
APMSS:一种具有非对称接口的固态存储系统
2018-09-21 03:26:44牛德姣贺庆建詹永照
计算机研究与发展 2018年9期
牛德姣 贺庆建 蔡 涛 王 杰 詹永照 梁 军
(江苏大学计算机科学与通信工程学院 江苏镇江 212013)(djniu@ujs.edu.cn)
计算机系统中各部件的发展具有很大的不均衡,当前存储部件的读写速度远低于计算部件的处理能力,这导致了严重的存储墙问题[1].由于存在机械部件,传统的磁盘很难有效提高读写速度.基于Flash的固态存储设备具有较高的I/O性能,但存在写寿命短和仅支持以块为单位的读写操作等问题.当前出现了一系列NVM存储器件,如PCM[2],STT-RAM[3]和RRAM[4]等,具有支持以字节为单位的读写、较长的写寿命、低功耗和接近DRAM的读写速度等优势,成为解决存储墙问题的重要手段;同时NVM存储器件的写寿命和读写速度也还在不断提高.此外3D XPoint等技术的出现,使得用NVM改造现有基于Flash的固态存储设备、构建新型的高速固态存储系统成为当前研究的热点.
但现有I/O系统软件栈是面向低速外存系统所设计,难以适应高速固态存储系统读写性能较高的特性,相关研究表明在新型固态存储系统中I/O系统软件的开销占总开销的63%以上[5],因此如何提高I/O系统软件的效率是固态存储系统中需要解决的重要问题.PCIe固态存储设备是当前构建高速固态存储系统的重要基础,但其具有较大的局限性;为了获得较高的传输效率PCIe接口以支持块访问方式为主,虽然可以改变每次传输的大小,但效率和灵活性还较低.当前操作系统还是使用块接口访问PCIe固态存储设备,无法利用内部NVM存储器件支持字节粒度读写的特点;在执行写操作时,以数据块为单位的方式存在写放大的问题,严重影响了固态存储系统的读写性能和使用寿命;在执行读操作时,以数据块为单位读出的数据能用于基于局部性原理构建的读缓存,从而提高访问存储设备时的读性能,同时读操作对固态存储系统的寿命也没有影响.因此有必要针对分析读写操作的不同特性,研究管理粒度和方式不同的读写操作接口,用于构建高效的固态存储系统.
我们设计具有非对称接口的固态存储系统,以提高I/O性能和延长其使用寿命.本文的主要贡献有4个方面:
1) 针对读写操作的不同特性,分离文件系统所提交的读写访问请求,有效利用固态存储系统内部支持字节读写的特性.
2) 设计了多粒度的固态存储系统映射算法,修改通用块层的结构,为解决写放大问题提供支撑.
3) 设计了动态粒度写算法,避免写放大问题,提高固态存储系统的写性能和延长其使用寿命.
4) 实现了一个具有非对称接口固态存储系统的原型(APMSS),使用Fio和Filebench进行了测试,验证了APMSS具有更高的写性能.
1 相关工作
当前的研究主要集中在使用NVM提高存储系统的性能和针对固态存储系统的新型文件系统方面.
1.1 新型NVM文件系统方面的研究
BPFS[6]和PMFS[7]是针对字节寻址的NVM存储设备的新型文件系统,提高I/O性能,降低读写延迟.BPFS使用短周期的影子分页法实现8 b的原子写操作和以及更细粒度的更新操作,并实现了硬件上写操作的原子性和顺序性.PMFS分离了元数据和数据的一致性保护方法,使用细粒度日志保护元数据的一致性;同时使用CoW策略实现数据写操作,保护文件系统的可靠性和一致性.文献[8]设计了SCMFS,使用操作系统的MMU管理NVM存储设备中的数据块,同时使用连续虚拟内存空间管理单位文件简化读写操作;并使用clflush/mfence机制保障执行文件访问操作的顺序,但没有给出如何保障文件系统的一致性.文献[9]设计了Aerie,通过直接让用户态程序访问NVM存储设备中的数据,避免现有I/O系统软件栈需要进行内核和用户态切换的时间开销,同时也提供了POSIX接口以支持现有应用;同时使用Mnemosyne[10]中的tornbit RAWL策略,保护文件系统的一致性.PMFS分离了元数据和数据的一致性保护方法,使用细粒度日志保护元数据的一致性;同时使用CoW策略实现数据写操作,保护文件系统的可靠性和一致性.文献[11]针对现有以数据块为单位的写操作机制中,存在写少量数据需先完成冗余读操作的问题,修改虚拟文件系统设计了非数据块粒度的写机制,应用于磁盘能提高7~45.5倍的写性能,应用于基于Flash的SSD能提高2.1~4.2倍的写性能.NOVA是针对DRAM和NVM混合情况的日志文件系统[12],通过为每个inode节点维护一个日志提高并发性和用原子更新实现日志的追加等,在保护文件系统的一致性和操作原子性的同时,能相比现有具有一致性保护的文件系统能提高3.1~13.5倍的性能.FCFS是针对NVM的新型文件系统[13],设计了多层次的混合粒度日志,针对元数据和数据分别使用redo和undo策略,针对应用的选择性并发检查点机制减少了需保存的数据量,使得上层应用的性能提高了近1倍.HMVFS是针对DRAM和NVM混合情况设计的多版本文件系统[14],通过轻量级的快照技术保护文件系统的一致性,使用内存中的Stratified File System Tree (SFST)保护多个快照之间的一致性,相比BTRFS和NILFS2能有效减少快照所需的开销.HINFS是面向NVM设计的高性能文件系统[15],给出了针对NVM主存的写缓存机制、以及DRAM中索引与缓存行中位图相结合的读一致性机制,并设计了基于缓存贡献模型的NVM主存写机制.文献[16]针对事务内存设计了模糊持久性策略,通过基于日志的执行和易失性的检查点机制,减少了实现事务机制的开销,能提高56.3%~143.7%的文件系统I/O性能.SIMFS[17]是一种能利用虚拟内存管理机制的内存文件系统,每个被访问的文件都拥有一个独立的连续虚拟地址空间,数据地址空间的连续性可以支持高速的顺序访问,而且独立空间的划分方式可以避免文件访问中的地址冲突问题,同时SIMFS还使用层级结构的文件页表(file page table)技术来组织文件数据,从而保证了SIMFS可以使内存带宽接近饱和.文献[18]在NOVA的基础上设计了NOVA-Fortis,提高NVM文件系统容忍存储器件错误和软件系统bug的能力,相比现有没有容错功能的DAX文件系统能提高1.5倍的读写性能,相比基于块的文件系统能提高3倍的读写性能.DevFS通过将文件系统嵌入到NVM存储设备中,能提高NVM存储设备2倍的吞吐率[19].
1.2 减少NVM系统软件栈开销的研究
文献[20]分析了使用不同控制方式访问PCM存储设备时的效率,发现使用轮询和同步读写策略、相比使用中断和异步读写策略能有效减少访问PCM存储设备时的I/O软件栈开销.文献[21]验证了在读PCM存储设备中的数据时,使用轮询能减少接口数据在用户态与内核态之间切换的开销,提高读性能.文献[22]和文献[23]设计了基于硬件的元数据和数据访问路径分离的方式,在用户态直接访问NVM存储设备中的数据,减少元数据的修改次数,提高访问NVM存储设备的I/O性能.BPFS[6]抛弃块设备接口,在用户态使用load和store指令直接访问DIMM接口的NVM存储设备,构建了一个全新的存储系统I/O软件栈.Mnemosyne是针对DIMM接口NVM存储设备设计的轻量级访问接口[10],实现了在用户态空间中管理NVM存储空间和保护文件系统一致性等问题.NVTM是一个面向NVM的事务访问接口[24],将非易失存储器直接映射到应用程序的地址空间,允许易失和非易失数据结构在程序中的无缝交互,从而在读写操作中避免操作系统的介入,提高数据访问性能.NV-heaps是针对NVM存储设备的一个轻量级的高性能对象存储系统[25],减少存储系统软件栈的开销,相比BerkeleyDB和Stasis能提高32倍和244倍的执行速度.文献[26]针对使用NVM存储设备构建SCM时,块访问接口无法附加优化存储系统性能信息的问题,设计了基于对象的SCM;文献[27]针对SCM,设计了一种新型的控制器和相应的函数库,通过操作之间的解耦合,减少存储系统软件栈的开销,并支持并发的原子操作;文献[28]在分析不同事务之间关联性的基础上,设计了DCT减少事务提交顺序之间的影响,并提高事务的执行效率;文献[29]在ISA的基础上,从程序执行路径中移除日志操作,使用动态标签减少移动日志数据的开销,借助硬件减少日志管理的开销,从而高效的实现访问NVM时操作的原子性;文献[30]设计了Stampede开发套件,能提高应用访问硬事务内存(HTM)和软事务内存(STM)时的性能,同时简化了STM的设计,使得Blue Gene/Q 上64线程和Intel Westmere上32线程的性能分别提高了17.7倍和13.2倍.Path hashing能避免对NVM的额外写操作,提高执行速度,减少所使用的NVM存储空间[31];文献[32]针对PCM设计了基于页的高效管理方式,适应上层应用的访问方式,首先使用双向链表管理PCM中的页,再使用DRAM构建了PCM页的缓存并设计了基于进入时间的淘汰算法,最后综合页迁移和交换信息优化了PCM中页的分配;文献[33]混合使用SSD和磁盘设计了I-CASH,利用SSD提供高速随机读性能,利用处理器中多个计算核心的强大计算能力和磁盘构建SSD中数据的日志,减少对SSD的随机写操作,在延长SSD使用寿命的同时,提高随机写的性能.
本文设计了具有非对称接口的固态存储系统,将读写访问请求进行分离,并针对读写访问请求的不同特性设计了相应的管理算法和多粒度的固态存储系统映射算法,从而能降低固态存储系统写放大问题,有效利用固态存储系统内部支持字节读写的特性,提高固态存储系统的写性能和延长其使用寿命.
2 具有非对称接口固态存储系统的结构
数据块是传统磁盘的数据组织和管理单位,现有的存储系统I/O软件栈在访问存储设备时也是以数据块为基本单位.这使得在访问块接口固态存储系统时无法利用NVM存储器件支持字节读写的特性,也没有利用PCIe接口能动态调整数据传输粒度的优势.在执行写操作时,存在严重写放大问题,同时还会严重影响固态存储系统的使用寿命,降低了块接口固态存储系统的I/O性能.而读操作不会影响固态存储系统的寿命,较大粒度的读操作也有利于实现数据的预取,提高读操作的性能;同时较大的读粒度也能减少读操作的数量,降低存储系统软件栈的开销.
我们给出具有非对称接口固态存储系统的结构,如图1所示.包括位于驱动层中的动态粒度写模块和面向缓存的读模块,以及位于通用块层中的多粒度映射模块等主要部分,同时去掉了写缓存,将存储设备和文件系统之间的缓存仅仅作为读缓存.多粒度映射模块用于在文件系统写固态存储系统前获得实际写数据的地址和大小等信息,从而动态改变PCIe接口的传输量;访问请求分析器实现对文件系统访问请求的分析,将读和写访问请求分解到对应模块执行;动态粒度写模块依据实际写数据的大小,在固态存储系统内部以字节为最小粒度执行写操作,避免写放大问题;面向缓存读模块负责以数据块为单位读取NVM存储器件中保存的数据,并反馈给文件系统.
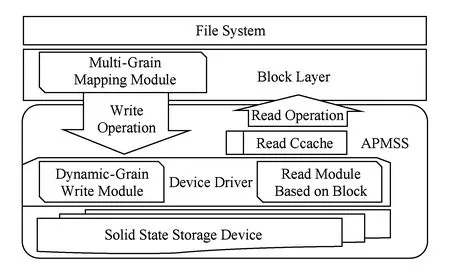
Fig.1 Structure of new solid storage system with asymmetric interface图1 具有非对称接口固态存储系统的结构
3 最小化直接写机制
固态存储系统的写操作会消耗存储器件的使用寿命,因此如何减少写入固体存储系统的数据量是一个重要问题.
在现有的存储系统写机制中,文件系统首先使用块粒度组织需要写入固态存储系统的数据,再通过以块为单位的映射表查找写入存储系统的地址,最后以块为单位向存储系统传输并写入数据.当仅需要向固态存储系统写入少量数据时,存在较严重的写放大问题,在影响固体存储系统使用寿命的同时,还会因为无效写操作影响写性能.
我们从改变写算法和映射算法两方面入手,设计固态存储系统的最小化直接写机制.
3.1 动态粒度固态存储系统写算法
对文件系统的写访问请求,我们以其实际写数据量为基础,动态调整写入固态存储系统的数据量,避免写放大的问题.
定义write_pos∈N表示写入数据的起始地址,当write_pos=-1时表示不启用动态粒度写算法.
定义write_len∈N表示写入数据的长度.
如图2所示,当写入数据量小于系统数据块大小时,首先在文件系统层中获取写入数据块中的write_pos和write_len,根据write_len设置PCIe传输的数据量,仅将写入数据、write_pos和write_len传输给固态存储系统,最后根据write_pos和write_len将数据包写入NVM存储器件的相应位置.
如图3所示,当写入数据量大于系统数据块大小时,同样首先在文件系统层中获取写入数据块的地址和大小,接着按照最大为系统数据块大小将写入数据分成若干个数据包,并以实际大小构建最后一个数据包;若数据包的大小等于数据块,则设置write_pos=-1,采用现有块为单位传输方式,并由固态存储系统将数据包作为一个数据块写入设备;若数据包小于数据块的大小,则从该数据包中获取write_pos和write_len的信息,设置PCIe接口的传输数据量、并发送数据包、write_pos和write_len,最后固态存储系统根据write_pos和write_len将数据包写入相应位置.
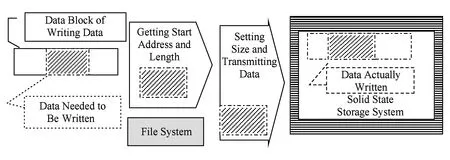
Fig.2 The write process with actually written data less than size of data block图2 写入数据量小于系统数据块大小时的写流程

Fig.3 The write process with actually written data larger than the size of data block图3 写入数据量大于系统数据块大小时的写流程
3.2 多粒度的固态存储系统映射算法
文件系统首先将写入固态存储系统的数据首先保存在内存中,通过内存与存储系统之间的映射表,确定写入存储系统的地址和长度后再写入存储系统.现有的存储系统映射表均是以数据块为单位进行组织和管理,这使得内外存之间的数据交换只用以数据块为单位.
我们设计多粒度的固态存储系统映射表,在每个映射项内增加dirty_pos∈N和dirty_len∈N,保存内外存之间多粒度的映射信息.其中dirty_pos表示在该数据块中需要更新到存储系统数据区的起始地址,dirty_len表示该数据块中需要更新到存储系统数据区的长度.当dirty_pos=-1时,表示该数据块不采用多粒度映射算法.
使用S∈N和L∈N分别表示要写入数据起始逻辑地址与长度,针对每次写操作使用3步骤修改固态存储系统映射表,实现多粒度的内外存映射算法.
步骤1.依据S查找固态存储系统映射表中所对应的映射项,如S与该映射项的起始地址相同且L的值与数据块大小相同,则将该映射项的dirty_pos=-1,否则将S对应的物理地址保存到dirty_pos中.
步骤2.比较L的值是否超出了该映射项对应逻辑块的长度,如未超出,则使用L设置dirty_len的值,并将L的值清零;否则依据数据块大小和dirty_pos计算出dirty_len的值,并更新S和L.
步骤3.如果L=0则结束整个操作,否则回到步骤1继续做.
图4给出了一个涉及3个映射项的写操作中计算每个映射项dirty_pos和dirty_len的情况.

Fig.4 Calculating dirty_pos and dirty_len in mapping table between memory and PCIe NVM Device图4 固态存储系统映射表中计算dirty_pos和dirty_len
通过多粒度固态存储系统映射算法,在每个固态存储系统映射项中标识实际需要写入数据的起始地址和长度,使得动态粒度固态存储系统写算法能获得实际需要写入的数据块信息,避免了文件系统与固态存储系统之间只能以数据块为单位交换数据的局限,为解决固态存储系统的写放大问题提供了支撑,从而提高固态存储系统的使用寿命和写性能.
4 基于块的读机制
读操作不会影响固态存储系统的寿命,同时较大的读操作粒度能利用局部性原理实现数据的预取,通过构建读缓存,提高读操作的性能;此外I/O操作中的系统软件开销已经成为影响固态存储系统读写性能的重要因素,同时NVM存储器件的读操作速度高于写操作,因此在固态存储系统的读算法中减少读次数,能有效降低存储系统软件栈的开销.
我们以数据块为单位执行固态存储系统的读操作,如图5所示;首先由文件系统获取读操作所在的数据块信息,并向固态存储系统发出读请求,固态存储系统读出数据后以块为单位传输给文件系统.

Fig.5 The process of read strategy based on block图5 基于块读机制的流程
以数据块作为读操作的单位,能与现有文件系统和缓存中数据的管理粒度保持一致,避免数据管理粒度转换等额外I/O栈软件开销,提高读操作的效率;同时文件系统与固态存储系统之间,每次的传输单位均一致,避免了频繁修改PCIe接口的参数,能减少了传输中的额外软件开销,提高读操作的性能.
5 原型测试与分析
我们首先实现具有非对称接口固态存储系统的原型,再使用通用的测试工具进行测试,并加载不同的文件系统进行分析与比较.
5.1 原型系统的实现
我们在块接口固态存储系统PMBD[34]的基础上实现APMSS的原型.在模拟NVM存储器件时,使用PMBD的缺省配置,在DRAM的基础上增加85 ns的读延迟和500 ns的写延迟模拟NVM介质;同时修改Linux内核,在内核地址的尾部预留10 GB内核空间作为PMBD的存储地址空间.
此外我们修改Linux内核中通用设备层管理内外存映射结构buffer_head,增加dirty_pos和dirty_len两个指针用于保存需要实际需要写回存储系统的数据位置和长度信息,并修改内外存映射的源代码实现多粒度的固态存储系统映射算法;再修改Linux内核中与设备驱动交互的bio结构,增加write_pos和write_len保存从buffer_head结构获得的dirty_pos和dirty_len信息;最后修改PMBD的源代码,将实际写回数据的位置和长度信息传递到给固态存储设备,增加动态粒度写算法、基于数据块的读算法和读写请求区分器,从而在执行写操作时利用NVM存储器件字节寻址特性,仅写入实际修改的数据;从而构建具有非对称接口固态存储系统的原型系统APMSS.
使用存储系统通用测试工具Fio和Filebench测试APMSS原型的写性能,测试环境的配置如表1所示.在测试时,所有的Ext4均使用DAX方式.

Table 1 The Configuration of Testing Environment表1 测试环境的配置
5.2 读写不同大小文件的性能
首先使用Ext4格式化APMSS,再应用Fio中Linux异步I/O引擎libaio,调整文件的大小分别为8 KB,32 KB,128 KB和512 KB,测试APMSS顺序读写3万个文件时的I/O性能,访问块大小设置为4 KB;并在PMBD上Ext4和Ext2执行相同测试,进行对比和分析.测试结果如图6和图7所示.

Fig.6 Sequential write performance with different size files图6 顺序写性能的测试

Fig.7 Sequential read performance with different size files图7 顺序读性能的测试
图6是顺序写性能的测试结果,从图6中可以看出:
1) 采用APMSS能有效提高Ext4的写性能.当文件大小为128 KB时,相比PMBD写性能提高了14%;同时还改变了Ext4写性能低于Ext2的情况,相比Ext2 on PMBD写性能提高了9.6%.这说明APMSS能针对固态存储系统的特性,使用动态粒度写算法通过仅仅写入实际修改的数据,避免写放大问题,提高写性能.
2) 当单个文件大小增加后,写相同数据量所需访问文件的次数不断下降,减少了读写文件元数据所需的时间开销,使得写速度不断提高;在单个文件从8 KB增加到512 KB后,APMSS的写性能提高了9倍多,而PMBD上的Ext4和Ext2仅增加了8.2倍和7.4倍,这表明APMSS相比现有块接口固态存储系统具有写性能的优势,同时能利用APMSS最小化写机制和内部支持字节写的特性减少读写文件元数据所需的时间开销.
3) 在改变所写文件大小时,APMSS上的Ext4的写性能始终高于PMBD上的Ext4,同时所提高的写性能绝对值随着文件大小的增加而不断提高,这和2)中类似,是由于减少了管理文件元数据的时间开销,这也进一步表明APMSS最小化写机制的有效性.在所写文件的大小从8 KB增加到512 KB时,写性能提高的速度呈现先增加后下降的趋势,在文件大小为128 KB时达到最大值,这是由于文件元数据读写速度不断提高并逐步接近文件系统处理文件元数据速度,消弱了文件写性能的提高幅度,这也表明APMSS能减轻存储系统所导致的计算机系统性能瓶颈.
图7给出了顺序读的测试结果,从图7中可以看出APMSS和PMBD上的Ext4具有相同的读性能,这主要由于APMSS能利用非对称接口区分读写操作,使用以数据块为粒度的方法处理读操作,避免在提高读写操作灵活性的同时对读性能产生影响,验证了APMSS具有良好的适应能力;同时可以发现对读写访问请求进行区分、采用不同的管理机制所可能增加的额外管理开销非常小,没有发现对APMSS的读性能照成影响.
5.3 改变读写文件大小时的访问请求处理效率
使用3.2节中相同的测试工具和设置,测试APMSS,PMBD上Ext4和Ext2处理访问请求的速度,测试结果如表2和表3所示.
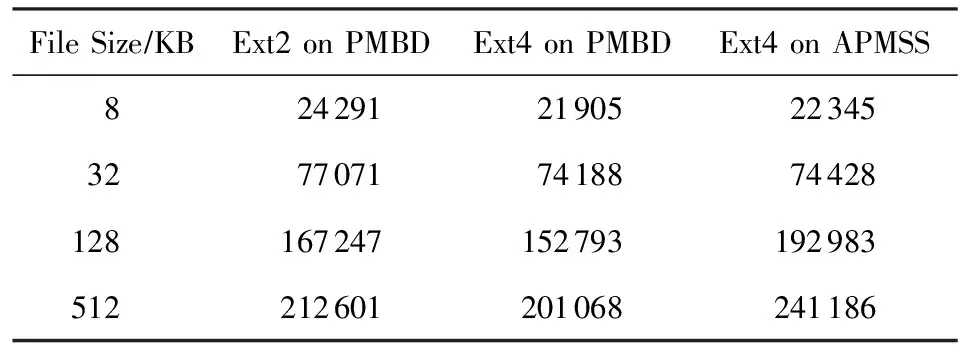
Table 2 The IOPS of Sequential Write表2 顺序写时的访问请求处理速度(IOPS)

Table 3 The IOPS of Sequential Read表3 顺序读时的访问请求处理速度(IOPS)
从表2和表3的测试结果中可以看出:
1) 读写访问请求处理速度的测试结果与I/O性能的测试结果类似.
2) 在执行写操作时,APMSS上Ext4处理写访问请求的速度高于PMBD上Ext4和Ext2,特别是针对PMBD上Ext4具有较大的优势,随着文件大小的增加,APMSS上Ext4相比PMBD上Ext4所提高的IOPS越来越显著,这验证了APMSS最小化直接写机制能有效避免写放大的问题.
3) 在执行读操作时,APMSS和PMBD上Ext4处理访问请求的速度相同,这验证了APMSS具有良好的适应能力,能区分读写操作,使用基于数据块的方法完成读访问请求,有利于发挥固态存储系统中读缓存的作用;同时也表明区分读写访问请求分别使用不同的管理策略可能增加的额外管理开销非常小,对APMSS的执行读操作时的IOPS没有影响;因此这些结果表明,APMSS在提高写访问请求处理速度的同时保持读访问请求的处理效率.
5.4 改变访问块大小时的IO性能
同样使用Ext4格式化APMSS,应用Fio中Linux异步I/O引擎libaio,改变文件系统中访问块的大小分别为4 KB,8 KB,16 KB和32 KB,测试APMSS顺序读写3万个512 KB文件时的I/O性能;并在PMBD上Ext4和Ext2执行相同测试,进行对比和分析.测试结果如图8和图9所示.

Fig.8 Sequential write performance with different block sizes图8 设置不同大小访问块时的顺序写性能
从图8中可以发现:
1) 随着访问块的增加,APMSS相比PMBD提高写性能的效果越来越明显.
2) 当访问块大小为4 KB时,APMSS上Ext4相比PMBD上Ext4和Ext2能提高2%~4%的写性能.
3) 当访问块大小为32 KB时,APMSS上Ext4的写性能相比PMBD上Ext4提高了22%、相比PMBD上Ext2提高了20%.
4) 综合2)和3)可以发现,当访问块增大后,单个访问块内实际需要写入固态存储系统数据所占的比重也随之下降,使得PMBD上的写放大问题越来越严重,对写性能的影响也就越明显;但同时APMSS中最小化直接写机制的效果也就越显著,使得APMSS在访问块较大时写性能的优势更加显著.
5) 随着访问块从4 KB增加到32 KB,写3万个512 KB文件所需写访问请求的数量逐渐下降,减少了I/O软件栈的开销,使得APMSS的写性能提高了约1倍;而同时PMBD上的Ext4和Ext2仅提高了70%;这进一步说明APMSS相比现有的块接口固态存储系统具有写性能的优势.
此外使用相同的配置,改变文件系统中访问块的大小,测试顺序读3万个512 KB文件的性能,结果如图9所示:

Fig.9 Sequential read performance with different block sizes图9 设置不同大小访问块时的顺序读性能
从图9中的结果可知,APMSS和PMBD上的Ext4具有相同的读性能,这验证了APMSS在提高写性能的同时,不会因为需要区分读写操作而影响其读性能.
5.5 应用综合应用负载时的测试
同样使用Ext4格式化APMSS,应用Filebench来模拟应用服务器的访问情况,选择Copyfile,Webserver和Fileserver三种类型负载测试APMSS的I/O性能,设置文件大小为32 KB、文件数量为5万个、访问块大小为4 KB,与PMBD上的Ext4进行比较,测试结果如图10所示.

Fig.10 The I/O performance with different real workload图10 不同真实负载下的I/O性能
Copyfile负载是模拟用户复制文件目录树的行为,主要测试系统持续读写性能.在应用Copyfile负载时,从测试结果可以发现APMSS上的Ext4能提高6.37%的I/O性能.这主要因为APMSS优化了固态存储系统的写操作,按照实际数据量大小以字节为单位写入固态存储系统,避免了不必要的写操作,提高了其上Ext4文件系统的写性能.
Webserver负载是模拟用户访问Web服务器的负载,主要是文件的读操作.在应用Webserver负载时,APMSS与PMBD上的Ext4的I/O性能基本相同.这主要由于APMSS能利用非对称接口区分读写操作,在使用最小化直接写机制的同时,仍然使用基于数据块的方式完成读访问请求,从而保持了较高的读性能,验证了APMSS具有良好的适应性.
Fileserver负载是模拟文件服务器中文件的共享、读写操作等情况,在应用Fileserver负载时,APMSS上Ext4的I/O性能相比PMBD上的Ext4提高了28.4%.这主要是由于Fileserver负载中的每个访问请求均包含一系列文件的open,write,append,read,close等操作,使得APMSS能发挥最小化直接写机制在处理数据量较小的文件元数据读写时的优势,有效解决写放大问题,提高了应用的性能.
6 总 结
使用NVM存储器件改造现有PCIe固态存储设备是构建新型高速固态存储系统的重要手段.固态存储系统现有块访问方式有很大的局限,存在写放大和无法利用NVM存储器件支持字节读写特性等问题,但同时也有利于获得较高的态存储设备读性能.我们针对固态存储系统设计了最小化直接写机制和基于块的读机制,区分读、写访问操作;在处理写访问操作时,仅将修改的数据写入固态存储系统,避免写放大问题,提高写性能;同时仍然以块为单位完成读访问操作,利用读缓存获得较高的读性能.最后我们在开源的PMBD的基础上,实现了具有非对称接口新型固态存储设系统的原型APMSS,使用存储系统的通用测试工具Fio和Filebench进行测试,并于现有基于NVM的块接口存储系统PMBD上的不同文件系统进行比较,结果表明APMSS上的Ext4相比PMBD上的Ext2和Ext4能提高9.6%~29.8%的写性能,从而验证了所设计的算法能有效提高固态存储系统的I/O性能.
当前我们还未利用固态存储系统内部的并行性优化读写操作的执行效率,下一步我们将针对固态存储系统的内部特性,进一步优化读写操作的性能.
猜你喜欢
上海理工大学学报(2021年3期)2021-07-20 08:04:04
陶瓷学报(2021年1期)2021-04-13 01:33:40
陶瓷学报(2021年1期)2021-04-13 01:32:54
哈尔滨轴承(2020年2期)2020-11-06 09:22:36
发明与创新·大科技(2019年12期)2019-03-17 09:23:31
信息安全研究(2016年4期)2016-12-01 06:06:57
信息安全与通信保密(2016年3期)2016-08-23 01:23:58
中国教育信息化(2015年12期)2015-08-24 07:58:36
导航定位学报(2015年2期)2015-06-05 09:27:42
电测与仪表(2015年10期)2015-04-09 11:48:20
