
基于深度学习和迁移学习的液压泵健康评估方法
2018-09-28 11:48:50,
机械与电子 2018年9期
,
(上海交通大学机械与动力工程学院,上海 200240)
0 引言
液压泵作为液压系统的动力元件,其健康状态会对液压系统的工作状态产生直接影响。近年来,利用传统机器学习对液压泵的故障诊断和健康评估取得了较多的成果[1-2]。随着深度学习的出现,在故障诊断和健康评估领域,越来越多的学者开始尝试采用深度学习。深度学习是一种不需要人工提取特征的方法,近年来被广泛应用[3-7]。然而,上面所述方法有其局限性,其一就是当设备在不同条件下的运行数据分布改变时,已训练的模型往往不再适用;此外,在一些新的条件下,运行数据有时很难获得,因此,没有足够的数据来训练得到一个模型。当前出现的迁移学习方法是有望解决这一问题的重要途径之一。目前迁移学习在图像、语音和文本识别的研究中已经取得了较大进展[8-10]。但是在机械设备状态检测领域,迁移学习的研究还比较少。Shen 等人[11]采用了一种迁移学习框架。使用SVD方法进行特征提取,利用TrAdaBoost算法,对轴承状态进行了评估。为了解决液压泵数据采集困难,在少量数据下建立健康评估模型的问题,在此提出了一种基于深度学习和迁移学习的液压泵健康评估方法。首先,利用快速傅里叶变换将时域信号转化为频域信号;然后,通过卷积神经网络的方法对已有大量历史条件下液压泵振动的频域信号建立预测模型;最后,用迁移学习的思想在目标少量液压泵数据上对深度学习模型进行微调。
1 深度学习和迁移学习理论
1.1 深度学习
深度学习利用多个层,自动提取数据深层特征,然后经过最后的分类器,实现分类功能,由于其强大的特征提取能力,使其分类效果往往优于传统机器学习方法。
卷积神经网络是深度学习的一种。传统的卷积神经网络包括特征提取部分和分类部分。特征提取部分包括输入层、卷积层和池化层,而卷积层和池化层可能不止一个;分类部分包括全连接层和输出层。卷积神经网络结构如图1所示。
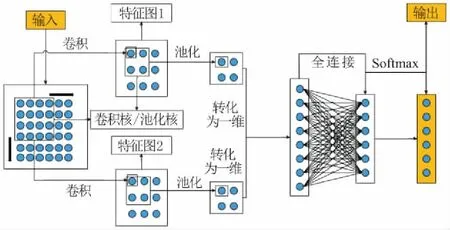
图1 卷积神经网络
卷积神经网络的输入数据为二维数组,输入数据大小inputsize=n×m,其中n,m分别为输入二维数组的列数和行数;卷积核大小Kernelsize=h×w,其中h,w分别为卷积核的长和宽;卷积核窗口的步长1×1,特征图的数目为f。同一特征图的卷积核共享权重和偏置,不同特征图之间权重和偏置不同,这就意味着不同特征图之间提取了输入数据的不同特征。那么在卷积层中,权重数量N为:
N=f×h×w
(1)
f为偏置的数量。所有特征图的大小为:
figsize=(n-h+1)×(m-w+1)
(2)
下面连接着激活函数ReLU,ReLU函数为:
f(x)=max(0,x)
(3)
x为特征图上点的值,被用在任意2个卷积层和池化层之间。接下来是池化层,本文使用最大池化的方法,选择池化核中的最大值,池化核大小为Kernel=h_×w_,这样得到了全部较小的特征图。通过平滑处理,将所有较小特征图从二维转换为一维,并连接成一个向量。全连接层可以提取深度特征,通常采用2个全连接层。其中后面全连接层的大小为1×n_class,n_class是需要分类的类别数。最后用Softmax激活函数来计算数据属于每个类别的可能性。Softmax函数如下:
(4)
Si表示数据i类别的概率;Vi为Softmax函数输入的第i个单元的值。
学生管理工作是一项很复杂的工作,大学生具有自主意识,管理者需要充分考虑学生的心愿,关心学生的发展,将自己的关怀和情感投入到学生管理中,才能实现双方的相互体谅,让学生感恩于辅导员的工作,修正自己的错误。社会环境是复杂的,学生自身的能力、素质不同,辅导员要想占据管理的主动地位还需要不断提升工作效率。管理学生并不是强制性的,管理人员应充分尊重学生、爱护学生,认识到学生个性发展的需求,培养学生的主动性和积极性,促进学生全面的发展。
本文使用交叉熵函数作为损失函数:
(5)
y为数据的实际类别;a为预测数据的类别。本文使用梯度下降法来最小化损失函数LH,得到所有连接权重和偏置。更新规则如下:
(6)
W和b分别代表权重和偏置,η是学习率,η>0。
1.2 迁移学习
迁移学习需要在已训练好的模型中,找到某些可以在待求解问题中被用来当作特征的层次,然后将新的数据输入该层,提取其特征,其输出特征作为新的网络输入,新的网络结构可以根据不同问题改变。该方法的优势在于,预训练模型已经在大量数据上进行了训练,故其特征较为良好,因此,基于特征的迁移学习可以节省一部分特征提取的过程,使网络结构更为简单。同时,该方法还可以解决数据不足的问题。如果在新的问题中,数据量不足,那么将很难提取有效的特征,这时,可以直接采用预训练模型的特征,在新的问题上定义分类器即可。
假设已经在大量历史数据下训练好了模型,接下来用迁移学习的思想,对该模型进行微调,得到适用于目标数据的预测模型,如图2所示。固定卷积神经网络结构不变,将输入数据和输出标签替换为目标数据,对已有网络进行微调训练。微调时,损失函数和更新规则保持不变。

图2 迁移学习
2 液压泵健康状态评估方法
液压泵随着其工作时间的推移,其健康状态逐渐恶化,由于泄漏量越来越大,其流量的波动逐渐变大,导致振动加剧。同时,随着液压泵泄漏增大和压力损失的增大,其出口压力会变得更加不稳定,会导致压力无法达到峰值。
实验测得全新的液压泵(工作0 h)、工作2 000 h的液压泵和工作3 500 h的液压泵的压力信号,如图3所示。由图3可知,压力信号呈现脉动特征,但不同健康状态的液压泵压力峰值不同。随着已工作时间的变长,液压泵的压力峰值逐渐降低。工作2 000 h的液压泵压力峰值有时达不到最大值,而工作3 500 h的液压泵其压力峰值则为不稳定。
取各健康状态的一段时间的出口压力,通过公式
(7)

表1 通过压力均值标记液压泵的健康状态
做好数据标记后,要对液压泵的振动信号建立深度学习和迁移学习模型,其流程如图4所示。采集目标数据和其他条件下数据(辅助数据)的振动信号;将时域信号转化成频域信号后,用卷积神经网络对辅助数据建立预训练模型;模型训练好之后,把模型的结构保留,将输入数据和其标签换成目标数据,对模型进行微调;最终得到模型,在目标数据中的测试数据上进行预测。
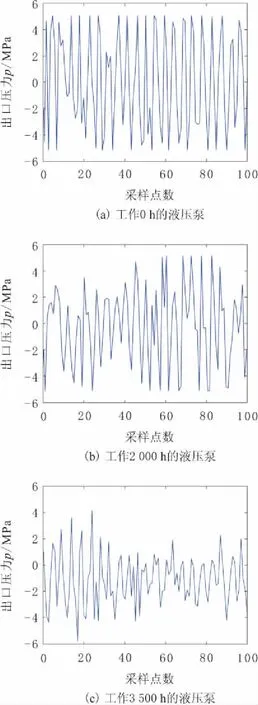
图3 不同健康状态下的液压泵出口压力信号
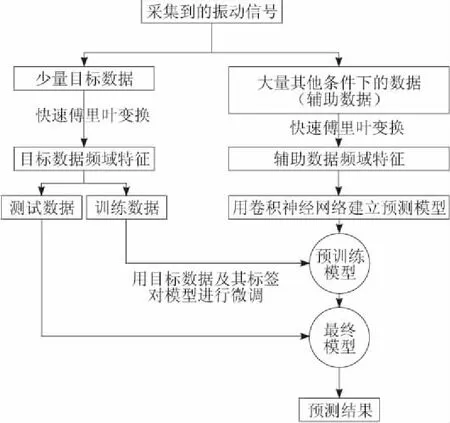
图4 液压泵健康评估算法流程
3 实验验证
本文进行了液压泵的实验,用深度学习和迁移学习算法对实验数据建立预测模型,并测试了预测准确率。
实验液压系统装置如图5所示,其液压系统原理如图6所示。实验装置包括电机、待测泵、振动传感器、溢流阀、油箱和压力传感器。实验室中采用的是川崎斜盘式轴向柱塞泵K3V112DTH100R2N01,共有3种不同健康状态的泵,分别为全新的1号泵,使用约2 000 h的2号泵,已经使用3 500 h即将报废的3号泵。分别在1 500 r/min,2 200 r/min转速条件下运行大约800 s,用不同传感器记录运行过程中的各种信号,包括振动、压力和温度等信号。其中,用压力信号对数据进行标记,用振动信号对液压泵建立预测模型。实验测得数据的保存为振动信号和模拟信号2种。振动传感器有3个,分别安装在泵主轴的左上、右上和正下方,两两之间呈120°分布。采样频率为50 kHz,总数据点数超过4 000万。

图5 实验室液压系统
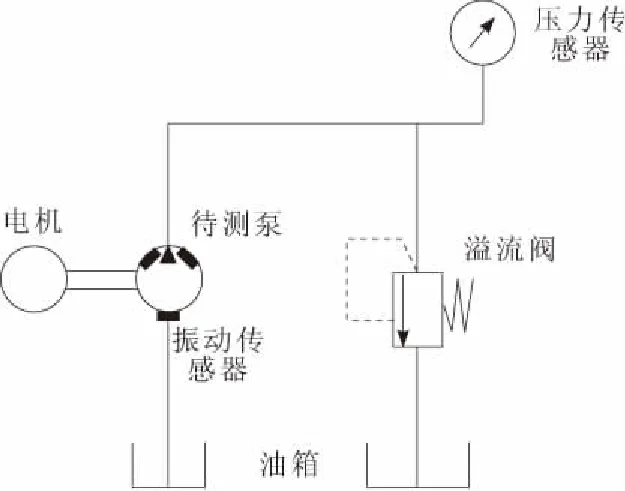
图6 液压系统原理
首先,通过计算出口压力均值,利用表1的计算结果对数据的健康状态进行标记。
然后,对采集的振动数据进行时频转换,得到不同健康状态的液压泵的频域特征,作为卷积神经网络的输入。
图7显示了工作3 500 h液压泵振动信号的频域特征,首先对其进行归一化操作,这样可以使网络训练的速度加快。归一化函数为:
(8)

图7 工作3 500 h液压泵振动信号频域特征
x为某一频率点的幅值,将所有数据转化到区间[-0.5,0.5]上。然后把这些一维数组特征分成若干组,每组包含相同数量的数据,每组占据一行,把它们堆叠成一个二维数组,作为卷积神经网络的输入。
接下来,使用深度学习和迁移学习的方法进行实验。实验中,分别在1 500 r/min,2 200 r/min转速下采集了3种不同健康状态的液压泵。选择1 500 r/min转速下采集到的数据作为目标数据,其中,每类健康状态的目标数据取50个。选择2 200 r/min转速下的数据作为辅助数据进行实验,每类健康状态的辅助数据取500个。
本文中,卷积神经网络的输入为50×40大小的数组,第一卷积层卷积核大小为5×5,步长为1×1,特征图个数为32,第一池化层池化核大小为2×2;第二卷积层卷积核大小为5×5,步长为1×1,特征图个数为64,第二池化层池化核大小为2×2。全连接层为128个单元。
在辅助数据上训练卷积神经网络模型,用于提取深度特征。在此,采用辅助数据每类数据500个,作为卷积神经网络的输入,训练完成后,保存模型。然后改用目标数据在保存的预训练模型上进行迁移学习任务,对网络进行微调。该实验与直接用目标数据训练深度卷积神经网络进行对比,实验结果如图8所示。
结果显示,经过辅助数据预训练的网络,初始准确率即可达到66.8%,并且很快(不到10轮)准确率达到了99%以上。而仅用目标数据进行深度学习的训练时,初始准确率只有12.4%,随着训练轮次的增加,其模型准确率会有较大的波动。进行25轮迭代,准确率才能达到90%以上。

图8 深度学习与基于深度学习的迁移学习的方法对比
接着,本文用不同数量的目标数据和辅助数据进行实验,验证本文方法的效果。目标数据取每类健康状态的数据,分别为10个、30个、50个和100个,辅助数据取目标数据的10倍,进行基于深度学习和迁移学习的实验,实验结果如表2所示。
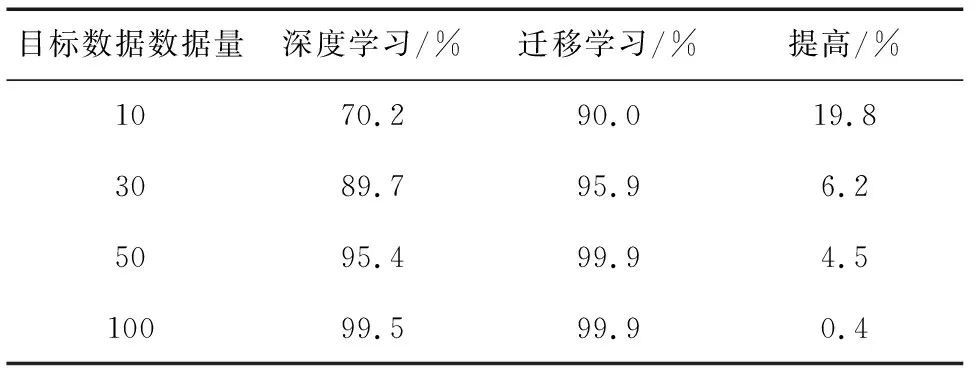
表2 不同数据量下深度学习与基于深度学习和迁移学习的结果对比
表2比较了深度学习和基于深度学习和迁移学习在不同目标数据量下的测试准确率。可以发现,在不同数量的目标数据下,本文提出的方法预测准确率较深度学习的方法有较大提高,且数据量越少,预测准确率提高越大。当每类目标数据为10个时(此时辅助数据为每类100个),本文提出的方法其准确率可达90.0%,相对于深度学习提升了19.8%,而当目标数据量为50时(此时辅助数据为每类500个),本文提出的方法其准确率可达99.9%。
4 结束语
本文提出了一种基于深度学习和迁移学习的液压泵健康评估方法。这种方法适用于目标数据量较少,不足以训练出一个较好的预测模型,但有较多辅助数据的情况。对液压泵进行了实验,得出了以下结论:
a.本文提出的方法在训练过程中,初始准确率、训练速度及最终准确率与深度学习相比,都有较大提高,且最终准确率可以达到99%以上。
b.本文提出的方法在不同目标数据量下,预测准确率都有较大提升,且数据量较少时,预测准确率提高得更为明显,说明该方法适用于目标数据较少的情况下。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
现代制造技术与装备(2021年9期)2021-04-03 13:44:40
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年11期)2019-07-04 00:34:38
通信电源技术(2018年5期)2018-08-23 01:15:34
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国修船(2014年5期)2014-12-18 09:03:08
