
一种基于标签传播的两阶段社区发现算法
2018-09-21 03:32郑文萍车晨浩钱宇华
计算机研究与发展 2018年9期
郑文萍 车晨浩 钱宇华 王 杰
1(山西大学大数据科学与产业研究院 太原 030006) 2(山西大学计算机与信息技术学院 太原 030006) 3(计算智能与中文信息处理教育部重点实验室(山西大学) 太原 030006) (wpzheng@sxu.edu.cn)
复杂网络分析在社会学、传染病学和生物学等领域有着广泛的应用[1-3].通常可以用图G=(V,E)表示一个复杂网络,其中V表示网络中个体的集合,E表示个体间联系的集合.社区结构(community structure)是复杂网络的重要特征之一,即一个网络可以分成若干社区,社区内节点之间连接相对紧密,社区间节点连接相对稀疏.有效的社区发现算法可以发现社会网络中的社区结构、生物网络中的蛋白质功能模块等,有助于深入研究各种类型复杂网络的功能模块及其演化特征,对准确地理解并分析复杂系统的拓扑结构及动力学特性具有十分重要的理论意义和应用价值[4-5].
目前复杂网络中的社区发现方法主要有基于图划分的聚类算法[6]、基于谱分析的聚类算法[7]、基于层次的聚类算法[8]和基于密度的聚类算法[9-10]等.Newman提出了一种基于贪心策略的快速社区发现算法(fast modularity maximization, FMM)[11],以最优化模块性为目标函数进行社区合并和更新.Blondel等人提出了BGLL算法[12],随机选择一个节点作为初始社区,迭代选择使当前社区模块性增长最大节点加入当前社区完成社区扩展过程.由于现实网络包含大量的小规模社区,网络社区内部连接数不一定比社区之间的连接数多,导致模块性不能较好地度量社区划分质量.Bai等人[13]基于互补熵理论提出了一种度量网络中社区发现质量的目标函数,该函数综合考虑社区内紧密程度和社区间稀疏程度对社区发现结果进行评价,并以公共邻居数度量节点相似性给出了一种图聚类算法ISCD+.
Raghavan等人提出了标签传播算法(label pro-pagation algorithm, LPA)[14],该算法中起初每个节点拥有独立的类标签,每次迭代中对于每个节点将其标签更改为其邻居节点中出现次数最多的标签,通过迭代,直到每个节点的标签与其邻居节点中出现次数最多的标签相同,则达到稳定状态,算法结束.此时具有相同标签的节点属于同一个社区.LPA算法有接近线性时间的复杂度,但划分过程中,节点更新顺序与标签传播过程存在很大的随机性,使划分结果表现了较强的不稳定性.Barber等人对LPA算法进行改进提出算法LPAm[15],参照随机连接定义节点标签更新方式,使得算法结果具有较高的模块性.然而,LPAm算法可能陷入局部最优解且结果存在不稳定性.Liu等人提出LPAm+算法[16],在LPAm算法之后引入后处理步骤,合并一些小社区进一步提高划分结果的模块性.Li等人基于LPA算法提出一种分阶段的社区发现算法LPA-S[17],依据节点间的相似性更新节点标签,得到初始社区划分;再根据社区相似性进行社区合并,使得最终划分结果中社区内部连边具有较高的密度.
以上算法主要针对LPA节点标签更新过程的不确定性进行了改进,并对划分结果进行适当处理以缓解过早陷入局部极值的问题.尽管如此,这些算法没有处理节点标签更新顺序的随机性,使得划分结果仍然存在较大的不稳定性.按合理的顺序选择待更新节点可以提高算法性能并得到稳定的社区划分结果.针对此问题,本文提出了一种基于标签传播的两阶段社区发现算法(a two-stage community detection algorithm based on label propagation, LPA-TS),减少了传统标签传播方法在节点更新和标签传播过程的随机性,可以得到稳定的计算结果;通过与一些经典算法在8个真实网络以及不同参数情况下LFR benchmark人工网络数据集上的实验比较分析,结果表明LPA-TS算法社区发现结果表现了良好的稳定性,且在标准互信息、调整兰德系数、模块性等方面均表现出较好的性能.
1 背景知识
一个复杂网络可以用图G=(V,E)来表示,其中节点集V={v1,v2,…,vn}表示网络个体的集合,边集E代表网络个体间联系的集合,记作边ei,j=(vi,vj).令n=|V|且m=|E|.除非特别声明,本文仅对无向简单图进行讨论.在图G中,节点vi的邻域NG(vi)定义为NG(vi)={vj|(vi,vj)∈E},其中vj∈NG(vi)称为节点vi的邻居节点.节点vi的度为d(vi)=|NG(vi)|,在不引起混淆的情况下,简记为di.假设Ω={V1,V2,…,Vk}是V的一种划分,Vr∈V且|Vr|=nr,称k为该划分中的社区个数.令di(Vr)=|{vj|(vi,vj)∈E且vj∈Vr}|表示节点vi与社区Vr内节点的连边数.


(1)
而弱社区是指社区中所有节点与社区内部节点的度数之和大于社区中所有节点与社区外部节点连接的度数之和:
(2)
默认取α=2.通常一个社区应该至少表现弱社区的性质.
2017年,Bertolero等人定义了节点的参与系数[19],用来刻画节点与网络中不同社区连边的分布情况:
(3)
参与系数的值越高则表示节点与较多社区存在连边,该节点对某社区的归属度比较低;相反,值越低表示节点的连边情况越集中于少数社区,则该节点对某社区的归属度较高.从具有明显社区归属的节点开始进行社区发现,有助于提高社区发现质量,并提高算法稳定性.
为了对社区划分结果进行度量,2004年Newman等提出了模块性[20]的概念,它反映了网络社区内部连接的强弱,作为一种社区划分的评价标准得到了广泛使用.将网络用邻接矩阵A来表示,若节点x与y直接相连,则Ax y=1,否则Ax y=0.模块性定义为
(4)
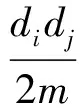
为了合理地对复杂网络中的节点进行社区发现,将节点间相似性作为衡量节点连接紧密程度的重要标准.目前已经有一些基于网络拓扑特征的相似性度量函数[21-22].公共邻居数(common neighbors, CN)度量[21]认为2个节点间的公共邻居节点越多,则它们在结构上越相似,连接越紧密:
CN(x,y)=|NGx∩NGy|.
(5)
2 一种基于标签传播的两阶段社区发现算法
基于节点参与系数与节点相似性,本文给出一种基于标签传播的两阶段社区发现算法(LPA-TS).算法包括2个主要过程:1)根据节点参与系数定义节点的更新顺序,并更新节点标签为与其具有最高相似性的邻居节点标签,得到社区的初始划分结果;2)将当前社区进行合并,并在目标函数的监督下完成社区划分的过程.第1阶段中首先根据节点的参与系数高低,从低到高确定节点的更新顺序;其次依据节点相似性,选择与当前遍历节点最相似的邻居节点的标签作为当前遍历节点的标签,得到第1阶段的划分结果.第2阶段中,将社区作为节点计算其参与系数以确定社区合并顺序,最后在目标函数的监督下将社区进行合并得到最终的划分结果.
2.1 节点更新顺序
在LPA算法中,不同的节点更新顺序会使得最终的社区划分结果有很大差异.如图1所示,可以看出,图1中7个节点应该被分成2个社区.算法初始将每个节点看作1个单独社区,假设当前虚线框住的节点已经被赋予了相同的社区标签.随后,若首先选择节点v4进行标签更新,有很大可能将节点v4与节点{v1,v2,v3}划分到同一社区,进而将所有节点划分为1个社区.而如果选择节点v5进行更新则会有很大可能得到正确的社区划分.这是由于节点v4位于2个社区的边界处,对社区的归属度不强,对其首先更新容易将2个社区合并为1个大社区.

Fig.1 An example network with two communities图1 具有2个社区的网络示例
可以看出,在节点标签更新的过程中,如果先更新归属度较强的社区内部节点的标签,会获得一个更符合实际社区结构且更稳定的划分结果.

从参与系数的定义看,一个节点的度越低,其社区归属程度越高;而一个节点的邻居节点社区归属越集中,其社区归属程度越高.优先选择参与系数低的节点进行更新,可以尽早得到更稳定的社区结构,进而得到更准确的社区划分结果.如图1最终得到2个社区划分{v1,v2,v3}和{v4,v5,v6,v7}.
2.2 标签传播
LPA算法在对节点的标签进行更新时,选取邻居节点的标签中出现次数最多的标签为自身标签,即认为其所有邻居节点的重要性相同,并没有考虑不同邻居节点的不同相似性.然而,在同一个社区中的个体往往具有较高的相似性.如在图1中,节点v4、节点v6和节点v7具有相同PC值,对于节点v4,其邻居节点的标签出现次数均为1,则有较大可能将v4划分入社区{v1,v2,v3},导致错误的划分结果.
实际上,对节点v4而言,社区{v1,v2,v3},{v6}和{v7}中各有一个节点与其关联,从图1中可以看出,由于v4与v6(或v7)有一个公共邻居节点,因此相较于节点v3,v4更有可能与v6(或v7)属于同一社区.
因此,用CN对节点间的相似性进行度量,2个节点间的公共邻居节点越多,则它们在结构上越相似,连接越紧密,在标签更新的过程中选择与其相似性最高的邻居节点的标签,可使最终划分在同一个社区中的节点具有较高的相似性,也更符合实际的社区分布.如在图1中,节点v4确定标签时,由于其与节点v6和节点v7的相似性高于其他节点,故标签会确定为节点v6或节点v7的标签,得到正确的划分.但是公共邻居数度量节点相似性在某些特殊情况下并不适用.例如若节点x和节点y之间存在连边,但无公共邻居节点,但它们之间的相似性应该大于0;特别地,一个悬挂点与其相邻点之间无公共邻居节点,但通常与其相邻点位于同一社区.基于此,本文对节点相似性计算为

(6)
2.3 初始社区发现过程
根据节点更新顺序和标签传播过程,算法给出网络初始划分结果.首先将网络中的每个节点看作一个独立社区,赋予唯一社区标签;计算节点的参与系数PCi(1≤i≤n),按从低到高的顺序依次更新节点标签.节点标签更新过程中,考虑当前节点与其邻居节点的公共邻居相似性,选择相似性最高的邻居节点标签作为当前节点的新标签.以上过程迭代进行,直到划分结果不再变化或者达到最大迭代次数.算法1给出LPA-TS算法的第1阶段即初始社区发现过程.
算法1.初始社区发现算法(LPA-TS第1阶段).
输入:网络G=(V,E)、最大迭代次数tmax,其中V={v1,v2,…,vn},A是图G的邻接矩阵;
输出:网络的初始划分结果L(V)={l1,l2,…,ln},其中,li表示节点vi的初始划分社区标签.
步骤1.根据
计算网络中节点vi和vj间的相似性.

步骤3.计算当前节点标签集合中不同的标签数k=|L(V)|.
步骤4.根据
计算节点vi的参与系数.
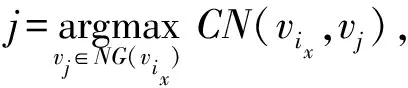
步骤7.t=t+1.
图2给出了在Karate网络上的初始社区发现结果.其中节点被初始划分为4个社区(用不同形状表示).可以看出,算法1的初始社区划分结果中,度数较大节点由于与邻居节点的相似性较高,容易将自身标签传播给邻居节点,从而形成以大度节点为中心的较大社区.而位于社区边缘的一些节点,由于度数偏低且与邻居节点的相似性小,容易形成一些规模较小的社区,如图2中菱形节点和三角形节点构成的社区.
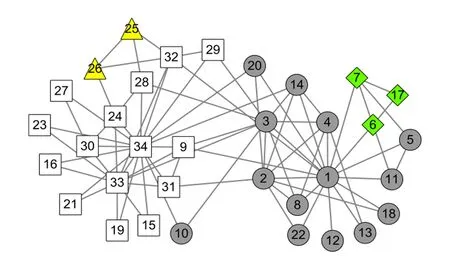
Fig.2 Communities of the Karate network discoveredby Step 1 of LPA-TS图2 LPA-TS第1阶段在Karate网络的初始社区发现结果
随着网络规模的增大,特别是网络连接比较稀疏时,算法第1阶段会得到大量的特别小规模的社区,造成对原始网络的过划分.为了得到更准确的社区划分结果,还需要对初始社区划分结果进行社区合并.
2.4 社区合并过程
针对初始社区发现过程网络过度划分的问题,首先分析得到的初始社区划分结果中,根据式(2)依次判断各初始社区是否满足弱社区的定义.通常情况下,式(2)中的内部度系数α=2,表示一个社区的内部度大于其外部连边数则为弱社区.当所分析网络中包含大量小规模社区时,特别是社区个数远大于单个社区规模时,一个社区的内部度可能会小于其外部连边.为更好地反映网络的社区组成,此时,需要根据网络类型适当提高式(2)中的内部度系数α.
将不满足弱社区定义的初始社区,与其相邻的且具有最多关联边数的社区合并为一个社区.在此为基础上继续进行LPA-TS算法第2阶段的标签传播过程.
将以上所得的每个社区看作一个节点,社区之间连边数作为2个社区对应节点连边的权重,给出该带权无向网络中节点参与系数的定义方式:
(7)

因此,此处仍然按社区对应节点的PC值从低到高的顺序进行标签更新.在节点si的标签更新过程中,选择与其具有最高连边权重的邻居节点标签作为si的新标签.每次节点标签的更新都意味着合并2个初始社区.
为了对节点标签传播过程进行有效控制,需要从社区内部连接紧密程度以及社区间连接的稀疏程度同时考虑社区发现质量,因此本文选择文献[13]提出的基于互补熵的评价函数,对当前社区合并结果进行评价:
(8)
算法2给出了LPA-TS第2阶段社区合并的具体过程.
算法2.社区合并过程(LPA-TS第2阶段).
输入:网络G=(V,E),其中V={v1,v2,…,vn},网络的初始划分结果L(V)={l1,l2,…,ln};
输出:网络的最终划分结果Ω={V1,V2,…,Vk}.


步骤5.计算当前网络划分的评价函数值F(Ωt+1).
步骤6.若F(Ωt+1)>F(Ωt),令t=t+1,返回步骤2;否则,算法2结束,返回Ωt+1为最终结果.
2.5 时间复杂度分析
本文提出的基于标签传播的两阶段社区发现算法LPA-TS包括2个主要过程:
1) 根据参与系数定义节点的更新顺序,并将节点标签更新为与其具有最高相似性的邻居节点标签,得到社区的初始划分结果;
2) 将初始划分结果中的小规模社区与其有最多连边的相邻社区进行合并;本文采用基于互补熵的评价函数F(Ω)作为目标函数对社区发现结果进行判断,得到F(Ω)值最大的社区发现结果作为算法最终输出.
算法1中,计算节点相似性的代价为O(n2),计算节点参与系数的代价为O(n2);在算法2中,假设当前网络中的社区数为n′,计算各社区间的连边数的代价为O(n′2);2阶段的标签更新的代价为O(t×(n+n′)),t为算法的迭代次数,因此算法LPA-TS的总时间复杂度为O(n2+n′2+t×(n+n′)).
3 实验结果与分析
选择不同参数情况下的LFR benchmark人工网络[23]和8个经典真实网络用本文算法LPA-TS进行社区发现,并选择LPA,LPAm,LPAm+,LPA-S,BGLL,ISCD+,FMM,Infomap[24]等包括经典的标签传播算法和以模块性为优化目标的算法作对比进行性能比较.
3.1 评价指标
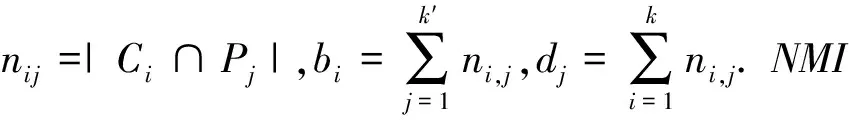
(9)
(10)
划分结果与原始划分的吻合程度越高,NMI和ARI的值越高.如果划分结果与网络随机划分结果相差越大,ARI的值更高.
为了对算法划分结果的稳定性进行评价,本文定义算法的稳定系数σ.对网络G,若|V(G)|=n,对第t次计算结果Ωt构造n×n阶的矩阵,其元素定义为

(11)
若算法运行T次,可得到计算结果的方差矩阵S,其元素定义为
(12)
由此,将算法稳定系数σ定义为
(13)
一个算法多次运行结果的算法稳定系数越低,说明算法划分结果越稳定.
3.2 人工网络实验
人工网络实验采用在社区发现算法性能检测中广泛采用的LFR benchmark数据集上进行,分别考察网络规模n为1 000或5 000,社区规模区间为10~50或20~100,混合参数μ为0.05~0.5的各种不同参数下LFR人工网络上本文算法LPA-TS与对比算法的性能比较.所有实验网络节点平均度为20,最大度为50,节点度序列满足指数为2的幂律分布,社区规模序列满足指数为1的幂律分布.取各算法在每个网络上执行30次的结果取平均值进行比较,结果如图3和图4所示.可以看到,混合参数较低(μ为0.05~0.3)时,网络的社区结构比较明显,各算法都取得了与实际网络中社区分布高度吻合的结果.随着μ的增大,网络中社区结构明显性降低,由于在本文LPA-TS算法中,选择参与系数较低的节点进行标签传播,确保算法在保持社区发现质量的同时,减少了节点标签传播过程中的随机性,从而使得算法运行结果比较稳定.
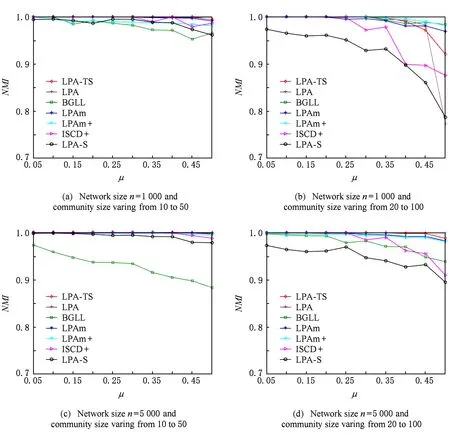
Fig.3 Comparison of NMI on LFR benchmark networks图3 各算法在LFR benchmark网络上的NMI比较结果

Fig.4 Comparison of ARI on LFR benchmark networks图4 各算法在LFR benchmark网络上的ARI比较结果
实际上,本文也与基于随机游走的社区发现算法Infomap进行了对比实验.Infomap算法在本文实验的LFR benchmark网络上社区发现结果与初始生成的社区划分结果完全吻合.这是由于LFR benchmark网络生成过程中,其社区内部连边和社区之间连边分别采用随机连接方式产生.这导致网络中各社区内部连边分布比较均匀,2节点之间的连边概率与其度数成正相关关系.所以LFR bench-mark网络中社区分布比较平衡,网络结构也相对稳定.因此,在LFR benchmark网络上,本文所提算法LPA-TS和算法LPA-S在各类算法比较中的优势没有在真实网络的实验结果表现明显.
然而,真实网络的社区构成更加多样化,社区内部连接和社区间连接也体现了很大的非平衡性.因此,我们进一步在经典的真实网络上对各算法性能进行了比较.
3.3 真实网络比较实验
在本节中,我们通过在空手道俱乐部(Zachary’s Karate Club)[27]、海豚社交网络(Dolphins Social Network)[28]、Polbooks[13]和大学生足球网络(American College Football Network)[29]四个带标签的真实网络以及Les Misérables[30],NetScience[31],Email[32]和Yeast[33]四个无标签的真实网络上进行实验以对算法进行评测.数据基本情况如表1所示:

Table 1 Real Network Datasets表1 真实网络数据集
由于LPA-TS算法引入了弱社区判断,以适应复杂的真实网络中多样性的社区变化,使其在真实网络上表现良好.算法比较结果如表2和表3所示,其中每个算法运行30次,取各项指标的平均值做比较.评价指标k表示算法最终发现的社区个数,Q是模块性指标,time表示算法运行时间,σ是算法稳定系数.
表2给出了算法LPA-TS与8种经典社区发现算法FMM,LPA,BGLL,LPAm,LPAm+,Infomap,ISCD+,LPA-S在有标签网络数据集的实验比较结果.可以看出,当网络规模较小时,各算法所发现的社区个数与实际社区数吻合得较好,算法稳定性也表现良好;随着网络规模的逐渐增大,本文算法LPA-TS在社区个数和结果稳定性方面表现突出.
图5给出了经典LPA算法在Karate网络上的3种不同的划分结果,由于其在节点更新顺序上的随机性,LPA对于网络的划分结果存在较大的不稳定性,甚至在划分过程中会将整个网络中的节点划分在一个社区中.

Table 2 Comparison of Real Networks with Labels表2 带标签真实网络实验结果对比表
Notes: Bolded part indicates the best result among the 9 algorithms.

Fig.5 Different results of the LPA on Karate network图5 LPA算法在Karate网络上的3种不同的划分结果
图6给出了本文算法LPA-TS在Karate网络上的划分结果,将该网络稳定地划分为2个社区.
图7给出了本文算法LPA-TS在Dolphins网络上的一种划分结果,该网络表示62只宽吻海豚之间相互联系的情况,节点表示海豚,若2只海豚间存在频繁联系则对应节点间存在边,Dolphins网络中有2个社区标签.LPA-TS可以得到2种不同的划分结果,这2种划分结果的区别仅在于节点40(图7中虚线圈出的节点)的社区归属.

Fig.6 Result of LPA-TS on Karate network图6 LPA-TS在Karate网络上的划分结果

Fig.7 Result of LPA-TS on Dolphins network图7 LPA-TS在Dolphins网络上的划分结果
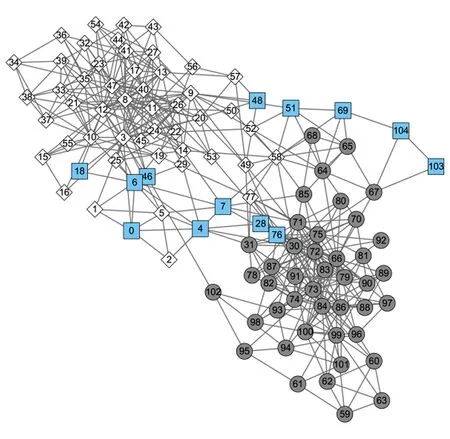
Fig.8 Primitive division on Polbooks network图8 Polbooks网络原始划分
图8给出了Polbooks网络的原始划分情况.该网络节点表示在Amazon在线书店上销售的与美国政治相关的图书,如2本图书曾被同一用户购买过,则对应节点之间存在一条无向边.这些图书被分为3类:“自由派”(圆形节点)、“保守派”(菱形节点)和“中间派”(方形节点).可以看到,“自由派”和“保守派”这2个社区内部连接比较紧密,社区间连边比较稀疏.而“中间派”节点代表的图书没有明显的政治倾向,其对应的社区结构也并不明显,这给社区发现算法的结果准确性和稳定性带来一定的困难.从表2可以看出,本文算法LPA-TS在NMI,ARI等指标上表现更好;与LPA,BGLL,LPAm,LPAm+,LPA-S 五种结果呈现随机性的算法相比,LPA-TS的算法稳定系数更低,因此运行结果比较稳定.图9给出了本文算法LPA-TS在Polbooks网络上所得的最终划分结果,将Polbooks网络划分为2个社区,且各社区内部的连边都比较稠密,社区间的连接比较稀疏,本文算法得到较为合理的划分.

Fig.9 Result of LPA-TS on Polbooks network图9 LPA-TS在Polbooks网络上的划分结果
Football网络是根据美国大学足球联赛2000年一个赛季的比赛赛程而建立的实际网络,共有12个足球联盟,每个球队都属于某一个联盟,因此包含12个社区标签.若2支队伍之间进行过比赛,则对应节点间存在连边.图10给出了LPA-TS在Football网络上的划分结果,与真实划分更为接近.
可以看出,在带标签的真实网络数据中,社区划分的模块性并不一定很高,这是因为真实网络社区结构更加多样化,模块性不能完全反映这种情况.
表3给出了算法LPA-TS与其他8种经典社区发现算法在4种无标签真实网络上的实验结果,分别从划分结果的模块性和稳定性2个方面对各算法性能进行比较.可以看出,本文算法LPA-TS的稳定系数较低,说明其具有良好的稳定性.
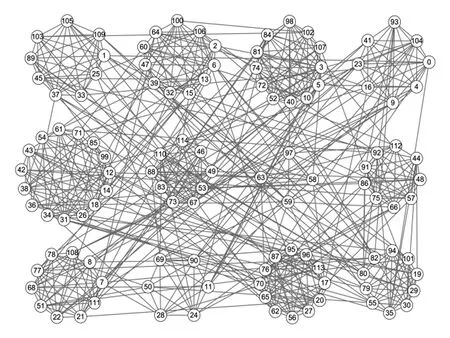
Fig.10 Result of LPA-TS on Football network图10 LPA-TS在Football网络上的划分结果

Table 3 Comparison of Real Networks without Labels表3 无标签真实网络实验结果对比表
Notes: Bolded part indicates the best result among the 9 algorithms.
4 总 结
本文提出了一种基于标签传播的两阶段社区发现算法,通过节点的参与系数确定节点更新顺序,并在标签传播过程中依据节点间相似性更新节点标签,得到社区的初始划分结果.判断得到的初始社区是否满足弱社区定义,若不满足则将其与相邻连边最多的社区进行合并.将初始划分得到的社区看作节点,社区之间的连边数作为节点间的边权重,得到社区关系网络,并按照参与系数由低到高的顺序合并社区关系网络中的节点,得到最终的社区划分结果.
通过与FMM,LPA,BGLL,LPAm,LPAm+,ISCD+,LPA-S等经典社区发现算法在不同参数情况下LFR benchmark人工网络数据集以及真实网络上的实验比较分析,结果表明:由于LPA-TS算法减少了在节点更新和标签传播过程的随机性,社区发现结果表现了良好的稳定性,且在标准互信息、调整兰德系数、模块性等方面均表现出较好的性能.
实际上,现实复杂网络中存在复杂多样的社区分布情况,如存在大量的小规模社区、社区规模分布呈现非平衡性、小社区内部连接数比社区间连接数少、网络结构的动态性等特点,这给复杂网络社区发现问题带来了多方面的挑战,未来将针对复杂网络中这些特殊的社区结构特点,研制有效的社区发现算法.
猜你喜欢
河北画报(2020年8期)2020-10-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
娃娃乐园·3-7岁综合智能(2017年9期)2018-02-01
娃娃乐园·3-7岁综合智能(2017年8期)2018-02-01
娃娃乐园·3-7岁综合智能(2017年7期)2018-02-01
雪莲(2017年2期)2017-05-12
环球市场信息导报(2017年1期)2017-04-08
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
