
网络环境下集体智慧领域知识模型构建
2018-10-10 02:19:28孔垂禹张赛男
吉林大学学报(信息科学版) 2018年5期
孔垂禹, 岑 丹, 张赛男
(1. 吉林大学 a. 大数据和网络中心; b. 图书馆, 长春 130012; 2. 吉林财经大学 新闻与传播学院, 长春 130117)
0 引 言
随着信息化技术的迅速发展网络个性化教育己经成为教育行业的一个重要部分。网络个性化学习打破了时间、 空间的限制, 吸引众多不同文化背景、 不同年龄层次的学习者。领域知识模型作为个性化学习系统中重要组成的部分, 是对学科领域知识的高度浓缩及结构化、 系统化的抽象表达, 在整个个性化学习系统中起到至关重要的作用, 因此, 越来越受到国内外学者的普遍关注。在20世纪60年代, 斯坦福大学的费哥巴姆教授团队成功研制出以化学学科为研究对象的DENDRAL专家系统, DENDRAL专家系统的研制开创了领域专业知识模型研究的先河[1]。Jonassen[2]提出了概念间的关联以网状结构进行组织知识的结论, 并以此为指导构建跨学科领域知识模型的有效途径。Singh等[3]提出了利用社会网络聚合信息的方法,指出利用社会网络聚合领域知识模型的新范式。Chen等[4]以e-learning学科领域文献资源为样本, 提出运用数据挖掘技术自动挖掘领域知识模型的方法, 实现了e-learning领域知识模型的构建。张会平等[5]提出利用词共现概念图的方法构建领域知识模型。陈庄等[6]提出从大量数据资源中自动挖掘认知图, 通过构建概念矩阵运用神经网络算法挖掘出概念间因果关系的方法构建领域知识模型。丁华等[7]提出基于粗糙集扩展模型的采煤机设计领域知识获取方法。夏火松等[8]提出利用线上商品评论有效性分类构建专业领域知识模型的方法。虽然目前国内外学者在化学、 情报学、 信息科学等多个领域, 对领域知识模型的概念界定、 构建方法、 运用工具等方面已经做了大量深入的研究, 并取得了一定的成果[9-12]。然而, 在领域知识模型构建的研究中, 还存在如下几个方面的问题有待深入研究。首先, 领域知识模型的构建是一项浩大的工程, 领域概念提取难度大、 数据挖掘复杂导致目前国内外相关研究人员往往趋向于利用人工智能技术构建领域知识模型。其次, 目前的领域知识模型的构建, 主要关注如何利用人工智能、 数据挖掘和本体等技术实现领域知识模型的构建, 忽视了人的主动参与在领域知识模型的构建中的重要作用, 及人与人交互产生的集体智慧对领域知识模型的构建的影响。
鉴于此, 笔者阐述了领域知识模型主要建模标准, 提出了领域知识模型建构参考规范, 并以联通主义学习理论为指导, 关注学习者个体行为、 主动参与及学习者共同参与生成的集体智慧, 在领域模型构建中的重要作用。由个体领域知识模型构建出发, 将个体领域知识模型聚合为集体领域知识模型, 实现知识点与知识点间的联结。集体领域知识模型又影响个体领域知识模型, 实现个体领域知识模型的优化, 进而完成领域模型的构建与优化。依靠人本身强大的语义理解与处理能力, 构建领域知识模型, 并对其进行评价与选择, 而不仅依靠计算机相关算法处理判断语义, 干涉领域知识模型构建。对个人与集体知识体系的建设具有很强的借鉴和指导意义。
1 领域知识模型建构参考规范
笔者参照IEEE LOM、 Dublin Core、 CELTS-3等, 相关学习对象元数据标准, 设计个性化学习系统中领域知识模型建构参考规范, 具体如图1所示。
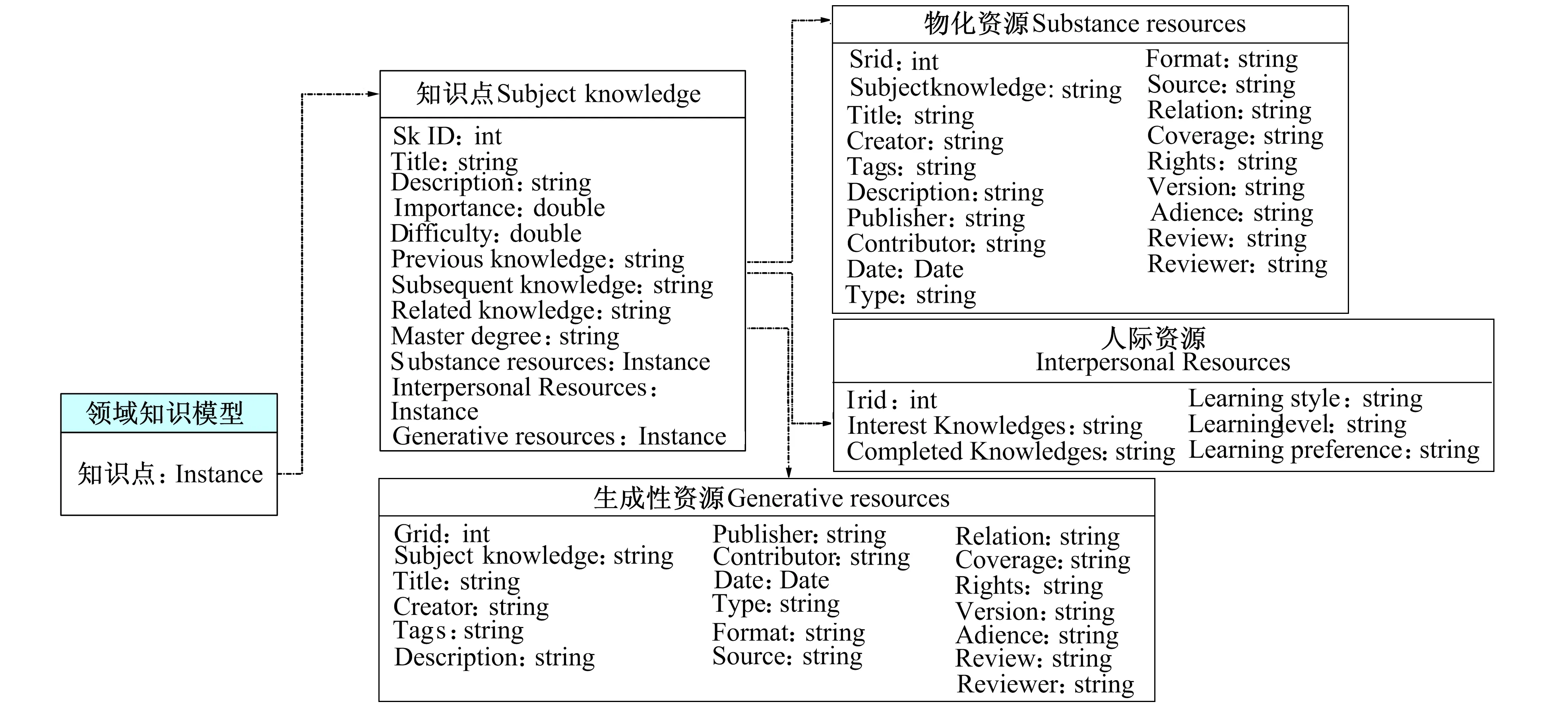
图1 领域知识模型建构参考规范Fig.1 Domain reference model specification
由图1所示, 笔者提出的领域知识模型是由知识点组成, 知识点与个性化学习系统中的物化资源、 人际资源、 生成性资源关联, 形成一对多的映射关系。
2 集体智慧视域下的领域知识模型构建
将领域知识模型分为个体领域知识模型和集体领域知识模型, 个体自主构建个人知识结构网络, 实现个体领域知识模型的构建。同时, 通过聚合计算, 将个体建构的个体领域知识模型聚合成集体领域知识模型, 聚合后的集体领域知识模型反馈给个体领域知识模型, 又为个体优化个体领域知识模型提供了有力支持。具体如图2所示。
1) 个体领域知识模型构建。学习者在自己的空间建构个体领域知识模型,学习者个人对自己的领域知识模型进行知识节点与知识节点间关联关系的编辑, 即知识节点的添加、 修改和删除, 知识节点间关联关系的建立、 修改、 解除。并以某个感兴趣知识点为中心, 向四周扩散, 到下一知识点(一级节点), 由其再扩散到下一知识点(二级节点), 以此类推, 到第N级节点。具体如图3所示。
因此, 个体领域知识模型可以抽象为知识点, 及知识点与知识点之间的关联关系。这样, 学习者m的个体领域知识模型可以表示为Dm(Um,Rm),Dm表示个体m自主建构的个体领域知识模型, 其中Um表示个体m建构的知识点集合,Rm表示知识点之间的映射关系。
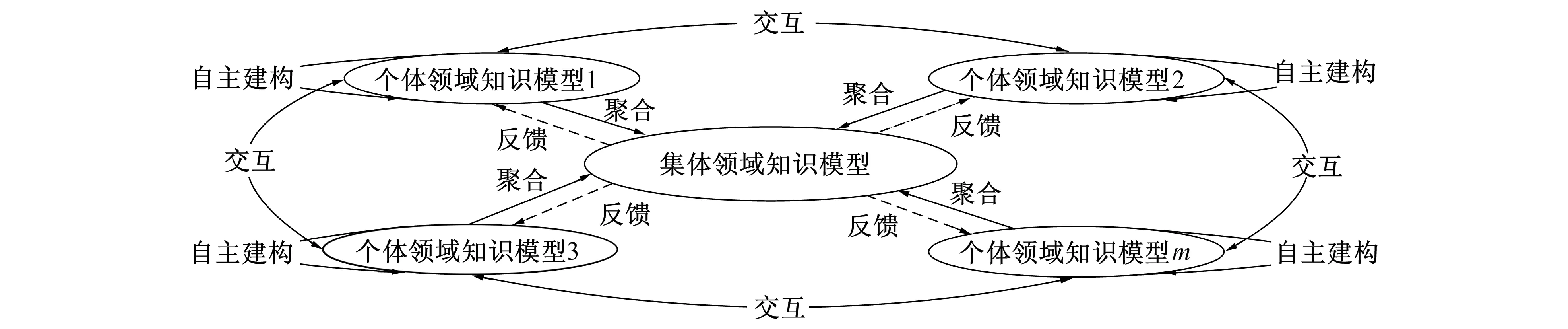
图2 个体领域知识模型与集体领域知识模型Fig.2 Individual domain knowledge model and collective domain knowledge model

图3 个体领域知识模型Fig.3 Individual domain knowledge model
2) 集体领域知识模型构建。集体领域知识模型构建是指将个人自主建构的个体领域知识模型, 通过聚合算法, 生成集体领域知识模型。它是每个个体学习行为的宏观呈现, 这种聚合不是个体领域知识模型中的知识点与知识点, 及知识点间关系的简单累加, 而是反映了学习者之间交流与协作后, 产生的集体智慧, 对集体领域知识模型构建的影响。
基于集体智慧的领域模型构建的核心是将个体领域知识模型聚合为集体领域知识模型, 是将个体智慧聚合为集体智慧的重点所在。虽然, 在开放学习环境下, 每个个体学习行为是独立的、 多元的、 主观的, 但在集体学习行为上呈现了集体的整体知识架构, 而且这种集体领域知识模型会随着个体领域模型的变化而变化, 二者交互、 相互影响、 共同发展。
因此, 笔者研究中的集体领域知识模型是以个体领域知识模型为基础, 依据学习者的学习行为,激励学习者主动参与, 充分发挥集体智慧, 依靠人本身强大的语义理解与处理能力, 聚合集体领域知识模型, 并对其进行评价与选择, 而不是通过计算机相关算法处理判断语义, 干涉聚合结果。具体聚合步骤如图4所示。
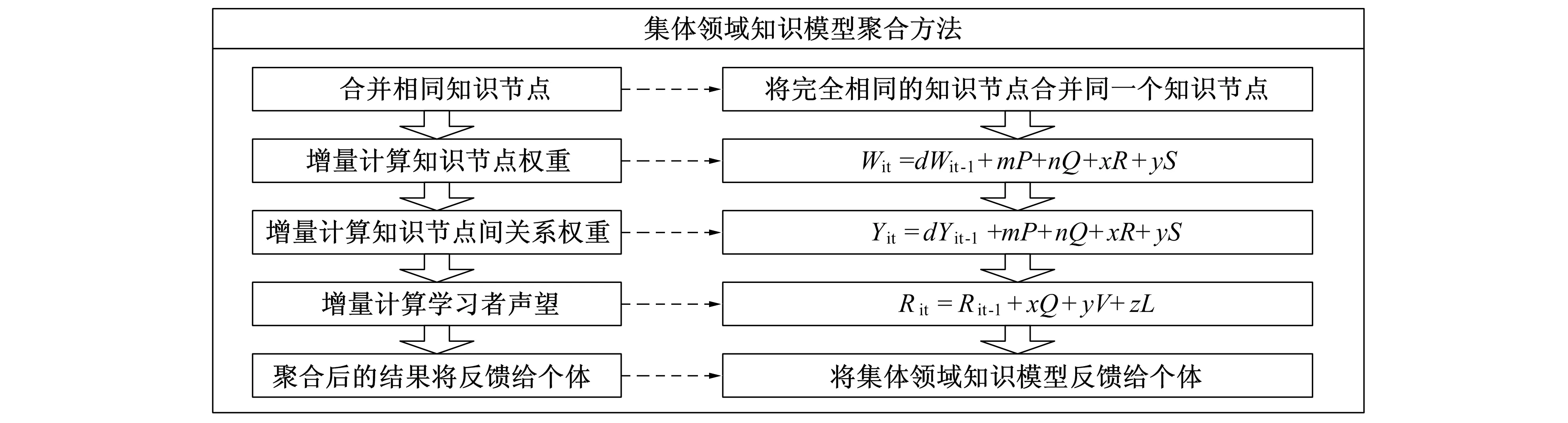
图4 集体领域知识模型聚合方法Fig.4 Collective domain knowledge model aggregation method
1) 合并相同知识节点。将两个或两个以上完全相同的知识节点合并成同一个知识节点, 并记录“源”知识节点的相关信息。通过学习者参与, 发挥“人”的语义理解与处理能力, 对知识节点进行语义分析, 并通过“集体”的力量促成共同语义的达成, 将语义相同的知识节点, 判断为相同知识节点后, 合并相同知识节点。同时, 个体在编辑个体领域知识模型时, 推荐相似的知识节点名称, 促进相同语义的收敛。具体如图5所示。
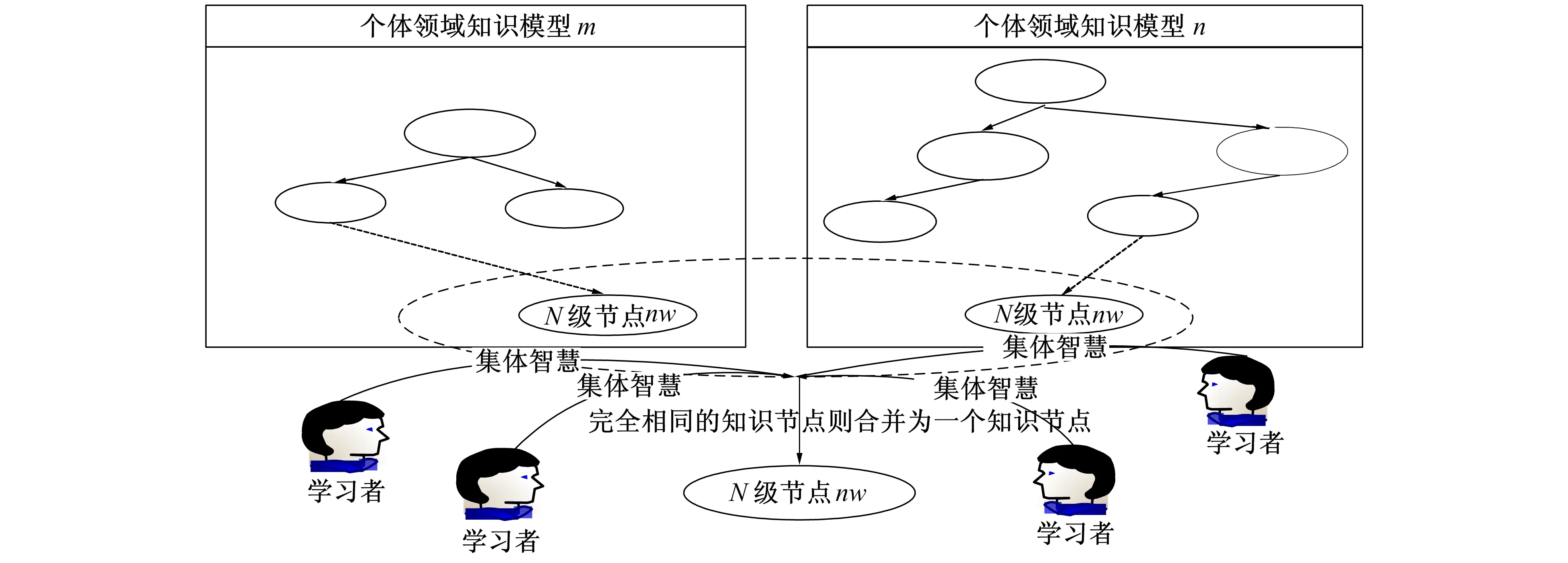
图5 知识节点合并Fig.5 Merging of knowledge nodes
2) 增量计算知识节点权重。增量计算是指上次聚合至本次聚合之间所发生的变化, 包括个人对个体领域知识模型的操作(添加、 修改、 删除)和个体对集体领域知识模型的操作(浏览、 引用、 好评)。即
Wit=dWit-1+mP+nQ+xR+yS
其中Wit为t时刻知识点i的权重;d为时间衰减因子;Wit-1为t-1时刻知识点的权重;m为好评操作权重系数;P为对该知识点得到好评的人数之和;n为浏览操作权重系数;Q为浏览过该知识点的人数之和;x为引用操作权重系数;R为“引用”该知识点的学习者人数减去之和, 引用后删除该知识点的学习者人数之和;y为学习者可信度权重系数;S为创建该节知识点的学习者可信度之和, 减去删除该知识点的学习者可信度之和。
知识点的权重会因学习者参与而发生动态变化。由于先建立的知识节点, 积累权重的时间较长, 而后建立的知识节点, 积累权重的时间较短, 因此, 需要通过时间衰减因子d, 降低先建立的知识点的权重。并且, 学习者的可信度及各种行为(引用、 好评、 浏览), 对聚合知识点的权值也有着不同程度的影响。
3) 增量计算知识节点间关系的权重。节点与节点之间关系(连线)代表着个体的认知路径, 和节点聚合是类似的,若多个学习者拥有相同路径,在聚合后的集体领域知识模型中会有较大的权重。则有
Yit=dYit-1+mP+nQ+xR+yS
其中Yit为t时刻节点间关系i的权重;d为时间衰减因子;Yit-1为t-1时刻节点间关系的权重;m为好评操作权重系数;P为对该知识点得到好评的人数之和;n为浏览操作权重系数;Q为浏览过该知识点的人数之和;x为引用操作权重系数;R为引用该知识点的学习者人数减去之和, 引用后删除该知识点的学习者人数之和;y为学习者可信度权重系数;S为创建该节知识点的学习者可信度之和, 减去删除该知识点的学习者可信度之和。
学习者可信度高低和创建该关系的学习者的数量决定了关系创建的权值大小。添加的知识点越多,创建该关系的学习者的数量越大,关系创建的权值就会越高。一个关系被引用的越多,引用的权值也会越大。好评也表现了学习者对知识点相关的赞同度。浏览行为反映了学习者对相关知识点使用的频繁度,浏览权值越高,表示学习者的关注度越大, 对领域知识模型的贡献程度也越高。
4) 根据学习者的行为, 增量计算学习者可信度。学习者可信度反映的是学习者对集体建构贡献的程度, 学习者创建的知识点, 知识点间关系被其他学习者引用、 浏览、 好评的越多, 该学习者所建构的个体领域知识模型, 对构建集体领域知识模型的贡献也就越大,该学习者的可信度也会越高。即有
Rit=Rit-1+xQ+yV+zL
其中Rit为当前时刻t, 个体i的可信度;Rit-1前一时刻t-1, 个体i的可信度;x为引用权重系数;Q为个体i的个体领域知识模型被引用的次数;Y为好评权重系数;V为个体i的个体领域知识模型被好评的次数;Z为浏览权重系数;L为个体i的个体领域知识模型被浏览的次数。
5) 将聚合后的结果反馈给个体。将聚合后的集体领域模型及时反馈给学习者, 供学习者再次建构个体领域模型时使用, 进而影响再次聚合的集体领域模型, 如此循环, 实现个体领域模型与集体领域模型持续进化与扩展。
经过上述步骤, 形成个体领域知识模型和集体领域知识模型, 实现知识点与知识点间的关联, 如图6所示。
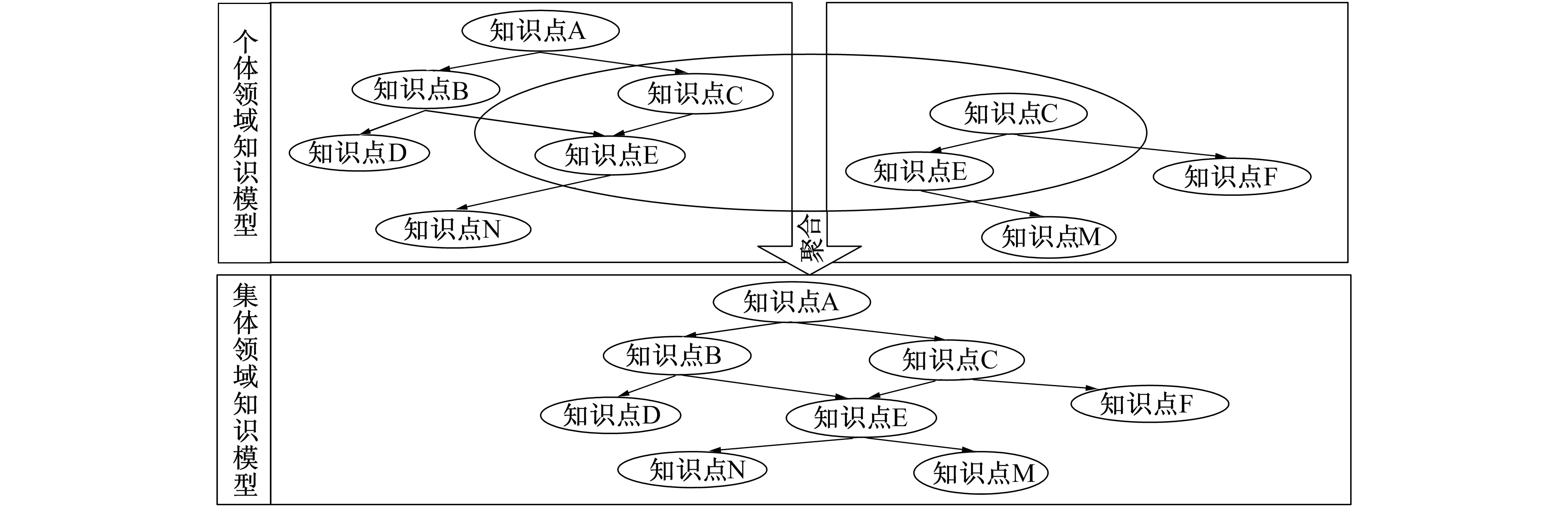
图6 知识点与知识点间的关联Fig.6 Correlation between knowledge points and knowledge points
图6中个体领域知识模型i包含知识点A, 知识点B, 知识点C, 知识点D, 知识点E, 知识点N。个体领域知识模型j包含知识点C, 知识点E, 知识点F, 知识点M。个体领域知识模型i与个体领域知识模型j拥有相同知识点C和知识点E, 在集体领域知识模型构建中, 将相同知识点C和知识点E合并, 同时依据集体领域知识模型聚合算法, 得到集体领域知识模型, 该模型包括知识点A, 知识点B, 知识点D, 知识点F, 知识点N, 知识点及合并后的知识点C和知识点E, 各知识点间的关联如上图所示。最终形成个体领域知识模型和集体领域知识模型, 实现知识点与知识点间的关联, 为个性化学习系统提供强有力的支撑。
3 应用与评价
笔者通过使用FLEX技术, 开发领域知识模型构建模块, 该模块以知识点为概念节识节点的添加、 修改、 删除及知识点的关联, 以概念图的形式展现知识点的结构体系。
图7 领域知识模型构建平台Fig.7 Domain knowledge model building platform
基于该平台设计相关实验, 用以验证该模式的有效性。本实验在2015级吉林大学大一新生中抽取200人, 进行为期一年的实验。同时邀请了吉林大学计算机基础实验室的20位专业教师, 作为领域专家, 组成专家小组。对领域知识模型的有效性进行评价。对最终形成的集体领域知识模型进行分析, 结果显示, 当学习周期结束, 由个体领域知识模型聚合而成的集体领域知识模型包含了该课程所有的知识点, 且知识结构与教学大纲基本符合, 可见, 虽然每个个体在学习过程中, 开始和结束的节点不同, 关系存在差异, 但在集体层面, 知识的关联存在趋同的趋势。因此, 笔者提出的集体智慧视域下的个性化学习系统中领域知识模型构建方法是合理有效的, 具有较高的应用与推广价值。
4 结 语
当今科学技术的迅速发展促使学科领域的分支更加细化, 学科领域知识之间相互渗透的现象日益明显。本文阐述了领域知识模型主要建模标准, 提出了领域知识模型建构参考规范, 关注学习者个体行为、 主动参与及学习者共同参与生成的集体智慧, 在领域模型构建中的重要作用, 由个体领域知识模型构建出发, 将个体领域知识模型聚合为集体领域知识模型, 实现知识点与知识点间的联结, 集体领域知识模型又影响个体领域知识模型, 实现个体领域知识模型的优化, 进而完成领域模型的构建与优化, 依靠人本身强大的语义理解与处理能力, 构建领域知识模型, 并对其进行评价与选择, 而不仅依靠计算机相关算法来处理判断语义, 干涉领域知识模型构建。本研究不仅丰富领域知识模型的理念, 也拓展了领域知识模型的研究框架, 是对领域知识模型的开创性探索, 是对开放学习平台中海量资源的组织方式的一种变革, 进而促进学习者的长时记忆及对知识的主动建构。对个人与集体知识体系的建设具有很强的借鉴和指导意义。
猜你喜欢
少先队活动(2022年4期)2022-06-06 07:19:42
当代陕西(2020年17期)2020-10-28 08:18:18
开放教育研究(2020年2期)2020-03-31 01:54:14
人大建设(2018年5期)2018-08-16 07:09:00
学苑创造·A版(2017年12期)2018-01-17 18:07:22
电信科学(2017年6期)2017-07-01 15:44:57
现代语文(2016年21期)2016-05-25 13:13:44
爆笑show(2015年11期)2015-12-17 01:35:31
大连民族大学学报(2015年2期)2015-02-27 08:28:11
卫生职业教育(2014年12期)2014-05-16 03:54:16
