
基于Docker Swarm集群的调度策略优化算法①
2018-09-17 08:49:38刘梅,高岑,田月,王嵩,刘璐
计算机系统应用 2018年9期
刘 梅,高 岑,田 月,王 嵩,刘 璐
1(中国科学院大学 计算机与控制学院,北京 100049)
2(中国科学院 沈阳计算技术研究所,沈阳 110168)
1 引言
Docker[1–3]是一个开源的引擎,提供一种轻量级虚拟化的解决方案.目前Docker已经获得操作系统Linux支持,同时越来越多的大企业如谷歌,微软,IBM 等开始青睐此项技术.2014 年 12 月,Docker公司发布了基于Go语言开发的原生态容器集群管理工具Swarm,主要用来对整个集群中的Docker镜像和容器进行管理,而且以一个虚拟整体的方式将整个集群呈现给用户,Swarm工具的发布促进了Docker在集群中的运用.
近年来,随着云计算的迅速发展,越来越多的公司利用Docker和Swarm工具在多个服务器上部署私有的PaaS(平台即服务)平台或IaaS(基础设施即服务)平台.Docker虚拟机与 KVM(Kernel-based Virtual Machine)一类的相比,最明显的优势是创建速度和启停速度更快,占用系统资源更少.原生Swarm调度策略是在合适的节点上启动并运行Docker容器,因此每个节点资源利用率的高低对整个集群的负载情况起决定性作用.目前Swarm内置三种调度策略Random,Spread和Binpack.Random策略是随机选择一个节点,一般用于开发测试阶段.Spread是优先选择权值小的节点(该节点占用资源如CPU,内存最少),以保证集群中所有节点资源的均匀使用.Binpack是优先选择权值大的节点(该节点占用资源如CPU,内存最多),以保证更多空余节点.Swarm在计算节点权值时可能会得到两个或多个相同权值的节点,而调度策略只是将这些相同权值的节点随机分配,并没有进行二次比较.即使这些节点的权值相同,但它们的CPU和内存使用情况也会不同.所以可能会造成以下情况:① 已使用较多CPU资源和较少内存资源的节点获得启动并运行容器的机会,而该容器需求较多的CPU资源和较少的内存资源;② 已使用较少CPU资源和较多内存资源的节点获得启动并运行容器的机会,而该容器需求较少的CPU资源和较多的内存资源.上述情况均会导致节点负载不平衡,从而造成整个集群负载[4–7]不均衡,降低集群的整体资源利用率.
针对上述问题,本文在Swarm集群调度策略的基础上,提出一种动态调度算法对Swarm调度[8–10]进行优化.通过实验证明,本算法能够使集群中节点负载更加均衡,同时提高集群的整体资源利用率.
2 Docker Swarm 集群
2.1 关于Docker
LXC(Linux Container)[11]容器技术是 Linux 系统中共享内核的操作系统级别的虚拟化技术,通过虚拟容器和宿主机共享内核来提升容器的启停速度,同时降低对内存等资源的消耗.而Docker是基于LXC容器技术的一种实现,一个Docker容器相当于一个虚拟机,既可以拥有特定的操作系统,也可以部署一个特定的应用,同时独立于所运行的操作系统.所以与传统的虚拟机相比,Docker省去了部署应用时环境配置,解决依赖等步骤,并且没有任何中间层资源开销,提升了资源利用率.
Docker采用了客户端-服务器(C/S)架构,架构如图 1 所示.其中,Docker client是客户端,Docker daemon是一个后台模块,用户通过Docker-Client发送请求,Docker daemon 对请求进行处理,实现对镜像和容器的使用和管理.Docker daemon模块主要包括Docker server和 Docker engine 两部分,Docker server接收并调度分发Docker client发送的用户请求,之后将具体的执行步骤交给 Docker engine,Docker engine将每一个具体的操作抽象为一个类似操作系统中进程的 job 操作.Docker registry 是 Docker的镜像存储服务端,主要用于管理镜像的上传与下载.Docker driver是驱动模块,负责对Docker容器执行环境进行定制.Libcontainer是Docker系统中使用Go语言实现的库,其设计目标是希望不依赖其他库文件,可以直接访问内核中与容器相关的API.
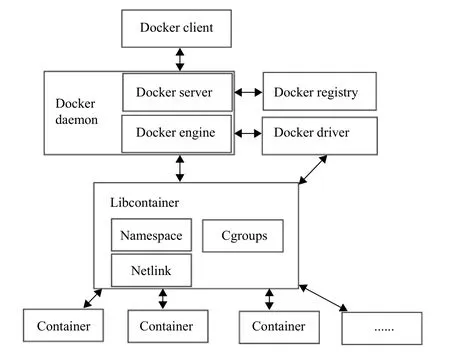
图1 Docker体系架构
2.2 Swarm集群架构
Docker公司在2014年12月初发布了Docker集群管理工具Swarm,用来统一管理由多个部署有Docker的物理机组成的集群中的镜像和容器.
Swarm 采用客户端-服务器(C/S)架构,架构如图2所示.

图2 Swarm 架构
图2 中,Docker API负责管理镜像的生命周期.Swarm Manage CLI负责对集群进行管理.LeaderShip提供集群高可用机制(High Avaliable),防止单点故障.Cluster API 定义了集群接口,主要用于对任务进行调度.Discovery service 是 Swarm 的发现服务,主要用于在每个节点上注册一个Agent时,将各个节点的IP端口上报,Manager将从 Discovery service 读取各节点信息.Scheduler是调度模块,负责在容器调度时选择最优节点,其主要分为两部分:Filter和 Strategy.Filter负责创建或运行容器时,告诉调度器哪些节点是可用的,它可以分为节点过滤和基于容器配置过滤,用户在创建集群时,需要根据节点功能分配给节点特定的标签,一旦启动容器,Filter会根据用户提供的标签,过滤出匹配标签的节点集合供Strategy处理.Strategy根据调度策略选择最优节点,Swarm内置的调度策略包括Random,Spread 和 Binpack 三种.其中 Random 策略是随机选择一个节点,一般用于开发测试阶段.Spread是优先选择权值小的节点(该节点占用资源如CPU,内存最少),以保证集群中所有节点资源的均匀使用.Binpack是优先选择权值大的节点(该节点占用资源如CPU,内存最多),以保证更多空余节点.
2.3 Swarm集群的调度策略及分析
目前 Swarm 内置的调度策略有三种,分别是Random(随机),Spread(扩散)和 Binpack(装箱),集群默认的调度策略是Spread.Random 调度是选择容器生成的节点位置是随机的,一般用于开发测试阶段.
Spread和Binpack调度首先根据申请容器的配置信息计算出CPU和内存利用率,将其结果求和得到节点权重,然后选择合适的节点运行容器.其中,Spread会优先选选择权值小的节点运行容器,而Binpack会优先选择权值大的节点运行容器.
Random策略的优点是实施简单,但经常容易导致节点CPU过载和内存不足.采用Spread策略,虽然能够减少因节点故障而损坏容器的数量,但是这种策略过多的占用了服务器资源(例如内存资源).而Binpack的优点是能将更多的容器运行在较少的节点上,但是会造成节点负载过重.
Swarm调度策略虽然简单有效,但是其在计算节点权值时可能会得到两个或多个相同权值的节点,而调度策略只是将这些相同权值的节点随机分配,并没有进行二次比较.即使这些节点的权值相同,但它们的CPU和内存使用情况也会不同.所以可能会造成以下情况:① 已使用较多CPU资源和较少内存资源的节点获得启动并运行容器的机会,而该容器需求较多的CPU资源和较少的内存资源;② 已使用较少CPU资源和较多内存资源的节点获得启动并运行容器的机会,而该容器需求较少的CPU资源和较多的内存资源.上述情况均会导致节点负载不平衡,从而造成整个集群负载不均衡,降低集群的整体资源利用率.
3 基于 Docker Swarm 集群的动态调度策略
3.1 Swarm集群的动态调度策略
根据上述问题,本文提出了一种动态调度策略对Swarm调度策略进行优化.通过动态收集节点信息,实现对下一时刻节点资源使用情况的预测,利用预测信息,对权值相同的节点再次计算其权值,进而再次排序,优先选取权值小的节点启动和运行容器,完成调度.具体实现过程如下:
首先,在每个节点上添加一个监控模块实时监控节点资源(CPU和内存资源)的利用率,输出为当前节点的CPU利用率和内存利用率.其次,在集群中添加一个信息收集模块,用来收集在一段时间内监控模块传递过来的节点信息,通过这些信息,预测出下一时刻节点的资源使用情况.最后,Scheduler模块调用收集模块,获取预测的节点信息,其中,Scheduler首先计算出节点CPU和内存利用率的的权值,进行排序,若存在相同权值的节点,Scheduler会根据这些节点的预测信息进行第二次权值计算,根据计算结果,对它们进行第二次排序,从而选择权值小的节点启动和运行容器,完成调度功能.
3.2 Swarm集群的动态调度算法的设计与实现
基于上述提出的动态调度策略,本文提出动态调度的算法.信息收集模块在获取最近时间段的节点资源使用信息后,利用该算法,实现对当前节点下一时刻CPU和内存使用情况的预测.
(1)预测模型的选取
对Swarm集群中节点资源信息进行预测,在选取预测算法时,应考虑以下三点:第一,预测模型能够在一定误差内,真实的反映出节点的CPU和内存资源使用情况;第二,对节点资源信息的预测都是实时预测,所以应该保证算法具有较小的时间复杂度;第三,在预测时仅需要对最近时间段产生的若干个样本进行拟合.鉴于上述考虑,本文采用一元线性回归[12,13]模型对节点信息进行预测.
在统计学中,一元线性回归模型预测是回归分析与预测理论相结合的一种定量分析预测方法,通过对预测对象和影响因素统计与分析,找出它们之间的线性变化规律,将变化规律用数学模型表达出来,并利用数学模型进行预测.其主要的优点包括实用性强,预测结果精确和使用方法简便.
(2)基于线性回归模型的节点负载预测
修改后的Swarm集群中的监控模块实时监控节点资源信息,基于原生的Swarm调度策略只计算了CPU和内存两个维度的资源,所以监控模块监控的节点信息包含CPU利用率和内存利用率,假定节点的CPU利用率为C,内存利用率为M.首先,模块获取前tn时 刻C=(<t1,c1>,<t2,c2>,<t3,c3>,···,<tn,cn>),M=(<t1,m1>,<t2,m2>,<t3,m3>,···,<tn,mn>).
其次,信息收集模块调用监控模块,获取这些样本值,采用一元线性回归分析方法进行模拟,建立数学模型.最后,利用数学模型对tn+1时刻的cn+1和mn+1进行预测.具体实现过程如下:
步骤一.设在ti时刻监控对象的取值为ri,时间序列T=<t1,t2,t3,···,tn>对应的监控对象取值为R=<r1,r2,r3,···,rn>.假定存在r关于t的一次函数:

其中,a与b为不依赖t的常量.
每一个真实值与其预测值的随机误差 ε之间相互独立,且服从同一分布,则:
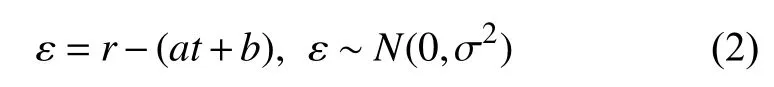
得出一元线性回归模型为:
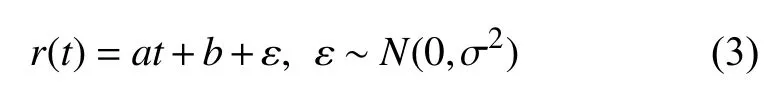
步骤二.未知参数a,b的确立.由每个样本r和监控值的随机误差 ε之间相互独立可得出样本中r的联合密度函数为:
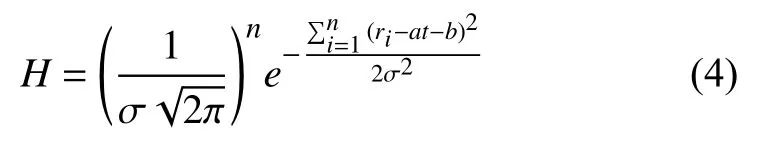
设置H求最大值,则得a与b的极大似然估计的值为:

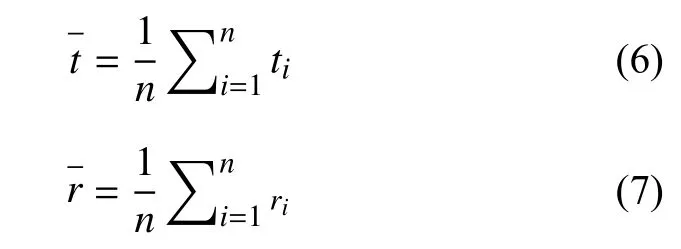
得出r关于时间t的经验回归方程:

步骤三.将进行预测的时间tn+1代入式(8),得到预测值:
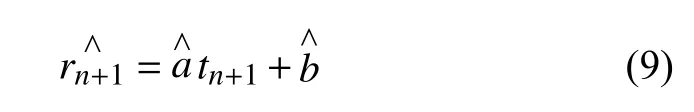
步骤四.精度检测.根据式(10)计算整个样本中监控对象的真实值和估测值之间的残差平方和.

推导得出L/σ2~ χ2(n−2),则整个样本的 σ2无偏估计量满足如下关系:
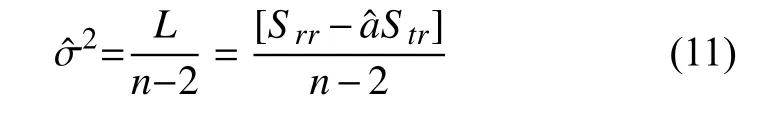
其中,Srr与Str满足:

(3)动态调度算法的运行过程
第一步,分别获取当前节点的CPU利用率和内存利用率的时间序列T及其相对应的样本观测值R.
第二步,将T和R分别代入式(6),式(7),得到和,再根据H(式(4)),求出和,确立经验回归方程.
第四步,根据式(11)对预测模型进行精度检测,评估预测模型是否符合要求,若不符合要求,缩小样本集,返回第二步.
第五步,对节点的CPU和内存的预测值进行权值计算.计算权值的方法采用Swarm内置的.
4 实验结果与分析
本文是基于Linux操作系统进行实验的.自Docker 1.12版本及该版本之后,Swarm集成进了Docker Engine.本文选取的Docker版本为Swarm17.03.0-ce.搭建了 4 个 Swarm 集群,集群 1,2,3 采用原生的Swarm搭建,其中集群1的调度策略为Random,集群2的调度策略为Spread,集群3的调度策略为Binpack;集群4采用改进后的Swarm搭建.对集群进行部署,每个集群配置三个节点,将运行容器的内存上限设置为 100 MB,1 GB,1 核的节点大约消耗 10% 的 CPU.集群 1,2,3,4 中各节点的性能为:节点 1 为 3 GB,4 核;节点 2 为 2 GB,2 核;节点 3 为 1 GB,1 核.
初始化集群中每个节点的资源利用状态,设置节点整体的资源使用率为S,内存使用率为M,CPU使用率为C,则它们之间存在的的关系为:S=M+C;每个节点资源的初始化状态如表1所示.

表1 节点资源的初始状态(单位:%)
本实验通过模拟,设定集群 1,集群 2,集群 3,集群4中的节点1都是满负载,剩余节点都为初始化状态,然后分别创建等数量容器40个.每个集群中的的各节点资源利用情况分别如表2,表3所示.

表2 集群 1 和集群 2 中各节点资源利用情况(单位:%)
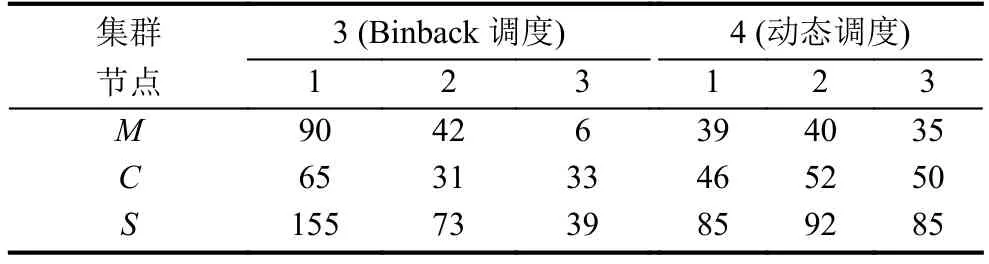
表3 集群 3 和集群 4 中各节点资源利用情况(单位:%)
由表1和表2可以看出,Swarm内置的三种调度策略对每个节点的资源利用较不平衡.将表1和表2中每个集群中的节点负载情况绘制成图3所示.由图3的结果表明,集群1,集群2和集群3分别利用Random策略,Spread策略和Binpack策略完成调度时,集群中的各个节点的负载相差较大,每一个节点的资源利用情况很不均衡.而集群4中增加一个动态调度算法后,集群中每个节点的负载较为平衡,这样就能够充分发挥每一个节点的性能,进而提高集群的整体资源利用率,同时,集群整体的负载也更加均衡.
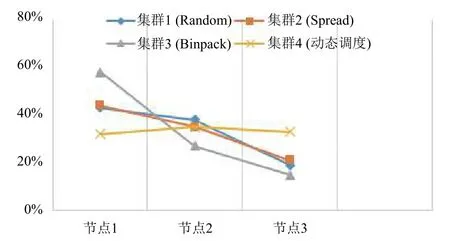
图3 集群负载均衡对比图
5 结语
本文分析了Swarm集群框架及其内置的调度策略,针对其调度策略在解决相同权值节点随机获取容器将会造成节点负载不均的问题,提出一种动态调度算法来均衡集群的负载.实验表明,增加动态调度算法能够使集群中节点负载更加均衡,同时提高集群的整体资源利用率.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
当代陕西(2019年13期)2019-08-20 03:54:22
中国化肥信息(2019年6期)2019-01-19 13:10:42
经济技术协作信息(2018年5期)2019-01-19 08:39:16
消费导刊(2017年24期)2018-01-31 01:29:29
自动化学报(2017年7期)2017-04-18 13:41:02
印制电路信息(2015年6期)2015-12-30 12:57:48
测绘科学与工程(2014年5期)2014-02-27 07:06:14
电脑爱好者(2009年13期)2009-07-07 09:52:52
