
基于卷积神经网络的实时人群密度估计
2018-09-17 11:35:46李白萍韩新怡吴冬梅
图学学报 2018年4期
李白萍,韩新怡,吴冬梅
基于卷积神经网络的实时人群密度估计
李白萍,韩新怡,吴冬梅
(西安科技大学通信与信息工程学院,陕西 西安 710054)
针对传统实时人群密度估计方法存在误差大、分类效果不佳等缺陷,提出了基于卷积神经网络的实时人群密度估计方法。通过对比4种常见网络结构:AlexNet、VGGNet、GoogLeNet和ResNet的准确度与实时性,选择综合性较好的GoogLeNet作为人群密度估计的模型,利用关键帧截取技术实现人群密度的实时估计并简要分析人群密度特征图。最后用实例验证了该方法的实时性与准确度,证明了其可行性。
人群密度;卷积神经网络;视频处理;实时估计
1 研究背景
人群密度作为描述人群聚集程度的参数,可以用来衡量人群的可控性与安全性。当人群密度上升时,人的不适程度也会随之增加,人群会更不稳定、不易控制。FRUIN[1]提出人群密度达到7.5人/m2时,人群易失去控制,发生灾难性事件的潜在可能性较大。传统的人群密度估计方法采用人工统计法,费时、费力且效率低下。近几年,人工智能正处于蓬勃发展的时期,特别是深度学习,已在图像处理领域取得了巨大的成功。目前,深度学习也逐渐被用于视频分析上,并取得了一定的成果。因此,可考虑利用深度学习良好的图像处理能力对视频中人群进行密度估计。
大多数人群密度估计方法是将人群看作一个整体,寻找某种可以描述整个人群的特征,然后建立此特征与人群密度之间的关系,利用此关系估计人群密度。根据所选特征的不同,常规的人群密度估计方法分为像素统计法[2]和纹理分析法[3]。像素统计法的核心是认为人群前景图像的像素数与人群密度存在正比例关系,借由计算整幅图像中人群前景像素数所占的比例大小,估计出人群密度。虽然此方法直观易理解,但当人群遮挡情况严重时,人群前景图像的像素数无法真实反映人群密度情况,存在估计不准确的现象。纹理分析法的思想是将密度与人群图像的纹理特征联系起来,当人群密度高时,图像的纹理较细,反之纹理较粗。一般来说,纹理分析主要采用较为传统的灰度共生矩阵法(gray level dependence matrix, GLDM)[4],纹理粗时矩阵变化较为缓慢,反之则变化快。GLDM能够很好地解决人群的重叠遮挡问题,在人群密度大时有良好的效果,但当人群密度较低时,此方法并不能保证良好的效果。上述两种方法均是人工从视频图像上提取预先划定好的特征,送入合适的分类器中分类。但人群场景较为复杂,人工选取的特征并不一定能完全地适用于各种情形,如像素统计法和纹理分析法均存在短板,且很难统一。
使用卷积神经网络处理静态人群图片能克服上述缺点,但静态图片不能满足实际生活中的实时性要求。为此,本文使用卷积神经网络,对视频的关键帧进行处理,完成视频上的人群密度估计。且使用PETS2009视频库[5]中的视频作为研究对象,将带标签的视频帧作为卷积神经网络的输入训练模型,提取出可表征人群密度的特征,输出则为人群密度的5个类别:Very Low (VL),Low (L),Medium (M),High (H),Very High (VH)。相比于常规方法,深度学习对人群视频有较好的适应性和鲁棒性,可以克服上述两种常规方法的缺点,能够真实地估计出人群密度情况。
2 卷积神经网络模型的选取
2.1 卷积神经网络的结构
卷积神经网络都是用卷积层、池化层等基本部件堆叠起来的结构。其均是前向传播计算输出值,后向传播调整权重与偏置。卷积层中包含多个卷积核,其分别与输入进行卷积,生成对应的特征图。设输入为×的矩阵,卷积核的大小为×,偏置为1,卷积后可得到大小为(–+1)×(–+1)的特征图。计算过程如下
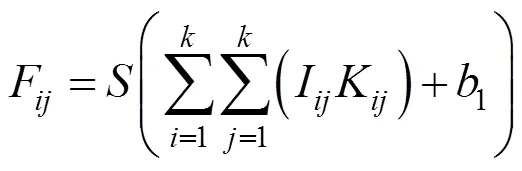
其中,F是为特征图矩阵中的元素;I为输入层与卷积核相对应的元素;为激活函数。
池化层是对原始特征图的二次特征提取,使用一个新的特征代替小区域的总体特征。池化后的高层特征图降低原特征图的维度,避免过拟合问题。池化的方法分为平均池化和最大池化[6]:平均池化是对需要池化的区域中的左右元素求和,取平均数为最终特征;最大池化是取池化区域中最大的元素为特征。两者的计算过程如下

其中,为原始特征图经过步长为、池化区域为×、偏置为2的池化层所得到的子采样特征图;max=1(F)为原始特征图池化区域×中的最大元素。
虽然采用的部件基本相同,但不同的网络结构由于卷积层尺寸大小和网络深度之间的差异,对同一数据集会呈现出不同的效果。目前,较为经典的网络结构有AlexNet、GoogLeNet、VGGNet和ResNet,由于其深度、参数量以及模型大小各异,因此需选择一个较为合适的结构完成视频上的人群密度估计。
2.2 基于准确度考虑
对于人群密度估计,首先要保证密度估计准确无误。AlexNet、GoogLeNet、VGGNet和ResNet这些结构在历年的ImageNet挑战赛均取得过很好的成绩,在ImageNet 1000类别数据集上的top-5错误率均可达到17%以下。但本文使用的PETS2009数据集规模远小于ImageNet,且类别更细化,因此需要网络有更好的特征提取能力。
从特征提取角度来看,网络越深,提取特征的能力越强,最终的分类结果也就越好。另外,网络路径数目的增加也成为卷积神经网络的一种设计趋势,人们在增加网络深度的同时扩增网络中的分支数量,使得模型的精度大幅度提高[7]。以下是对上述各网络在准确度和网络深度与结构上的讨论。
(1) AlexNet的深度为8层,前5层是卷积层,后3层是全连接层,在最后一个连接层可输出1 000个类别;AlexNet的网络分支较少,属于简单的链式结构。其在ImageNet上分类测试的top-5、top-1错误率分别为15.3%和36.7%[8]。单从准确度来看,AlexNet的效果并不十分出色,但其是第一个大规模卷积神经网络结构,且思想对后续的网络结构具有指导作用,如第一次采用Dropout减少过拟合,使用ReLU加快网络的收敛速度等。
(2) VGGNet有6种网络配置,这些网络结构的设计原则均相同,不同的是网络深度,最深可达19层。目前,较为常用的深度分别为16层和19层。VGGNet由AlexNet发展而来,也为链式结构,网络不存在额外分支,从输入到输出只有一条路径。VGGNet在分类与识别任务中均取得了不俗的成绩:效果最好的16层的VGGNet-D的top-5、 top-1错误率可分别低至7.3%和24.8%[9]。VGGNet取得如此优秀的结果,不仅是因为网络深,也因为其使用了多个小尺寸卷积核代替一个大尺寸卷积核,在增加网络非线性能力的同时减少了参数。
(3) GoogLeNet深度有22层,与前两种网络不同,GoogLeNet的路径分支众多,如图1所示,Inception结构增加了网络的宽度,宽度与深度共同提升了GoogLeNet的性能。
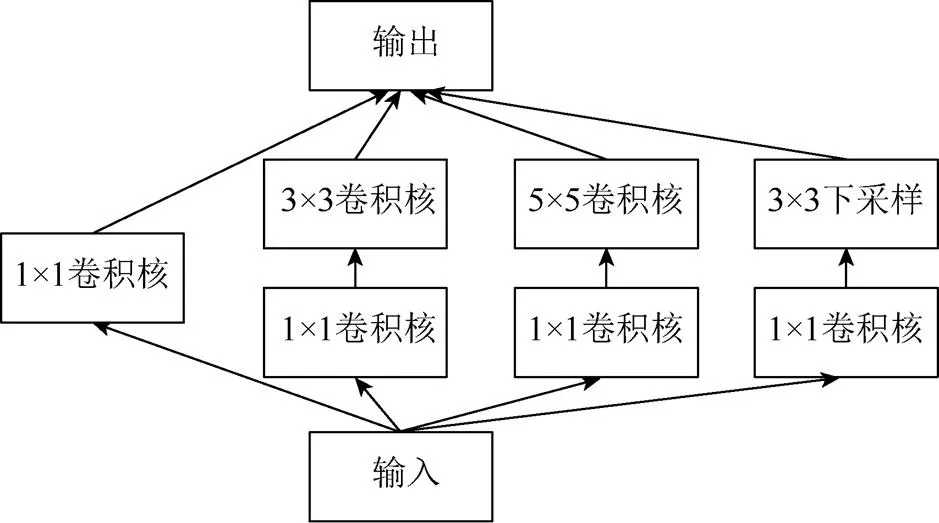
图1 GoogLeNet的Inception结构
(4) 在Inception结构中,使用了大小不同的卷积核,可融合不同尺度的特征,提高网络性能。GoogLeNet在ImageNet上分类的top-5错误率仅为6.66%[10],可见其性能十分优秀,深而宽的网络结构可以有效地提取和融合不同尺寸的特征,符合人群密度分类任务的要求。
(5) ResNet深度可达152层,引入身份捷径链接”(identity shortcut connection)解决了梯度弥散问题,使网络深度增加的同时性能不退化。最终,ResNet的top-5错误率为3.6%[11]。
2.3 基于实时性考虑
实时性是影响视频人群密度分类准确性的重要因素。对于视频,分类计算耗时长,将会导致预测结果滞后于视频内容,与实际结果偏差过大。因此,所选取的网络结构要在保证准确度的同时高效运算。网络的深度对计算速度有着重要影响,一般而言,层数越多计算耗时越长[12]。另外,参数量也能反映计算效率,参数越多,计算开销越大,效率就越低。以下是关于4种网络运算效率的讨论。
(1) AlexNet:8层网络结构。有3个全连接层,有60 M以上的参数量。由于结构层数最少,计算耗时最短,但因全连接层的存在其参数量并不少。虽然AlexNet实时性好,但准确度在4种网络中最低,卷积层少从而特征抽取能力弱,泛化能力也较差。
(2) VGGNet:深度和网络结构使得其计算单张图片所需的时间更长。由于拥有3个全连接层,参数量在133 M以上。
(3) GoogLeNet:参数量仅为7 M,远远小于AlexNet和VGGNet。虽然比VGGNet更深,但GoogLeNet的Inception架构可以将稀疏矩阵聚类为较为密集的子矩阵来提高网络性能,既保持网络结构的稀疏性,又利用了密集矩阵的高计算性能。另外,Inception使用1×1卷积核进行降维,使计算性能大幅提高。一般来说,具有Inception的网络比没有Inception的网络速度快2~3倍。GoogLeNet使用average pooling代替全连接层,大幅减少参数量的同时将top-1错误率降低了0.6%。GoogLeNet的计算速度低于AlexNet,远远高于VGGNet,加之准确度高,适合本文任务的要求。
(4) ResNet:残差网络越深,分类效果越好。常见的残差网络结构远比前3种深,计算开销较之更大,准确度高,但不满足实时性要求。
综上,AlexNet可满足实时性,但准确度不够高;VGGNet与ResNet的准确度高,但计算开销大,这3种网络均不适合本文任务。GoogLeNet不仅满足准确度要求,也满足实时性要求,因此本文选择GoogLeNet作为在视频是人群密度分类的核心算法。
3 人群密度分类
人群密度分类可建立人群图像与密度类别之间的某种关联,并以此作为衡量标准,对新的视频数据或图像数据进行人群密度估计。本文将人群图像的视频帧作为输入,用卷积神经网络寻找特征,并分析特征图。
3.1 人群密度特征图
对于人群密度估计,所选取的特征在很大程度上影响着估计结果。卷积神经网络的深层结构能抽取较为抽象的高层非线性特征,其对训练数据有着最佳的本征解释。在卷积神经网络中,卷积核可以探测特定的形状、颜色等[13],图2为训练完成的GoogLeNet模型的第一个卷积层中的卷积核。特征图中包含卷积核所抓取到的特征。因此,将已检测到细小形状、颜色的特征图作为网络下一层的输入,再次通过卷积获得更为复杂的特征。经过多层之后,抽取出的特征会变得复杂抽象。

图2 GoogLeNet第一个卷积层的卷积核
特征图可以显示图像经过不同的卷积核,卷积计算之后的情形。对特征图进行可视化后,能够清楚地观察CNN网络的工作过程。如图像进入卷积神经网络中,经过层层卷积、下采样后,特征图也相应地变得越来越倾向于某个类别。图3是取自PETS2009视频库中的3帧图片,分别代表人群密度为低、中、高3种情形。将其送入训练好的GoogLeNet模型,完成分类运算后,对图像经过第二个卷积层后的特征图进行可视化,如图3所示。
图4中彩色区域对应着3帧图片中的人群位置,其形状与人群形状相近,人越多,彩色区域越大,由此可见,人群的某个特征激活了对应该特征图的卷积核。特征图中的高亮彩色部分是“敏感”区域,对其分类结果的影响远大于蓝色区域。在卷积神经网络的低层,卷积核提取的特征较为简单,即线条、形状及颜色等,因此在特征图右上角检测到了某种与人群相似的特征,即高亮区域。类似于这样的误检区域会随着卷积层数的增多而减少。越往高层,经过的卷积层越多,特征图越接近于简单的像素块。图5为高密度时某一高层特征图。其彩色部分依旧是对分类结果敏感的部分,但不同的是高层特征图已不再有人群形状等细节信息,说明高层的卷积核提取的特征更为复杂,这种特征必然是人群所独有的特征。

图3 3种密度的人群图

图4 人群图像的特征图

图5 高密度人群图像的高层特征图
3.2 实时人群密度分类
视频是由连续的帧图像组成的,帧中记录了视频里的所有信息,使用卷积神经网络处理视频的实质是对其视频中的帧进行处理。但视频相邻帧之间图像的变化非常小,存在一定的冗余信息。实际上,人群在1 s内不会发生巨大变化,但视频1 s内至少有25帧,如果将全部的帧送入卷积神经网络,意味着处理一帧图片的时间需要低于40 ms才能保证实时性。在实际处理中,不同图片的处理耗时并不相同,有些图片需要更长的处理时间。处理全部帧必然因为处理耗时而累积与实际情况的时间差,因此,将全部的帧送入模型处理不仅会加重硬件资源的负担,更会拖慢处理速度,降低实时性。为了进一步保证人群密度估计的实时性,降低GPU的压力,本文使用静态图像作为训练数据集训练模型,在实际估计时从视频中每隔固定时间抽取视频的一帧,缩放及归一化处理后送入网络进行计算,在保证实时性的同时减小了硬件压力(图6)。截取帧时,按照时序每隔25帧取一帧,尽可能保留时间信息。预处理即对图像的尺寸做归一化处理,以及对帧图像的零均值处理。GoogLeNet要求输入图像的大小为224×224,因此需要对截取到的帧图像的尺寸归一化。数据预处理还包括在RGB 3个通道上分别减去该维的均值,使彩色帧的每一个维度都具有零均值。
4 实验与分析
4.1 视频人群密度估计实验
实验使用PETS2009数据集作为数据来源,内部有不同时间、不同视角的人群视频段,在不同的视角下,视频中的背景是不相同的。选取4个视角下共36段视频作为最终使用的数据集。将数据集中的所有视频段按照1︰1的比例分为训练数据集和测试数据集。一般训练集中的数据要比测试集中的数据多,才能使模型学习充分。但在本实验中,由于数据集的背景场景较少,因此适当减少训练集的数据并且增加测试集的数据,可以更有效的说明模型的泛化能力。在训练集中,将所有样本分为VL(Very Low)、L(Low)、M(Medium)、H(High)、VH(Very High)5类,分别对应人数为0~8人、9~16人、17~24人、25~32人及≥33人为。对于测试集,选取4个视频段,对其按照训练集的标准对帧分类并标注,作为测试精度的验证数据集;剩余视频段不分类标注,作为实时人群密度分类的输入视频。实验使用的网络模型有AlexNet、VGGNet和GoogLeNet。实验平台是在Windows 10上用VS2015搭建的Caffe平台,视频的读取预处理均使用Opencv-Python,GPU为GTX 1080。
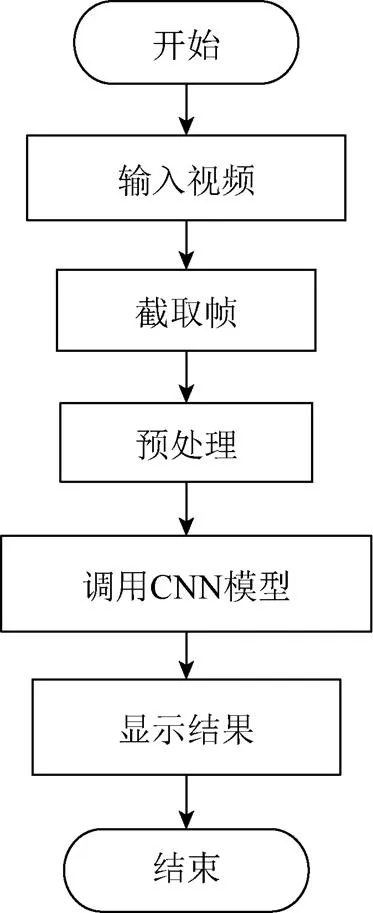
图6 实时估计流程图
直接使用人群数据集训练模型不仅收敛速度慢,且极易发生过拟合,因此实验使用人群数据集在ImageNet预训练模型上进行微调,迭代50 000次后测试精度达到99%以上时停止训练。其中,动量项为0.9,基础学习速率设为0.001,学习速率调整策略为均匀分布(step),batch_size设为32,权重衰减系数为0.002。使用预留的标注视频帧对训练好的模型进行精度测试,batch_size为50,最终测试误差低至2.5%。图7是模型误差随迭代次数增加的变化。
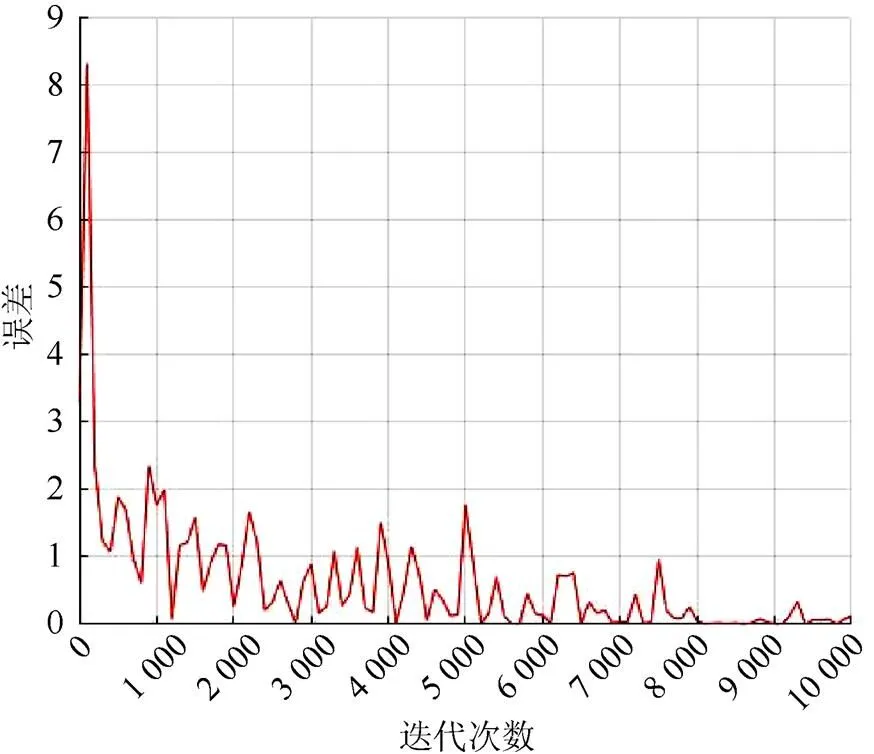
图7 GoogLeNet前10 000次迭代的误差情况
使用视频验证时,每隔25帧截取一帧分别送入AlexNet、VGGNet和GoogLeNet计算,并将分类结果显示在视频画面上,效果如图8所示。实验14段视频共截取出1 124帧图片,分类准确率为

从表1和式(4)中可以求出AlexNet的分类准确率为95.6%,VGGNet的准确率为96.9%,GoogLeNet的准确率为97.2%。由此可见,GoogLeNet准确率较高,能够克服传统方法的弊端。

表1 3种模型的错误分类帧数统计
4.2 实时性实验
在使用CUDA对卷积神经网络的计算进行加速,需要分类计算的帧图像平均每张耗时0.02 s,远远小于人群变化的时间,运算效率符合实时密度估计的要求。在使用CUDA对卷积神经网络进行加速的情况下,对层数相对较少的3种结构:AlexNet、VGGNet与本文使用的GoogLeNet进行了实时性实验。实验中使用GPU GTX1080,分别对3种网络模型处理单帧图片所需的时间进行比较。3种网络结构用相同的训练集进行训练,使用相同的50帧图片进行实验,统计时间并分别求模型的耗时均值。实验结果见表2。
表2 平均耗时比较

网络参数量(M)平均耗时(s) AlexNet600.034 VGG-D1380.079 GoogLeNet70.043
由表2可以看出,GoogLeNet的平均处理时间为43 ms,略长于AlexNet,但比VGGNet短很多。由平均时间可看出,网络无法在1 s内处理完25帧图像,且在实验中一些帧的处理时间达到了150 ms以上,如果将全部的帧送入网络处理,会造成处理结果远滞后于实际情况。因此,本文采用在1 s内抓取一帧进行处理,可以在基本保证实时性的情况下反映实际人群密度情况。
5 结束语
针对人群密度估计,使用卷积神经网络克服像素统计法的遮挡问题和纹理分析法在低密度效果不佳的问题,将估计准确率提升到96%以上并实现了对视频中的人群密度估计。但文中使用的数据集的背景较为理想,没有考虑视觉畸变问题。同时,使用的数据集的背景较为单一,因此在模型泛化上可能存在一定的局限性。人群安全不仅是要关注人群密度,也需要关注高密度时人群的行为,在未来,应该将人群密度与人群的运动分析相结合,使人群视频分析更加智能化。
[1] FRUIN J J. Pedestrian planning and design [M]. New York: Metropolitan Association of Urban Designers and Environmental Planners, 1971: 26-40.
[2] DAVIES A C, YIN J H, VELASTIN S A. Crowd monitoring using image processing [J]. Electronics & Communication Engineering Journal, 1995, 7(1): 37-47.
[3] MARANA A N, VELASTIN S A, COSTA L F, et al. Automatic estimation of crowd density using texture [J]. Safety Science, 1998, 28(3): 165-175.
[4] HARALICK R M. Statistical and structural approaches to texture [J]. Proceedings of the IEEE, 1979, 67(5): 786-804.
[5] FERRYMAN J, SHAHROKNI A. PETS2009: Dateset and challenge [C]//11th IEEE International Workshop Performance Evaluation of Tracking and Surveillance. New York: IEEE Press, 2010: 1-6.
[6] BOUREAU Y L, PONCE J, LECUN Y. A theoretical analysis of feature pooling in visual recognition [C]// Proceedings of the 27th International Conference on Machine Learning. New York: ACM Press, 2010: 111-118.
[7] SMITH L N, TOPIN N. Deep convolution neural networks design patterns [EB/OL]. (2016-11-14) [2017-06-10]. https://arxiv.org/abs/1611.00847.
[8] KRIZHEVSKY A, SUTSKEVER I, HINTON G. ImageNet classification with deep convolutional neural networks [C]//International Conference on Neural Information Processing Systems. Cambridge: MIT Press, 2012: 1097-1105.
[9] SIMONYAN K, ZISSERMAN A. Very deep convolution networks for large-scale image recognition [EB/OL]. (2015-04-10) [2016-12-4]. https://arxiv.org/abs/ 1409.1556.
[10] SZEGEDY C, LIU W, JIA Y, et al. Going deeper with convolution [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 1-9.
[11] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [EB/OL]. (2015-12-10) [2017-01-10]. https://arxiv.org/abs/1512.03385.
[12] 付敏. 基于卷积圣经网络的人群密度估计[D]. 成都: 电子科技大学, 2014.
[13] 马海军. 监控场景中人数统计算法的研究与应用[D]. 合肥: 安徽大学, 2016.
Real-Time Crowd Density Estimation Based on Convolutional Neural Networks
LI Baiping, HAN Xinyi, WU Dongmei
(College of Communication and Information Engineering, Xi’an University of Seience and Technology, Xi’an Shaanxi 710054, China)
In response to the deficiencies such as big error and poor performance in the traditional method of real-time crowd density estimation, a new one based on CNN is proposed. By comparing the accuracy and real-time of four common network structures—AlexNet, VGGNet, GoogLeNet, and ResNet, the GoogLeNet which has relatively better comprehensive performance is chosen as the model for crowd density estimation. We used the key-frame extraction technology to realize real-time crowd density estimation and briefly analyze the crowd density feature map. Finally, examples are analyzed to verify the real time, accuracy, and feasibility of this new method of real-time crowd density estimation.
crowd density; convolutional neural networks; video processing; real-time estimation
TP 391.4
10.11996/JG.j.2095-302X.2018040728
A
2095-302X(2018)04-0728-07
2017-10-16;
2017-12-18
陕西省重点研发计划项目(2017GY-095)
李白萍(1963-),女,广东广州人,教授,博士。主要研究方向为数字移动通信、数字图像处理。E-mail:610135278@qq.com
猜你喜欢
廊坊师范学院学报(自然科学版)(2022年3期)2022-10-11 04:32:06
北京航空航天大学学报(2022年8期)2022-08-31 08:58:24
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
高技术通讯(2021年3期)2021-06-09 06:57:24
科技视界(2021年4期)2021-04-13 06:03:56
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电测与仪表(2017年24期)2017-12-19 05:15:16
北京航空航天大学学报(2017年12期)2017-04-23 08:31:39
电视技术(2014年19期)2014-03-11 15:38:20
