
大众媒体视野下的“健康中国”
——基于2016—2017年部分媒体报道的文本分析
2018-10-11 13:21:14姜浩然杨肖光
中国卫生政策研究 2018年9期
姜浩然* 周 萍 杨肖光
1.辽宁社会科学院社会学所 辽宁沈阳 110031
2.复旦大学公共卫生学院国家卫生健康委卫生技术评估重点实验室 上海 200032
“健康中国”是当前中国重点推进的国家级战略。健康中国的内涵极为丰富,涉及从微观层面的健康生活方式、健康服务,到宏观层面的健康保障、健康环境、健康产业以及健康治理体系等各个方面[1],带动了全国范围内围绕健康议题而开展的各项政治、经济和社会活动。健康中国建设的进程也为各级各类新闻媒体所持续关注。自十八届五中全会提出“推进健康中国建设”理念,到2016年8月全国卫生与健康大会召开及中央政治局审议通过《“健康中国2030”规划》,再到十九大正式提出“实施健康中国战略”,其间累积的大量媒体报道信息,为全景式的认识这一国家重大政策的实施进程提供了潜在的可能性。
新闻媒体是重要的信息载体、意见表达渠道和公共沟通平台。媒体在及时、准确记录事件的发生的同时,也反映了社会对于特定问题的态度。同时,媒体也承载着舆论导向的功能,在推行政策的过程中,政府也会有意识的利用媒体进行宣传和倡导。[2]在互联网与大数据时代,随着文本数据挖掘技术的突破,媒体报道的量化分析已引起研究者的重视,并广泛应用于各个领域,如金融、农业、环境等。[3]然而,在卫生与健康领域,媒体报道相关研究分析多停留在新闻传播学的角度开展的媒体报道内容分析。[4]为数不多的基于量化的舆情分析[5]则以报道频次、时间分布、关键词词频等描述方法为主,对新闻文本信息挖掘的深度有限,也一定程度上影响了分析效果。
本文将利用文本挖掘(text-mining)的手段,对2016—2017年部分综合性新闻媒体关于健康中国的报道进行挖掘与分析,探索媒体报道健康中国的内容、领域、总体性特点,进而从一个新的视角了解健康中国的政策导向、实施进展和重点领域,为政府有关部门更好的推进健康中国战略提供参考。
1 资料与方法
1.1 数据来源及预处理
1.1.1 数据采集
利用自编R语言程序,从国内有影响力的门户网站、重点报刊数字版等渠道采集部分综合性新闻报道文本。具体来源是:从新浪、搜狐、凤凰、腾讯、网易、人民网、新华网、中国新闻网等门户网站的新闻频道采集时政新闻、社会新闻、财经新闻以及新闻评论栏目的全部新闻;从财新网、新京报网、澎湃新闻网三个重要的综合性媒体网站采集各子栏目新闻;同时采集了人民日报、光明日报、中国青年报三家重点报刊数字版的全部新闻,并去除国际新闻、娱乐新闻、体育新闻、广告等栏目。新闻采集时间范围为2016年1月1日—2017年12月31日。共获取新闻文本总数5 343 966篇。需指出的是,本文数据来源全部为综合性新闻媒体,并未纳入《健康报》、《健康时报》等专业健康媒体。部分由于网站限制采集原因,同时也考虑到专业健康媒体可能会对数据整体分布造成影响。
1.1.2 数据筛选、过滤与分词
采集到的原始新闻文本保留“标题”、“发布时间”、“来源”和“正文”四个字段作为分析的基础数据。首先以词典规则的方法[6]筛选出与健康中国相关的媒体报道①词典规则法即根据若干关键词在文档中出现的频次与位置赋分,并以特定阈值为限进行文本筛选或归类的方法。,具体方法是:
(1)筛选出标题和正文中出现“健康中国、全民健康、健康融入所有政策”中任意一个关键词的报道文本,作为初筛结果,共计13 630篇新闻。
(2)根据“健康中国、全民健康、健康融入所有政策”三个关键词在新闻报道中的出现位置,对初筛新闻进行打分。经人工测试后确定的赋值规则为:如果任意关键词出现在标题位置则权重为6,出现在文本首段权重为3、非首段的首句权重2、非首段非首句权重0.6,按出现次数加权后加总得出主题得分。
(3)由于部分报道可能间或出现上述关键词,但其报道本身与健康领域无关(如财经新闻),故本文拟定了若干健康领域的关键词②健康领域关键词为:医疗、医保、卫生、医药、医院、医生、健康、疾病、治病、医药、医疗保险、医疗保障、健身、健康产业、养老、医改、病人、患者、卫计委、诊疗、医务、医学、寿命、控烟、吸烟、食品安全、残疾、中医、老年、疾控、老龄、慢病、慢性病、疫苗、疫情、用药、防治、保健。,这些领域词表中的任一词在正文中出现一次计0.05分,加总后作为领域得分。主题得分与领域得分相加得到文档总分。经作者人工判断并讨论后,确定得分2.5分以上的入选,共计10 308篇。
(4)由于热点新闻可能会被不同的网站多次转发,故本文利用文本相似度计算的方法[7],对新闻正文进行了去重处理,剩余新闻6 999篇。作为文本分析的数据源。
1.1.3 文本分词及预处理
对于6 999篇报道,在保留标题、发布时间、来源字段不变的前提下,利用R语言jiebaR工具包[8]将新闻正文进行分词处理。分词工具中加入自编词库,避免一些专有词汇(如“健康融入所有政策”)被错误拆分。分词后的文本去掉“的、我”等单字停用词、数字和英文字母,词语最小长度保留为两字,最终形成用于描述分析和主题模型分析所用的语料数据。
1.2 数据分析
1.2.1 文本词频分布的描述分析
数据分析同样使用R语言相关工具包完成。首先描述新闻在月度时间序列的分布情况,以及媒体来源统计,对本文所分析的新闻文本集合进行整体描述。文本关键词及其词频识别与计算是文本挖掘内容的重要方法[9],本文利用词频—逆文档频率(TF-IDF)方法[10]筛选出新闻文本中的高频关键词,并描述高频词的时间序列分布情况,以此发现媒体报道健康中国的聚焦点及其随时间的进展变化。
1.2.2 基于LDA主题模型(Topic Model)的文本挖掘
本文运用主题模型(Topic Model)方法对6 999份已经分词的文本进行自动分类,尝试发现健康中国相关新闻报道中不同侧重点和方向。主题模型(topic-model)[11]是文本挖掘的重要进展,可以通过无监督类机器学习算法,依据给定的主题数量对文档进行自动分类。该模型假设,整个文档集合中存在若干个主题(topic),每一个特定主题由文档中包含的词汇以不同的概率定义出来,而每一篇特定文档(document)中与某个主题的相关程度也是不一样的。模型拟合的结果之一是展示某一特定主题所关联的高频词及其从属于该主题的概率,通过列举高概率词语组合,可以判断出该主题的内容。[12]此外,主题模型的拟合还可以实现按主题将文档聚类的效果。本文选择主题模型中最为常用的LDA(Latent Dirichlet allocation)模型[12],利用 R语言 topicmodels工具包作为具体工具,对新闻语料进行主题识别。主题数量在运行模型前由研究者自行确定。尽管在理论上可以用 perplexity[13]或 coherence[14]指标评估主题区分效果,进而确定合适的主题数量,但在实际研究中,通常做法是参考相关指标,通过人工审读方式确定主题数量。故本文将在参照perplexity指标的基础上,以人工判断的方式,选择分类效果最好的主题数量作为结果,详见结果部分。
2 结果
2.1 报道分布情况
2.1.1 时间趋势分布
图1是2016年1月—2017年12月关于健康中国报道数量的时间分布趋势(以未去重的13 630篇新闻计算),从中可以看到,健康中国的报道力度与全国“两会”、全国卫生与健康大会、中共十九大等事件密切相关。

图1 月度健康中国相关新闻报道量分布
2.1.2 报道来源分布
从媒体来源上看,经过去重的6 999篇报道来自超过500家国内信息来源,形式以报纸和新闻网站为主,同时也有少量来自政府网站、新媒体、自媒体的信息被报纸和网站所转载。表1列举了报道超过50篇以上的媒体名称。
2.2 词频分析
本文统计了健康中国报道的关键词及其分布情况,以原始词频和TF-IDF加权得分分别统计。原始词频,即特定词语在报道正文中出现的次数,能够在一定程度上表现出新闻报道用语的特点。表2是前32位原始词频表,图2是相应的前60位的原始词云图,可以看到,“健康”与“发展”是涉及最多的词语,而“推进”、“建设”、“改革”、“促进”、“实现”、“加快”等表示政府行动的词语也频繁出现。
而TF-IDF得分则能够反映出词语在报道文本中的相对重要程度,能够更好的反映出报道的主题和聚焦点。表3是TF-IDF得分前32位的高频词表,图3是与之相应的前60位的高频词TFIDF得分的词云图,如医疗卫生方面(中医药、医疗、医院、卫生、患者、医生等),体育健身方面(体育、活动、全民健身、运动等),健康管理方面(健康体检、营养、居民等),以及健康产业方面(健康产业、企业、产业等),更多的反映出健康中国的内容。

表1 媒体来源与报道数量
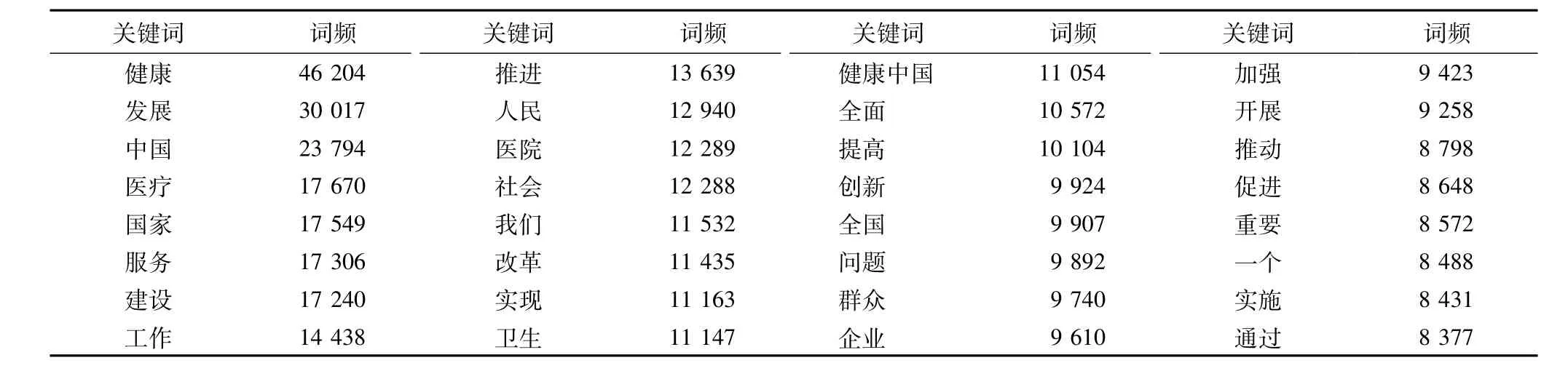
表2 报道中出现的热点词汇及词频(原始词频)

表3 报道关键词及其TF-IDF得分

图2 报道热点词汇词云图(原始词频)
2.3 主题模型分析
根据主题模型分析的一般步骤[12],作者分别设定了5~25个主题数量,分别生成不同的主题分类组合。在对分类结果分别进行人工审阅后发现,主题数量设定为19的情况下,分类效果最为明显,能够较好的反映出健康中国报道的不同方面。其中,表5中的6个主题类别与医疗卫生相关,表6中的主题与民众的健康生活相关,表7则是健康产业相关主题。另外,还剩余一些相关性不明显的主题,也一并列出。

图3 报道热点词汇词云图(TF-IDF得分)
2.3.1 医疗卫生类主题
医疗卫生类主题是健康中国报道中最重要的主题类别。表5列出了医疗卫生类中不同主题词概率得分在前15位的词,以及该类别下新闻文档的数量。其中主题1是与医药卫生体制改革相关的报道,从中可以看到医疗、医保、家庭医生、分级诊疗等当前国家医改重点推进的政策领域。这一主题类别下的有报道659篇,也是所有主题中最多的。主题2是医疗服务相关的话题,围绕医生、患者、疾病等议题展开。主题3是医学教育和医学人才培养的话题。在当前医学人才需求增加、医患矛盾突出等背景下,这一话题也是媒体报道和讨论的热点。主题4与医学科技创新、国际合作等议题相关。健康中国建设以科技创新为重要推动力,同时也为科技发展和成果转化提供了重要平台。此外,该主题还提示了十九大以来愈加重要的“全球健康”议题。尽管在前15位关键词中体现的不明显,但是该主题的文档集中也纳入了诸如习近平总书记访问世界卫生组织、全球健康促进大会在上海召开、中国与东盟、非洲国家地区的卫生合作等新闻报道。主题5是中医、中药相关的话题,也说明中医药以及中国传统医学文化在健康中国建设中的重要地位。主题6是与公共卫生和疾病控制相关的话题,包括了疾病预防、妇女儿童保健、残疾人、农村地区等公共卫生的重点领域。

表5 医疗卫生类相关主题及关键词
2.3.2 健康生活类主题
表6中的主题与民众的健康生活更加密切。其中主题7是营养与健康生活方式相关的话题,包括饮食、运动、常见疾病知识等。主题8的体育健身也是健康中国的重要内容,其中可以看到从日常锻炼、广场休闲到专业体育赛事等各种类别的体育健身在报道范围中。主题9涉及到健康科普宣传等活动,一定程度上反映了政府和社会开展健康知识宣传、提升民众健康素养的行动。主题10是食品安全相关话题。主题11则是健康中国的另一个重要话题——养老。

表6 社会生活类主题及关键词

(续)
2.3.3 健康产业类主题
表7中的主题与健康产业相关。主题12首先提及的企业、市场、产品等主要关键词,说明当前健康产业发展的积极态势。也可以看到互联网、(人工)智能等最新的科技进展在健康产业(如健康管理)中的重要作用。主题13和主题14分别代表了健康保险和生物医药这两个健康产业中的重点领域。前者连带着金融、投资等健康产业的拓展领域,而后者则与上市、集团化等资本运作相关。主题15则涉及到市场与投资环境的治理、制度建设等。而农业和农村的话题也在这个主题下出现。主题16则提到了边疆和少数民族地区的报道,特别是健康体检相关话题,也显示出健康中国在边疆和少数民族地区实施过程中的特点。
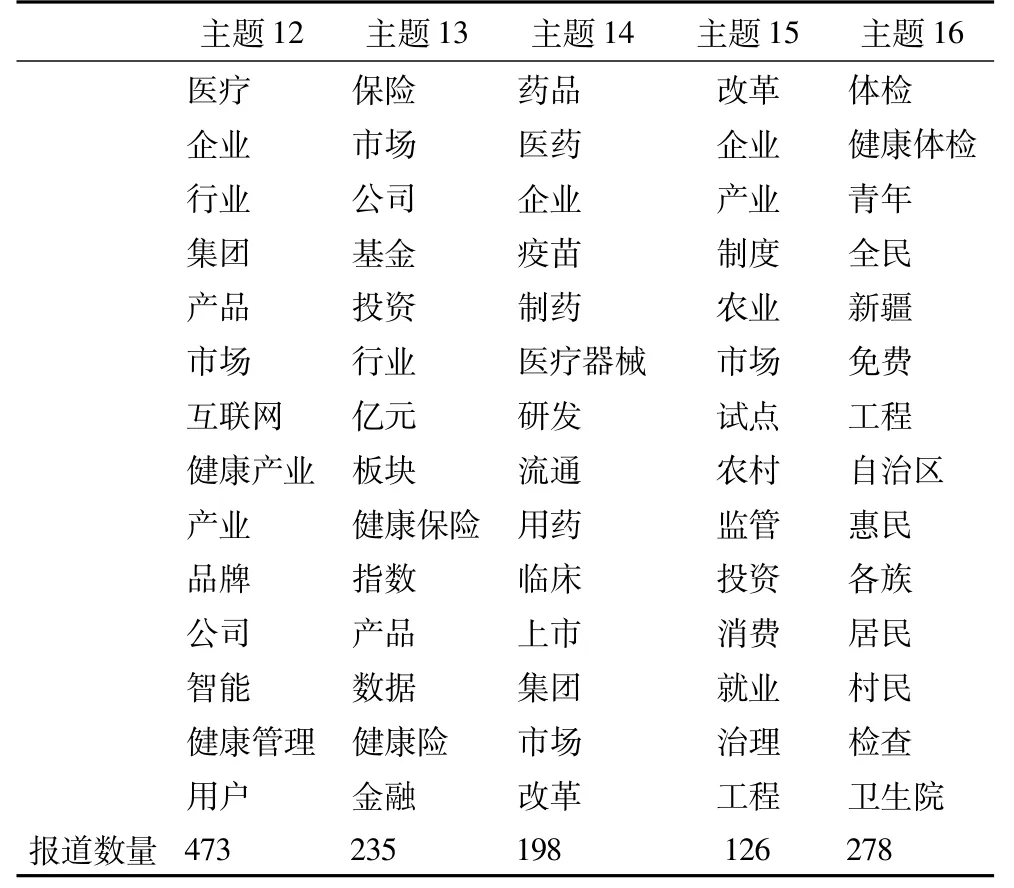
表7 健康产业类相关主题及关键词
2.3.4 其他类别主题
此外,模型中还归类了其他3个主题,大多为国家领导人讲话或重要政策文件,以及宣传落实党的精神的新闻报道(表8)。这些政治类的报道大多是综合性的,涉及经济社会各个方面,健康中国有时仅作为一个话题在其中提及,因此在主题关键词上体现的不是很明显。而且由于是无监督的自动机器学习,主题19也出现了主题混淆的现象。
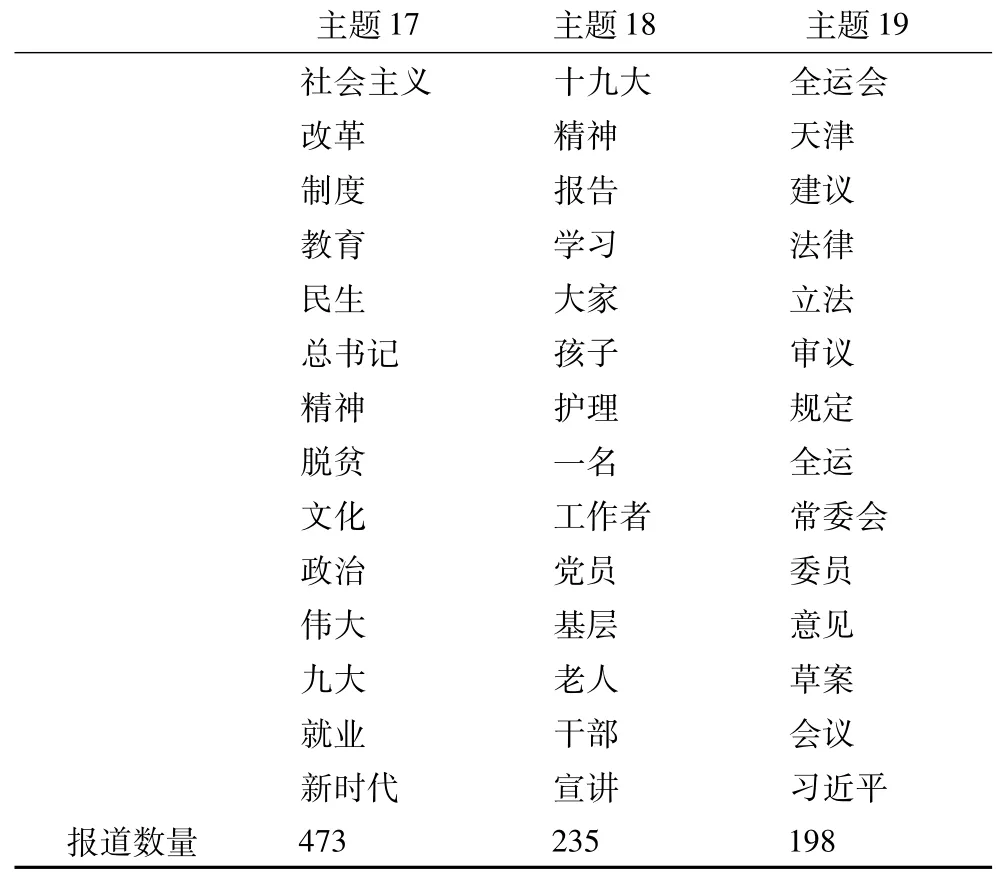
表8 其他主题及关键词
3 讨论
3.1 健康中国的媒体呈现特点
3.1.1 健康中国在媒体中占有重要位置
首先,从分析结果上看,健康中国作为国家宏观战略,始终保持着高度的媒体关注度,并且还在持续的上升。健康中国在媒体中的重要性可以从报道的时间与来源分布中凸显出来。从报道的时间分布上看,在媒体报道集中的时间段内(如两会、十九大、全国卫生与健康大会),健康中国的报道也呈现明显的多发趋势,这也在一定程度上反映了媒体对于健康中国议题的关注度。从媒体报道来源可以看到,人民网、中国新闻网、央广网、新华社、人民日报等国家级媒体是健康中国新闻报道的最重要主体,这也充分体现出了当前国家级媒体在宣传健康中国政策过程中的重要作用。
3.1.2 健康中国媒体报道领域广泛、内容丰富
无论是词频分布分析还是主题模型分析,都可以看出健康中国报道分布在不同领域,媒体报道的内容与健康中国的政策要点能够基本呼应。且不同类别中文档的分布数量相对平衡,体现出较好的区分情况。这也说明本研究中的报道文本能够相对全面和完整的覆盖健康中国的各个方面。同时,不同领域也呈现出各自特点,如医改和医疗卫生体制问题作为健康中国建设中的核心问题,仍然受到媒体的大量关注。食品安全主题(主题10)一方面反映出媒体和公众对于食品安全问题高度的关注程度,另一方面也体现了政府在食品安全监管的重视,以及对相关违法行为的打击。而主题1中,养老与“产业”、“项目”等词语关联起来,也反映出当前养老向产业化和社会化方向的发展态势。
3.1.3 健康中国的媒体报道态度趋向正面
虽然本文未做专门的文本情感分析(sentiment analysis),但从关键词的罗列中可以发现,媒体报道的健康中国相对正面和积极,“问题”、“矛盾”等负向的词语几乎没有在高频词中出现。这也说明,健康中国作为一项普惠性的国家政策,并未在媒体和社会中引起太多争议。一方面,国家借助媒体为政策的推进营造良好的舆论氛围,另一方面,媒体也对于健康中国政策持积极态度,这都使得健康中国的报道在态度上较为正面。
3.2 文本挖掘方法在卫生政策研究中具有巨大潜力和价值
从方法学角度看,本研究是利用计算机辅助技术,从大规模非结构化文本中提取健康政策信息的一次尝试,体现出了文本挖掘方法在卫生政策研究中的巨大潜力。文本挖掘方法的价值首先在于海量信息的处理能力。如前所述,健康中国是一个内涵极为丰富的国家战略,相关信息的处理要求已经超出传统的定性内容分析方法的能力范围,而这也恰恰是计算机辅助技术的优势所在。同时,文本挖掘的结果也可以为进一步的研究提供线索。如对于关键词及其时间趋势分布的分析,能够对政策进程中的重点和热点问题起到提示作用,便于进一步探索。主题模型本身在实现主题聚类的同时,也能够有效的实现新闻文本的筛选和分类,有助于开展常规的基于人工阅读与编码的内容分析。
当然,本文只是从文本挖掘的角度,从媒体报道的视角展示健康中国的整体进展。这当然无法反映健康中国的全貌,也不涉及效果评估或经验总结。但分析结果也提示媒体报道能够及时的反映出健康中国政策的内容及其进展,进而成为认识和解读这一国家政策的潜在且有效的证据来源。随着数据的积累、方法的进步,相关研究工作将具有很好的政策价值与前景。
3.3 本研究的局限
作为一种新的尝试,本研究也存在一定的不足,主要体现在研究方法的精细度方面。新闻文本属于高度非结构化的数据,固然TF-IDF、LDA主题模型等机器学习方法在挖掘文本信息方面较传统的基于统计规则的方法有所深入,但分析结果的呈现仍相对简单。特别是新闻背景、报道时间、新闻类别、来源分类等重要的文本属性信息也并未在分析中体现。近年来,在文本挖掘的前沿研究中,文本属性信息纳入主题模型分析已经有了很多进展[15],而以词向量方法为代表的深度学习方法在自然语言处理领域的突破[16],也使得文本内在的语义关系分析成为可能。这些技术方法与新闻文本数据的进一步结合,也将进一步增强基于海量数据进行卫生政策研究的能力。
作者声明本文无实际或潜在的利益冲突。
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
制造技术与机床(2019年10期)2019-10-26 02:48:08
电子制作(2018年18期)2018-11-14 01:48:06
瞭望东方周刊(2016年33期)2016-09-08 17:40:48
小学教学参考(2015年20期)2016-01-15 08:44:38
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
图书馆论坛(2014年8期)2014-03-11 18:47:59
语文知识(2014年1期)2014-02-28 21:59:13
