目标语句的单词,其中每一个像素代表的是源语句对于目标语句的权重,即为注意力机制的表现。右侧条状图从0.0到1.0为权重大小(0.0表现为黑色,1.0表现为白色)。
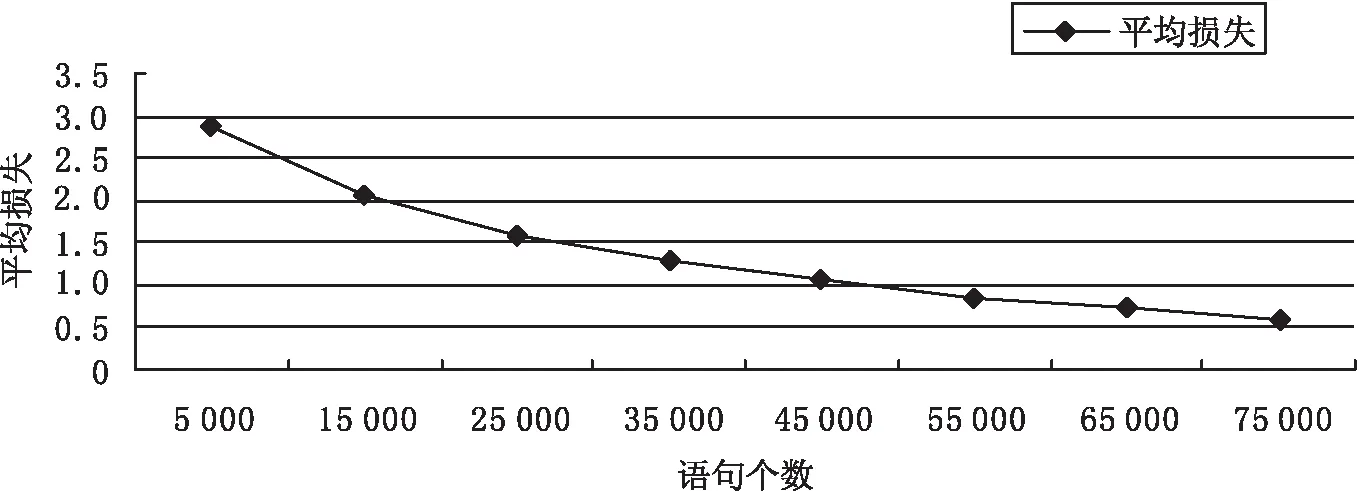
图4 训练状态表
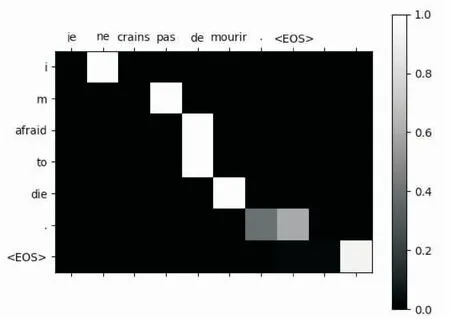
图5 训练语句(a)
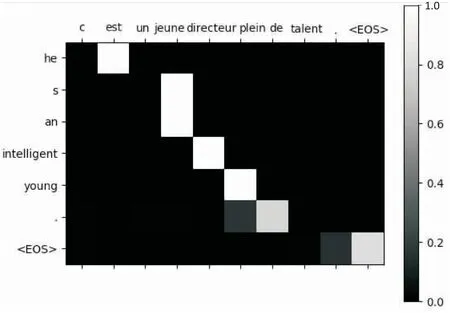
图6 训练语句(b)
4.2 评价指标及方法
机器翻译的评价标准有BLEU[15]、NIST[16]、METEOR[17]和TER[18],以上用来评价机器翻译的标准都是用对比机器翻译译文和人工译文的方法来衡量机器翻译的质量,定量模型的质量和翻译结果。实验使用BLEU作为评价标准,以衡量翻译的准确率和词错率。
BLEU的取值范围是0到1,数值越接近1说明机器翻译的效果越好、词错率越低。实验使用的是英法数据集,将预测翻译出的数据与参考译文数据分别存储在不同的文档里,通过计算Bleu1、Bleu2、Bleu3、Bleu4的值来分析翻译质量。取其中300个语句进行计算,得出的结果如表1所示。
表中gram代表词的个数,当gram为4时BLEU值相对较低,但词数多的情况下准确率高,因此选择BLEU4作为最终评价值。由BLEU4的值可以看出,评价值相对较低,说明预测翻译效果不理想。通过分析实验结果,主要存在的问题有:
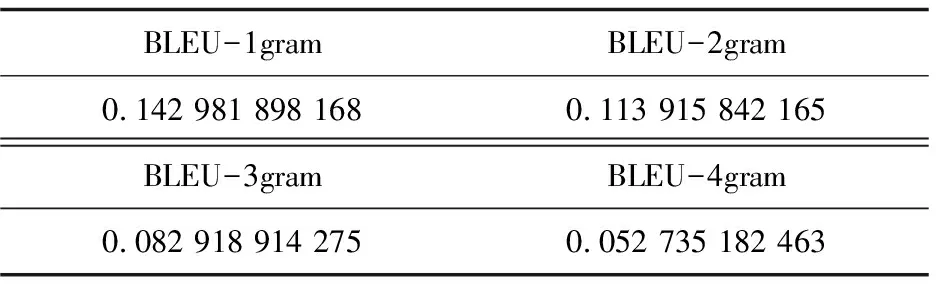
表1 300个语句得出的BLEU值
(1)模型架构相对较简单,RNN中隐藏层数较少,训练不到位。
(2)数据集数量较少,方向单一,使模型不能很好地学习,导致翻译效果不佳。
5 结束语
在英法两种语言之间的翻译上使用了基于神经网络的RNN模型,用到的数据相对较少,因此模型的层数和规模也相对较少。通过对数据的训练和测试达到测试RNN模型的效果。同时,通过训练RNN模型并观察它的准确率,来不断改进模型,从而达到更好的预期效果。此次实验用到的数据具有一定的局限性,因此在准确率方面还有一定的欠缺。但是对于模型的研究和探讨有一定的作用。
猜你喜欢
现代电力(2022年2期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
甘肃教育(2020年22期)2020-04-13
电子制作(2019年19期)2019-11-23
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2017年12期)2017-04-23
第二课堂(课外活动版)(2016年2期)2016-10-21
小学生·多元智能大王(2014年6期)2014-07-09
外语教学理论与实践(2014年1期)2014-06-15
小雪花·初中高分作文(2009年8期)2009-11-16
