
基于用户定义安全条件的可验证重复数据删除方法
2018-10-15 09:04刘红燕咸鹤群鲁秀青侯瑞涛
计算机研究与发展 2018年10期
刘红燕 咸鹤群 鲁秀青 侯瑞涛 高 原
1(青岛大学计算机科学技术学院 山东青岛 266071)2(综合业务网理论及关键技术国家重点实验室(西安电子科技大学) 西安 710071)
云存储技术的不断发展促使更多的组织和个人将数据外包至云服务器进行存储,以释放本地的存储空间[1-2].从简单的备份系统到云存储系统,云服务器为用户提供了低成本、可扩展的在线服务[3].随着用户数据规模的不断增长,云服务器提供商(cloud service provider, CSP)面临着巨大的挑战——超大规模的数据量和大量冗余数据的管理.CSP普遍采用重复数据删除技术来提高存储空间利用率,实现可扩展的云存储管理.重复数据删除技术(data deduplication)是指多个用户上传同一数据时,云服务器仅保存一份数据拷贝,为其他用户创建该数据拷贝的链接,由此节省网络带宽和压缩云存储空间.现有的商用云存储系统普遍应用了重复数据删除技术,如Dropbox,Wuala,Mozy,Geogle Drive等[4].研究表明:重复数据删除技术可有效降低备份系统的存储开销,甚至可高达90%以上.在普通应用系统中,该技术可降低60%以上的存储开销[5].
根据数据处理的粒度,重复数据删除技术可分为文件级重复数据删除和块级重复数据删除.与文件级重复数据删除技术相比,块级重复数据删除具有更小的数据粒度,可以提高存储空间的使用效率,但需要在每个数据块中都记录其所属的文件标识.根据重复删除操作发生的场合,重复数据删除技术可分为服务器端重复数据删除和客户端重复数据删除.客户端重复数据删除技术应用较为普遍,可节省网络上传带宽,但易遭受侧信道攻击和在线穷举攻击[6].服务器端重复数据删除要求将所有数据上传至云服务器,由云服务器进行数据重复性判断和执行相应操作,该方式可有效地抵御侧信道攻击和在线穷举攻击,但需要额外的数据带宽.以上方法各有其优势和局限性,通常根据应用场景和安全需求进行选择.
随着网络安全问题的不断凸显,用户对数据安全的重视程度不断提高.为保护数据隐私,用户通常先对数据加密,再将其外包至云服务器.然而,即使相同的数据,在不同的加密密钥和加密方式的作用下,所得的密文也是不一致的[7-9],因此云服务器难以直接根据密文判断数据是否来自同一明文数据,这严重制约了跨用户重复数据删除系统的执行效率.
加密数据的重复删除是一类特殊的安全多方计算问题[10],除了考虑云服务器对用户隐私的威胁,还要实现互不信任的参与者之间的协作.用户在不泄露各自隐私的前提下,需要借助云服务器共同完成数据的共享和重复删除.与电子选举、秘密共享、匿名签名等典型的安全多方计算问题[11-12]相比,加密数据的重复删除更加体现了受限安全环境中的用户协同计算特征.
为解决数据加密和重复数据删除技术的兼容性问题,研究者对数据加密算法进行了改进.最初的解决方案是采用云服务器设定的全局变量对所有数据加密,但云服务器不可信,这将导致用户数据的泄露.在此基础上,Douceur等人首次提出了实现数据保密性和重复数据删除效率性的平衡方案——收敛加密(convergent encryption, CE)[7].该方案采用数据散列值作为加密密钥,在加密算法确定的情况下,相同的数据可加密得到相同的密文[13].尽管CE简单且高效,但当数据信息熵较低时,CE易遭受字典攻击和离线穷举攻击,仍无法达到语义安全的要求[14].Cui等人提出一种基于密文策略属性加密的重复数据删除方案[15].方案采用混合云结构,公有云负责数据的存储,私有云负责数据重复性检测,这种结构增大了云服务器的管理开销.此外,所有数据都采取属性加密策略,执行效率较低.
为提高重复数据删除效率,Stanek等人提出将数据分为流行数据和非流行数据,并采取不同的加密策略[16].流行数据的隐私程度较低,采用收敛加密进行保护;非流行数据的隐私程度较高,需要采用语义安全的对称加密算法加密.为实现用户的身份管理和重复数据的安全删除,该方案引入了第三方服务器和索引服务器.在此基础上,Puzio等人提出了借助第三方服务器协助云服务器完成重复数据删除操作的perfectDedup方案[17],该方案利用完美Hash函数进行文件标识的计算,且允许对流行数据块进行重复数据删除操作.对非流行数据块,云服务器将会保存多个数据拷贝.上述方案都引入了第三方服务器,增加了系统的复杂性,因此实用性不强,且仍无法防范来自云服务器的离线穷举攻击.
在系统架构方面,Liu等人首次提出了一种无需可信第三方的服务器端重复数据删除方案[18].拥有相同数据拷贝的用户运行password authenticated key exchange(PAKE)协议进行密钥交换[19-20].与之前的方案相比,该方案摆脱了实时在线的第三方,采用同态加密,相同的数据可加密得到相同的密文.但是,每个用户在上传数据之前都要运行PAKE协议与其他用户进行交互,以获取数据加密密钥.这带来了额外的计算开销和通信开销,降低了方案的执行效率.另外,对用户在线的要求降低了该方案的实用性.
在数据所有权管理方面,为保护数据的隐私,云服务器应防止非授权用户对数据的非法访问.Hur等人[21]提出了基于随机收敛加密(randomized convergent encryption, RCE)和组密钥管理机制的重复数据删除方案,可实现数据的动态权限保护.方案采用双层加密模式,内层采用RCE,外层基于组密钥进行对称加密.将默克尔Hash树用于组密钥的加密和解密,实现所有权的动态管理.但方案采用双层Hash值作为文件标识,仍易遭受来自云服务器的穷举攻击.
观察目前已有的重复数据删除方案,均未考虑一个现实的问题——用户对数据共享程度与范围的控制.现有的方案多以云服务器为中心,着力降低其存储开销,追求其利益最大化.在很多实际应用中,用户为充分保护数据隐私,不希望与其他用户共享数据.若用户的密钥生成算法或密钥生成器的安全性较弱,攻击者可根据大量数据的上传记录,猜测出数据加密密钥,这对于用户数据安全造成了严重威胁.例如,企业项目组长上传某个内部文件,要求仅在项目组内共享该数据.现有的重复数据删除方案一旦判定云服务器中存在重复的数据,即执行重复数据删除操作,并进行数据的共享.敌手可通过检测数据上传情况发起穷举攻击,获得数据内容,甚至得到项目组长的数据加密密钥.这种数据被动共享及安全风险的产生,源于用户数据共享控制机制的缺失,将会严重影响云存储用户的数据安全.
此外,已有的方案均未考虑敌手通过信道监听的方式进行攻击的可能性.上述方案均假设第三方完全可信,并且通信信道是绝对安全的.在重复数据删除系统中,一旦敌手对通信信道进行监听,截获数据标识等信息,便可伪装成合法用户与云服务器进行交互.云服务器无法正确判断出敌手身份的合法性,则授予敌手对该数据的访问权.
在云服务器和用户多方不可信的前提下,实现支持用户隐私保护和高效重复数据删除的云存储系统,保证数据标识和加密密钥的安全管理是目前云存储安全领域研究的热点问题.本文提出了一种基于用户定义安全条件的可验证重复数据删除方法.所有用户都需要与云服务器进行交互,以验证其对数据的所有权.用户间互不信任,无法获取其他用户与云服务器之间有效的交互数据.首次解决了用户定义的重复数据删除问题,能够有效消除恶意用户信道监听攻击的威胁.数据的初始上传者可自主选择要共享数据的用户范围,当且仅当后继上传者满足其设定的安全条件,方可进行数据的共享.具体来说,本文的贡献可归纳为3个方面:
1) 在重复数据删除方案中分析了用户数据共享控制问题,引入了用户属性,基于双线性映射扩展了数据标识,设计了数据安全条件机制,实现了用户定义的重复数据删除,充分保护了数据隐私;
2) 基于安全多方计算理论和布隆过滤器技术,构造了数据所有权证明协议,实现了对数据所有权的证明和保护,有效防范敌手通过信道监听获取数据的所有权;
3) 采取文件级和块级相结合的重复数据删除方法,进一步提高了重复数据删除效率.
1 预备知识
1.1 双线性映射


2) 可计算性.∀P,Q∈G1,e(P,Q)是可计算的.
3) 非退化性.∃P,Q∈G1,使得e(P,Q)≠ε.
1.2 广播加密
广播加密是一种在不安全信道上给选定用户集传输加密信息的密码体制[23].以选定的用户集为单位,只有授权用户方可解密出明文信息.基于身份的广播加密方案(IBBE)将基于身份的公钥加密体制应用于广播加密方案[24].IBBE方案的安全性基于双线性Diffie-Hellman假设,采用了基于身份的多接收者公钥加密的思想.
用户身份标识可以是任何能代表用户身份的字符串,利用双线性映射将这些标识字符串转换成公/私钥对.每个用户只存储部分公共参数以及其公/私钥对.广播中心(broadcast center, BC)用公钥加密发送给用户的信息,用户使用对应的私钥进行解密.
1.3 所有权证明协议
所有权证明(proof of ownership)协议是提高客户端重复数据删除方案安全性的有效措施[25].所有权证明采用数据的短Hash值作为文件的代理,用户可以向云服务器证明其拥有该数据的所有权.具体来说,所有权证明包括以下2个交互算法,分别由证明者(用户)和校验者(云服务器)执行:
1) 云服务器根据数据D的信息进行预计算,生成质询集合Challenge和对应的回答集合Res;
2) 为证明对D拥有所有权,用户从云服务器中获取未被使用的质询chall,其中chall∈Challenge.如果用户能计算出正确的回答,则说明该用户拥有数据D的所有权.
1.4 布隆过滤器(Bloom filter)
布隆过滤器是一种基于多个Hash映射函数的概率性数据结构,包括1个位数组(bit array)以及t个Hash函数,其中t个Hash函数将数据以相同的概率映射到位数组的任意下标,并将位数组的对应位设置为1[26].布隆过滤器可用于确认元素归属问题和成员查询问题,其优势在于存储和执行效率较高;缺点是当数据量较大时,极大概率下会产生冲突,这将影响元素判断的准确性.布隆过滤器包含以下函数:
1)Bloom_Init:初始化函数.若布隆过滤器包含长度为s的位数组BF,则需要将BF的每一位初始化为0;设Hi表示随机映射函数,其特性皆为{0,1}*→[0,s-1],其中整数i∈[0,t-1];
2)Bloom_Insert:元素插入函数.将元素e插入布隆过滤器的位数组中.Bloom_Insert(e,BF):BF[Hi(e)]←1,其中i∈[0,t-1];
3)Bloom_Query:元素查询函数.检查元素e是否属于此集合.Bloom_Query(e,BF):对所有i∈[0,t-1]判断BF[Hi(e)]数值是否为1.若存在映射位置对应的数值是0,则该元素一定不属于此集合.若映射位置数值全为1,则该元素可能属于此集合.因为布隆过滤器在元素映射过程中存在碰撞,所以具有一定的误判率.
1.5 计算Diffie_Hellman问题(CDH问题)
设G为大素数P的乘法群,其中g为生成元.CDH问题可以描述为: 对给定的g,ga,gb∈G1,计算Q=gab∈G1,其中a,b是未知的整数.
2 系统模型
2.1 系统结构
本文的系统模型如图1所示,包含2类实体:云服务器和用户.云服务器为用户提供数据存储和数据共享服务.每个用户可将其数据上传至云服务器,若该数据在云服务器中已存在,则云服务器采用重复数据删除技术来删除冗余数据,提高其存储利用率.在基于用户定义安全条件的可验证重复数据删除方案中,用户可选择是否设定安全条件.当用户上传数据D时,若用户属性符合在云服务器中已存在的安全条件,或者用户定义的安全条件在云服务器中已存在,则可进行数据的重复删除和共享.否则该用户视为另一安全条件下的初始上传者.

Fig. 1 System structure图1 系统结构图
在系统初始化阶段,云服务器公布可用于生成安全条件的属性列表.用户可选择其中的任意属性,定义对属性取值的安全要求,生成数据安全条件Φ(D).Φ(D)由数据标识T(D)和属性取值的安全要求ϑ(attr)两个部分构成,其中attr表示用户选定的属性.云服务器负责维护数据映射结构δ,δ实现了数据块和元数据之间的一一对应关系.元数据包括文件的安全条件集合、数据块标识集合、数据密文集合、密钥密文集合、文件对应的分块数据量、布隆过滤器的位数组、数据的所有权集合.云服务器中存储的文件和相应的位数组一一对应.
我们采取文件级和块级相结合的客户端重复数据删除方法.1)文件级重复数据删除.先判断文件在云服务器中是否已存在,如果已存在,则用户放弃数据上传请求,云服务器为当前用户创建文件的链接;2)块级重复数据删除.如果文件在云服务器中不存在,则进行块级重复性检查,如果块级重复,则进行块级重复数据删除;否则将块级数据上传至云服务器.
2.2 敌手模型
云服务器和用户之间存在利益冲突,云服务器希望降低存储成本,而用户希望得到安全高效的服务.因此,我们不考虑云服务器与用户合谋的情况.另外,我们认为所有数据都是隐私数据,而云服务器对用户数据是好奇的.因此,需要防止来自恶意用户和云服务器的攻击,我们主要考虑以下2种类型的攻击者:
1) 恶意用户.此类攻击者可监听信道,获得上传数据的部分信息,如文件安全条件等,从而通过与云服务器进行交互,获取数据的准确信息.攻击者也可通过对合法用户的通信信道进行监听,并与云服务器正常交互,从而获得数据的所有权.
2) 云服务器.云服务器可直接访问数据.诚实但好奇的云服务器会维护数据的完整性和可用性,但可在用户不知晓的情况下,对其存储的数据进行非法访问,从而获得尽可能多的数据明文信息.
2.3 设计目标
为实现安全高效的重复数据删除,设计的方案应该满足以下3个性质:
1) 数据安全性.要求上传的数据是语义安全的,敌手无法对上传的数据进行成功解密,从而获得任何有用信息;
2) 数据访问控制.确保仅授权用户可获得数据的访问权,非授权用户无法访问任何数据;
3) 密钥安全性.用户之间无需交互,即可获得数据加密密钥,确保云服务器和敌手不可获取数据的加密密钥.
2.4 符号说明
在本文方案中,用户可以自定义数据共享的群体,即设置重复数据删除操作的执行条件.但是,如果用户设定的数据安全条件过于苛刻(比如:无法与其他任何用户进行数据共享),将影响重复数据删除的效率.因此,我们引入了安全文件比例配额参数α,表示用户设定了安全条件的数据占其上传数据的比例.通过限制α的取值,保证云服务器能够对足够多的数据进行重复数据删除.

Table 1 Symbol Description表1 符号说明
3 可验证重复数据删除方案
本方案实现了重复数据删除方案中用户对数据共享操作的自主控制.云服务器设定用于生成安全条件的属性列表,并将其对用户公开.用户可选定具体属性进行设定,并与数据标识关联,生成安全条件,当且仅当后继上传者属性符合该安全条件,重复数据删除操作才会发生.否则,该后继上传者被视为另一安全条件下的初始上传者.属性列表可以包含诸如邮箱地址、网段号、客户端版本等信息.例如用户可以选定网段号这一属性,并设定当且仅当后继上传者IP地址的网段号属于某特定B类地址时,重复数据删除操作才会发生.
本方案包含以下7项操作:
1) 数据的重复性检测.方案采取文件级和块级相结合的重复数据删除方法,因此我们需要进行文件级和块级2阶段的重复数据检测.
2) 标识生成.可分为文件标识生成算法TagGen(x,F)→T(F)和块级标识生成算法TagGen(x,B)→T(B),其中密钥x由用户通过广播加密获得.


5) 密钥生成.KeyGen(r,B)→k,输入随机参数r和数据块B,输出数据的加密密钥.
6) 加密算法.Enc采用对称加密对数据块进行加密,加密密钥为k,输出密文C.
7) 解密算法.Dec采用解密密钥k对密文C进行解密.
3.1 系统初始化
系统初始化阶段的主要任务是对系统中的必备参数执行初始化操作,可分为2步:1)广播中心向所有用户安全地分发密钥x和u,用于标识生成和数据加密;2)云服务器将元数据设置为空.
3.2 重复性检测与数据上传
数据重复性检测由云服务器完成,可分为文件级重复性检测和块级重复性检测.当用户上传或下载文件F时,计算出文件标识T(F)=e(g,H(F)x),并可用其生成数据安全条件,其中x由用户通过广播加密获得.在数据上传阶段,云服务器首先对当前用户上传的文件进行文件级重复性检测,存在重复的情况如图2所示.如果未检测到重复文件,则进行更细粒度的块级重复性检测,如图3所示.在所有的场景中,用户都可以自主选择是否设定数据安全条件.

Fig. 2 Data upload (file duplication)图2 数据上传(文件重复)
当前上传者Ui对其上传的文件设定了安全条件Φ(F),如果在云服务器中已存在具有相同安全条件的文件,则判定存在文件重复,如图2(a)所示.当前上传者Uj在上传文件时未定义安全条件,仅生成数据标识T(F)并将其上传至云服务器.若云服务器中存在相同的文件且设有安全条件Φ(F′),Uj的属性符合Φ(F′),则判定存在文件重复;若云服务器中存在未设定安全条件的相同文件,且标识匹配,即可直接判定存在文件重复,如图2(b)所示.在上述2种情况中,上传者都需要通过云服务器发起的所有权挑战,才能与之前的对应用户共享文件.
在图3中,上传者Ui对其上传的文件F设定了安全条件Φ(F).如果云服务器中不存在一致的安全条件,则Ui作为带有安全条件的F的初始上传者,进而执行更细粒度的块级重复性检测,如图3(a)所示.若当前上传者Uj对其上传的文件F未设定安全条件,仅将数据标识T(F)上传至云服务器.如果云服务器中不存在匹配的数据标识,则Uj作为未设定安全条件的F的初始上传者,进而执行更细粒度的块级重复性检测,如图3(b)所示.在上述2种情况中,用户为执行块级重复性检测,需要对数据分块,计算每一块的数据标识,根据云服务器返回的重复性检测结果,执行数据重复删除或加密上传操作.

Fig. 3 Data upload (Initial upload)图3 数据上传(初始上传)
在块级重复性检测过程中,对所有云服务器中不存在的数据块进行加密上传.对任一数据块B,用户U选取随机参数r,基于r和B的Hash值生成加密密钥k.U采用k对数据块进行对称加密,并基于广播加密的密钥u对r加密保护,具体操作如算法1所示.
算法1. 数据加密算法.
输入:数据块B、密钥参数u;
输出:密文(Cr,CB).
Step1. 从集合FS中随机选取元素x.
Step2. 根据密钥生成算法生成数据加密密钥,k←KeyGen(r,Hash(B)).
Step3. 基于广播加密的密钥u对r加密保护,Ck←SE(u,Hash(B)-r).
Step4. 基于密钥k对数据块进行加密,CB←SE(k,B).输出密文集(Cr,CB).
用户将数据上传至云服务器后,将失去对数据所有权的控制.云服务器会将数据所有权授予符合安全条件的后继上传者.敌手可通过信道监听攻击,伪装成合法用户与云服务器进行交互,从而获得数据的所有权,进而对数据进行下载、修改等操作.为保护数据隐私和完整性,防止上述场景的出现,云服务器在将用户添加到所有权集之前,需要验证用户的所有权.本文基于布隆过滤器设计了数据所有权证明协议DPoW.
在初始上传者IU上传数据F时,需要进行布隆过滤器的初始化,保存每个数据分块的块标识与位置的信息,并在云服务器端的元数据中记录分块数量N,具体操作如算法2所示.
算法2. 布隆过滤器初始化算法.
输入:数据块Bi,其中i∈[0,N-1];
输出:用户计算的位数组BFc.
Step1. 调用标识生成算法,计算出Bi的块标识T(Bi).
Step2. 调用块位置和块标识映射函数生成元素e,其中e=H′(i,T(Bi)).
Step3. 调用布隆过滤器元素插入算法Bloom_Insert,将元素e插入位数组BFc中.
后继上传者SU上传数据时,需要进行所有权验证.云服务器从F的N个数据块中,任取l(l∈[1,N])块,将块位置数组Index发送给SU.对任一数据块BIndex[i],SU需要根据标识生成算法,计算出对应的块标识T(BIndex[i]),其中i∈[0,l].用户将计算得到的块标识保存在块标识数组Res中,并将其发送给云服务器.
云服务器收到Res后,计算出每个块标识和块位置所对应的散列值,确定其是否在布隆过滤器的位数组BF中.若l个散列值都在BF中则认为SU拥有F的数据所有权,并将SU加入到F对应的用户集合AU中,具体操作如算法3所示.否则,视为SU不具有访问权限.
算法3. 所有权挑战算法(云服务器端).
输入:块位置数组Index、块标识数组Res;
输出:数据所有权集合.
Step1.判断用户返回的数据块标识是否属于原集合.
Step1.1. 对每一数据块BIndex[i],调用块位置和块标识映射函数,生成元素e,其中e=H′(Index[i],Res[i]),i∈[0,l-1].
Step1.2. 云服务器调用布隆过滤器元素检测算法Bloom_Query,检测e是否属于原集合.
Step2. 若所有数据块对应的映射结果在BF中都能查询到,则将当前用户添加到所有权集合中F.AU←(F.AU)∪(id(SU)).
3.3 数据恢复
若用户Ui设定了数据安全条件Φ(D),则在数据恢复过程中,用户将Φ(D)上传至云服务器,如图4(a)所示.云服务器验证该数据是否已存在以及Ui是否具有访问权.当且仅当验证成功,云服务器才会将数据D对应的全部数据块密文{CBll}和密钥密文{Ckll}返回给用户.用户对其进行解密,从而恢复出原始数据D.若用户Uj未设定数据安全条件,则如图4(b)所示,Uj将数据标识T(D)上传至云服务器进行数据重复性检测和数据的下载.对任一数据块B,用户调用解密算法对其密文(Ck,CB)进行解密.使用广播加密的密钥u对Ck对称加密的解密,用户恢复出参数r,从而调用密钥生成算法,生成数据解密密钥k,进而解密恢复出数据块B,其中:
r=Hash(B)-SD(u,Ck).
4 安全性分析
4.1 数据安全条件的安全性
用户U需要将数据D的安全条件Φ(D)=T(D)‖ϑ(attrU)上传至云服务器,用于数据查找和重复性判断,其中attrU表示用户U选定的属性.我们主要分析数据安全条件中数据标识的安全性,包括其不可伪造性以及可区分性.
引理1. 对于安全的散列函数H:{0,1}*→G1,∀D1,D2∈[0,1]*,D1≠D2,H(D1)=H(D2)的概率是可忽略的.即:
P[H(D1)=H(D2)|D1≠D2]≤ε.
定理1. 数据标识的不可伪造性.设数据D的初始上传者Ui上传的数据标识为T(D)=e(g,H(D)x).当前用户Uj上传数据D′时,上传的数据标识为T(D′)=e(g,H(D′)x).当且仅当T(D)=T(D′)时,D=D′成立.即若T(D)=T(D′),那D≠D′的概率是可忽略的:
P[D≠D′|T(D)=T(D′)]≤ε.
证明. 不失一般性,由双线性映射的双线性,我们可得以下推论:
T(D)=e(g,H(D)x)=e(g,H(D))x.
(1)
若D≠D′,我们从以下2个方面讨论敌手对数据标识的攻击:
1) 假设敌手A是恶意用户,则A能获得参数x;
2) 假设敌手A是云服务器,则对A而言,参数H(D)和x都是不可预测的.
以上2种情况,敌手A都不能构造出满足等式T(D)=T(D′)的数据标识.换而言之,即P[D≠D′|e(g,H(D))x=e(g,H(D′))x]≤ε.
因此,数据标识具有不可伪造性,根据T(D)=T(D′)即可判断出D=D′.
证毕.
定理2. 数据标识的可区分性.设数据D的初始上传者Ui上传的数据标识为T(D)=e(g,H(D)x).当前上传者Uj上传数据D′时,上传的数据标识为T(D′)=e(g,H(D′)x).若D≠D′,则T(D)=T(D′)的概率是可忽略的,即:
P[T(D)=T(D′)|D≠D′]≤ε.
证明. 假设存在D≠D′,使得T(D)=T(D′).根据双线性映射的性质可得等式:
T(D)=T(D′) ⟺e(g,H(D)x)=e(g,H(D′)x)⟺
e(g,H(D))x=e(g,H(D′))x⟺
e(g,H(D))=e(g,H(D′)).
(2)
欲使式(2)成立,式H(D)=H(D′)必须成立.根据引理1,可得D=D′.这与假设矛盾,因此假设不成立.即:
P[T(D)=T(D′)|D≠D′]≤ε.
可见,当且仅当D=D′时,T(D)=T(D′)才会成立.即数据标识之间具有可区分性.
证毕.

定理3. 数据标识的安全性.云服务器无法对数据标识进行离线穷举攻击,以获得任何数据明文信息.
证明. 假设数据D的安全条件为Φ(D),云服务器以穷举的方式对D的内容进行猜测.根据Φ(D)的构造,我们可知Φ(D)=T(D)‖ϑ(attr).这里我们仅讨论云服务器对标识T(D)=e(g,H(D)x)的攻击.根据双线性映射的性质,我们可得T(D)=e(g,H(D))x.云服务器对数据D进行枚举,穷举大量的数据{Di},试图找到满足T(D)=T(Di)的数据Di.云服务器可以计算出e(g,H(Di)),但由于不是授权用户,无法从广播中心得知安全参数x,因此无法计算出T(Di)=e(g,H(Di))x.由引理2可知,即使已知e(g,H(D))x和e(g,H(Di)),计算e(g,H(Di))x仍是困难的.即若云服务器以离线穷举方式成功破解其存储的数据标识,则意味着可以成功解决乘法循环群G2中的一例CDH困难问题.群G2中的CDH问题是困难的,因此云服务器无法以穷举的方式从数据标识中获得数据明文的任何信息.
证毕.
4.2 所有权证明协议的安全性
方案基于布隆过滤器实现了对数据所有权的证明,防止敌手进行信道监听攻击,这是实现多方计算安全性的主要技术[27-28].假设敌手A成功通过了云服务器发起的所有权证明,即针对云服务器选取的l块数据块挑战,A生成的回答都能通过布隆过滤器的验证.设A挑战成功的概率为Psucc.针对l块中的任一数据块,A挑战成功可以分为2种情况:1)A成功生成了正确的数据标识作为挑战回答,令其概率为PRtag;2)A未产生正确的数据标识,但是因为布隆过滤器在元素映射过程中存在碰撞性,使得产生的数据标识经过运算也能通过布隆过滤器验证,令其概率为Pf,则可推算出:
Psucc=(PRtag+Pf×(1-PRtag))l.
(3)
我们具体分析敌手A提供正确数据标识的概率PRtag.针对任一数据块B,存在以下2种情况:1)敌手A已经知道了B的内容,因此可以正确生成数据标识,令其概率为p;2)敌手A不知道数据块的内容,但是A可以预测TagGen函数输出的每一位,进而猜测出正确的数据标识.在随机预言机模型下,A正确猜测出TagGen函数输出的每一位的概率为0.5,则A正确猜测出数据标识的概率为0.5|TagGen(x,B)|.可推出:
PRtag=p+(1-p)×0.5|TagGen(x,B)|.
(4)
将式(4)代入式(3),可得出:
Psucc=(PRtag+Pf×(1-PRtag))l=
(p+(1-p)×0.5|TagGen(x,B)|+
Pf×(1-(p+(1-p)×0.5|TagGen(x,B)|)))l=
(p+(1-p)×0.5|TagGen(x,B)|+
(1-p)×Pf-Pf×(1-p)×0.5|TagGen(x,B)|)l=
(p+(1-p)×(0.5|TagGen(x,B)|+
Pf×(1-0.5|TagGen(x,B)|)))l.
为保证数据的安全性,Psucc应该满足Psucc≤2-λ,其中λ是系统安全参数,即(p+(1-p)×(0.5|TagGen(x,B)|+Pf×(1-0.5|TagGen(x,B)|)))l≤2-λ,可以计算出:
l≥λ×ln 2×(p+(1-p)×(0.5|TagGen(x,B)|+
Pf×(1-0.5|TagGen(x,B)|)))-1.
(5)
即当l的数值满足式(5)时,敌手成功计算出数据标识的概率将是可忽略的.
4.3 数据的安全性
方案采用随机数r和数据摘要生成数据的加密密钥k.其次,利用广播加密的密钥对随机数r进行加密保护,从而保证了k的安全.本节主要从来自恶意用户和云服务器的2方面威胁,分析多方计算环境中的数据安全性.
4.3.1 抵御来自恶意用户的攻击
定理4. 恶意用户EU无法利用信道监听得来的交互数据,计算出数据本身的信息.
证明. 假设恶意用户EU是广播中心的授权用户,因此EU可获得广播的密钥x,u.设EU通过监听通信信道,得到数据交互信息T(B)以及数据下载信息Ck,CB.根据已获得的信息,EU对数据块B进行穷举攻击.
EU对数据块B进行穷举攻击,具体操作如下:
1)EU穷举数据块集合PB={Bi},i∈[1,2blkSize],其中blkSize表示数据块大小;
2)EU对PB中的所有数据块计算{Hash(Bi)};
3)EU穷举随机数集合{rj},j∈[1,2rndSize],其中rndSize表示随机数长度;

若EU穷举的密文集合中存在CBi,且满足CB=CBi,则认为敌手挑战成功,数据明文信息遭到泄露.EU可以成功破解数据的时间复杂度为Ο(2blkSize),在计算上不可行.
证毕.
4.3.2 抵御来自云服务器的攻击
定理5. 云服务器S无法通过对其存储的数据进行离线穷举攻击,从而获得数据本身的信息.
证明.S可以执行以下操作,以期望获得数据本身的信息.
根据定理4可知,S无法根据数据的密文,对数据成功进行穷举攻击.因此,本节中我们仅考虑S从数据安全条件方面获取数据本身的信息.
1)S查询数据结构δ得到数据标识T(D);
2)S穷举数据集合,得到集合{Di},计算出{H(Di)},i∈[1,2DSize],其中DSize表示数据本身的长度;
3) 因为S不是授权用户,因此无法获得广播中心发送的密钥x.S对x进行穷举,得到集合{xj},j∈[1,2xSize],其中xSize表示密钥x的长度.
如果在S穷举的{Di}中,存在Di,在xj的作用下,得到T(Di)=T(D),则认为S成功地进行了穷举攻击.该过程的时间复杂度为Ο(2DSize),在计算上不可行.因此,云服务器无法从其存储的数据结构中获得数据的信息.
证毕.
4.4 进一步讨论
在本文的方案中,存在云服务器欺骗行为的可能.当云服务器根据用户发送的数据安全条件判断是否执行重复数据删除操作时,可能会伪造查询结果.一种情况是用户上传数据安全条件后,云服务器在存在重复数据的情况下,仍给出无重复数据的回复.但是,这种欺骗行为是没有意义的.用户的目的只是将数据安全地存储于云服务器中,且云服务器无法得知正确的安全参数.云服务器伪造安全条件查询结果,则要消耗更多的存储空间,损害的是其自身利益.另一种情况是云服务器未检测到重复数据,但给出数据已存在的回复,并执行重复数据删除操作.然而,这种情况无法实现.云服务器仅通过上传的安全条件,无法给用户分配正确的访问链接.用户在数据恢复过程中会发生错误.所以,我们不考虑云服务器伪造安全条件查询结果的欺骗行为.
5 仿真实验与效率分析
本方案基于GMP[29],PBC[30],OpenSSL[31]函数库,采用C++语言进行编程实现.实验环境采用配有2.6 GHz主频6核双CPU,128 GB运行内存的HP ProLiant BL460c Gen8服务器以及多台具有2.5 GHz i7处理器和16GB内存的DELL台式机.网络连接采用10 Mbps的局域网模拟云存储应用环境.操作系统均为ubantu Linux.云服务器采用MySQL数据库存储数据信息.利用上述设备模拟了一个多用户云存储的多方计算应用场景[32-33].程序实现分为客户端和服务器端2个部分.客户端模拟用户执行数据上传的过程,服务器端模拟与用户的交互过程及云服务器数据的管理.
方案采取文件级和块级相结合的重复数据删除方法,以数据块作为云服务器数据密文存储的最小单位.实验使用MD5作为Hash函数,基于AES对称加密算法对数据块进行加密、解密.在密钥生成阶段,利用HMAC-SHA-1算法对随机数r和数据D的Hash值进行计算,生成密钥k.为模拟真实的应用环境,数据块大小为4 KB.云服务器发起的DPoW挑战中,块数l=100.对于分块数量不足100的文件,l取其实际分块数量.本节从删重率、计算开销以及方案性能3方面进行模拟实验与分析.
5.1 删重率
我们定义删重率τ=(重复数据大小/总数据大小)×100%.我们进行了4组模拟实验,用于讨论安全文件比例配额α和数据提取参数β对系统删重率的影响,并讨论删重率对系统执行效率的影响.其中,β用于模拟真实的应用场景,为用户分配一定数量的重复文件.
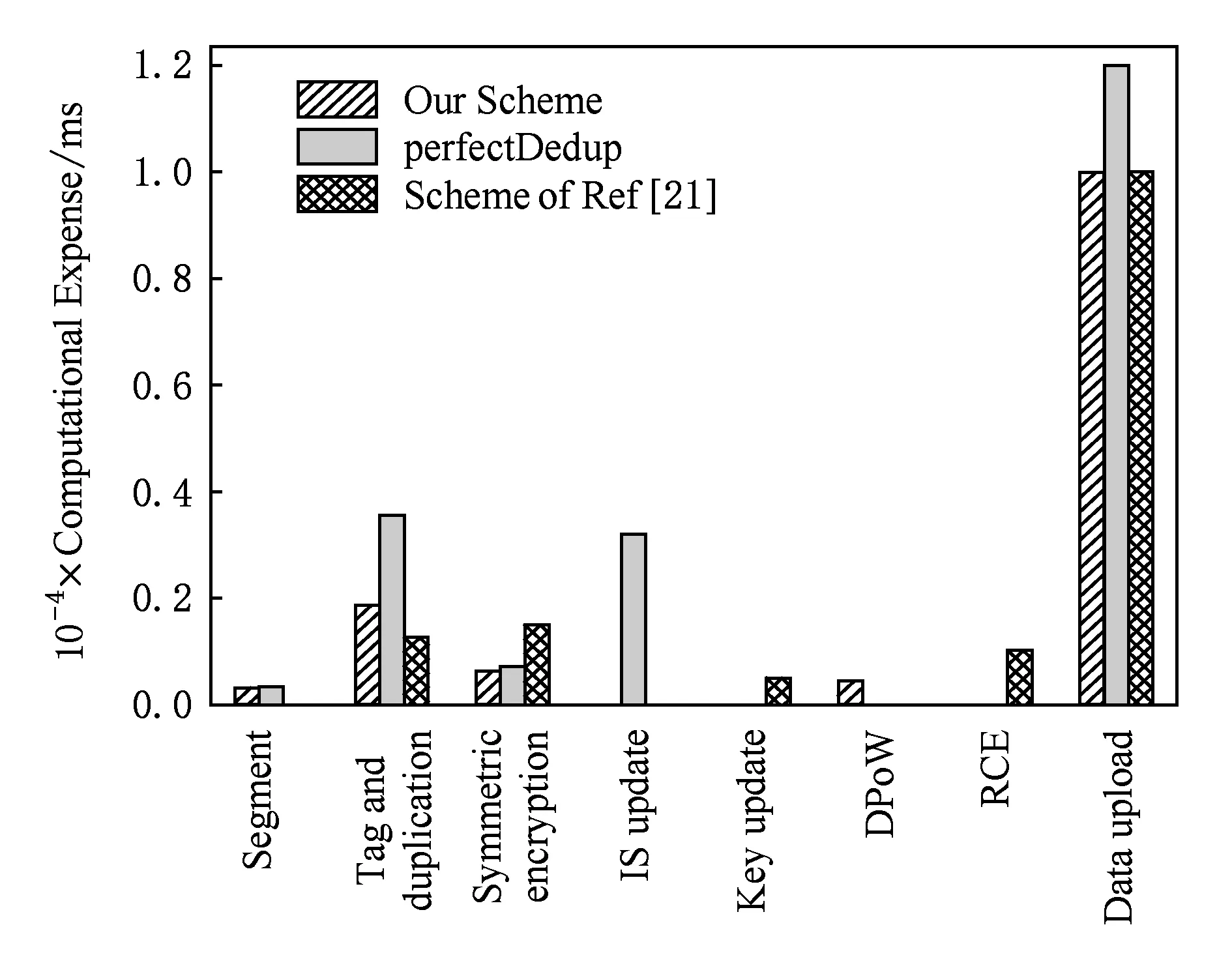
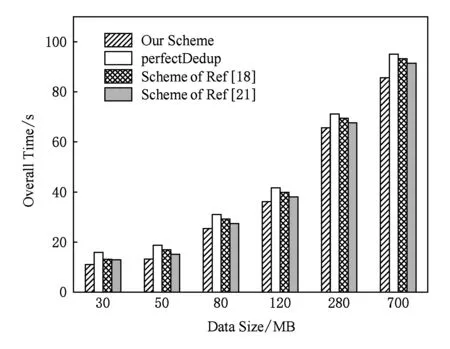
为测试文件数量n对删重率的影响,我们设定用户数量m=100,且α=0.2,基于不同取值的β,将不同数量的文件上传至云服务器,实验结果如图5所示.当n Fig. 5 Impact of file number on τ图5 文件数量对删重率的影响 我们设置α,β的取值分别为0.2和7,观察用户数量m对删重率的影响,实验结果如图6所示.文件数量一定的情况下,用户数量与删重率可视为正比关系.用户越多,系统中重复文件数量也随之增加,数据删重率越高. Fig. 6 Impact of user number on τ图6 用户数量对删重率的影响 另外,α的取值会对系统删重率产生一定的影响.当文件和用户数量一定时,α取值越大,表明上传数据中设有安全条件的数据越多,重复删除的条件更加苛刻,系统的删重率也越低,如图7所示.因此,本方案对α的取值进行了限制,仅部分文件可设定安全条件,这样既可以提高数据的保密性,又能保证系统的执行效率. Fig. 7 Impact of α on τ图7 α的取值对系统删重率的影响 为评估删重率对系统的影响,我们进行了如下实验.选取多个Linux发行版作为数据集合,本文实验中所用文件样本均选自该数据集[34].实验首先选取2个样本集合,分别包含500个大小不等、内容不同的文件.将集合1中的所有数据以初始上传者身份上传到云服务器.根据需要模拟的删重率,分别从集合1和集合2中选取部分文件,以后继上传者身份上传.计算上传每100 MB文件所需的平均时间,实验结果如表2和图8所示.当删重率较高时,所有权证明所需的时间开销较高,文件加密与上传操作较少;删重率较低时,文件加密与上传操作所占时间开销比例较大.删重率为100%时,整体时间开销约为删重率等于20%时的一半.由此,可以看出,本文设计的重复数据删除系统在文件备份系统中,既可实现较高的文件重复删除效率,也可带来较好的用户体验. Table 2 Comparison of Data Upload with Different τ表2 不同删重率对应的数据上传情况对比 Fig. 8 Impact of τ on computational expense per 100 MB data图8 每100 MB数据删除率对时间开销的影响 我们将数据上传过程分为数据分块、安全条件生成、重复性检测、所有权证明、对称加密以及数据上传6个部分.关于计算开销的实验分为2个部分,用于DPoW证明所需的时间开销以及方案整体的时间开销.为模拟真实的应用环境,我们对云服务器中的元数据进行了随机化设置,设初始列表中包含超过2 000条不同的数据元组,对应于云服务器中存储的数据块,且设定了安全条件的数据量和未设定安全条件的数据量比值约为1∶4. 5.2.1 DPoW所需的时间开销 采用t个相互独立的Hash函数作为布隆过滤器的映射函数,并对映射结果取模.t的取值对布隆过滤器的误判率存在一定的影响.若t的取值过大,则位数组BF中更多的元素被设置为1,新元素被误判的概率就越大;若t的取值过小,BF中的0就越多,将影响系统的误判率[35]. 为评估文件大小和t值对DPoW初始化操作性能的影响,我们进行了如下实验.对不同的t值,上传不同大小的文件,记录用于DPoW初始化的时间开销.实验结果如图9所示.文件规模越大,数据分块越多,将块标识和块位置的映射结果插入BF的操作重复次数越多,初始化布隆过滤器的时间开销越大.此外,对于同样大小的文件,其分块数量是固定的.t值越大,意味着需要对BF中更多的元素进行操作,因此所需的时间开销越大. 我们通过实验测算了DPoW占系统总体时间开销的比例.对不同的t,该比例均不超过5%,实验结果如图10所示.当t固定时,对于不同大小的文件,用于DPoW的时间占总体时间开销的比例十分相近.随着文件规模的增大,该比例呈减小趋势.这是因为用于DPoW质询的时间是固定的.因此,本文提出的DPoW对系统的执行效率所造成的影响是可忽略的. Fig. 9 The time used for DPoW intialization图9 DPoW初始化所用的时间开销 Fig. 10 The proportion of DPoW in total system overhead图10 所有权证明占系统总体开销的比例 5.2.2 方案的总体时间开销 通过上传不同大小的文件,测试各阶段操作所需的时间开销,实验结果如图11所示.方案将部分计算开销与实际存储操作都外包给云服务器.此外,数据分块、安全条件的生成、对称加密所需的时间开销非常小.因此相比较而言,客户端的时间开销远小于服务器端的时间开销. 尽管以数据块作为最小存储单元,云服务器存储结构中会存在部分重复项,如文件标识.但是,这能够进一步降低云服务器的实际存储开销. 我们与perfectDedup方案、文献[18]以及文献[21]对比了文件上传操作的时间开销.各阶段时间开销对比结果如图12所示,总体时间开销对比如图13所示.在数据标识生成、重复性检测阶段,本方案明显优于perfectDedup方案和文献[21],因为块级和文件级相结合的数据重复性检测方法提高了系统性能.而perfectDedup方案仅采用块级重复性检测,且引入了实时在线的第三方.文献[18]采用的同态加密和PAKE方案增加了系统执行时间.文献[21]需要由云服务器对RCE加密的密文进行外层加密,增加了系统复杂性.实验结果表明:尽管本方案所引入的DPoW产生了一定的时间开销,但整体上仍优于其他的方案. Fig. 11 Time span for each phrase of system图11 系统各阶段操作的时间开销 Fig. 12 Comparison of every phase about time span图12 各阶段时间开销对比 Fig. 13 Comparison of overall time span图13 整体时间开销对比 表3分析比较了本方案与其他代表性方案的优点和局限性. 本文研究了云存储环境中加密数据的重复删除问题,提出了基于用户定义安全条件的可验证重复数据删除方案.方案首次分析了用户数据共享控制问题,引入了用户属性,基于双线性映射扩展了数据标识,设计了数据安全条件机制.当且仅当后继上传者的安全条件与现有安全条件一致或其属性符合现有安全条件,才会发生数据的重复删除.本方案采取文件级和块级相结合的重复数据删除方法,进一步提高了系统执行效率.此外,基于安全多方计算理论和布隆过滤器技术设计了所有权证明机制,实现了对数据所有权的控制,能有效抵御来自敌手的信道监听攻击.安全性分析和实验结果表明:本方案能安全、高效地实现云存储环境中加密数据的重复删除. 实现云存储用户动态所有权控制,解决用户数据更新操作的权限管理问题是有待进一步研究的问题.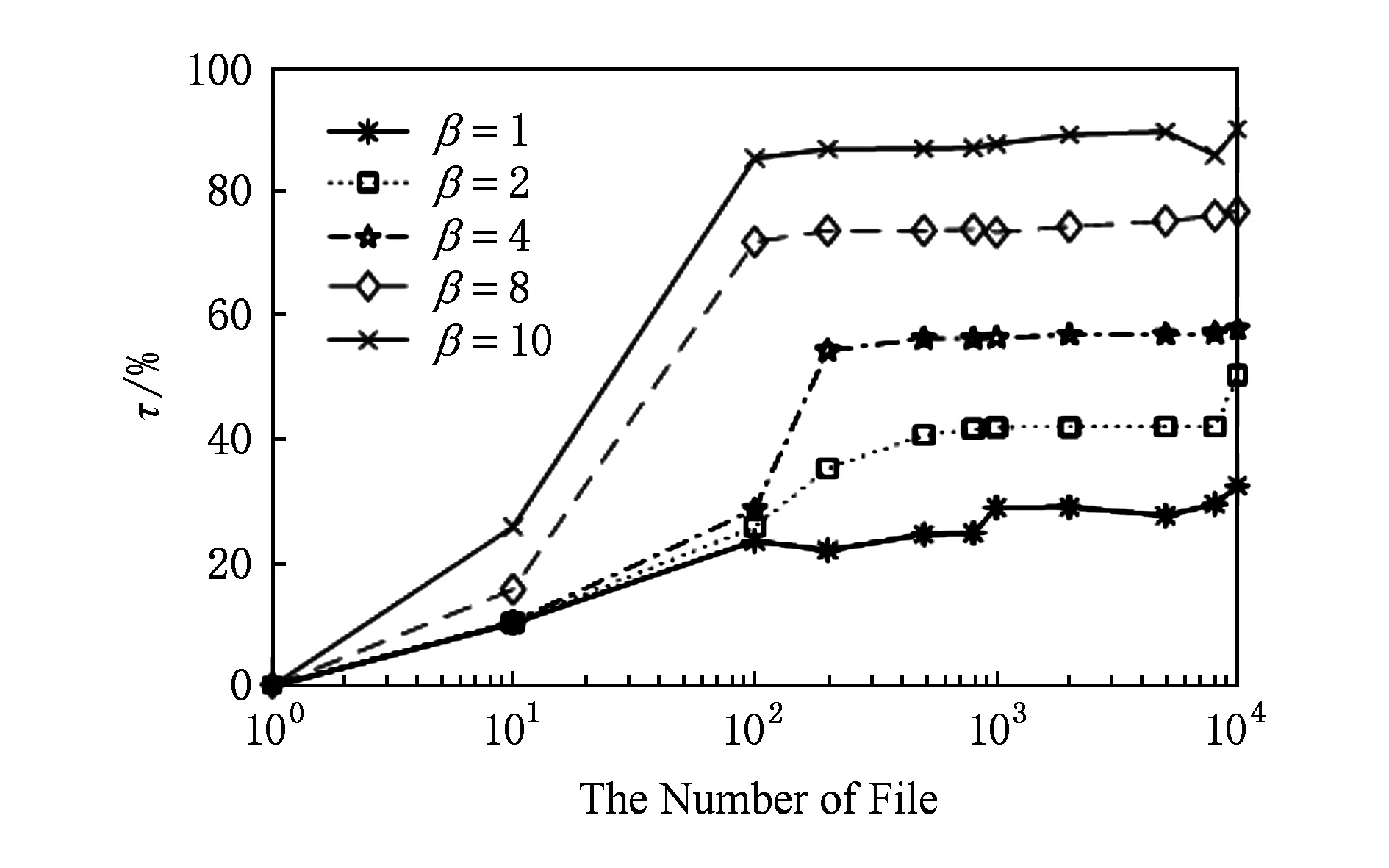




5.2 计算开销

5.3 方案特点比较
6 总结与展望
猜你喜欢
故事作文·低年级(2022年2期)2022-02-23
故事作文·低年级(2022年1期)2022-02-03
北京电子科技学院学报(2020年2期)2020-11-20
电脑爱好者(2020年6期)2020-05-26
军民两用技术与产品(2019年12期)2020-01-19
网络安全和信息化(2019年8期)2019-08-28
网络安全和信息化(2019年7期)2019-07-10
小型微型计算机系统(2018年9期)2018-10-26
中国计算机报(2018年12期)2018-10-08
课堂内外(小学版)(2017年5期)2017-06-07
