
3D建模在数据增强中的应用研究
2018-09-20 11:29范峰曹文馨向征
无线互联科技 2018年15期
范峰 曹文馨 向征

摘要:在计算视觉领域中,训练卷积神经网络往往需要大量的数据,网上公开的数据集,少说也有几十万张,但是在现实中我们能拥有的数据集资源往往没有那么多,数据量少,这是一方面。在学术研究与教学中,很多算法都有一个基本假设,那就是数据分布是均匀的,当我们把这些算法直接应用于实际数据时,大多数情况下都无法取得理想的效果。因为实际数据往往分布得很不均匀,都会存在“长尾现象”。数据分布不均匀,数据量少,往往会造成过拟合等问题,数据量少可以通过扩充训练数据的方法来解决,现在有基本的对图像的裁剪、翻转、缩放、平移、尺度变换、对比度变换、噪声扰动、颜色变化等数据增强的方法,但是这些方法都是基于原有的数据集,虽然能一定程度上解决数据集过少的问题,但是对数据分布不均匀并没有多大的帮助,文章对此提出一种易于实现且对数据分布不均匀具有一定作用的解决方案。
关键词:3D建模;数据增强;卷积神经网络;计算机视觉
传统的数据增强方法是基于原有的图像数据进行各种变换,从这里引出了一个问题,严格地讲,任何数据集样本都有分布不均匀的情况,比如说猫与狗的正面图片比较多,而背面或者上方的图片比较少,那么经过传统的数据增强方法数据集的分布一样没有产生变化,训练出来的模型对正面的特征识别的准确率就比较高,但是背面特征识别的准确率就比较低[1]。在文本处理以及其他非图像数据处理领域针对这一个问题的解决方法目前有采样、加权,但是这两种方法在图像识别中是比较难操作的,还有数据合成,数据合成方法是利用已有样本生成更多的样本,这类方法在小数据场景下有很多成功的案例,比如医学图像分析等,但是这个方法用来生成识别图像数据集是明显行不通的,不过可以借鉴其合成训练数据的思想,如果通过3D建模技术创建相应的3D模型,再对3D模型进行全方位图像信息的收集,再添加到数据集中进行训练,那么效果会是怎样,我们针对这个猜想开始进行试验[2]。
1 模型选取及实验设计
创建3D模型的方法有两种:(1)若数据集的图像像素较高,我们可以直接通过数据集里的目标的多方位图片来生成模型,现在有众多的2D图像转3D模型的技术及软件,比较出名的有google open 3D reconstruction,Autodesk 123D Catch,smart3D等。(2)若数据集像素较低,不足以生成高精度的模型,那么我们就需要在其他地方寻找目标对象的3D模型资源了,这个可比找数据集难度低多了。有了模型之后,我们使用3Ds Max 2018中的动画渲染,选择输出JPG图片,来合成新的数据集[3]。
在这次实验中,我们随机选取了著名的猫狗大战中部分图片来进行测试,总样本数量为25 000张,用相同的卷积神经网络分别训练这4 000个数据,以及再加入我们通过对模型制作的数据。
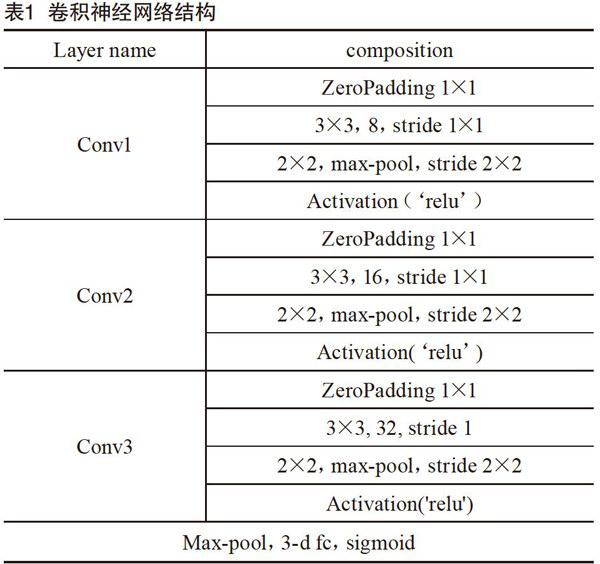
卷积神经网络模型的搭建。考虑到获取最优识别准确率不是我们的最终目的,我们搭建了一个并不是很深的网络,避免在这方面浪费多余的时间,卷积神经网络的结构为一层输入层,3层卷积层,并在每层卷积层后加入了dropout(随机丢弃一部分神经元,降低过拟合),损失函数采用常见的分类用的损失函数对数损失函数,最后输出预测值,我们将这个算法模型作为控制变量,实验数据作为自变量W。卷积神经网络结构如表1所示。
2 实验概述
为了验证本文提出的有效性及可行性,实验主要分为两个阶段:第一阶段,实验A,将从数据集中随机选取的4 000个数据,3 000个作为训练数据,1 000个作为测试数据,然后训练卷积神经网络,迭代10个epoch,记录实验结果。第二阶段,实验B,将从3D模型获取到的1 000个数据加载到原有的数据中,用同样结构的卷积神经网络以同样的epoch训练,记录实验结果并对比[5]。
2.1 实验阶段
2.1.1 实验数据选择与处理
试验阶段一使用的数据集为Kaggle官网上下载的catsva dogs的分类数据集。此数据集一共有25 000个图像数据,包括各种类型的猫以及各种各种类型的狗在各种环境下的图片。
我们选取部分数据集,将数据集按1:4比例随机划分训练集以及测试集,训练集为4 000个图像数据测试集有1 000个图像数据,接下来通过opencv读取并分别为猫与狗的数据打上标签。
图1为部分制作数据集的模型,通过3D MAX动画对模型实现全方位图像渲染,每个模型渲染百张左右的图片,最后分别加入分类猫和分类狗的数据集下,并打上标签,测试数据集并不改变,它用来作为控制变量。
2.1.2 训练模型
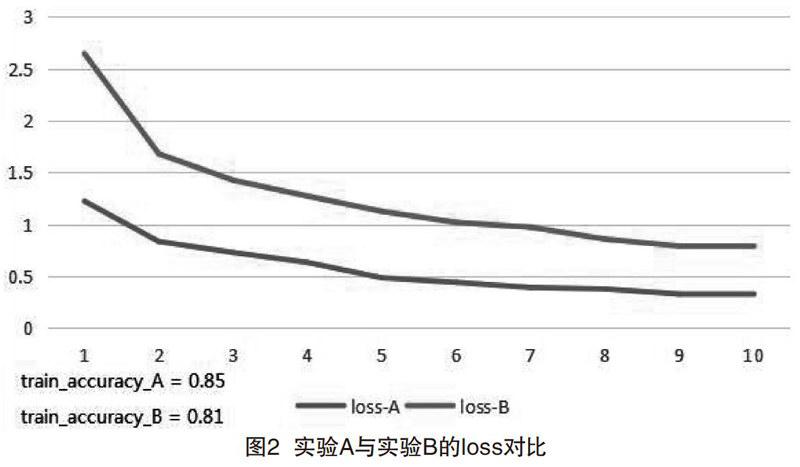
当训练数据和模型都已经准备好之后,开始试验,实验结果如图2所示。
模型经过10个epoch的训练损失和准确率的变化情况如图2所示,loss-A随着epoch的变化与Loss-B对比,实验A的loss比实验B低,这说明实验B的数据比实验A的样本之间的平均差异变大了。
图3中accuracy-A随epoch变化的曲线与accuracy-B相比较,实验A的训练准确率也比实验B的准确率高,目前看起来实验A的效果比实验B好,但是,实验A的训练准确率有85%,测试准确率却只有73%,这说明模型过拟合比较严重了,然而实验B的表现则好很多,虽然训练数据准确率只有81%,但是测试集的准确率有78%,这说明后来由模型制作的训练数据对模型的过拟合问题起到了良好的纠正作用,当然模型还可以继续调优,可以达到95%或者以上,81%也算不上多好的表现,但是我们的目的已经实现了,3D模型制作确实能一定程度上起到降低过拟合情况的作用。
2.2 实验结论
通过实验A的数据与实验B的数据对比,实验B的模型表现比实验A的模型表现准确5个百分点,证明了3D建模技术在数据增强中确实有着良好的表现,它不仅能够改善数据集中常见的“长尾现象”,降低模型的拟合程度,而且它与传统的數据增强方法并不冲突,甚至还可以在它合成的数据集上面再进行传统的数据增强,能够最大限度地利用原有的数据集的价值。
3 结语
在实验之前我们就猜想,从人的角度出发,让一个人能够在多种情况下识别一个对象,那么全方位认识该对象的特征是必须的,而对于计算机视觉来说,也是同样的道理,只有全方位的图片数据信息够多,那么才能训练出对对象全方位特征都具有识别能力的模型[6]。
两个阶段的实验有力地证明了建模技术在提高模型预测精度和降低过拟合程度上有着明显的效果,而且与原来的数据增强方法并不冲突,可以一起使用,这样能够在有限的原始数据集获得更多有价值的数据,最大限度地提取出数据的价值,从而训练出精度更高的算法模型[7]。
未来计算机视觉任务发展面临的挑战就有来自数据集因素的,有标注的图像和视频数据较少,机器在模拟人类智能进行认知或者感知的过程中,需要大量有标注的图像或者视频数据指导机器学习其中一般的模式。当前,主要依赖人工标注海量的图像视频数据,不仅费时费力而且没有统一的标准。现在3D建模技术越来越方便快捷以及成本越来越低,精度也越来越高,我们推测以后用3D建模技术来制作数据集也不是没有可能,因为通过3D模型来合成数据与传统的收集图像数据有两个比较大的优势:它能够迅速制作大量的数据;它的制作是人为控制的,可以保证数据分布得均匀[8]。在深度学习算法的门槛越来越低,搭建模型越来越方便,算法模型的调优越来越简单的现在,将来获取优良的数据集将成为一个算法模型提升重要的因素,通过3D建模技术制作优良的数据集将成为一个好的选择。
[参考文献]
[1]HINTON G E, SALAKHUTDINOV R R.Reducing the dimensionality of data with neural networks[J].Science, 2006(5786):504-507.
[2]HE K, ZHANG X, REN S, et al.Deep residual learning for image recognition[C].Las Vegas:Computer Vision and PatternRecognition, 2016:770-778.
[3]UGULINO W, CARDADOR D, VEGA K, et al.Wearable computing:accelerometers, data classification of body postures andmovements[C].Curitiba:Brazilian Conference on Advances in Artificial Intelligence, 2012:52-61.
[4]GUYON I.Design of experiments for the NIPS 2003 variable selection benchmark[C].Vancouver:Conference and Workshop on NeuralInformation Processing Systems, 2003.
[5]KINGMA D, BA J. Adam:a method for stochastic optimization[M].San Diego:Computer Science, 2014.
[6]盧宏涛,张秦川.深度卷积神经网络在计算机视觉中的应用研究综述[J].数据采集与处理,2016(1):1-17.
[7]倪晨旭.计算机视觉研究综述[J].电子世界,2018(1):91.
[8]GREGORY R.Cordelia Schmid:MoCap-guided data augmentation for 3D pose estimation in the wild[C].Barcelona:Conference andWorkshop on Neural Information Processing Systems, 2016.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
医学食疗与健康(2021年27期)2021-05-13
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
电子制作(2019年11期)2019-07-04
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
电视技术(2014年19期)2014-03-11
现代防御技术(2014年6期)2014-02-28
