
改进特征权重的短文本聚类算法①
2018-09-17 08:49郭锐锋
计算机系统应用 2018年9期
马 存,郭锐锋,高 岑,孙 咏
1(中国科学院大学,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
1 相关工作
随着移动终端智能化的发展,纷繁多样的短文本信息充斥着互联网的各个角落.由于短文本信息少,口语化严重,网络新词多,使用传统的文档聚类会导致向量空间模型高度稀疏,缺乏语义信息,所以需要针对短文本的固有特点寻求一种有效的模型表示和聚类方法.
传统的向量空间模型,主要通过特征词和权重来表示短文本数据,它的缺点也很明显,它忽略了同义词在语义中的贡献并且会出现特征稀疏的问题,进而造成维数灾难.为了解决短文本特征稀疏的问题,一些学者研究了外部信息增强的方法,对短文本特征进行扩展,从而提高聚类效果[1–3].然而语义扩展方法并没有解决“维数灾难”的问题,还带来了新的问题,比如聚类的效果完全依赖于知识库的丰富程序,无法识别新兴的网络新词,比如 2016 年流行的“老司机”,“发车了”等.另有一部分学者通过原始高维特征词空间映射到低维的潜在语义空间或主题空间,挖掘文本潜在的语义结构[4–6].但这种模型忽略了低频词的贡献,尤其是短文本中贡献度高的低频词,导致上述模型应用于网络短文本中的效果很差.
词向量是一种基于大量未标注的语料学习而来的低维分布式实数向量,充分挖掘了同义词之间的共现关系[7,8].基于此,本文结合短文本的特点和词向量的优势,提出一种改进的特征词权重并结合松弛词语移动距离(RWMD)的短文本聚类算法.首先,定义多因子权重规则,如文本中词性和情感词,对于情感词的处理主要包括文字和表情符号,接着使用Skip-gram模型基于定义好的权重规则训练特征词向量,最后引入RWMD距离计算文本之间的相似度并以此聚类.实验结果表明本文提出的方法切实可行,尤其是在网络短文本中效果明显.
2 改进的特征词向量及聚类模型框架
2.1 改进策略
短文本数据,尤其是论坛帖子,商品评论以及微博和微信的聊天记录,形式复杂多样,包含各种表情符号,在数据预处理阶段不能简单的将表情符号当作噪声直接去除,否则会失去一部分语义信息,即情感信息;另外由于数据包含的短文本的长度也大小不一,因此关键词的位置因素也必须考虑在内;再者就是词性对短文本的影响[9],名词、动词、形容词和副词是文本特征的重要组成部分,因此词性的贡献也不容忽视.基于此,本文在文献[8]中提出的特征权重计算法进行了修改,提出一种融合表情符号、位置因素以及词性信息的多因子加权策略的关键词提取方法:
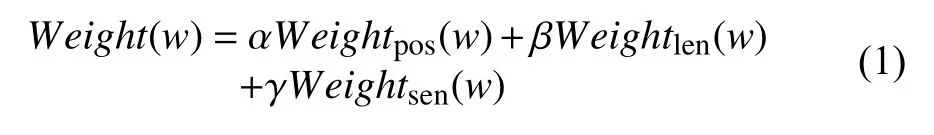
式中,Weight(w)表示词语w在文本d中的权重,Weightsen表示单词w在文本d中情感所占的权重,α,β,γ为加权系数,他们之和为1.Weightpos和Weightlen的计算公式参考文献[8],Weightsen的计算公式为:
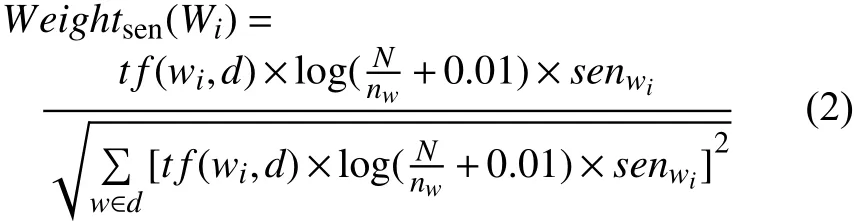
其中,tf(wi,d)表示特征Wi在文本d中的词频;N表示文本总数;表示所有文本集中出现第i个词语的文本数量;senwi表示该词的情感加权值,其具体值需要根据文献[10]的研究内容加以定义,将表情符号归为7个情感类别,结合实验用数据集,分别统计每一类情感所占比例,以此比例作为senwi的加权值.定义如表1所列.

表1 情感类别系数
在预处理阶段,当文本中含有表情符号时,会根据表1中的希腊字母进行替换.若一个短文本中含有多种表情符号,则根据多个表情符号的权值综合计算其权重;若一个文本中不含有表情符号,则在特征词权重的计算公式中,第3项将为0.即:
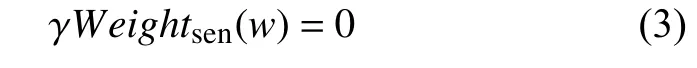
此时,α取经验值0.6.本文将此模型记为EFA(Emotion Fusion Algorithm)算法.
2.2 训练特征词向量
本文使用Mikolov[11]提出的基于Hierarchical Softmax构造的Skip-gram模型训练词向量,它主要包括 3层结构:输入层,投影层和输出层,目标函数L如式(1)所示:
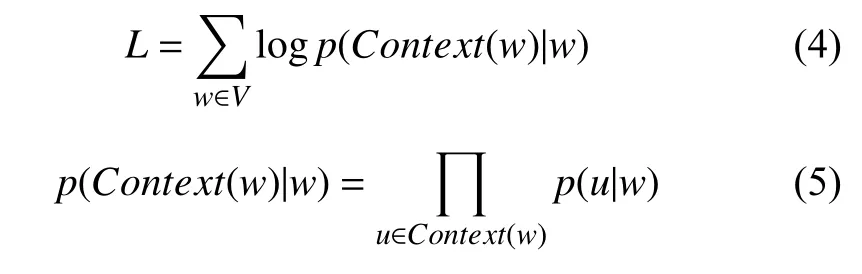
其中,V是数据词典,Context(w)表示单词w的上下文窗口,一般窗口值取5到10效果较好.
2.3 以特征词表征的短文本相似度计算
文本采用RWMD距离算法来计算文本之间的语义相似度,RWMD算法是基于WMD算法放松限制条件来降低算法的复杂度[12]改进而来.RWMD算法是将一个短文本的特征词向量全部流向另一个短文本的特征词向量所经过的距离总和的最小值作为两个短文本之间的语义相似度.
2.3.1 特征词之间的语义相似度
RWMD算法在计算文本的相似度之前需要先计算特征词之间的相似度,衡量两个特征词之间的相似度使用欧式距离来计算,即:

L的值越小,说明两个词越相近.
2.3.2 短文本之间的相似度计算
使用RWMD距离计算短文本d中所有特征词流向短文本d′中所有特征词距离和的最小值作为短文本d和短文本d′之间的相似度.假设允许短文本d中的每个特征词可以流向d′中的任意一个特征词,矩阵T ∈ Rn×n是转移矩阵,其中Tij≥0,表示词语i有多少转移到了词语j,C(i,j)表示词语i和词语j之间的语义相似度,目标函数为:
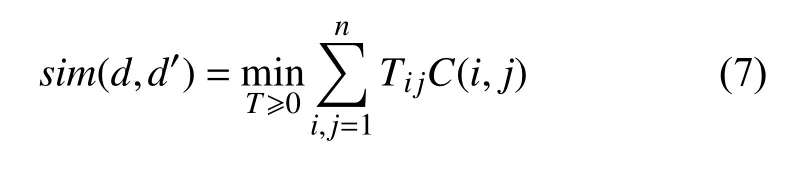
约束条件为:

2.4 K-means聚类算法流程

输入:实验所用的短文本数据集.通过数据预处理,并加权计算融合情感词权重的特征词集合,并由Softmax模型训练而成的特征词向量.输出:具有K类的短文本集合.Step 1.指定聚类数目K,以及K个初始聚类中心.Step 2.指定 RWMD 算法为距离函数.Step 3.计算每个文本向量d与K个初始聚类中心的RWMD距离,将每个文本向量d分配给距离最小的聚类中心.Step 4.重新计算新的K个聚类中心.Step 5.重复 Step 3 及 Step 4,直到聚类中心小于阈值.
3 实验与结果分析
3.1 实验数据
本文采用了3种类型数据集:微博数据、文本分类通用数据和QQ群聊天数据.其中文本分类通用数据集从中选取5个类别的标题;聊天记录数据人工标注出若干个聊天片段.具体描述如表2所示.
3.2 评价指标
为了使结果更有对比性,本文采用了文本聚类常用的准确率、召回率、和宏平均作为实验结果的评价指标:

其中,Pij、Rij和Fij表示类别i在类簇j中的准确率、召回率和F1值,Ci表示正确类别i中的文本数,Cj表示结果中类簇j中的文本数,Cij表示结果中类簇j中原本属于类别i的文本数,对于类簇j取各个类别中Fij最高的作为类别i的F1值,Fmacro表示宏平均的结果,m表示原始类别的个数.
3.3 实验结果与分析
本文使用VSM,LDA和BTM这3中模型对文本进行表示来验证模型的可行性和有效性,分别将结果记为KM-VSM、KM-LDA、KM-BTM,本文提出的模型结果记作KM-EFA.其中VSM中使用TF-IDF作为特征权重,LDA模型和BTM模型中主题数设为15,超参数 α和β 取经验值50/K,β=0.01,迭代次数为2000.
3.3.1 对比实验
在上文中介绍的3个数据集上分别使用上述4 种方法进行实验,使用平均F值作为评价指标,结果如表3所示.从表中可以看出,基于主题模型的聚类评测结果一般要好于基于VSM模型的聚类结果,说明无法发现同义词之间语义关系的模型会受到短文本数据特征稀疏的影响;基于BTM模型的聚类评测效果优于基于LDA模型的聚类效果,说明在短文本特征比较少的时候基于主题概率的统计方法统计出的数据意义不大.其中模型KM-EFA1是不考虑情感因素只考虑词性和位置因素的评测结果,而KM-EFA2是考虑了所有因素的评测结果.对比发现,本文提出的方法评测结果要优于对比方法,在3个数据集的试验中,性能比次优的结果平均提高了13.62%,从而验证了本模型使用情感加权更能挖掘出词之间的语义相似性,从而提高聚类效果.

表3 模型在数据集上的评测结果
3.3.2 特征值参数与权重系数分析
为了校验特征词选择过程的参数K以及情感权重加权系数 γ对聚类的影响,本文在3个数据集上分别取γ等于 0.1、0.25 和 0.45,同时对参数K在[5,100]范围以步长为5,进行遍历,结果如图1所示.
从图中可以看出,当情感权重系数不同时,随着K的变化,F值也变得有所不同.综合来说,当特征K在[40,50]之间时,F值表现最好,这是因为K太小时,特征个数不足以表达完整的语义,当K太大时,句子的主题信息不明显,会造成“富者越富”的现象,影响聚类效果.另外,当数据集中表现情感的词比较多时,情感权重的大小会直接影响聚类的好坏.如微博和聊天数据含有大量情感词,聚类的效果完全由情感权重决定,但在普通的分类文本中情感权重越大聚类效果则越差.

图1 特征个数与权重参数分析
4 结束语
本文融合情感加权的方法有效的提高了短文本的聚类效果,尤其在微博微信等即时聊天的短文本数据中,效果更好,这是因为在这类文本中人们使用表情符号的频率相对普通文本较高,此方法能充分挖掘符号下的语义信息.但随着深入的研究,这类文本中也充斥着大量的不规范用语,如“狗带”,“一颗赛艇”等,这些不规范用语对聚类结果产生一定的影响,尤其是一些拆分字没有办法对其准确的表示,比如“古月哥欠”,表达的是胡歌,但经过分词之后,这几个字会变得毫无意义,虽然这类词语出现频次较低,但往往这类词语是短文本的核心语义,同时用户故意使用这类词语一般均会涉及不正当言论,是网络监督和舆情管理的重要分析方向.因此,对这种现象的研究,具有重要的现实意义.
猜你喜欢
消费电子(2022年6期)2022-08-25
计算机技术与发展(2022年8期)2022-08-23
计算机系统应用(2021年9期)2021-10-11
疯狂英语·新阅版(2020年11期)2020-12-21
现代信息科技(2020年18期)2020-02-22
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
大作文(2016年7期)2016-05-14
Coco薇(2015年10期)2015-10-19
阅读与作文(英语高中版)(2013年12期)2013-12-11
