
融合信任相似度的高校图书馆个性化推荐研究*
2018-09-18 02:32:38林晓霞刘敏杨晓东徐尧
数字图书馆论坛 2018年8期
林晓霞 刘敏 杨晓东 徐尧
(1. 山东科技大学计算机科学与工程学院,青岛 266590;2. 山东科技大学信息工程系,泰安 271019)
随着图书馆馆藏数量的快速增长,用户越来越难以快速、准确地获取其需求的全部文献资源。为更好地满足用户需求,馆藏资源浏览及检索过程中的个性化推荐服务应运而生,即个人图书馆服务,如美国康奈尔大学的MyLibrary个性化服务。目前,推荐算法主要包括基于内容的推荐[1]、基于协同过滤的推荐[2]、基于关联规则的推荐[3]、基于网络结构的推荐[4]及混合推荐[5]等,而在图书馆个性化推荐中基于协同过滤的推荐算法应用最广泛,且对于提升和改进图书馆服务起到一定作用。但是,基于协同过滤的推荐算法较依赖用户对图书的评价或阅读反馈,通常用户对所借阅图书的评价不多,实际阅读发生的图书数量也有限(即数据稀疏问题),并且不断加入新生和新书(即冷启动问题),对协同过滤推荐算法的准确性与可用性都带来了很大挑战。
为应对数据稀疏问题,刘健[6]结合关联语义链与传统协同过滤算法,充分挖掘用户信息,缓解数据稀疏的问题;Gong[7]通过聚类平滑的方法填充评分矩阵,以降低评分数据的稀疏;Xu等[8]通过融合用户和项目的预测评分,填充评分矩阵。以上方法虽然在一定程度上解决了数据稀疏的问题,但是推荐精度有待提高。为解决冷启动问题,王成等[9]通过引入项目热度对用户相似度进行改进,来提高推荐精度;郑孝遥等[10]在传统协同过滤算法中引入信任度,算法在推荐精度上有较大提高;Guo等[11]将显式或隐式的评分和信任用户相结合,对算法进行改进;郭艳红[12]运用平均值法,作为新项目的预测值,改善了冷启动问题;Ahn[13]提出一种新的启发式相似度,改善了冷启动下的推荐性能。
这些方法一定程度上解决了已有算法存在的一些问题,但是算法比较单一,实际应用效果并不理想。
本文在上述研究的基础上,提出一种融合信任相似度的个性化推荐方法,即利用借阅记录中的借阅时长、借阅方式等构建用户-图书评分矩阵,引入信任相似度对传统的相似度进行改进,根据邻居用户计算得到图书推荐度,结合新书的推荐度,实现图书推荐。实验结果表明,该改进方法降低了评分稀疏,提高了图书推荐的精度。
1 研究背景
协同过滤推荐最早被运用在电子商务领域[14],包括基于用户的协同过滤推荐[15]和基于项目的协同过滤推荐[16]。
数据稀疏问题是协同过滤存在的最大问题,评分少将会导致评分数据稀疏,进而使用户相似度计算不准确,无法为用户找到最近邻居,影响推荐精度。在图书馆中,用户和图书的数量十分庞大,但是用户借阅记录中的评分极少,评价矩阵存在严重稀疏问题,无法准确为用户推荐图书。
冷启动问题是协同过滤存在的另一个问题,在高校中,每年都会有新用户,新用户没有借阅记录,在计算新用户相似度时,没有可依据的数据,因此新用户得不到良好的推荐;图书馆新购入的图书,没有被用户借阅过,也无法被推荐。
本文对传统协同过滤算法进行改进,通过借阅信息构建用户-图书评分矩阵来缓解数据稀疏和冷启动问题,融入信任相似度来提高用户的相似度,以解决存在的问题,提高个性化推荐精度。
2 融合信任相似度的个性化推荐模型构建
本文的图书馆借阅数据包括用户信息表(姓名、性别、单位)、图书信息表(书名、出版社、作者、索书号)、借阅信息表(借阅时长点、借阅次数)三个维度,利用图书馆借阅数据中这三个维度的信息,经过分析处理,建立个性化推荐模型,将符合用户需求的图书推荐给用户,为用户提供个性化阅读服务。融合信任相似度的个性化推荐模型如图1所示。
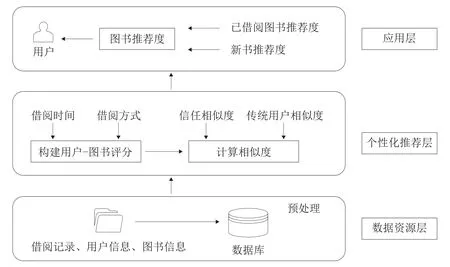
图1 融合信任相似度的个性化推荐模型
改进后的融合信任相似度的个性化推荐模型主要包括数据资源层、个性化推荐层和应用层。其中,数据资源层是将借阅记录、用户信息、图书信息进行预处理;个性化推荐层用于构建评分和计算相似度,寻找最近邻居;应用层是根据推荐度的高低将图书推荐给用户。
2.1 融合信任相似度的个性化推荐算法的步骤
传统的协同过滤个性化推荐算法由于评分数据稀疏,计算得出的用户相似度不准确,因而推荐精度很低。根据上面的分析,本文将对传统的推荐算法改进,提出一种融合信任相似度的个性化推荐算法,可以将融合信任相似度的个性化推荐算法概括为以下步骤:①根据借阅记录中的借阅信息,构建用户-图书评分矩阵;②根据构建的评分矩阵,使用余弦相似度计算出用户相似度;③分别计算显性信任度、隐性信任度、新用户信任度,得出综合信任度;④将用户相似度与综合信任度相融合,计算出改进后的用户相似度;⑤根据改进后的用户相似度,找到用户的最近邻居;⑥根据最近邻居借阅的图书,得出图书的推荐度,与新书推荐度融合,得到最终的图书推荐度。其中,输入内容为用户借阅记录、用户信息、图书信息、信任系数(α1、α2、α3),用户相似度因子(β)、邻居用户数,输出内容为图书的推荐度。
2.2 用户-图书评分矩阵构建
在实际应用中,高校图书馆虽然提供了评分功能,但是用户对图书的评分很少,甚至没有,评分矩阵比较稀疏,因此可以通过借阅信息来构建用户-图书评分矩阵。在图书馆的借阅系统中可以获取用户对图书的借阅时长及借阅方式等相关数据,本文以此为基础,构建用户-图书评分矩阵。
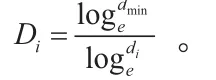
用Rij表示用户i对图书j的借阅时长所得的评分,Tij表示用户i对图书j的借阅时长,Tmin表示该图书被借阅的最短时长,Tmax表示该图书被借阅的最长时长。
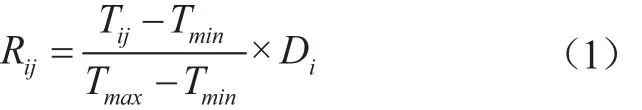
(2)借阅方式。用户的借阅方式可以分为初借和续借。初次借阅时用户没有目的,只有所借阅的图书对其有意义,用户才会续借。因此,初借和续借两种借阅方式的比重不同,用Bij表示用户i对书j的借阅方式所得的评分,Bij可以根据历史数据统计分析设置。
本文通过借阅时长、借阅方式两者之和构建评分矩阵,用R’ij表示构建的评分矩阵,即R’ij=Rij+Bij,所构建的用户-图书评分矩阵如表1所示。

表1 用户-图书评分矩阵
2.3 用户相似度
个性化推荐算法中,相似度是核心。传统的协同过滤算法根据用户相似度对未评分图书进行预测。实际上,除用户间的相似关系外,用户间隐含的信任关系也会影响图书的推荐。在用户之间,也会存在一种信任与被信任的关系,因此本文引入信任相似度,将信任相似度融入用户相似度中。
(1)显性信任度。显性信任指用户之间存在很明显的信任关系,本文即共同借阅过相同书籍的用户间存在显性信任关系。两个用户共同借阅的图书数量越多,显性信任度越大。
用Bu表示用户u的借阅书目集,Bv表示用户v的借阅书目集,Bm表示与用户v具有最多共同借阅书目的用户借阅书目集,Bu∩Bv表示用户u和用户v的共同借阅书籍数量。
令表示用户u和用户v之间的直接信任关系,即用户u信任用户v的程度,直接信任度表示为公式(2)。
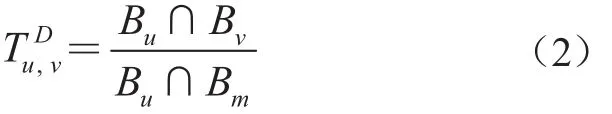
其中,Bu∩Bm表示用户u与用户v具有最多共同借阅书目的用户的借阅书目集的交集。
信任度的范围[0,1],当Bu=Bm时,与用户具有最多共同借阅书目的用户信任度等于1;Bu=Bv时,信任度等于0;其他情况下直接信任关系的信任度小于1。
(2)隐性信任度。很多用户之间没有共同借阅过相同书籍,不存在显性信任关系,无法直接计算信任度。本文利用信任的传递性来计算两个用户之间的隐性信任度,可以根据用户之间的显性信任关系推导出用户之间隐含的信任关系,通过共同朋友的借阅信息,来实现个性化推荐。
用表示用户u与用户v的隐性信任,i表示用户之间的共同朋友,m表示两个用户之间共同的朋友数量。
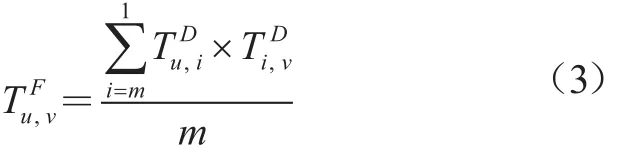
(3)新用户信任度。新生刚入校,借阅图书时没有目标,通常情况下更愿意信任同专业的同学,且新生在填写注册信息时会有具体的学院专业信息。因此,本文提出新用户信任,可以在一定程度上对新生进行个性化推荐。新用户信任用表示,通过历史统计数据分析,相同专业的新用户信任为0.6,不同专业的新用户信任为0.4。
(4)综合信任度。将上述3种信任进行加权融合,得到用户的综合信任度。用来表示综合信任度。
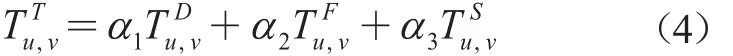
其中,α1、α2、α3分别表示显性信任、隐性信任、新用户信任的权值,并且α1+α2+α3=1。
(5)相似度计算。将信任相似度与用户相似度进行融合,得到最终的用户相似度。simnew(u,v)表示改进后的用户相似度,sim(u,v)表示用户相似度,表示信任相似度。
其中,0≤β≤1。
2.4 图书推荐度
图书推荐度指图书的可推荐程度,计算出每本图书推荐度后,将推荐度高的图书推荐给用户。本文将图书分为已借阅图书和新书两类。
(1)已借阅图书的推荐度。已借阅图书的推荐度指已经被借阅过的图书的可推荐度。用Pu,i表示被借阅图书的推荐度,若用户已借阅多本图书,表示用户u对图书的平均评分,表示用户v对图书的平均评分。

(2)新书推荐度。图书馆每年都会引进一批新书,这些新书没有用户的评分及借阅记录,无法推荐给用户。同一院系中,虽然专业不同,但基础课程差别不大,用户的借阅需求基本相同。本文利用中图分类号,进行新书推荐。中图分类法将相同学科、相同主题的图书归为一类。在图书信息表中,通过索书号中的中图分类号可以了解用户借阅图书类目,根据用户以往的借阅记录分析各类图书所占的比重。以山东科技大学泰安校区的3个院系为例,根据用户的以往借阅记录,分析得出不同类型的图书在各个院系所占的比重,如表2所示。

表2 不同类型的图书在各个院系所占比重示例
(3)图书推荐度。融合新书的推荐度和被借阅图书的推荐度,得到最终的图书推荐度。设Pz表示图书推荐度。

其中,Pa表示新书的推荐度。
3 实验结果及其分析
3.1 实验数据集
为验证本文所提出推荐算法的可用性,选取山东科技大学图书馆的后台借阅记录数据进行试验,将数据范围定位为7197名学生的借阅记录,时间跨度为2012年9月—2017年7月,共100986条借阅记录,涉及283568本图书。将这些数据划分为训练集和测试集,训练集为2012年9月—2016年7月的借阅数据,测试集为2016年9月—2017年7月的借阅数据。以随机方式从信息系、经管系、文法系中各抽取30名学生的借阅记录进行试验。
3.2 评价标准
推荐准确率是衡量算法推荐能力的标准之一,本文使用推荐准确率(MAE)来验证算法的推荐质量。MAE越小,则表示推荐越准确。

其中,N为进行预测图书的数量,Rui为用户的实际评分,Pui为预测的评分。
3.3 实验结果及分析
本文主要分析设计参数α1、α2、α3、β、不同邻居数对推荐准确率的影响,以及所构建评分矩阵的有效性验证,设计5组不同的实验,选择最优参数,最后与其他模型进行对比分析。
(1)评分矩阵的有效性验证。用评分数据的稀疏来衡量用户-图书评分矩阵的有效性,计算得到改进前的评分数据稀疏为96.19%,通过构建用户-图书评分矩阵,得出评分数据稀疏仅为0.90%。
可以看出,本文提出的构建方法,极大地改善了评分数据的稀疏,解决了高校图书馆评分严重稀疏的问题。
(2)信任参数α1、α2对实验结果的影响。由于对于所有老用户,α3=0;因此将信任参数分成10组分别进行验证,对应的MAE值如表3所示。
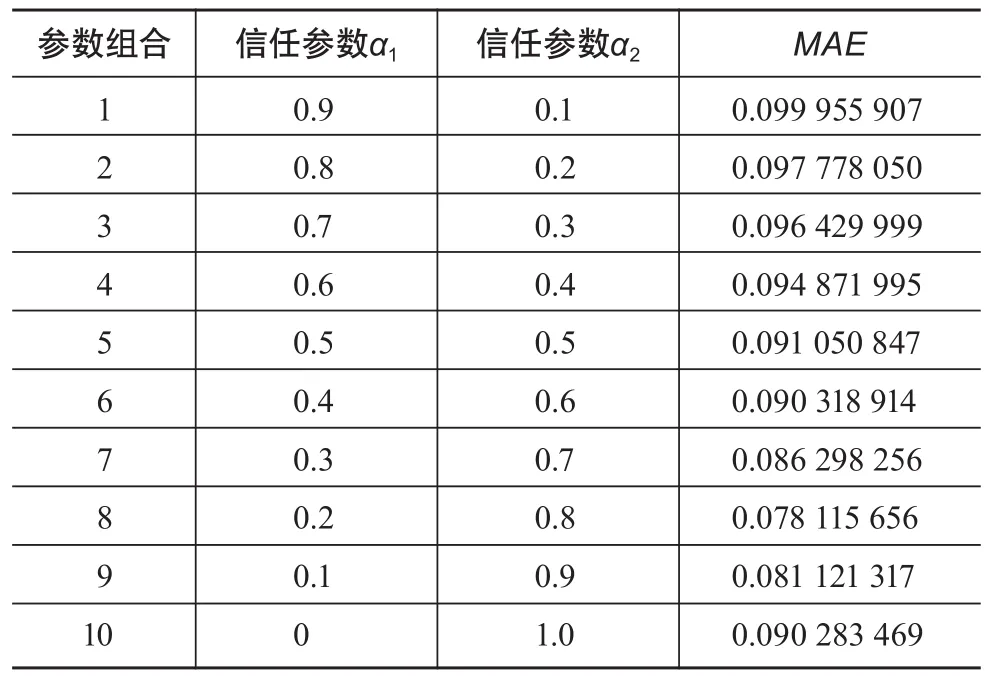
表3 参数组合对应的MAE值
实验表明,在其他参数默认的情况下,信任参数组合8时MAE值最小,即α1=0.2,α2=0.8时,MAE值最小,推荐效果最好。
(3)相似度权重因子β的取值。此实验验证β取值的大小对推荐效果的影响,推荐效果用也MAE来衡量,MAE值越小,推荐质量也就越高。为找到MAE的最小值,实验将在训练集上以不同值进行训练,在测试集中进行测试,测试结果如图2所示。
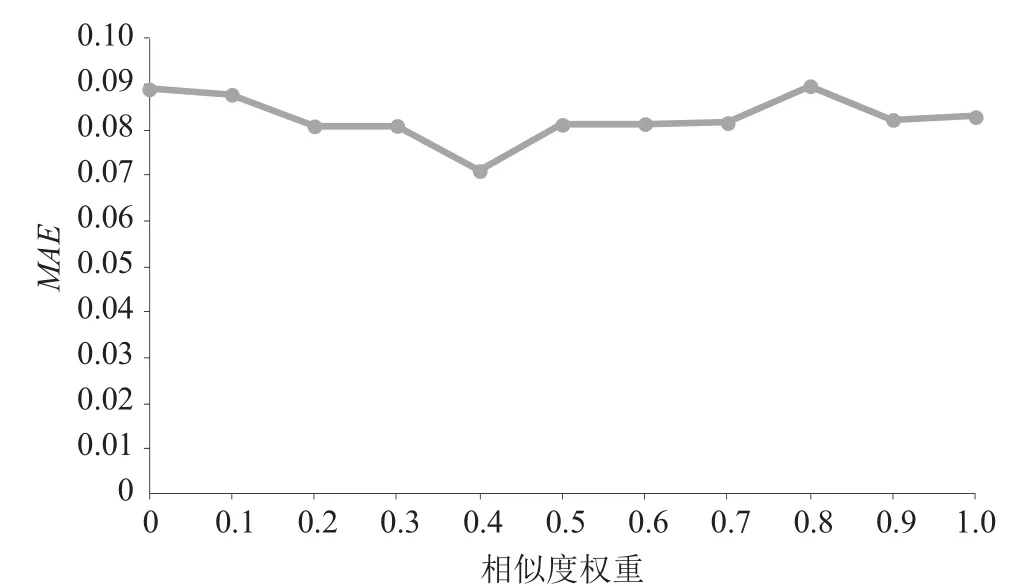
图2 不同权重下MAE的值
由图2可以看出,在β=0.4,根据公式(5),即信任相似度为0.6时,MAE值最小,此时推荐最准确,因此本文将用户相似度权重β设为0.4。
(4)设置邻居个数。选择不同的用户规模进行推荐,从用户信息表中随机抽取用户,最近邻居数分别取5、10、15、20、25、30,间隔为5。实验结果如图3所示。
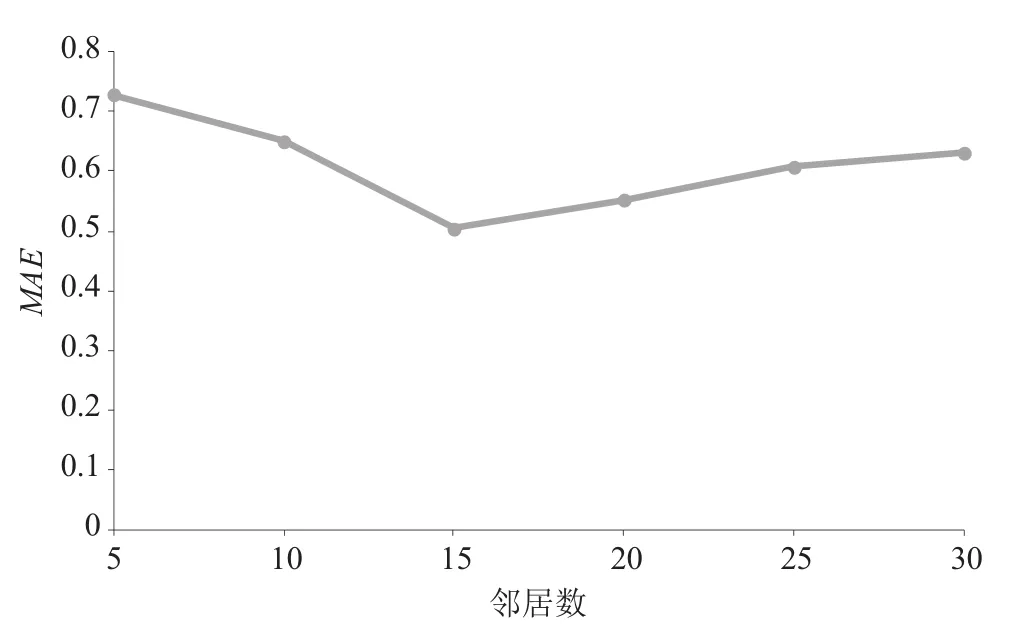
图3 不同邻居数下的MAE值
由图3可以看出,在邻居数15之前,MAE值逐渐减小,当邻居用户为15时,MAE值最小,此时对用户的推荐精度最高。
(5)本文提出的改进算法与传统协同过滤算法的对比。为验证本文算法的准确性,基于相同的邻居数下,对比传统的协同过滤算法与改进后的协同过滤算法下MAE的大小,实验结果如图4所示。
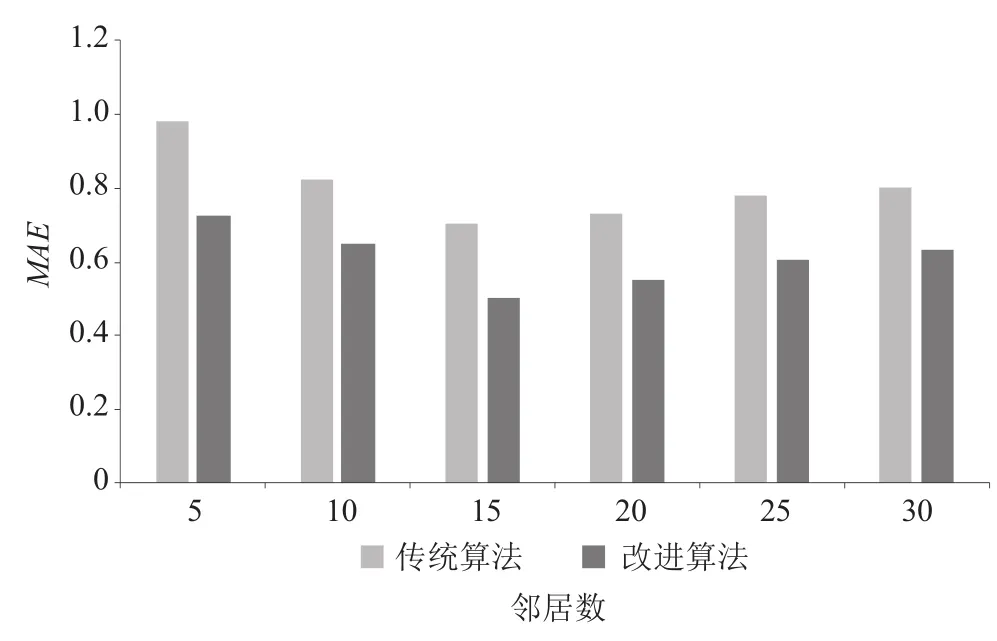
图4 两种不同算法的比较
从图4可以清楚地看出,本文提出的改进算法推荐精度明显高于传统协同过滤算法。
4 结语
本文针对传统协同过滤算法存在的问题,结合高校图书馆的实际特点,提出了一种融合信任相似度的高校图书馆个性化推荐方法。以用户的借阅信息构建用户-图书矩阵,有效地解决了评分数据严重稀疏的问题,将信任相似度融入传统的用户相似度,极大地提高了推荐精度,同时,提出的新生信任度及新书推荐度改善了冷启动现象。实验结果表明,融合信任相似度的高校图书馆个性化推荐方法具有很好的推荐效果,但本文仍存在一定欠缺,后续将针对冷门图书进行推荐,提高资源利用率,并进一步完善算法,以求达到更精确的推荐效果,为高校用户提供更好的服务。
猜你喜欢
文苑(2020年4期)2020-05-30 12:35:12
少年博览·小学高年级(2018年10期)2018-12-10 09:00:04
新闻传播(2018年12期)2018-09-19 06:27:10
环球时报(2018-01-23)2018-01-23 05:25:53
桃之夭夭B(2017年2期)2017-02-24 17:32:43
知音海外版(上半月)(2016年12期)2017-01-13 13:10:09
汽车与新动力(2016年6期)2017-01-04 10:50:48
计算机工程(2015年4期)2015-07-05 08:27:45
中国卫生(2015年1期)2015-01-22 17:20:15
高中生·青春励志(2014年11期)2014-11-25 10:07:54
