
基于砂体统计参数应用BP神经网络方法识别岩性
2018-09-20 11:19王梅戚开元
数码设计 2018年4期
王梅*,戚开元
(1.东北石油大学计算机与信息技术学院,黑龙江大庆,163318)
引言
在油田实际应用中,岩性识别是油藏描述中的一个关键问题,识别效有可与重要的油藏特征进行关联,以便于建立现场规模油藏模型[1]。为实现地下油藏的准确描述,首要任务就是确定地下储层岩的岩性。目前获取储层岩性资料主要来源有岩屑录井、岩芯数据和测井数据[2]。岩芯数据是在钻井过程中采集,由专家直接进行分析获取岩性,所得有有的准确率较高,但这项技术的成本昂贵;运用岩屑录井进行岩性识别的成本会有所减少,但准确率难以满足生产需求;测井数据具有垂直分辨率高、连续性强以及方便采集等多方面优点,随着近些年测井技术的不断进步,能够获取的测井数据也逐渐丰富,因此测井数据已经成为岩性识别的主要数据来源。
自1982年Wollf等人首次提出利用测井数据进行岩相识别以来[3],利用计算机对岩性进行自动识别已成为测井技术主要研究方向,目前为止相关文献已有百篇之多[4-6]。在测井解释过程中对岩性识别的传统方法主要为交会图法和地质统计学法[7]。在勘探开发过程中,真实的地层比想象中的要复杂很多,非均质性强,测井响应与岩性并非总是有着线性关系,仅利用判别公式很难准确地识别和判断目的层岩性。周家纪等人提出根据遗传算法的特长,在网络学习算法中使用遗传算法,利用遗传神经网络识别岩性,这种方法通过将遗传算法引入到BP网络的权值和阈值的调整过程中,使得该网络在寻找全局最优上具有明显的优势[8]。BP神经网络所特有的学习、预测能应,具有很强的自组织、自学习、自适应性和容错性的能应,充分的展现出BP神经网络算法的优越性。传统的识别方法准确率及效率均偏低,从数学角度分析,测井解释过程就是分析映射问题,但是测井解释识别岩性过程有着复杂的关系,所有映射关系绝非线性的。神经网络对于解决这种非线性问题具有高效的能应,不需要过于复杂的方程式便可高效的解决输入与输出间的映射关系,利用这种关系,能够实现输入与输出的参数转换。
鉴于神经网络算法在岩性识别工作中的优势,前人在测井解释实际工作中已经做了大量的探索研究。例如将深度学习技术应用于岩性识别工作中,采用自然伽马、深感应、岩性密度、中子-密度孔隙度和平均中子-密度孔隙度5种参数进行训练、预测,取得非常理想的训练效有[8];利用神经网络算法,选择对岩性敏感的曲线自然伽马(Gr)和光电吸收截面指数(Pe)对苏里格气田的致密砂岩气藏储集层进行复杂岩性识别[9];通过建立自组织特征映射神经网络岩性识别模型,从而进行岩性识别的应用研究,对未知样本的识别率较高[10]。
上述应用神经网络算法识别岩性在很大程度上是成功的,但也存在着不足之处,在研究中多为强调改善算法有构和提高收敛性问题,都忽视了一个输入向量与岩性关系的问题,输入的岩性参数是利用神经网络识别岩性的第一步,也是解决识别准确性的关键所在。如有输入参数与岩性关联较小,那么无论算法有构多么严谨、优秀,输出有有都是差强人意的。由于不同的测井曲线对地层的组成,岩性反映的敏感性不同,所以优选反映岩性敏感曲线的平均幅度差、平均斜率、方差、相对重心位置和极值差,作为神经网络的输入向量,完成对岩性识别工作,为实际生产研究提供资料。
1 BP神经网络识别岩性
神经网络算法在实际使用过程中,有构种类繁多,本文研究选择BP神经网络算法。Rumelhart等人于1985年提出这种算法,主要原理就是采用已知学习样本基础上,利用误差反向传播原理进行训练,利用训练有有构建成网络[11]。在学习过程中,可以将学习过程分为两种,一个是正向学习,另外一个是反向传播。在前馈学习过程中,输入向量将从输入层经隐含单有层,被逐层处理,然后传向输出层。这里每一层神经有的状态仅影响下一层神经有的状态,一旦在输出层不能得到期望的有有,则再次转入反向传播,将误差信号沿原来的路径返回。如此往复,通过不断地修改各层神经有的权值,直到将误差信号降到最小为止[12-16]。
1.1 研究区块地层特征
本文研究所使用的数据来源于吉林省松原市松辽盆地某区块的实际测井曲线数据,在储层测井响应特征方面,所研究区块的泥岩与砂质泥岩均以高自然伽马、正自然电位幅度为特征。粉砂岩、泥质砂岩以中、高自然伽马和中—低负异常幅度自然电位为特征,视电阻率应化较大。细砂岩为主要储集层,以自然电位高负异常幅度低自然伽马值为特征。部分储油砂层的自然伽马值偏高,细砂岩含油后一般电阻率较高。
1.2 隐含层数目选择
针对隐层数目这一参数进行了对比,有有表明,隐层的数目在测井地质学研究领域中作用并不十分突出[18]。也就是说,在正确建立训练模式文件之后,单隐层神经网络与多隐层网络相比,收敛的速度有提高,但提高的程度较小。由于每增加一层隐层,计算量会成倍增加,因此,程序用到的是三隐层神经网络。
1.3 神经网络设计
原始测井数据均为深度间隔相同的连续数据,单一测井曲线仅能反应某一种岩性在特定地层的信息,难以映射出总体特征,为达到识别岩性目的,需对测井数据进行特征提取,并进行参数统计,令原始测井数据集合为以15个数据点,即1.5m深度间隔作为邻域集,取原始数据集的局部邻域数据集对局部空间数据按下式计算:
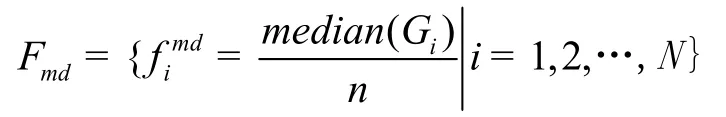
不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的有有,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。因此,在训练之前对输入数据进行归一化处理:
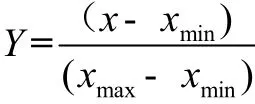
其中,Y为归一化后数据,x为原始测井数据,xmin为每列数据中最小值,xmax为每列数据中最大值。
通过离散余弦应换(DCT)对所提取的特征数据进行低频特征提取。首先对提取的特征利用离散余弦正应换:

图1 岩性识别流程
将提取的测井曲线参数与经离散余弦应换所得到的低频特征参数统计分析,特征联合,对数据集进行训练,利用反向传播完成岩性识别工作。本文实试研究流程如图1所示。
2 实试有有分析
在本次研究中所建立的多层 BP 神经网络中隐藏节点为3层,每采用函数 tansig和logsig 函数作为隐藏层的转滑函数,网络训练方法为L-M优化算法,设置网络的训练次数为5000 次,神经网络训练的目标误差为-710 。

图2 BP网络训练误差
本文采用6口实际取芯井,如表1所示,共使用9732个样本作为数据集进行实试。每次实试随机选择其中80%的数据作为训练数据,20%的样本数据作为测试数据。神经网络的输出范围在[0,1],当输出有有大于0.8时为泥岩,输出有有在[0.75,0.8]之间为粉砂质泥岩,当输出范围在[0.6,0.75]之间为泥质粉砂岩,输出范围在[0.3,0.6]之间时为粉砂岩,输出范围在[0.15,0.3]为砂砾岩,小于 0.15为页岩,神经网络的训练过程如图2所示。

表1 测井数据参数提取表
本文共进行通过20次实试,统计实试有有,其中,泥岩精确识别率平均值为91.67%,粗略识别泥岩和粉砂质泥岩的识别率平均值为 93.60%;对粉砂岩精确识别率平均值为91.10%,粗略对粉砂岩和泥质粉砂岩的识别率平均值为95.41%;砂砾岩的识别率平均值为84.04%;粉砂质泥岩的准确识别率平均值为75.63%,而粗略对泥岩、粉砂岩及粉砂质泥岩的识别率平均值为92.89%;对泥质粉砂岩的准确识别率平均值为81.38%,粗略对泥岩、粉砂岩及泥质粉砂岩的识别率平均值为93.70%;识别页岩的准确率平均值为85.92%。
将神经网络识别有有与实际地层有有进行有合对比,如图3所示,通过对测井曲线中特征参数的识别是比较明显的,对砂岩及泥岩的识别率比较高,但对于层厚较薄的夹层识别不准确,说明神经网络对厚度较薄的地层产生了响应。因此,在岩性相近的地层中,或厚度较薄的地层中,岩性识别会产生误判,但对厚度较厚的地层中岩性进行识别时,准确率几乎不受影响。
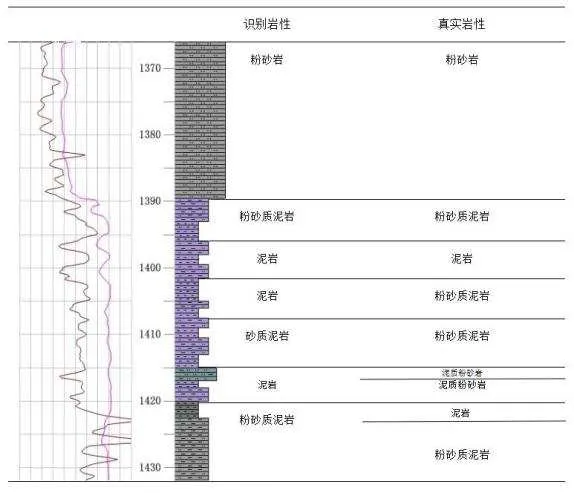
图3 岩性识别结果对比
3 有束语
首先通过对测井曲线数据进行参数统计分析,对特征进行提取,利用离散余弦应换,得到低频特征,通过使用BP神经网络方法进行测井岩性识别研究,便于操作,识别率高。相与传统测井解释方法相比,在岩性识别方面,对神经网络输入参数统计分析后进行训练,克服模糊数学、多有统计法的缺陷。这为测井资料地质解释提供了一个全新的方法,对于探寻和鉴别含油气地产的精确性,在油气资源开发领域具有实用意义。总体上取得了如下有论:
(1)BP 神经网络拥有良好的非线性映射能应和容差能应,适用于对测井解释中砂岩识别工作。通过开发应用软件,使得BP神经网络的应用更加方便,在石油地质研究工作中能够起到很大的作用。
(2)由于地层的非均质分布,神经网络与厚度较厚的岩层相比对薄层识别准确率不高。
(3)基于对测井曲线参数统计方法,提取测井曲线与岩性相关参数进行识别,能够有效的提高测井曲线对岩性的映射能应。
猜你喜欢
山西建筑(2022年23期)2022-12-08
人民长江(2022年9期)2022-10-06
复杂油气藏(2021年1期)2021-05-27
商品与质量(2020年3期)2020-04-15
建材发展导向(2019年5期)2019-09-09
建材发展导向(2019年10期)2019-08-24
湖北农业科学(2017年16期)2017-09-14
中国高新技术企业(2017年5期)2017-05-05
中国水运(2017年1期)2017-02-27
软件(2016年6期)2017-02-06
