
一种用于阿尔茨海默病分类的二阶段多任务特征选择算法
2018-10-09 06:18:02杨晨晖侯超群
厦门大学学报(自然科学版) 2018年5期
杨晨晖,侯超群
(厦门大学信息科学与技术学院,福建厦门361005)
阿尔茨海默病(Alzheimer′s disease,AD)是一种不可逆的神经退行性疾病,会导致患者神经细胞的死亡和脑组织的损失,临床表现为记忆下降和认知功能损害.据预测,在2050年每85人中将有1个人是AD患者[1].随着问题的严重性日益突出,越来越多的国家和科研机构投入了大量资金和人力致力于对AD的研究工作,同时也有越来越多关于AD的公开数据集面向研究者.比如,AD神经影像学(ADNI,https:∥ida.loni.usc.edu/login.jsp)数据库提供了磁共振成像(MRI)、正电子发射型计算机断层显像(PET)和脑脊液(CSF)等模态的数据;华盛顿大学AD研究中心创建了开放式系列图像研究[2](OASIS,http:∥www.oasisbrains.org)数据集,主要收集MRI模态的数据,包括416名年龄介于18岁到96岁之间的受试者.然而,AD领域的数据集具有样本量少、多模态、维度高等特点,如何有效地选择特征具有重要的研究意义.Kloppel等[3]证实了在某些情况下,传统机器学习算法对AD的预测比临床医生更准确,该证明对研究计算机辅助诊断AD具有重要的意义.
特征选择通过移除样本的原始特征中一些不相关或者冗余的特征,找到一种具有良好泛化能力并能够紧凑表达的原始特征,进而达到降低数据维度、提升模型准确度、降低模型时间复杂度等目的.有效的选择特征对进一步处理数据和使用数据具有重要的意义.无监督特征选择方法作为特征选择的重要分支发挥着重要作用.Liu等[4]利用稀疏表达计算有效距离以衡量2个样本之间相似度进行特征选择.Zhu等[5]提出基于正则化自表达的无监督特征选择算法,不仅能够对特征进行选择,还可以根据模型重构度对样本进行选择.Tang等[6]提出一种无监督的拉普拉斯分数特征选择方法,可选择最能保持数据集局部拓扑结构的特征.此外,近几年来AD领域不断涌现的模态数据类型为多模态特征选择提供了重要的数据基础.单模态数据不能充分挖掘样本的隐藏信息,而不同模态数据从不同视角提供互补信息,整合多种模态数据能够挖掘样本更多的隐含信息.Liu等[7]提出了模态内关系受限的多任务特征选择方法来保留互补的模态间信息,并通过增加模态间关系约束项进而保护不同模态中同类样本的相对距离;Liu等[7]把每个模态中的特征选择过程作为一个单独任务,并根据稀疏性限制所选特征以保持模态间关系,对AD进行有效地预测.
此外,随着计算能力和标注数据的增加,深度学习算法在很多领域取得显著的效果.针对AD的分类问题,Liu等[8]先使用堆栈式的自编码进行特征提取,紧接着使用softmax[9]作为分类层有效地对AD进行分类;Gupta等[10]结合稀疏自编码和2D卷积神经网络有效地提高了分类精度;Payan等[11]使用3D卷积神经网络改进了Gupta的方法,提升了0.65%的准确率.复杂的深层卷积神经网络方法[8,10-11]将特征选择和分类器整合到一个网络结构并取得显著的效果,但目前该方法仍缺乏理论支撑.
本研究提出一种结合基于有效距离的拉普拉斯分数特征选择(effective distance-based laplacian score feature selection,EDLSFS)算法和基于类内方差最小化的多任务特征选择(minimum intra-class variance-based multitask feature selection,MIVMTFS)算法的二阶段多任务特征选择(two-stage multi-task feature selection,TSMTFS)算法;并分别讨论MIVMTFS算法和TSMTFS算法对AD进行分类的分类准确率,还将TSMTFS算法与相似的基于传统特征工程的算法和主流的深度学习算法进行比较.
1 MIVMTFS算法
Belhumeur等[12]于1996年将线性判别分析(linear discriminant analysis,LDA)算法引入人工智能领域,LDA利用样本的标签作为先验知识将高维模式的数据投影到最佳鉴别矢量空间,投影后的新特征具有最大类间离散度和最小类内离散度等特点.主成分分析[13](principal component analysis,PCA)使用无监督的方式在样本中选择对应方差大的前k维作为新特征.Huang等[14]使用组合的LDA算法在多模态数据中共同确定与病理关联的大脑区域特征.Zhang等[15]针对AD的分类问题,提出了一种基于多模态多任务学习的算法(MTFS)联合选择特征.但是在多任务特征学习中,如果对每个任务只考虑样本和样本标签之间的关系而忽略样本间的相互依赖关系,可能会导致相似的样本映射后的映射点间隔较大. Jie等[16]对MTFS算法进行改进,提出一个基于流形正则化项的多任务特征学习算法(M2TFS),主要思想是距离相近的样本通过线性映射之后的映射点同样接近,并将该思想嵌入到模型的损失函数中,实现特征的有效联合选择.
本研究受文献[16]以及传统降维方法思想的启发提出MIVMTFS算法.MIVMTFS算法对映射函数加以限制,使得同模态同类样本映射后的映射点具有聚集的特点,选择出来的特征将更有利于分类器的分类效果.MIVMTFS算法引入了同类样本全局方差最小的思想,通过让类内方差尽可能小来优化目标函数.本研究构建的类内方差最小化项如式(1)所示(推导过程详见附录http:∥jxmu.xmu.edu.cn/upload/html/20180519.html):
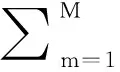
(1)

(2)
其中:Y是表示样本的类标的列向量;β和γ是2个取值范围为(0,1]的常量,它们的比值反映稀疏化正则项和类内方差最小化损失项对目标损失函数最小的贡献比重,可以通过训练数据集内部交叉验证得到.
本研究提出的MIVMTFS算法中,L2,1正则化项β‖W‖2,1能够确保只有少量的特征从多模态数据中共同选择;而类内方差最小化项(式(2)中第3项)通过对同类数据映射点类内离散程度的控制保留了单模态数据中最具有分类能力的信息,从而可能诱导更有分类能力的特征.在下文的实验部分中,本研究将MIVMTFS算法与MTFS和M2TFS算法进行比较,验证MIVMFTS算法的有效性.
2 EDLSFS算法
拉普拉斯分数(Laplacian score,LS)是基于拉普拉斯特征图[17]和局部性保持投影[18]理论产生的.拉普拉斯分数的基本思想是评估特征项对数据集拓扑结构的局部保持能力,根据评估结果来决定是否保留此维度特征.Chung等[19]提出LS被认为是关于特征的瑞利熵.基于相似度保护的特征选择算法已经被广泛使用在相关研究[20-23]中,能够选择出最佳保护原始数据局部结构的特征.此外,基于相似度保护的特征选择准则有一个统一的模式[24],LS及其扩展方法[25]是典型的基于相似度保护的无监督特征选择方法.LS基于图模型,采用特征拥有的分类能力衡量其重要程度.例如Cai等[19]提出多集群结构保护方法(MCFC)用于特征选择,MCFC基于数据的谱分析和L1正则化回归模型引导特征选择过程.Zhao等[22]提出基于流形的最大间隔方法用于无监督特征选择.
有效距离基于概率学思想的距离测度,可以反映数据的动态结构[26].相比于欧几里德距离,有效距离通过考虑数据的动态结构信息,可以帮助揭示数据隐藏的几何模式.因此在特征学习任务中,采用有效距离代替欧几里德距离可引入动态结构信息,进而提升学习性能.忽略网络结构的潜在复杂性,有效距离的核心思想是:一些可能路径子集可以控制数据的动态结构.给定样本关联矩阵P,记Pa b(0≤Pa b≤1)为从节点a到节点b的转移概率,则节点a与节点b的有效距离
Da b=(1-logPa b)
(3)
由式(3)可知,从节点a到节点b的转移概率越小,表明节点a与节点b间的距离越大;反之,两个节点间的距离越小.由于关联矩阵P是非对称的,所以有效距离矩阵D=(Dij)也是非对称的.相比于传统的几何距离,有效距离可以揭示数据的隐藏几何模式、捕捉到数据的动态结构信息,因此在特征选择方法中使用有效距离可以找到数据中最具有分类能力的特征.
基于给定的有效距离矩阵D,本研究计算每一对样本间的相似度,记样本的相似度矩阵S=(Sij),
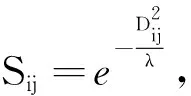
(4)
其中,常量λ表示高斯函数的宽度.矩阵元素Sij定义了样本xi与样本xj间的相似性.在LS进行特征选择过程中,样本第r维特征的拉普拉斯分数Qr的计算公式如式(5)所示:

(5)

EDLSFS算法的步骤如下所示:
初始化高斯函数宽度参数λ.
1) 基于稀疏表达构造重构P,并归一化P的每一列;
2) 根据P和式(3)计算有效距离矩阵D;
3) 根据式(4)构造基于有效距离的相似矩阵S;
4) 根据相似矩阵S和式(5)得出各特征维度的拉普拉斯分数Q;
5) 根据拉普拉斯分数Q对各个特征维度进行排名;
6) 根据设定阈值,选取排名靠前的特征作为降维后的新特征.
输出:各个特征维度根据拉普拉斯分数排名后的数组.
3 TSMTFS算法
EDLSFS算法和MIVMTFS算法在特征选择上具有互补性.EDLSFS算法可以捕捉到数据间的动态结构信息,从而选择出最优区分能力的特征且保持了原有特征空间的局部信息.同时EDLSFS算法也存在不足之处:1) 有效距离的计算利用样本间的相互线性表达,而实际应用中许多样本之间是非线性相关的;2) 特征排名的阈值很难确定,较小的阈值使得剔除的特征偏多、信息丢失,较大的阈值剔除的特征偏少导致仍存在较多的冗余特征.MIVMTFS算法利用类标与数据分布信息来选择特征,由于引入了类标信息并改造了目标函数,使其在多模态数据中能够选取出更具有分类能力的特征,但在特征维度比较高、样本数比较少的情况下,容易陷入参数优化不收敛情况.
本研究结合EDLSFS算法和MIVMTFS算法实现特征有效选择.主要是先使用EDLSFS算法对数据原始特征做初步降维,降维后的特征作为有监督特征选择MIVMTFS算法的输入,实现特征的进一步选择.在实验过程中把无监督特征选择过程和有监督特征选择过程结合起来,利用10折交叉验证和网格化搜索策略实现最优参数设置.TSMTFS算法流程框架如图1所示,输入是多模态影像的原始特征,依次使用无监督和有监督的特征选择方法并使用10折交叉验证法寻找最优参数获取精简特征集,以此特征作为分类器(本研究使用多核支持向量机)的输入进行训练,得到最终的分类结果.
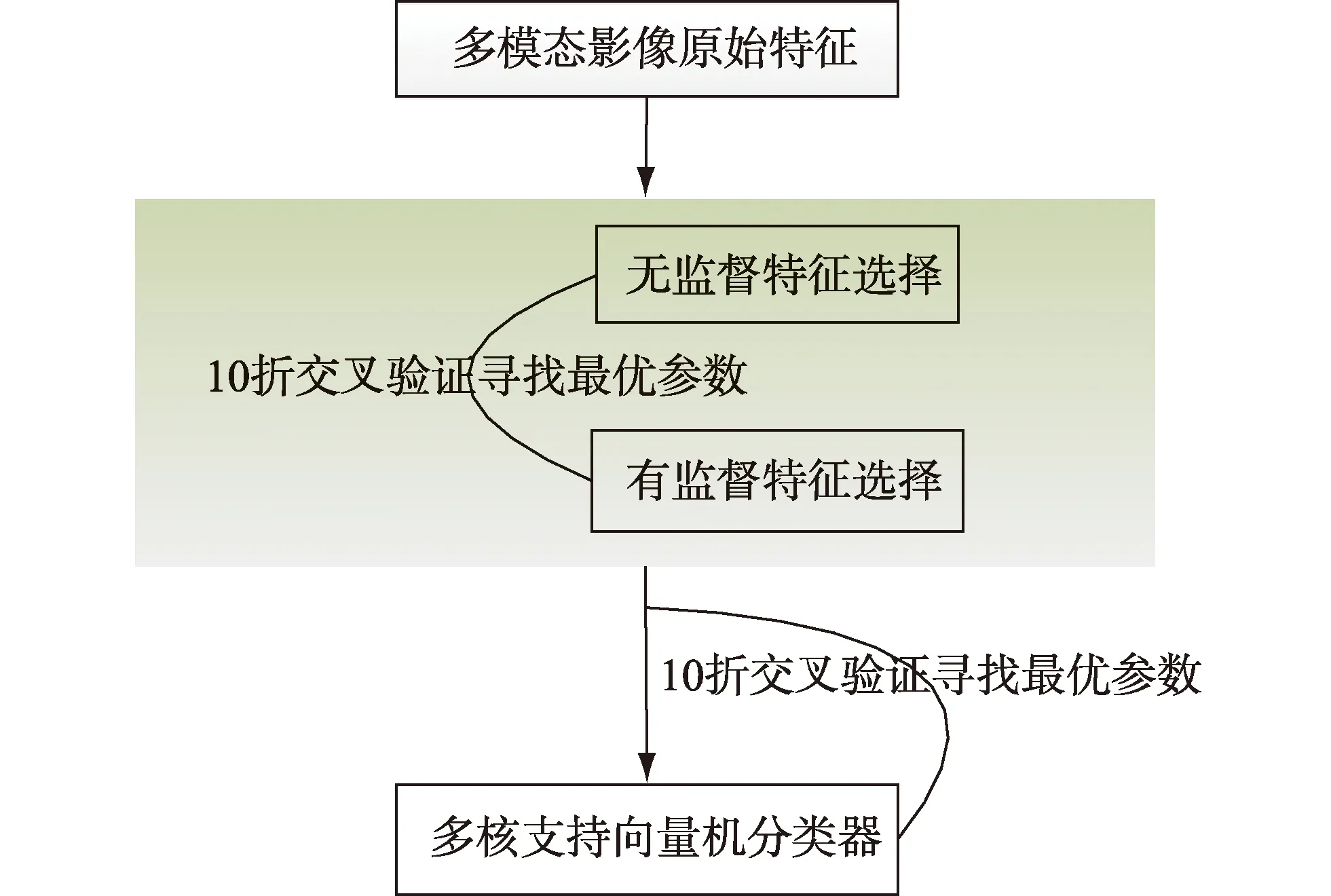
图1 TSMTFS算法的流程图Fig.1 The flow diagram of TSMTFS algorithm
4 实 验
4.1 实验数据集
本研究的实验部分使用238个来自AD神经影像学数据库的样本,包括磁共振成像(MRI)和正电子发射型计算机断层显像(PET)2种模态的医学影像数据,具体参数如表1所示.本研究参考文献[27]的方法获取MRI和PET数据以及数据处理流程,相关的实验过程在MATLAB平台上实现.

表1 238个样本的基本信息
注:MCI表示轻度认知功能障碍;NC表示正常受试者;CDR表示临床痴呆评定量表,取值范围为[0,3],数值越大表示痴呆程度越严重;N表示样本数量.
4.2 MIVMTFS实验分析
MIVMTFS算法使用由238个样本组成的多模态(PET+MRI)数据,分别对AD vs NC、MCI vs NC两个分类任务与MTFS[15]和M2TFS[16]算法进行比较,实验结果如表2所示.MIVMTFS算法通过将式(1)作为惩罚项加入式(2)的目标函数进行优化,使得类内方差尽可能小进而提升了分类效果.在AD vs NC的分类任务中通过10折交叉验证,MIVMTFS算法达到93.09%的平均准确率(ACC),其他指标也是最优;在MCI vs NC的分类任务中通过10折交叉验证,MIVMTFS算法达到76.83%的ACC,引入流形正则化项的M2TFS算法在各项指标达到最优.MIVMTFS算法通过对同类数据映射点类内离散程度的控制保留了单模态数据中最具有分类能力的信息,但缺乏捕捉数据间的动态结构信息的能力,因此选择的特征丢失了原有特征空间的局部信息.
此外,本研究使用MIVMTFS算法分别在MRI和PET 2个单模态数据集上进行实验,分析被选中的脑区个数.其中,MRI模态的最优特征个数为19,PET模态的最优特征个数为20;同时使用MRI+PET模态的最优特征个数为56,包括单独使用MRI模态和PET模态时选中的特征.实验结果进一步说明了MIVMTFS算法能够实现多模态数据的有效特征选择,标记出对疾病敏感的脑区域,为脑疾病的辅助诊断提供实验依据.

表2 多模态数据下MIVMTFS算法与MTFS和M2TFS算法的比较
注:SEN表示敏感度;SPE表示特异性;AUC表示ROC曲线下的面积.
4.3 TSMTFS实验分析
TSMTFS实验部分对238个样本进行组合得到3种模态数据类型,即MRI、PET、MRI+PET,然后分别对这3种模态数据进行实验.通过10折交叉验证TSMTFS算法在AD vs NC分类任务中,MRI、PET、MRI+PET的准确率对应的方差分别为0.174,0.220,0.102;在MCI vs NC分类任务中分别为0.091,0.043,0.270.实验结果如表3所示,TSMTFS算法结合了EDLSFS算法和MIVMTFS算法,其多模态数据上的分类性能更优于单模态数据上的分类性能.针对多模态(MRI+PET)数据:在AD vs NC的分类任务中,TSMTFS算法的ACC比MIVMTFS算法提升了0.17个百分点;在MCI vs NC的分类任务中TSMTFS算法的ACC比MIVMTFS算法提升了5.86个百分点,同时也优于M2TFS算法.
本研究的数据中,103名MCI受试者还可进一步划分为47名MCI-C和56名MCI-NC,分别表示在随访中转化为AD和未转化为AD的受试者.本研究使用多模态数据(MRI+PET)分别采用3种算法进行MCI-C vs MCI-NC分类,TSMTFS算法的各项指标都优于MTFS算法和M2TFS算法,结果如表4所示.

表3 TSMTFS算法在不同模态的分类结果
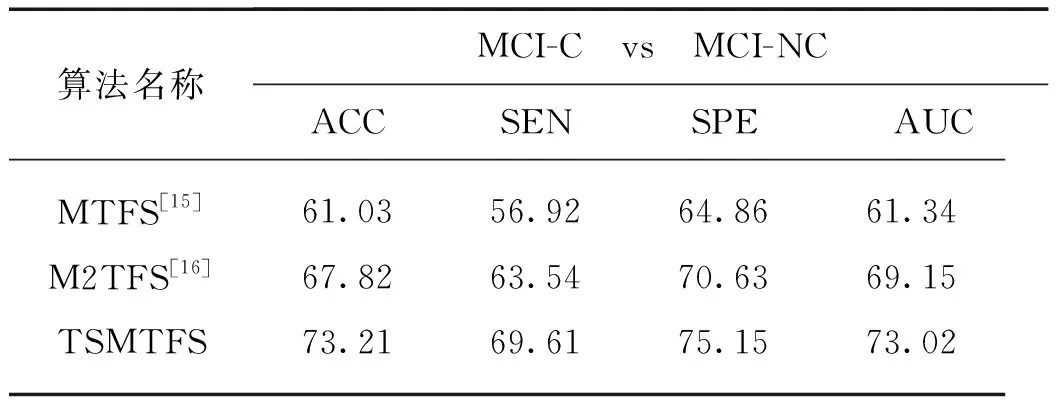
表4 多模态数据下TSMTFS算法与MTFS和M2TFS算法的比较
上述实验结果中,表3首先验证了TSMTFS算法在多模态数据上的效果优于单模态数据,同时也进一步说明结合了MIVMTFS和EDLSFS算法的TSMTFS算法能够进一步挖掘多模态数据之间的有效特征.表4针对MCI-C vs MCI-NC的分类任务,以多模态数据为数据集分别对MTFS、M2TFS和TSMTFS算法进行比较,实验结果表明TSMTFS算法取得最优的效果.
此外,本研究还选择了3种当前主流的基于深度学习算法[8,10-11]与TSMTFS算法进行比较,文献[8,10-11]中使用深度卷积神经将特征选择和分类器整合到一个网络结构并取得显著的效果.如表5所示,在AD vs NC的分类任务中,Liu等[8]取得了87.76%的ACC;Gupta等[10]结合了稀疏自编码和2D卷积神经网络进行特征提取,取得了94.74%的ACC;Payan等[11]使用3D卷积神经网络改进了Gupta的方法,提升了0.65%的ACC.本研究提出的TSMTFS算法取得了93.26%的ACC,与基于深度学习的算法[8,10-11]得到的结果相差不大.实验结果再次验证了TSMTFS算法选择的特征能够有效地对AD进行预测,由于文献[8,10-11]使用卷积神经网络提取图像的特征并进行分类,特征模块和分类器都是基于反向传播更新参数的方式进行训练,目前仍缺乏对模型决策做出明确解释的理论支撑,而TSMTFS算法提取的特征则相对更具有可解释性.
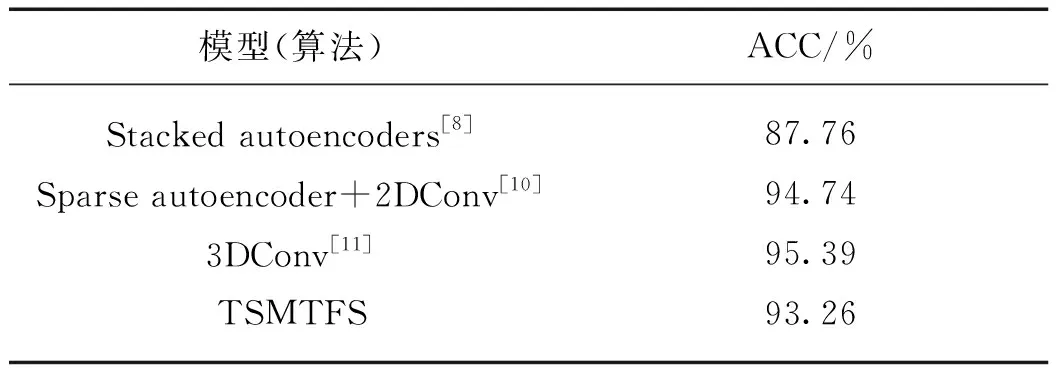
表5 TSMTFS算法与一些深度学习算法的ACC比较
5 结 论
本研究受文献[16]中算法以及传统降维思想的启发提出了MIVMTFS算法,并将MIVMTFS算法与EDLSFS算法结合进一步提出了TSMTFS算法.TSMTFS算法首先利用EDLSFS算法在无监督情况下筛选出较为优质的特征作为一个数据子集.然后利用MIVMTFS算法在有监督情况下进一步选择更具有分类能力的特征子集.TSMTFS算法最大的优点是在选择特征数量较多且样本数量较少的情况下不易陷入次优解,能够更好地选择出具有最优分类能力的特征;缺点是时间复杂度较高,主要由于无监督特征选择部分需要花费更多的时间.本研究在第一阶段过滤掉部分特征,限制了整体性能的进一步提升.但在无监督过程采用了基于有效距离的相似性测度保留了具有分类能力的特征,筛选出有效的精简特征子集,提升分类器的性能.本研究的实验数据来源于ADNI,实验部分主要包括3部分:1) 以多模态数据对MIVMTFS算法进行实验,并与MTFS和M2TFS算法做比较,验证了MIVMTFS算法的有效性和鲁棒性;2) 分别以单模态和多模态数据对TSMTFS算法进行实验,验证了TSMTFS算法在多模态数据上能够更加有效地预测AD;3) 以多模态为数据集,对MCI-C vs MCI-NC分类任务进行实验,TSMTFS算法相对于MTFS和M2TFS算法取得最优性能,ACC只有73.21%,还有很大的提升空间.此外,实验进一步将TSMTFS算法与当前主流的深度学习算法[8,10-11]作比较.虽然使用深度学习算法[8,10-11]的ACC更高,但深度学习算法目前仍缺少理论支撑,可解释性不强,而本研究方法可以标记出对疾病敏感的脑区域.在下一步的研究工作中,将围绕两方面继续研究:1) 深度学习算法及其在特定领域的解释性;2) 将深度学习算法提取的特征与传统特征选择算法进一步结合,获取更有效的特征子集.
猜你喜欢
小学生导刊(2018年34期)2018-12-18 01:53:14
电子制作(2017年23期)2017-02-02 07:17:06
山东青年(2016年3期)2016-02-28 14:25:55
西北工业大学学报(2015年4期)2016-01-19 03:31:47
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
母子健康(2015年1期)2015-02-28 11:21:33
计算物理(2014年2期)2014-03-11 17:01:39
振动工程学报(2014年4期)2014-03-01 01:15:41
延河(下半月)(2014年3期)2014-02-28 21:06:45
