
一种基于微日志的持久性事务内存系统
2018-09-21 03:26胡庆达陈游旻陆游游舒继武杨晓辉
计算机研究与发展 2018年9期
陈 娟 胡庆达 陈游旻 陆游游 舒继武 杨晓辉
1(东南大学信息科学与工程学院 南京 210093) 2 (清华大学计算机科学与技术系 北京 100084) (chenmj09@163.com)
近年来,新型非易失性存储器(non volatile memory, NVM)吸引了学术界和工业界的广泛关注.典型的非易失存储器包括PCM[1-2],STTRAM[3-4],ReRAM[5]和3D XPoint[6],其不仅具有接近传统内存材料随机访问存储器(dynamic random access memory,DRAM)的随机访问性能,而且在内存层次提供了数据持久性的保证.因此,基于NVM的持久性内存打破了传统易失性内存和持久性外存之间的界限,为设计更加高效的存储系统提供了新的机遇.
虽然持久性内存保证了数据的持久性,然而,CPU缓存依然是易失性的,并且会打乱数据写回到持久性内存的顺序,这导致持久性内存上的数据在系统突然崩溃时可能处于不一致的中间状态.为解决此问题和充分发挥出持久性内存良好的性能优势,研究者们提出了持久性事务内存系统.这些系统通过日志机制保证事务的原子性和一致性.其中,Mnemosyne[7]和NVML[8]分别是基于redo log和undo log日志机制的代表性事务内存系统.在更新原数据前,系统分别先将新/旧数据持久化到日志中,从而在系统崩溃时根据日志中存在的数据副本将其恢复到一致性的状态.这些事务系统不仅为应用程序访问持久性内存提供数据一致性的保证,而且可以通过用户态接口直接访问持久性内存上的数据,降低持久化操作的软件延迟.
虽然持久性内存具有集成度高、静态能耗低和数据持久性等优势,但其也存在一定的局限性.首先,持久性内存往往具有读写不对称性,写延迟远高于读延迟.例如PCM的读延迟与DRAM相似,而写延迟几乎是DRAM的10倍[3].此外,持久性内存还具有耐久性的问题.例如PCM只能承受住106~108次写操作[9-10],STT-RAM虽然在理论上具有较高的耐久性,但在实际测试中发现,其最多也只能承受1012次写操作,无法达到理论中的期望值[9,11].因此,如何减少对持久性内存的写操作,从而减轻写操作带来的延迟和磨损是持久性事务内存系统中亟待解决的重要问题.
然而,本文发现现有持久性事务内存系统的日志机制带来了过多的写操作,主要有2个方面原因:
1) 现有系统没有区分事务中不同类型的写操作,即无论是对内存中已有数据的更新操作还是向事务中新分配区域添加数据的写操作(本文称之为分配操作),现有系统都利用相同的日志机制保证数据的一致性.然而日志操作不仅加快持久性内存设备的磨损速度,而且还需要使用CLFLUSH等指令对缓存中的数据进行强制刷新,增加事务的延迟[12],造成系统性能的下降.
本文发现redo log和undo log这2种日志机制都只是用于保证被更新的旧数据在系统崩溃时存在一个可恢复的数据副本.对于第1次写入的新数据,不需要依赖日志机制来保证数据的一致性,因此这部分日志开销可以被消除.
2) 现有系统使用相同的数据类型(通常是64 b整型)将更新操作的地址和数据等字段完整地持久化到日志中,即使这些字段存储的数据通常可以用更小的内存空间存储.这会产生大量的日志写操作,严重加快持久性内存设备的磨损速度.
本文发现日志操作中大部分数据可以通过压缩算法减少写入的日志数据总量.这种优化策略不仅可以保留原有数据的副本,而且能够减小对持久性内存的写磨损.此外,因为除了系统崩溃后的恢复过程,系统不会再次访问已经写入的日志数据,所以压缩操作对事务性能的影响可处在一个可控的范围之内.
针对上述2个方面的问题,本文分别提出分配操作感知的日志优化策略(allocation-aware log optimization, AALO)和基于压缩算法的日志优化策略(compression-based log optimization, CBLO).AALO动态识别出事务中不同类型的写操作,并分别使用不同的日志机制保证所有写操作的一致性,避免分配操作产生的日志开销;CBLO在将新数据写入日志时,利用zigzag压缩算法[13]对日志数据进行压缩,进一步减少日志操作的写开销.
本文结合上述2种优化策略,设计并实现基于微日志的持久性事务内存(a tiny-log based persistent transactional memory, TLPTM)系统.测试结果表明:相比于Mnemosyne,TLPTM系统具有更高的耐久度,其将日志的数据总量降低70%~81%,从而更好地提升持久性内存系统的耐久性.
1 相关工作
为保证系统发生故障后能够恢复到一致性的状态,现有的持久性事务内存系统通常采用基于redo log或者undo log的日志机制.例如Mnemosyne[7]和BPPM[14-15]是基于redo log的持久性事务内存系统,而NV-heap[16],NVML[8]和DCT[17]是基于undo log的持久性事务内存系统.Wan等人在文献[18]中对undo log和redo log两种日志机制在持久性事务内存系统中的使用作了深入研究.这2种日志机制的主要区别在于:在将新数据写入持久性内存中的数据区之前,redo log先将新数据持久化到日志中,而undo log先将内存中的原数据持久化到日志中.当系统突然崩溃时,对于那些已经成功提交但未写入到数据区的事务,基于redo log的事务系统使用日志区中的数据重做已经提交的事务,而基于undo log的事务系统使用日志区中的数据执行回滚操作.无论是redo log还是undo log,两者都是为了在系统突然崩溃时,事务系统可以找到一个正确的数据版本,将数据恢复到一致性的状态.本节具体介绍近年来具有代表性的持久性事务内存系统.
NVML[8]是Intel公司开发的基于undo log的持久性事务内存系统.对于事务中每一个写操作,NVML将对应的旧数据持久化到日志中,然后再去修改原数据.然而,持久性内存会将编程上的错误(例如内存泄露或者访问野指针等)永久性地保存下来,即使在系统重启后依然可能导致系统崩溃.Coburn等人设计了NV-heaps[16],提出了一套灵活健壮的编程模型,以帮助程序员减少编程过程中可能引入的错误.
在基于undo log的事务系统中,每一次写操作需要先将旧数据持久化到日志中,然后才能修改原数据区,这将导致频繁的CLFLUSH操作,带来过高的持久化延迟.Kolli等人设计了DCT[17],该设计通过硬件的方式减少持久化操作之间的顺序依赖关系,从而充分发挥存储系统的并发处理能力,减少持久化延迟对系统性能的影响.但是,DCT系统不可避免地引入了额外的硬件开销.
基于redo log的事务系统在事务提交时才将数据持久化到日志中,从而有效地减少了事务的持久化操作,并且不需要额外的硬件开销.Mnemosyne[7]是基于TinySTM[19]系统开发的基于redo log的持久性事务内存系统,其主要事务流程如图1所示.Mnemosyne在事务执行过程中将所有更新数据缓存在易失性的写集合中.当事务提交时,系统首先将写集合中所有数据持久化到日志中,然后再将这些数据持久化到原数据区.
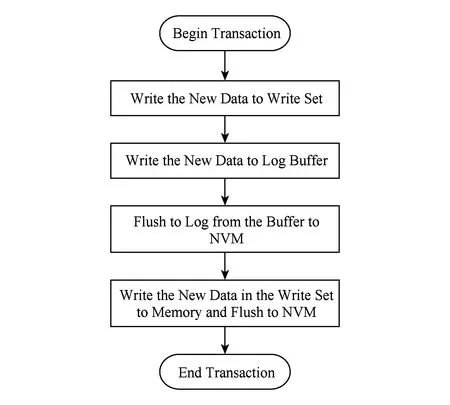
Fig.1 The transaction mechanism process of Mnemosyne图1 Mnemosyne的事务机制
Lu等人提出了BPPM[14-15],BPPM在完成日志操作后不需要将数据立即持久化到原数据区,只有当日志空间不足时才将数据持久化到原地址,从而有效地降低了事务的延迟.此外,BPPM还设计了模糊持久化技术,该技术能够区分出日志区中尚未提交的数据,从而避免了在CPU缓存中维护多个数据副本的额外开销.
Sun等人提出DP2[20],DP2技术区分出日志写入和数据写入,在日志写入时通过持久性屏障和减少日志的保存时间来降低写操作的延迟,DP2在一定程度上降低了事务的开销,并且提高了持久性内存设备的使用寿命.
虽然上述工作在一定程度上提高了事务的性能,但是它们所使用的日志机制不可避免地引入了引言中所提到的2个问题而带来了额外的写开销.
2 TLPTM架构设计
本文提出一种基于微日志的持久性事务内存系统.图2描述TLPTM的架构图.本文使用支持DAX[8]功能的文件系统PMFS[21],通过内存映射文件的方式将持久性内存以用户态的形式暴露给TLPTM,从而降低传统持久化路径的软件栈开销.上层应用通过TLPTM的事务接口访问和更新持久性内存上的数据.

Fig.2 Architecture of TLPTM图2 TLPTM架构图
由于TLPTM是通过内存映射文件的方式从非易失主存中获取一块内存区间,然后在用户态保护程序在这块内存空间上的数据一致性,因此TLPTM只保证程序级别的一致性.而内存映射文件所涉及到的文件的一致性由文件系统保证,例如PMFS,HiNFS[22]、支持DAX功能的EXT4文件系统等.
TLPTM主要包含3个模块:
1) 日志模块.第1节提到,因为undo log导致了频繁的持久化操作,所以日志模块采用了基于redo log的日志机制,在事务执行过程中先将新数据维持在易失性的写集合中,只有在事务提交时会触发持久化操作.此外,TLPTM利用CLFLUSH等软件指令保证持久化操作的顺序性.
2) 并发控制模块.在事务执行过程中,任何2个事务可能同时更新同一个数据,TLPTM利用并发控制模块解决事务间的冲突.通过日志模块和并发控制模块,TLPTM保证了事务的ACID特性.
3) 内存管理模块.TLPTM通过文件系统的mmap接口,将持久性内存区域映射到进程某个固定的虚拟地址,然后利用内存管理模块管理映射出的内存区域,保证内存分配/释放操作的持久性和一致性.
为了解决引言中提到的2个问题,TLPTM在日志模块中设计了分配操作感知的日志优化策略AALO和基于压缩算法的日志优化策略CBLO.AALO在事务运行过程中区分出内存更新操作和分配操作.对于分配操作,绕开了日志操作,直接将新数据写到新分配到的地址上,减少了分配操作的日志开销.CBLO在将日志数据写入到持久性内存前,先利用压缩算法对日志数据进行压缩,减少写入日志的数据大小,从而减少对持久性内存设备的写磨损.
3 关键技术
本节首先介绍2个关键日志优化策略AALO和CBLO,然后介绍基于上述优化策略的TLPTM系统的事务机制.
3.1 分配操作感知的日志优化策略AALO
事务的写操作主要包含2个类型:对持久性内存中已有数据的更新操作;向事务中新分配区域添加数据的分配操作.在现有的持久性事务内存系统中,无论是更新操作还是分配操作产生的新数据,都采用的是相同的日志机制,即将新/旧数据先写入到日志中,再写入到原数据区.
对于更新操作,系统需要利用日志机制保证其崩溃时存在可恢复的数据副本.然而对于分配操作,系统只需要将新数据直接写入到新分配的数据地址,并不需要提前写日志的操作,因为这部分数据之前在系统中并不存在,即使系统在事务提交前突然崩溃,也不会影响其一致性状态.
因此,TLPTM设计了分配操作感知的日志优化策略AALO.在事务执行过程中,AALO区分出分配操作和更新操作.当应用在事务中新分配某块持久性内存区域时,TLPTM记录下新分配的数据区域地址.当事务中有写操作发生时,TLPTM根据事务中新分配的数据区域地址,判断出每个写操作是否落在新分配的数据区域中,如果是,则说明当前操作是分配操作,否则就判定其为更新操作.
然后,TLPTM根据写操作类型的不同,使用不同的日志机制来保证事务的一致性;当事务中的写操作是对内存中已有数据作修改时,TLPTM使用redo log保证数据的一致性.而当事务中的写操作是向该事务新分配的区域添加数据时,TLPTM直接在事务提交时将数据持久化到新分配的数据区.因此,TLPTM消除了分配操作带来的日志开销.
3.2 基于压缩算法的日志优化策略CBLO
本文观察到日志数据往往具有如下特点:对于每个写操作,日志中记录的信息主要包含3个字段,即该操作更新的内存地址addr、新数据value以及掩码mask,它们都是8 B的整型数据.现有系统将这8 B的数据完整地持久化到日志中,即使这些字段存储的数据通常可以用更小的数据类型表示.因此,TLPTM设计了基于压缩算法的日志优化策略CBLO,该策略将日志数据进行压缩以减少写入的日志数据总量,在保证原有数据副本的同时减少对持久性内存的写操作.CBLO采用zigzag压缩算法[13],使用该压缩算法的原因主要有2个:①日志中记录的数据类型都是64 b的整型数据,而zigzag算法十分适合整型数据的压缩;②因为日志数据中addr和mask等字段在大多数情况下数值大小比较固定且数值较小,而zigzag算法对于小整数的压缩效果尤其明显.
zigzag算法的基本思想是:将有符号的数字映射为无符号的数字,其以一种在正整数与负整数之间来回交错的方式进行,绝对值小的数字经zigzag压缩编码后,无论正负都可以只使用较少的字节数来表示.
在具体实现中,当系统执行写日志操作时,TLPTM利用zigzag算法对所有需要持久化到日志中的数据进行重新编码,将其表示成比特位信息中具有更多前导0的另一个整数.当存储该数据的内存空间有若干个字节的比特位信息都为0时,zigzag算法会尽可能将这些字节丢弃,用更小的内存空间存储剩余的字节信息,最后持久化到内存中的日志区.由此就达到了将日志数据进行压缩的目的.日志数据经压缩后,有效地减少了日志操作的数据总量,从而提高了持久性内存设备的耐久性.
值得注意的是,由于本设计在日志写入的过程中引入了压缩算法,这不可避免地引入了一定的延迟.因为在对数据进行压缩的过程中,使用的是一个循环结构,该循环结构的作用就是将数据的比特位信息中存在1的字节提取出来,当数据经zigzag进行编码后的比特位信息中具有较多的1时,该循环的运行时间就会越长,因此相应地会增加程序的运行时间.但由于日志数据一般只有在系统突然崩溃后需要做故障恢复的情况下才会被访问,压缩后的数据通常不需要反复的解压缩/压缩过程,所以压缩算法所带来的延迟处在一个可控的范围之内.此外,持久性内存具有读写不对称性,压缩算法能够有效降低写入数据的总量,这在一定程度上也降低了事务的平均延迟.这部分的影响会在第4节实验部分给出进一步的验证.
3.3 事务机制
3.3.1 事务接口
TLPTM利用GCC事务编译器[23]向传统C/C++代码加入了事务语义,通过关键字__tm_atomic和一组花括号定义事务的范围,保证这段代码的ACID特性.事务范围内的内存访问操作会被GCC事务编译器捕获,TLPTM利用TinySTM替换了事务中的内存访问操作.在事务执行过程中,TLPTM将所有更新操作记录在一个易失性的写集合中.当事务提交时,通过redo log日志机制,将写集合中的写操作备份到日志中,并调用持久化模块保证日志操作的持久性.最后,TLPTM将新数据持久化到原数据区.此外,TLPTM利用TinySTM的锁机制保证了事务的并发控制,从而实现了并发控制模块,这部分的细节介绍可参考之前的研究工作[19].
3.3.2 日志模块
当事务提交时,TLPTM利用软件指令对日志操作和原数据写回操作进行持久化.因为日志数据只有在系统崩溃时才会被访问,所以TLPTM利用MOVNT指令绕开了CPU缓存,将日志数据直接持久化到持久性内存上,避免了对CPU缓存的干扰.此外,TLPTM利用MFENCE指令,确保在执行原数据修改前将所有日志操作进行持久化.对于原数据写回操作,TLPTM利用CLFLUSH指令保证所有写操作的持久性.此外,日志模块设计了2种优化策略AALO和CBLO,解决了引言中提到的现有系统存在的2个问题.
3.3.3 内存管理模块
内存管理模块是基于易失性内存分配器Hoard[24]实现的.Hoard最初是针对多线程场景设计的,其按照超级块的粒度(例如16KB)对传统内存进行切割.为了减少多线程间的冲突,Hoard同时维护了全局的超级块池和线程局部的超级块池,线程只有在局部超级块池的空间耗尽时,才会向全局超级块池申请新的超级块,从而减少了多线程间的锁冲突.对于每个超级块,Hoard将其分成固定大小的内存块,满足给定区间大小的分配操作.
然而,Hoard是基于传统内存设计的,无法保证分配操作的持久性和一致性.为了解决这个问题,TLPTM在持久性内存的固定区域预留了每个超级块的位图(bitmap).位图中每个比特位都表示了对应超级块中某个内存块的分配状态.此外,TLPTM利用事务接口,保证分配/释放操作中位图修改操作的持久性和一致性.
3.3.4 TLPTM的事务机制流程
图3表示了基于AALO和CBLO的TLPTM系统的事务机制流程图.TLPTM与基于redo log的传统系统相比,主要有2点区别:1)TLPTM增加了一个写操作判断,即判断写操作是否是分配操作;2)TLPTM在执行日志持久化操作前利用zigzag算法对其进行了压缩.

Fig.3 The transaction mechanism process of TLPTM图3 TLPTM的事务机制
3.3.5 系统恢复
当系统突然崩溃时,TLPTM需要将系统恢复到崩溃前的一致性状态.首先,TLPTM通过文件系统的mmap接口,将持久性内存区域映射到某个固定的虚拟地址.其次,根据超级块中的位图信息重建内存管理模块的数据结构.最后,根据日志数据中的信息,重做已经提交的事务,丢弃未完成的事务,由此完成整个系统的恢复过程.
4 实验测试与分析
为了分析评价TLPTM的性能和耐久性,本节的实验将从3个方面对TLPTM进行测试与评价:
1) 对比测试分配操作感知的日志优化策略AALO的性能和耐久性;
2) 对比测试基于压缩算法的日志优化策略CBLO的耐久性;
3) 对比测试Mnemosyne和TLPTM的性能和耐久性.
4.1 测试环境
本文所有实验均基于同一台Linux服务器,内核版本为4.4.16,处理器型号为Intel®Xeon®CPU E5-2680 v3,共包含4个物理核心.此外,服务器还配置了32 GB的内存和1 TB的硬盘.实验配置环境如表1所示:

Table 1 Experiment Configuration表1 实验环境配置
本文使用Mnemosyne[7]中的Hash表作为实验的测试程序,并将每个事务中产生的日志数据的平均字节数和事务平均延迟作为系统在可靠性和性能的评价标准.实验中使用3种不同的负载来评估TLPTM的性能和耐久性.其中,Workloada被设置为在Hash表中全部执行分配操作,Workloadb的场景是在Hash表中执行分配操作和更新操作的比例均为50%,Workloadc被设置为在Hash表中全部执行更新操作.表2中列出了这3种负载的特点.

Table 2 Workload Features表2 负载的特点
虽然持久性内存相关技术发展十分迅速,但是目前大多数研究还只是集中在设备级别,对系统级别的研究仍面临着缺少真实的NVM设备的境况.因此,大多数研究不具备在真实NVM存储环境下验证上层软件技术有效性的条件,而构建NVM模拟器或模拟平台是解决上述问题的有效途径[11].本文使用与Mnemosyne[7]类似的持久性内存模拟方法,即将普通内存划分为常规的易失性内存和模拟的非易失内存.默认情况下,本实验使用CPU提供的RDTSC指令将模拟延迟设置为500 ns.因为Mnemosyne和TLPTM都是基于TinySTM[19]和redo log实现的持久性事务内存系统,本文主要以Mnemosyne作为比较系统,从而保证了系统对比的公平性.
4.2 分配操作感知的日志优化策略的测试
本节实验将使用了AALO的系统与Mnemosyne进行对比,验证了分配操作感知的日志优化策略对持久性事务内存系统的可靠性和性能方面的影响.
4.2.1 耐久性测试
日志写入量的测试结果如图4所示,除负载c外,AALO将每个事务日志操作产生的平均字节修改数降低了54%~64%.负载a理论上更契合于本文提出的分配操作感知的优化策略,因为负载a连续地向Hash表中插入新的键值对,这会导致频繁地调用内存分配函数,由于是向内存中添加新数据,该操作不需要通过日志操作来保证一致性.但是,随着插入操作所占比例的增加,每个事务的日志操作产生的平均字节修改数也随之增加,这是因为内存分配信息也会保留在日志中,因而出现图4中所示的结果.

Fig.4 Comparison of log size between Mnemosyne and AALO图4 Mnemosyne和AALO日志写入量的对比
由于负载c中每次操作都是更新哈希表中已有的键值对,而本文提出的分配操作感知的优化策略只对分配操作有效,因此对耐久性的提升并不明显.
4.2.2 性能测试
在3种工作负载下,本节分别测试了AALO对持久性内存系统的性能影响,其与Mnemosyne的延迟对比如图5所示,除负载c外,AALO将写入延迟降低了15%~24%.由于负载a受到频繁的内存分配操作带来的影响,所以其性能要略差于其他负载.由于负载c全部都是更新操作,因此2个系统的性能基本相似.

Fig.5 Comparison of latency between transaction mechanisms图5 事务机制的延迟对比
由此可知,分配操作感知的日志优化策略不仅减少了每个事务的写磨损,而且也降低了日志操作引入的持久化延迟.
4.3 基于压缩算法的日志优化策略的测试
本节实验将使用CBLO的系统与Mnemosyne进行对比,验证了基于压缩算法的日志优化策略对持久性事务内存系统可靠性方面的影响.实验结果如图6所示,从图6中可以看出,使用了CBLO的系统中日志操作的平均字节修改数比Mnemosyne减少了61%~70%.磨损大大降低的原因在于,日志操作的所有字段都是64 b的整型数据.首先,考虑字段addr和mask,当地址addr是9 b数的整型数字时,经zigzag压缩编码后,只需要使用5 B进行存储;而mask在多数情况下为-1,经压缩编码后,只占用1 B.而value字段是由应用程序决定的,当传入的value较小时也能获得良好的压缩率.因此,相比于Mnemosyne,CBLO大大减少了持久性内存系统的日志写入量.
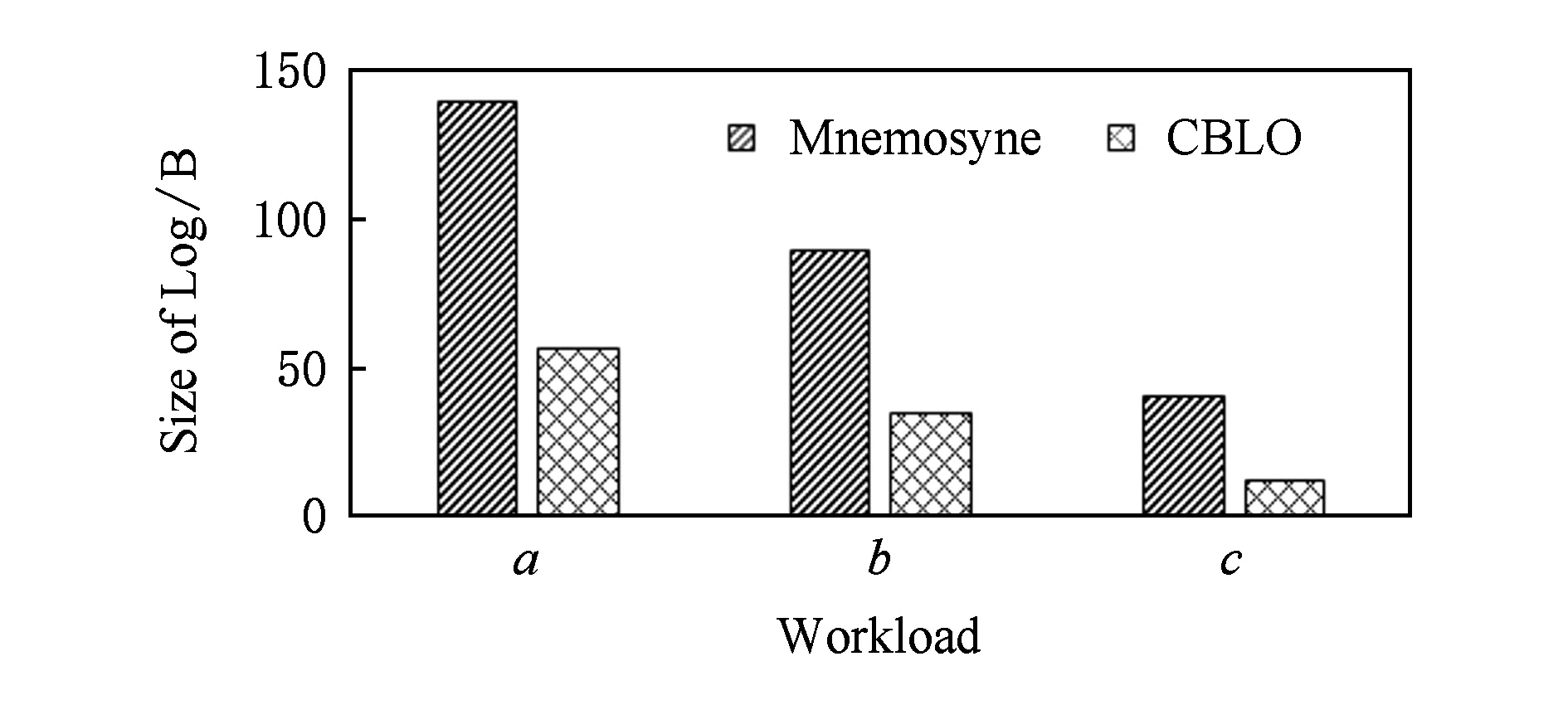
Fig.6 Comparison of log size between Mnemosyne and CBLO图6 Mnemosyne和CBLO日志写入量的对比
此外,压缩算法不可避免地增加了日志操作的延迟,但是因为日志数据只有在系统恢复时才会被访问到,所以压缩算法产生的开销可以接受.本文将在4.4节中讨论基于2种优化策略的TLPTM的性能效果.
4.4 TLPTM与Mnemosyne的对比
本节实验将基于2种优化策略的TLPTM与Mnemosyne进行对比,由此判断TLPTM在性能和可靠性方面的效果.
4.4.1 耐久性测试
本实验比较了基于AALO与CBLO两种优化的TLPTM系统与Mnemosyne的耐久性.两者产生的日志写入量对比如图7所示.从图7中看出,在不同的工作负载中,与Mnemosyne相比,TLPTM在耐久性上都有十分明显的提升,除负载c外,TLPTM将日志的写入总量降低了79%~81%.因为负载c不包含分配操作,AALO并没有对其写磨损产生优化效果,所以其耐久性的提升效果略低于其他2种工作负载,但其凭借CBLO的优化依然达到了70%的耐久性提升.
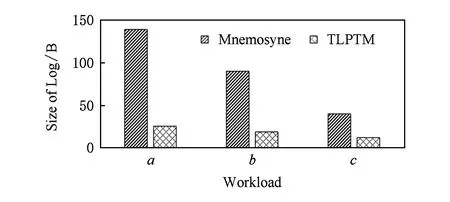
Fig.7 Comparison of log size between Mnemosyne and TLPTM图7 Mnemosyne与TLPTM产生日志数据的大小对比

Fig.8 Comparison of latency between TLPTM and Mnemosyne transaction mechanisms图8 TLPTM与Mnemosyne事务机制的延迟对比
4.4.2 性能测试
本节实验测试TLPTM与Mnemosyne的性能对比,结果如图8所示,相比于4.2.2节中的实验效果,基于2种优化的TLPTM系统的性能有所降低,这说明压缩算法在降低日志操作产生的写磨损的同时,带来了一定的性能影响.因为在对数据进行压缩的过程中,使用的是一个循环结构,该循环结构的作用就是将数据的比特位信息中存在1的字节全部提取出来,当数据经zigzag进行编码后的比特位信息中具有较多的1时,该循环的运行时间就会越长,因此相应地会增加程序的运行时间,从而对系统性能造成一定影响.使用TLPTM系统的用户可以根据自己的需求,选择是否使用基于压缩算法的日志优化策略CBLO,从而获得在性能或者可靠性方面的提升.
5 总 结
持久性内存因为非易失性、静态功耗低和集成度高等优势,有望代替DRAM成为新的主存材料.研究人员设计了轻量级的持久性事务内存系统,用于保证持久性内存上更新操作的一致性.然而,持久性内存同时也存在着使用寿命有限和写延迟过高的局限性.现有的事务系统因为日志操作引入额外的写操作,带来严重的写延迟和写磨损等问题.
为了解决这些问题,本文提出了分配操作感知的日志优化策略AALO和基于压缩算法的日志优化策略CBLO.结合这2种优化策略,本文设计并实现了基于微日志的持久性事务内存系统TLPTM.实验结果表明,与现有的事务系统Mnemosyne相比,本文提出的分配操作感知的优化策略将事务的性能提升了15%~24%,基于上述2种优化策略的TLPTM将日志的数据总量降低了70%~81%.
猜你喜欢
节能与环保(2022年7期)2022-11-09
华人时刊(2021年13期)2021-11-27
魅力中国(2021年24期)2021-11-26
心声歌刊(2020年4期)2020-09-07
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
计算机技术与发展(2019年11期)2019-11-18
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
计算技术与自动化(2017年3期)2017-10-26
山东工业技术(2017年7期)2017-04-10
