
基于YAP流水线的影像组学研究流程的实现
2018-10-08 07:01:04李冬宝宋阳罗庆谢海滨杨光
磁共振成像 2018年7期
李冬宝,宋阳,罗庆,谢海滨,2*,杨光,2*
作者单位:
1. 华东师范大学物理与材料科学学院,上海市磁共振重点实验室,上海200062
2. 上海康达卡勒幅医疗科技有限公司,上海 200062
医疗影像是临床诊断中的重要工具,可以无创地提供患者信息来辅助临床医师进行诊断。影像组学是[1-2]是一种常见的将影像和临床诊断相关联的方法,通过对大量的医学图像进行分析得到隐含的图像特征数据,并对特征数据与临床诊断进行关联分析,从而建立从图像到临床诊断的模型。该模型可以用于分析医学影像,辅助医师进行临床诊断、术后干预等。相较于活体组织检查,它不会对人体产生身体或心理上的伤害。磁共振成像作为临床中常用的检测方法,多角度、多参数、多序列成像,具有较高的软组织对比度,不会造成放射性和侵入性的伤害,可以提供丰富的临床特征,经常用于影像组学研究[3-5]。
又一条流水线(yet another pipeline,YAP)是一个医学图像重建与后处理的开发框架[6],采用基于接口的设计,可以通过插件对系统进行扩展。YAP具有以下特点:(1)处理模块支持多个输入输出端口,流水线支持分支结构;(2)提供了参数管理,可以向处理模块传递伴随数据的参数,也可以在模块间传递参数;(3)支持灵活多样的数据组织形式。此外,YAP还提供了基本的核心部件、基础磁共振图像处理插件库、接口实现和使用的帮助类等。
由于影像组学很多开发工具是基于Python语言开发的,为了方便在YAP中搭建影像组学流水线,本研究为YAP增加了Python语言的支持,允许使用Python编写流水线中的处理模块,方便了算法的研究;同时利用基于Python的影像组学软件包van Griethuysen等[7]在YAP上实现了影像组学处理流水线。本研究的最后一部分,使用影像组学流水线进行多模态磁共振图像肿瘤病理分级预测的方法。
1 影像组学流水线实现
1.1 影像组学研究流程
自Lambin等[1]和Kumar等[2]提出影像组学概念以来,这种方法越来越多被用来研究肿瘤病理分级,临床诊断以及治疗反馈。影像组学进行分类的流程如图1所示,其过程大致包括:获取图像、预处理、图像分割、特征提取、特征选择、分类以及结果分析。
其中,影像组学最常用图像包括CT、PET以及MRI[8-9]。预处理过程常常包含图像配准、归一化等过程,使得用于组学分析的图像尽可能一致。图像分割步骤可以采用自动分割或者手动分割,不同的分割算法会影响影像组学的结果[8]。用于研究的金标准则常常采用手工分割的方法,高质量自动分割算法的匮乏可能是妨碍影像组学应用的主要障碍之一。
影像组学分析中,可以使用很多不同类型的特征,包括信号强度、几何形状、纹理等不同类别的特征。信号强度特征是基于图像中像素点计算的统计值。几何形状特征是指肿瘤的形状以及肿瘤的大小。纹理特征又称为高阶特征,是对图像中多个像素灰度关系进行统计,Kumar等[2]研究提到纹理特征会比信号强度特征有更好的潜在价值。本研究使用的纹理特征包括Gray-Level Co-occurrence matrix (GLCM)[10]特征、Gray-Level Size Zone Matrix (GLSZM)[11]特征、Gray-Level Run Length Matrix (GLRLM)[12]特征、Gray Level Dependence Matrix (GLDM)[13]特征和Neighboring Gray Tone Difference Matrix (NGTDM)[14]特征等。此外,可能影响模型的临床或个人信息也可以加入特征空间。
虽然使用更多的特征可能会导致更准确的模型[15],但过多的特征容易导致过拟合现象,因此需要通过特征选择来去除冗余的或与分类结果无关的特征,减少分析所用的特征数量。特征选择方法有很多,例如Pearson相关系数[16]、遗传算法[17]以及递归特征消除方法[18]等。影像组学分析的最后一步是建立特征到临床结论的预测模型,支持向量机(support vector machine,SVM)[19]就是最常用的分类器之一。
1.2 影像组学流水线的总体设计
由于在科研工作中,图像分割常常由有经验的影像科医师手工完成,本研究实现的影像组学流水线假定已经完成了图像预处理与图像分割工作。由于不同数据来源的原始数据组织形式不尽相同,为了使用本研究的流水线处理,应使用手工或者自动的方式将图像数据转换成如图2所示的文件目录结构中。
影像组学流水线的结构如图3所示。其中,SampleIterator表示样本迭代器,它将数据文件夹中的每个样本的文件夹一次送入ModalityIterator处理器处理。ModalityIterator表示模态迭代器,它将每个样本中不同模态(序列)的图像送入后续处理器处理。NiiReader处理器,实现对*.nii格式文件的读取,它读取的数据被送入FeatureExtractor进行特征提取,提取的特征依次有ModalityCollector、SampleCollector收集到样本特征矩阵。最后样本特征矩阵汇总后,送入Classifier进行特征选择、分类等分析处理。实现上述流程的YAP脚本代码如图4所示。
其中第1行导入PythonRadiomics.dll模块,使得脚本可以使用该模块提供的处理器。影像组学流水线中所使用的所有处理器,都在此模块中实现。第3~13行,定义了流水线中要使用的处理器对象。其语法类似C++中的对象定义,在构造处理器对象的同时,可以指定处理器的属性。
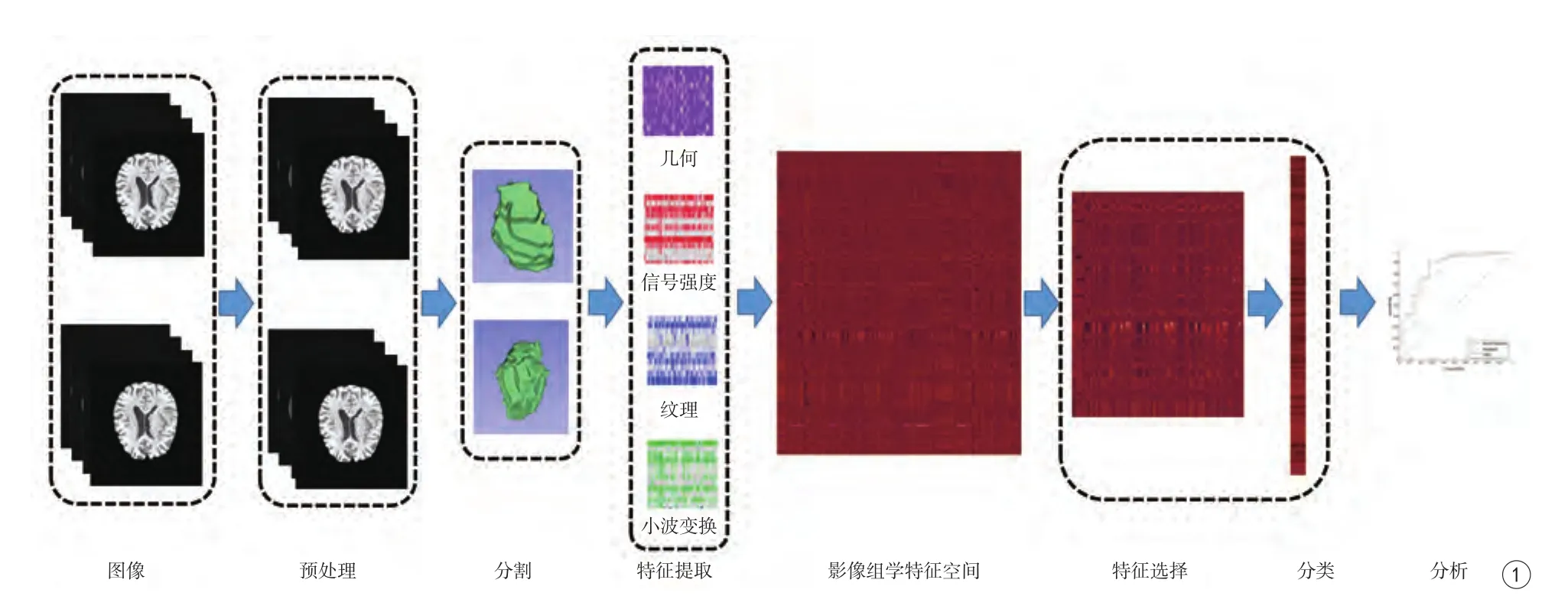
图1 影像组学图像分类处理流程Fig. 1 Flowchart of radiomics-based classification.
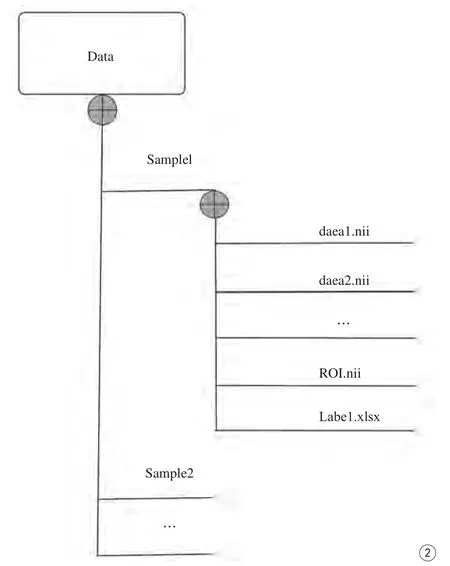
图2 流水线要求的数据集的存储方式。图中Sample1、Sample2、…等表示不同的样本文件夹;data1.nii、data2.nii、…表示不同模态的图像;ROI.nii表示分割图像;Label.xlsx表示当前样本的标记数据Fig. 2 Required structure of folders containing dataset images. Sample1,Sample2, … means different sample folders. data1.nii, data2.nii, … means different modality images. ROI.nii means a segmentation image. Label.xlsx means current sample label data.
第15~22行,使用“->”操作符将处理器对象相互连接,在处理器对象Id后面可以指定具体的输入或输出端口Id;如果不指定端口,那么就使用默认输入“Input”或输出“Output”。
第24行指定将整个流水线的输入端口设置为sample处理器的Input端口。运行时,直接向流水线中馈送数据对象即可启动流水线处理。由于sample处理器可以从其属性获得待处理的文件夹路径,所以用于启动流水线工作的数据对象可以是个空数据对象。
1.3 Python支持
如前文所述,本研究影像组学流水线所用的所有处理器都在PythonRadiomics.dll中提供。在实现FeatureExtractor处理器时,笔者使用了PyRadiomics软件包提供的功能,这是一个由第三方提供的用Python语言编写的影像组学处理软件包。
Python是一种面向对象的解释型语言,它具有简单易学、运行速度快、免费开源、良好移植性、面向对象特性、扩展性和丰富的第三方库等诸多优点。它可以方便地调用C/C++、Java等语言编写的模块,所以也有“胶水语言”称号。Python在科学计算方面有强大的第三方库,例如:Numpy、scikit-learn等,在大数据与人工智能火热的背景下,Python得到了迅速的发展,在IEEE Spectrum2017年发布的编程语言排行榜上高居榜首[20],绝大多数的机器学习平台也都支持Python编程。
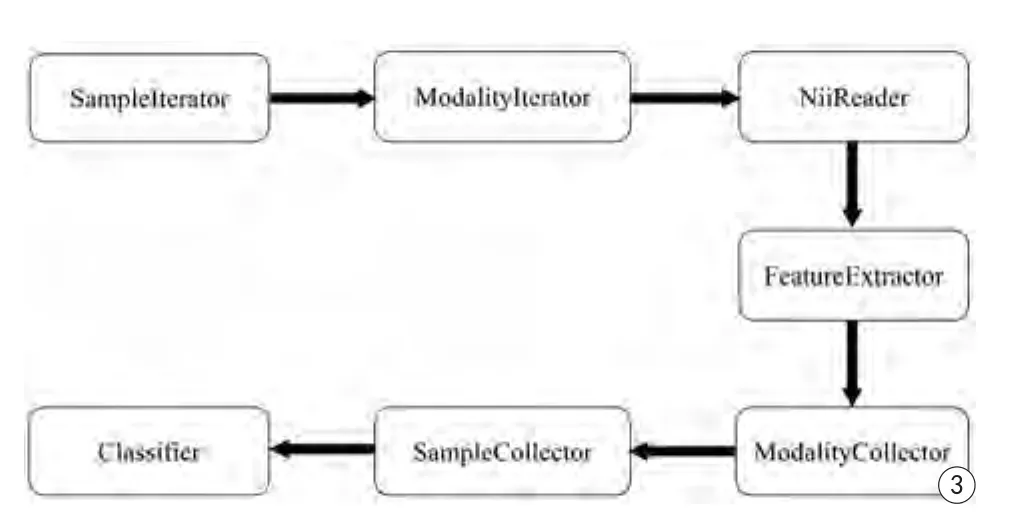
图3 影像组学流水线在YAP中的流程图。图中使用的模块包括样本迭代器(SampleIterator)、模态迭代器(ModalityIterator)、Nii文件读取器(NiiReader)、特征提取器(FeatureExtractor)、模态收集器(ModalityCollector)、样本收集器(SampleCollector)以及分类处理器(Classifier)Fig. 3 Flowchart of radiomics pipeline in YAP. Modules used in the flowchart includes SampleIterator, ModalityIterator, NiiReader,FeatureExtractor, ModalityCollector, SampleCollector and Classifier processor.

图4 实现的影像组学流程的YAP脚本代码 图5 Python服务中提供的IPython接口函数签名Fig. 4 Implementation of Radiomics flowchart’s YAP script code.Fig. 5 IPython Interface function signature in the Python service.
本研究在YAP中增加了对Python语言的支持,允许在编写处理器时使用Python脚本,这样就简化了一些算法的研究工作,一些对于速度要求不高的处理器,也可以使用Python编写,以提升开发效率。由于在同一进程内无法使用多个Python解释器,更不用说同时使用不同版本的Python解释器,所以在YAP的系统服务中,以IPython接口的形式,将调用Python脚本进行数据处理的能力提供给处理器开发人员。需要指出的是,目前笔者在IPython中只提供了专门用于YAP流水线数据处理的高级接口,并不能调用Python的所有功能,相应代码如图5所示。
在流水线中,调用Python处理器的流程如图6所示。图中虚线框内表示Python引擎内部运行的大致过程,Python引擎将数据转换为Python识别的数据类型,然后调用Python解析器(Python Interpreter)对脚本文件Radiomics.py(PythonProcessor的Module属性制定,并通过IPython::Process()函数的参数传递)进行解析,最后得到结果转换得到C++形式数据类型,作为IPython::Process()函数的输出,由PythonProcessor处理器传往下一处理器。需要指出的是,Python引擎会在首次使用时启动Python 解释器。
在YAP中增加了流水线支持后,就可以使用Python语言编写处理器,实现特定的处理步骤。Python的快速开发能力和强大的科学计算、可视化相关的第三方库的支持,能给利用YAP进行算法研究的人员带来极大的便利。本研究工作中的FeatureExtractor利用了PyRadiomics中的脚本进行特征提取;Classifier处理器,同样利用Python脚本进行影像组学的特征选择和分类工作。
另一方面,我们的影像组学流水线中采用了医学图像常用的NIfTI格式,NiiReader处理器用于对该格式文件的支持,目前仅支持NIfTI-1和NIfTI-2版本的基本类型数据的解析,对<*.img,*.hdr>形式的文件对解析不支持。笔者用C++编写了该处理器。不同语言编写的处理器,可以在同一条流水线中应用,体现了YAP的灵活性。
2 应用影像组学流水线对胶质瘤分级
2.1 使用的数据
为验证本研究影像组学流水线的可用性,笔者使用本研究的影像组学流水线对BRATS2017[21]公开数据集中的三维多模态胶质瘤数据进行了影像组学研究。该数据集中的成像序列包括FLAIR、T1CE、T1和T2。数据经过标准化处理,提供了分割好的多种肿瘤感兴趣区域,包括坏死或非增强部分、肿瘤周围水肿部分和肿瘤增强区域。在本研究中,笔者将以标记区域合并作为图像感兴趣区域。
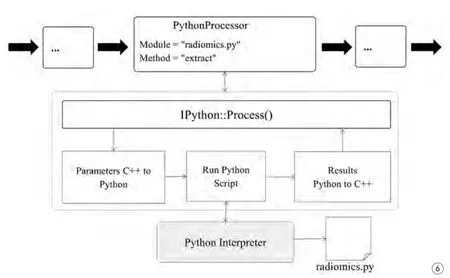
图6 Python引擎处理数据流程。PythonProcessor:调用Python服务的处理模块,PythonProcessor中的extract表示脚本中被调用的函数;Python Interpreter:Python解析器;radiomics.py:被调用的Python脚本文件Fig. 6 Python engine processing data flow. PythonProcessor refers to a processor which calls Python service.Python Interpreter refers to Python script parser. Radiomics.py refers to Python script file called. ‘extract’ in the PythonProcessor refers to a called function in the ‘radiomics.py’ script.
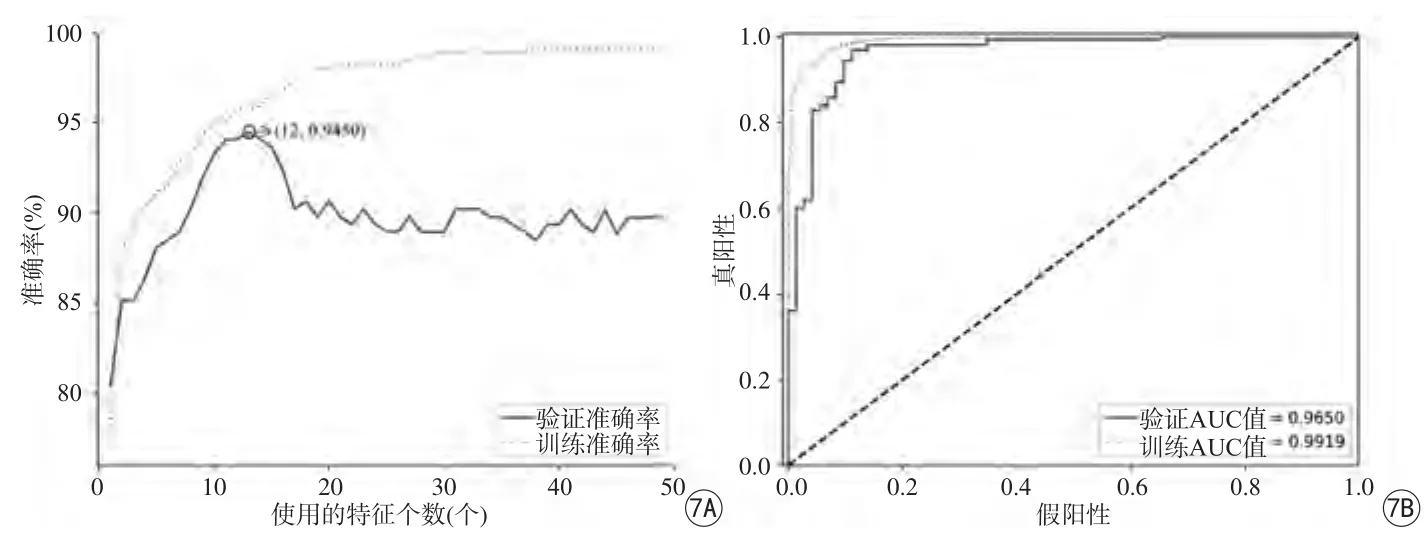
图7 BRATS2017 肿瘤分级的结果。A:不同的特征数量得到的模型准确率,选择特征数为12时,可以获得最佳的平均准确率94.5%。B:ROC曲线,其中验证集的AUC值为0.9650Fig. 7 Results for classification of BRATS2017 dataset. A: Model accuracy using different features number.The highest average accuracy of 94.5% was achieved when the number of selected features is 12. B: Receiver operator characteristic curve of the models. AUC for the validation data is 0.9650.
此外,BRATS2017也提供了肿瘤的分级标记,即高级别胶质瘤(higher grade glioma,HGG)和低级别胶质瘤(lower grade glioma,LGG)标记。数据集中包括72例LGG、163例HGG,共235个样本。按照流水线的解析要求,把数据预先整理如图2所示的形式,然后将路径设置给SampleIterator处理器的Path属性。
2.2 实验方法
本实验的特征提取利用了PyRadiomics工具包中的脚本,对图像进行预处理和特征提取。结合不同的模态,提取的可量化特征一共有383种。采用RFE (recursive feature elimination)[18]进行特征筛选,采用线性SVM进行模型建立,为了获得较好的模型结果,对线性SVM分类器的分类惩罚参数C进行基本范围的遍历调节,C值分别取0.001、0.005、0.01、0.05、0.1、0.25、0.5、1、2。10-Fold交叉验证(cross-validation,CV)进行模型评估。评估方法包括准确率、受试者操作特性(receiver operating characteristic,ROC)曲线和曲线下面积(area under curve,AUC)值。
2.3 结果和讨论
使用RFE方法对特征排序后,观察10次交叉验证实验的平均准确率随所选的特征数变化的情况,最终得到平均准确率最高的情况出现在选择特征数为12时,如图7A所示。其中,得出当C=0.25时,10次交叉验证的平均准确率可以达到94.5%。除准确率外,还使用ROC曲线的AUC值作为判定模型好坏。在图7B中,表示训练和验证的ROC曲线以及对应的AUC值为0.9650。
由实验过程和结果可见:通过YAP流水线,可以实现对影像组学处理过程的应用。得到良好的分级结果,可以为临床医师提供很大帮助,也为该类型的疾病预测和治疗分析提供帮助。
在影像组学流水线上,不同数据的研究,仅需要通过改变流水线脚本里Python处理器里的参数,例如图6中的Module和Method等即可,而无需将项目进行重新编译。而且在流水线中,也可以很方便地添加一些其他处理模块,例如利用YAP提供的基础设施,可以方便地进行特征的保存、可视化等操作,也可以将计算过程中发生的错误或关键数据记录到日志。这些对算法开发人员和图像研究人员都提供很大的便利。在影像组学流水线上,可以方便地开发并验证自己的算法,这为算法研究、医学影像研究以及更大规模的应用提供了便利。
3 讨论
本研究在YAP框架中增加了对Python语言的支持,并在此基础上实现了影像组学流水线。该流水线充分利用了Python语言中丰富的科学计算软件包,也可以利用C++的速度和YAP流水线提供的基础服务。混合语言开发医学影像后处理流水线,既可以利用Python的快速开发进行算法研究,也可以在需要时,将Python处理器用C++处理器替代,以提高性能。我们利用影像组学流水线对BRATS2017公开数据集进行了脑部胶质瘤的影像组学的研究,得到较好的分类结果,这进一步确认使用YAP流水线形式进行影像组学研究是可行的。
猜你喜欢
汉语世界(The World of Chinese)(2023年2期)2023-06-22 14:50:17
小学科学(学生版)(2020年2期)2020-03-03 13:40:16
国际口腔医学杂志(2019年3期)2019-05-31 10:09:26
天然产物研究与开发(2018年2期)2018-04-04 02:01:12
中国资源综合利用(2016年9期)2016-01-22 08:35:22
医学研究杂志(2015年11期)2015-06-10 06:44:03
电子设计工程(2015年12期)2015-02-27 12:06:20
汽车零部件(2014年1期)2014-09-21 11:41:11
小青蛙报(2014年1期)2014-03-21 21:29:39
自动化博览(2014年6期)2014-02-28 22:32:05
