
基于改进K-means算法的多场景分布式电源规划
2018-10-10 02:22:18张弈鹏罗凤鸣
吉林大学学报(信息科学版) 2018年5期
刘 伟, 张弈鹏, 罗凤鸣
(东北石油大学 电气信息工程学院, 黑龙江 大庆 163318)
0 引 言
随着负荷快速增长, 环境污染和全球变暖促使分布式电源在局部发电成为新趋势[1,2]。精确设计和操作DG(Distributed Generation)可提高配电网络的电能质量、 可靠性和安全性。此外, 还可减少系统的功率损耗和传输拥塞[3,4]。尽管有上述优点, 若DG选址和配置容量选择不当, 在配电网络中可能存在不可接受的电压曲线、 电压稳定性不足及保护装置不能准确操作等潜在缺点。
近年来, 对DG选址定容问题的研究有许多文献报道[5-8]。为规划方便, 以上文献通常假设DG出力以及负荷需求水平常年恒定不变, 最终导致所得DG位置和容量的配置方案实用性差。目前也有部分学者考虑了DG出力及负荷需求的时序性和不确定性而对其进行调度规划。文献[9]提出了一种将基于蒙特卡罗模拟法的DG并入配电网的可靠性分析, 但由于模拟次数过多, 增加了规划复杂度; 文献[10]提出了一种K-means聚类多场景概率分析方法, 有效地降低了DG的波动性和不确定性对配电网的影响, 但聚类数目的设定没有理论依据; 文献[11]将NSGA-Ⅱ引入DG多目标优化配置问题中, 可有效避免选取权重带来的主观影响, 但由于Pareto解集数量庞大, 无疑会给制定者增加决策压力。
综上分析, 笔者综合考虑DG出力和负荷需求水平的时序性和不确定性, 采用蒙特卡洛模拟法生成全年风-负荷运行场景, 并引入轮廓系数作为K-means场景聚类优劣的评价指标, 以配电网全年总投资费用、 总电压偏移量和网络损耗最小化为目标构建DG多目标规划模型, 最后采用NSGA-Ⅱ对模型进行求解和无偏折中策略实现多目标的最优决策, 并以IEEE33节点配电网为例, 验证了良好的DG规划效果。
1 风速-负荷概率模型
1.1 风速概率模型
风力发电机(WTG: Wind Turbine Generator)的输出功率主要由该地区的风速大小决定。风速一般服从weibull分布, 其概率密度函数[10]为
(1)
其中v为WTG叶轮轮毂处的风速;k和c分别为形状参数和尺度参数。可根据WTG的输出功率与v之间的关系[10]求得DG出力。
1.2 负荷概率模型
负荷也具有时序性, 不同类型的负荷运行曲线也不同, 负荷需求水平[10]可用正态分布近似表示为
(2)
其中p为随机负荷大小,μ为期望,σ为方差, 均可根据历史数据求得。
2 改进K-means聚类算法
采用蒙特卡洛法[9]模拟全年风-负荷模型的预测数据, 以典型日场景代表每季度特征, 每个典型日分为24个时段, 共需生成96个场景, 此举增加了规划复杂度, 因此笔者通过聚类分析法对场景进行缩减。K-means算法是一种常用的聚类方法, 以距离作为相似性的评价指标, 即认为两个元素的距离越近, 其相似度就越大, 样本将被聚类成K个簇(cluster)。 文献[10]验证了蒙特卡洛算法与K-means结合进行场景分析的有效性, 但由于聚类数目K的取值决定了聚类效果好坏, 为此引入轮廓参数[12]为聚类算法提供评价指标。在多场景缩减问题中, 假定场景样本为{x(1),…,x(m)}, 其中m为场景生成数, 每个x(i)∈R2包含风、 负载两个特征。改进K-means算法具体描述如下。
1) 轮廓系数Si为[-1,1]之间的常数, 其值越趋近于1代表聚类结果越优; 反之, 越差。计算公式为
(3)
其中ai表示场景i到本簇中其他场景的均值距离,bi为场景i到其他簇所有场景的最小均值距离。
2) 根据步骤1)中确定的聚类数K随机生成聚类中心点(cluster centroids):μ1,…,μk∈R2, 一般中心点取自聚类场景样本。
3) 每个场景计算其到K个中心的距离, 并选取距离最近的中心作为归属类, 最后重新计算聚类中心μj(通过计算每类场景均值进行中心更新), 重复以下公式直到收敛。
对于每个场景i, 计算其应该属于的类
(4)
对于每个类j, 重新计算该类的中心
(5)
其中ci为[1,K]之间的整数, 表示场景i距离K个聚类中心最近的类。
3 DG优化配置数学模型
3.1 目标函数
DG总投资费用
(6)
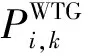
系统总电压偏差为
(7)
其中Ui,k表示在场景k中时节点i的电压幅值;N为配电网系统节点总数。设额定电压标幺值为1(pu)。
系统网络损耗为
(8)
其中L为配电网支路总数;Qi,k为在场景k时支路i的末端无功功率损耗;Vi,k为在场景k时支路i末端的节点电压;Ri为支路i的电阻。
3.2 约束条件
等式约束为
(9)
其中PDGi、QDGi分别为各节点的DG注入有功、 无功功率;PLi、QLi分别为各节点的注入有功、 无功功率;Ui为节点i的电压幅值;Uk为节点k的电压幅值;Gik为支路i,k上的电导;Bik为支路i,k上的电纳;θik为节点i与节点k电压角度的差值;L为与节点i相关联的支路数。
不等式约束为
(10)
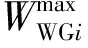
4 DG的多目标规划
4.1 NSGA-Ⅱ算法概述
电力系统规划问题一般被抽象为多目标、 非线性、 不连续以及不可微的优化函数模型[13], 由于规划问题常存在大量的局部极值点, 因此, 传统数学算法难以获取全局最优点。由于以遗传算法为代表的智能进化算法凭借着毋需微积分便可获取全局最优值的优势, 因此成为电力系统研究人员广泛应用的规划手段。NSGA-Ⅱ在继承遗传算法基本思想的同时, 增加了帕累托理论(Pareto)和拥挤距离, 可有效解决多目标函数优化问题, 是目前最流行的多目标智能算法之一。
4.2 NSGA-Ⅱ算法流程图
笔者采用蒙特卡洛模拟法对全年运行场景进行随机模拟, 通过改进聚类算法对全年96个运行场景进行缩减, 在满足各项约束条件情况下, 运用NSGA-Ⅱ算法对调度模型进行求解, 求解流程如图1所示。
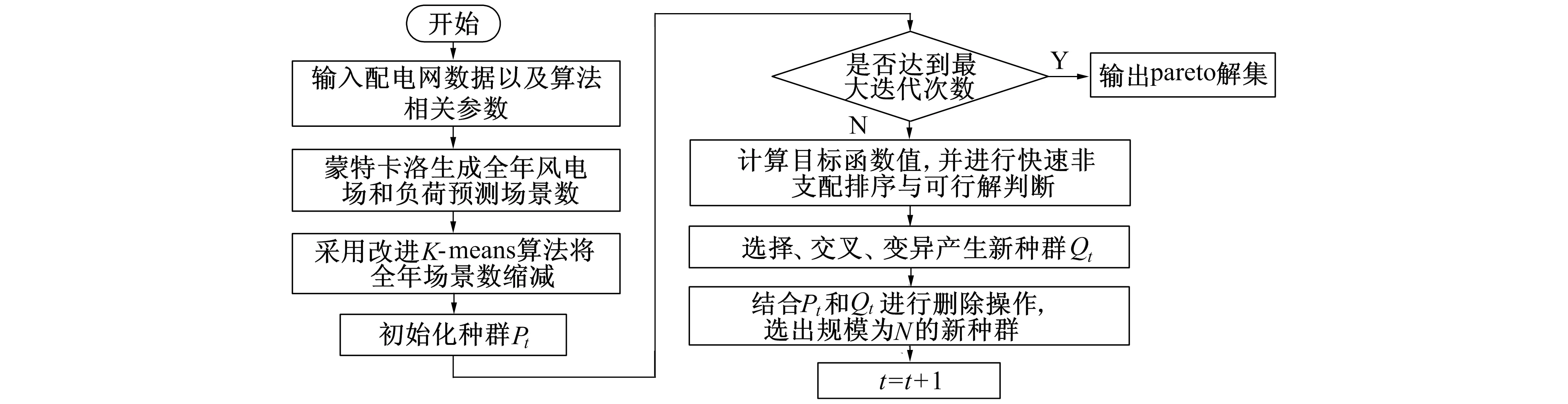
图1 基于NSGA-Ⅱ算法的分布式电源规划流程图Fig.1 Flow diagram of distributed power planning based on NSGA-Ⅱ algorithm
5 仿真验证
5.1 相关参数
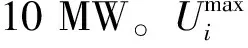
NSGA-Ⅱ的参数设置为: 种群规模为50, 最大迭代次数为100, 交叉和变异概率分别为0.9和0.1。标准遗传算法的参数与NSGA-Ⅱ设置相同。
5.2 聚类结果分析
采用改进聚类算法对全年96个运行场景进行缩减规划, 其中聚类数K(即场景数)取值[2,40]之间的常数, 轮廓系数评价指标如图2所示。
由图2可知, 当K值为13时, 平均轮廓值最大为0.925且最接近于1, 故认定将场景数目缩减为13类时效果最好。相比于规划全年96个场景下的分布式电源优化配置问题, 改进聚类算法不仅可有效地缩减全年86%的运行场景数, 大幅地降低计算复杂度, 而且引入轮廓系数后也为场景缩减算法的规划结果优劣提供了评判依据。
5.3 基于NSGA-Ⅱ的DG规划结果分析
如图3所示, 采用NSGA-Ⅱ算法进行多目标求解将会得到一组Pareto解集, 虽然可得到均衡多个目标函数的解集, 但解集数量过大无疑会增加方案制定者的决策负担。为降低决策压力, 笔者采用无偏折中策略评价Pareto解集并选择最佳折中解供制定者抉择。每个解的优质度为
(11)
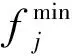
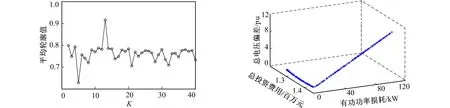
图2 不同K值的平均轮廓值 图3 NSGA-Ⅱ算法规划结果 Fig.2 The average contour value for Fig.3 Comparison of two algorithms different K values Pareto solution set
第i个解的优劣值为
(12)
其值越小则解越优, 最小值为最佳折中解。其中m为目标函数的个数;n为Pareto最优解集中解的个数。
由表1可知, NSGA-Ⅱ的最优折中配置方案能为配电公司减少近63.19%的网络有功损耗, 降低约49.35%的电压总偏差量, 标准遗传算法的最优配置方案能为配电公司减少约57.51%的网络有功损耗, 降低约38.51%的电压总偏差量。针对不同的配置结果, 考虑到DG对节点电压的支撑作用, 两种算法选择了系统端部的17和32节点作为安装节点; 相比于传统的单目标遗传算法, NSGA-Ⅱ依据Pareto关系协调多个目标的利益进行规划, 从而求得的安装容量更为合理, 对系统的总电压偏差和网络损耗改善更明显。

表1 两种算法配置方案对比
节点电压优化结果和系统网损优化结果分别如图4和图5所示, 从图4、 图5中可得以下结论。
1) 未安装DG, 系统各节点电压偏差和网络损耗偏高。长此以往, 在配电网运行过程中, 各种事故和故障会经常发生。
2) 按笔者规划配置方案接入分布式电源后, 配电网各节点的网损、 总电压偏差下降都十分明显, 进一步证明了合理的安装分布式电源可有效地改善系统的可靠性和安全性。
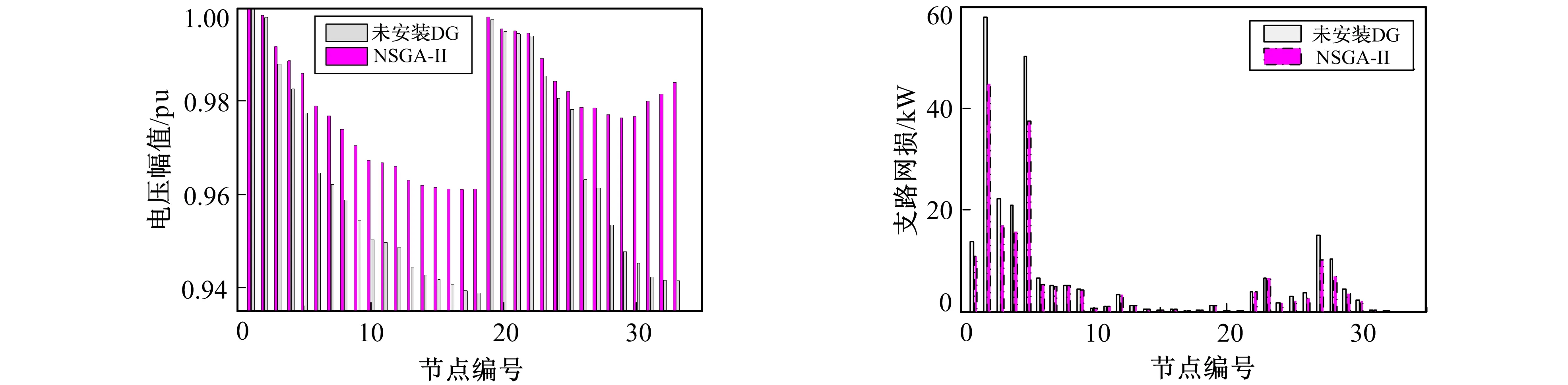
图4 节点电压优化结果 图5 系统网损优化结果 Fig.4 Node voltage optimization results Fig.5 System loss optimization results
6 结 语
笔者综合考虑DG和负荷的时序特性, 从经济性、 电能质量可靠性、 降低网损3方面进行建模。首先利用蒙特卡洛模拟全年运行场景, 并通过改进K-means聚类算法进行场景优化, 从而简化模型复杂度并提高了优化精度。最后通过NSGA-Ⅱ与无偏折中策略对多目标函数进行数值优化。笔者以IEEE33节点配电网络为例进行规划, 仿真结果表明, 所提改进K-means算法能提供更为精准的聚类场景, 可有效降低规划计算复杂度, 无偏折中解对Pareto解集的客观评价可有效地减少决策压力, 为决策者提供更加优质的配置方案。目前, 虽然DG投资费用昂贵, 但随着国家补贴政策的扶助以及相应技术的发展, 未来分布式发电技术将会更具潜能。
猜你喜欢
经济技术协作信息(2018年32期)2018-11-30 01:43:16
电子测试(2017年15期)2017-12-18 07:19:27
东北电力技术(2016年2期)2016-05-17 04:32:46
中国化肥信息(2016年35期)2016-05-17 04:25:50
电测与仪表(2016年5期)2016-04-22 01:14:14
河南电力(2016年5期)2016-02-06 02:11:24
智能系统学报(2015年4期)2015-12-27 09:38:39
核科学与工程(2015年2期)2015-09-26 11:56:59
电子设计工程(2015年6期)2015-02-27 12:04:53
电测与仪表(2014年17期)2014-04-04 11:56:34
