
L1范数约束正交子空间非负矩阵分解①
2018-09-17 08:49韩东,盖杉
计算机系统应用 2018年9期
韩 东,盖 杉
(南昌航空大学 信息工程学院,南昌 330063)
1 引言
非负矩阵分解(Non-negative Matrix Factorization,NMF)[1]算法因其收敛速度快以及分解后的稀疏分量能够清晰直观地描述原始数据等特点,在计算机视觉,文本聚类,模式识别等领域受到了广泛关注.NMF本质上是一种基于部分的矩阵分解方法,能够以非负形式表示原始数据的局部特征.
NMF将原始非负矩阵X分解为两个非负矩阵WH的乘积.分解后的矩阵仅包含非负元素,并且基向量W具有一定的数据局部表示能力,这使得NMF在诸多领域得到广泛运用.在文献[2]中,Park等通过人眼过滤和最小化基于NMF的重构图像错误率来进行人眼检测.考虑到数据集合的内部几何结构,文献[3]通过最近邻图来刻画数据集中相邻数据点的关系,提出了图正则化非负矩阵分解.为了充分利用判别信息,同时考虑到数据中的几何结构,文献[4]提出了K近邻非负矩阵分解(NMF-K-NN).在此基础上,Jun Ye等使用模糊集来处理模式识别中的不确定因素,提出了模糊K近邻非负矩阵分解(NMF-FK-NN)方法[5].Zhang等[6]通过最小化约束梯度距离,提出保持拓扑性非负矩阵分解(TPNMF),该方法能够保持脸部空间的局部内在拓扑结构.在研究聚类问题的过程中,Yang等指出[7],正交性的约束能在很大程度上优化聚类效果,其本质是施加正交性约束后的NMF结果更加稀疏,从而使原始数据的基之间区别性增强,进而提升聚类效果.Li等[8]提出基于正交子空间的非负矩阵分解(Non-negative Matrix Factorization on Orthogonal Subspace,NMFOS),将对W(或 H )的正交性约束作为NMF目标函数中的一部分直接进行优化,减少因施加正交性约束而带来的巨大计算量,同时还能在一定程度上提升基矩阵 W(系数矩阵 H )的稀疏性.
基于正交子空间的非负矩阵分解虽然能在一定程度上提升分解矩阵的稀疏性,但是它导致的稀疏程度是难以控制的.本文为了在分解过程中进一步提升分解矩阵的稀疏性,在分解过程中引入了L1范数约束,将L1范数约束转换成目标函数的正则部分进行求解,提出了L1范数约束正交子空间非负矩阵分解(Nonnegative Matrix Factorization on Orthogonal Subspace with L1 norm constrains,NMFOS-L1).本文方法不仅能提升聚类效果,同时还提升了分解结果的稀疏表达能力,具有实用价值.
2 非负矩阵分解
给定非负矩阵X=[x1,x2,···,xn]∈Rm+×n,NMF将原始矩阵分解为两个非负低秩矩阵 W 和 H,即:
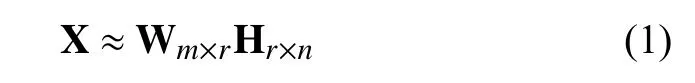
其中,r<<min{m,n}.NMF常采用欧氏距离衡量 W H对X的逼近程度,目标函数如下:
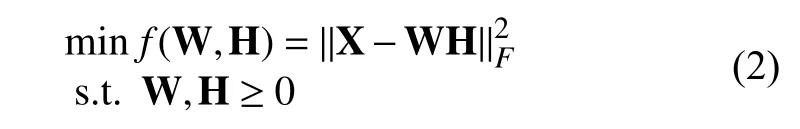
式中,‖·‖F为Frobenius范数,矩阵 W 的每一列称作基向量,矩阵 H 每一列为系数向量,将基向量进行线性组合来表示原始数据矩阵.Lee和Seung[9]给出如下乘性迭代规则:
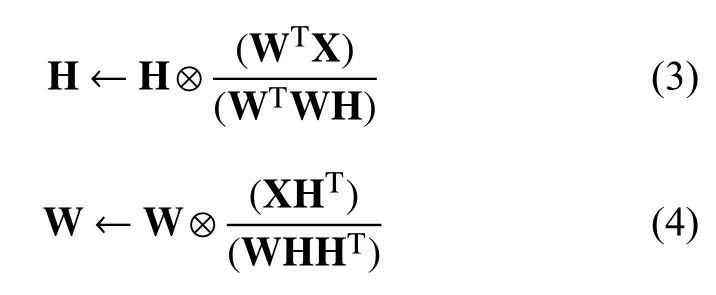
式中,⊗为矩阵元素的乘积运算符号,交替进行式(3)和式(4),可以求得式(2)的系数矩阵和基矩阵.
3 基于正交子空间的非负矩阵分解
NMFOS将分解所得矩阵的正交性约束通过拉格朗日乘子引入到矩阵分解的目标函数中进行优化,从而使分解结果的正交性不必通过正交性约束完成,减少计算量.NMFOS的目标函数如下:对矩阵W加入正交性约束,目标函数为:
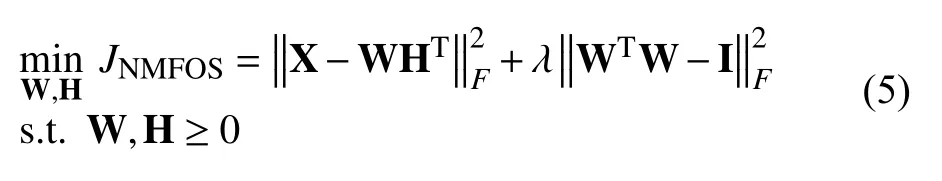
对矩阵 H 加入正交性约束,目标函数为:
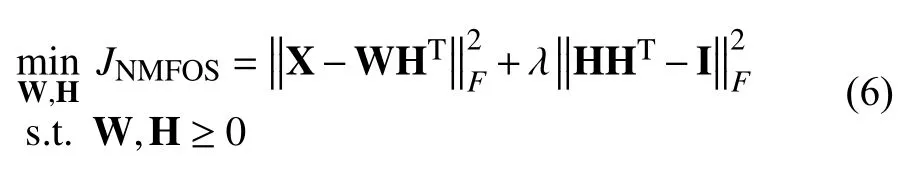
其中,λ ≥0为正则参数,I是全1矩阵.对于式(5)和式(6),Li等[8]给出了如下的乘性迭代规则:
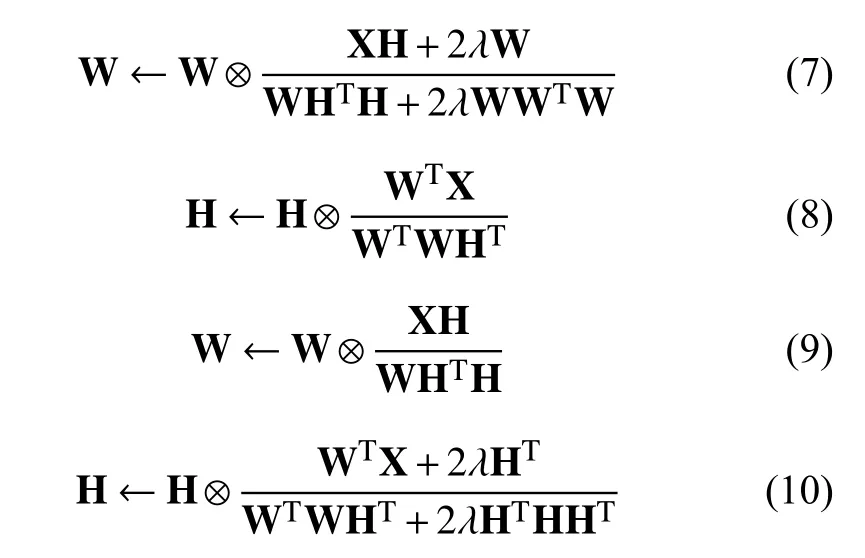
4 L1范数约束正交子空间非负矩阵分解
NMF算法的分解结果在一定程度上呈现稀疏性,但是稀疏程度难以控制.Hoyer于2004年提出稀疏性非负矩阵分解[10],在目标函数上添加L1正则化的稀疏约束.如果对NMFOS加上正则化的稀疏约束,那么就可以得到更加稀疏的分解矩阵,从而提高分解质量.
通过引入稀疏约束条件到NMFOS的目标函数,将稀疏约束正交子空间非负矩阵分解归结为下列优化问题:对矩阵 W 而言,目标函数为:
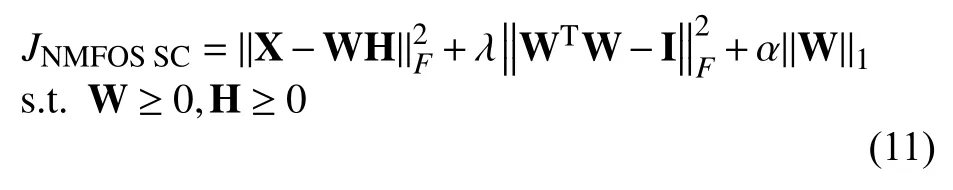
对矩阵 H 而言,目标函数为:
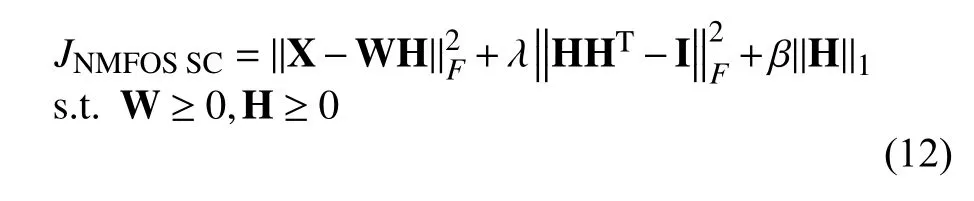
式中,λ,α,β均为大于0的常数.利用最速下降法和乘子迭代法,推导出上式的乘性迭代规则;首先新的目标函数可表示为:

5 实验与结果分析
为了验证NMFOS-L1算法有效性,本文在手写体数字光学识别数据集(Optical Recognition of Handwriting Digits)[11]、ORL 人脸数据库[12]和Yale人脸数据库[13]进行了聚类的对比实验.同时,为了验证本文算法所得到的基矩阵的稀疏性,在ORL和Yale人脸数据库进行实验,比较了几种不同算法的稀疏表达能力.
手写体数字光学识别数据集:该数据集从UCI数据库中选取0,2,4,6几个数字,构成2237个样本,每个样本有62特征,分为4个类.ORL人脸数据库[12]是由40个人,每人10幅图像构成.每幅图像为256个灰度级,分辨率为1 1 2×92.该库的人脸图像表情变化,面部细节,以及拍摄角度变化较大.图1为ORL人脸库同一个人的10张图像.

图1 ORL人脸数据库
Yale人脸库[13]包含15个人每人11幅共165幅人脸图像,这些照片在不同的光照条件和角度下拍摄,人脸表情也有较大变化.每幅图像均为1 0 0×100像素.图2为Yale同一个人的10张图像.

图2 Yale人脸数据库
5.1 聚类实验
在聚类问题中,常见的评测指标是纯度和F值.本文在已知类标签情况下,将不同算法的聚类结果进行对比,利用纯度来评价不同算法产生的分类效果.纯度:所有簇的纯净度的均值.范围为[0,1],数值越大,纯净度越高,效果越好.定义式为:
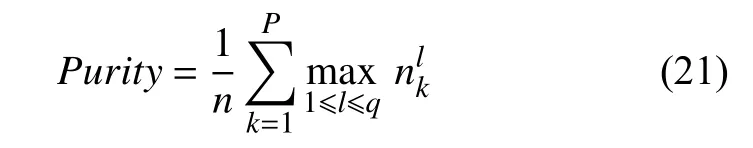
式中,q为总的类数,nlk是簇k中标记为类l的个数.聚类熵:度量各簇中所有类的分布情况.取值范围为[0,1],取值越小,聚类效果越好.定义如下:
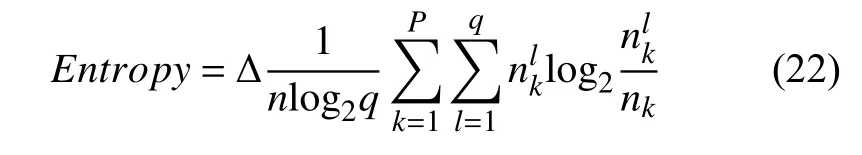
在本节实验中设定P=q,在每个数据库独立地重复实验200次,并设定迭代次数的最大值为2000.在实验时,选取参数 λ=5,β=1.实验结果如表1所示.
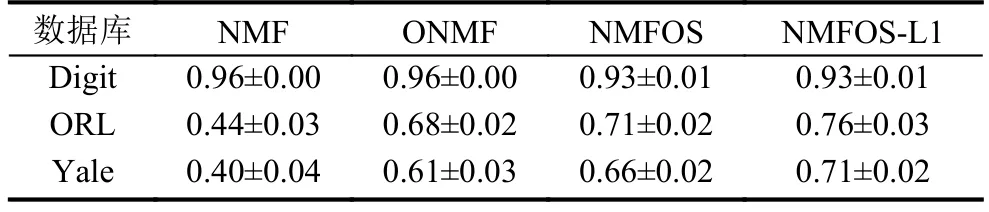
表1 三种数据库上的聚类纯度(均值±方差)
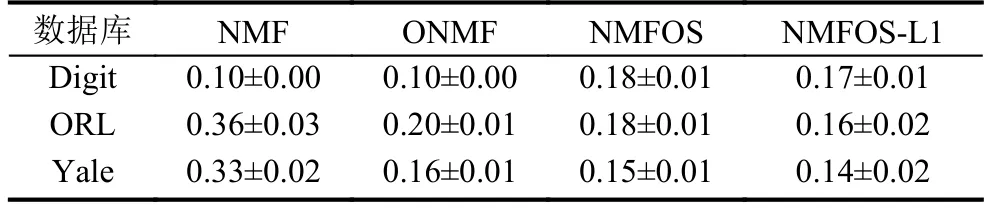
表2 三种数据库上的聚类熵(均值±方差)
5.2 稀疏性对比实验
本节我们在ORL和Yale人脸数据库上进行人脸特征提取,对比了NMF、ONMF、NMFOS、和本文NMFOS-L1几种算法的局部表达能力.图3给出了秩为25时,不同算法得到的基矩阵图像.
由图3可以看出,在这两个数据库上对比这4种算法的基图像稀疏度,NMF稀疏度最低,NMFOSL1的基图像最为稀疏,换言之,该算法具有最优的局部表达能力.
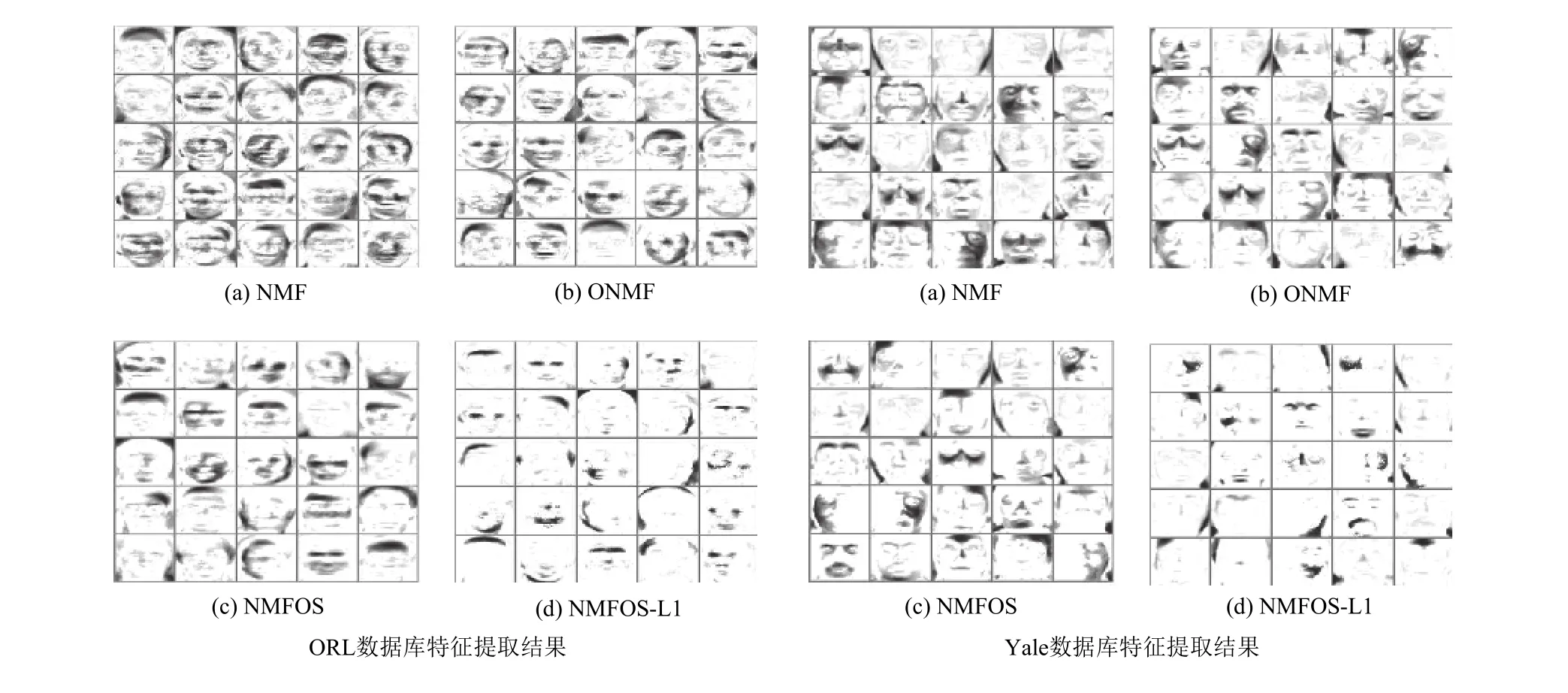
图3 ORL和Yale数据库不同算法人脸特征提取结果对比
Hoyer在文献[9]中给出了度量向量稀疏度的函数:
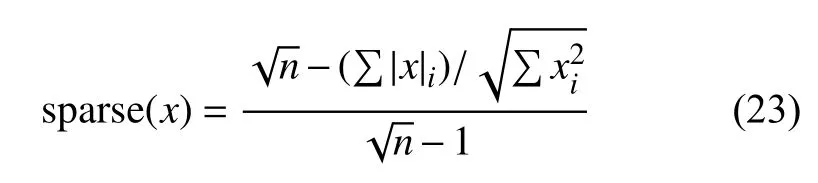
实验最后,我们对矩阵分解结果的稀疏性进行对比.从表3和表4中我们可以看到,本文算法所得的基矩阵和稀疏矩阵更加稀疏,本文算法的稀疏表达能力优于对比的几种算法.
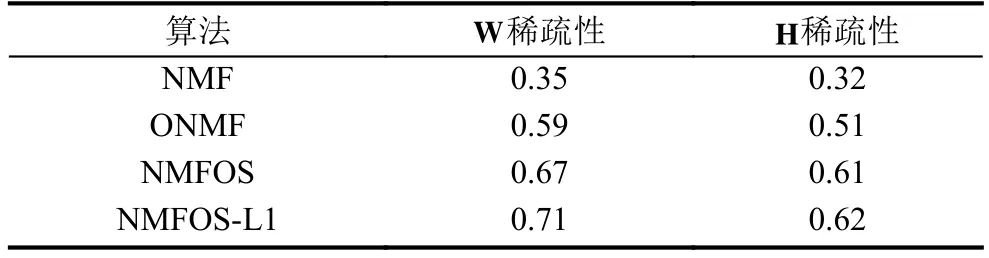
表3 ORL数据库上不同算法的稀疏性
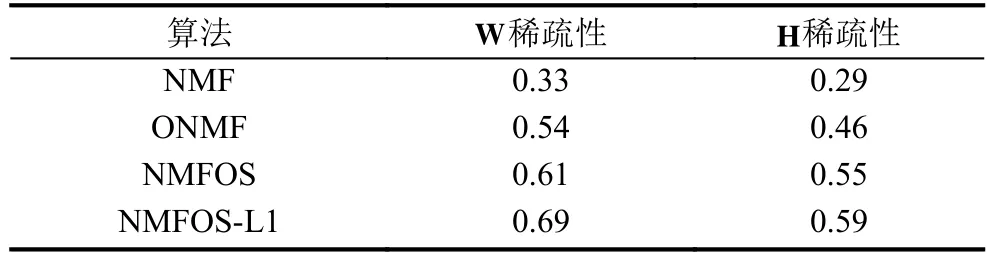
表4 Yale数据库上不同算法的稀疏性
6 结束语
针对正交子空间非负矩阵分解相对稀疏或局部化描述原数据时导致的稀疏能力和程度比较弱的问题,本文将稀疏约束引入正交子空间非负矩阵分解的目标函数中,提出稀疏约束正交子空间非负矩阵分解.同时给出了迭代公式.实验证明该算法具有更好的聚类效果以及稀疏表达能力,在人脸特征提取领域具有应用潜力.进一步提升正交子空间非负矩阵分解算法效率,以及将本文方法推广应用到计算机视觉中都是我们进一步要研究的内容.
猜你喜欢
波谱学杂志(2022年1期)2022-03-15
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
动漫星空(2018年9期)2018-10-26
中国校外教育(下旬)(2017年8期)2017-10-30
小学阅读指南·低年级版(2017年1期)2017-03-13
现代电子技术(2016年5期)2016-05-14
人生十六七(2015年6期)2015-02-28
奇闻怪事(2014年5期)2014-05-13
计算机辅助工程(2012年5期)2012-11-21
