
一种动态权值自适应粒子群优化典型函数问题
2018-09-14 12:02毛剑琳
电子科技 2018年9期
杨 巍,毛剑琳,熊 晔
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
粒子群优化(Particle Swarm Optimization,PSO)算法源于鸟群捕食行为的模拟,最早于1995年由Eberhart和Kennedy提出,该算法是典型的群体智能优化算法[1-2],具有设置参数较少,关联度较低,操作灵活简单等优点。目前主要应用在函数优化问题[3],结合模糊系统控制,神经网络控制在工程领域上已被广泛应用[4-6]。但传统粒子群算法本身也存在缺陷,当变量维数较多时,目标函数中存在较多局部极值时,PSO算法容易出现提前收敛或陷入局部极值,进化后期收敛速度慢、精度低、易早熟等问题。目前解决办法主要集中在两个方面:一是算法优化改进;二是算法研究上。因此,出现了粒子群诸多改进办法[7-12]。改进过程中通常结合其他算法,往往增加PSO算法的复杂性,并未对算法进行实质性的改变。在传统PSO算法的迭代过程中主要是对速度更新和位置进行更新。方程涉及惯性环节、个体认知环节和群体认知环节。三个环节共同决定粒子群更新方向,使粒子朝着更好的方向运动。个体认知环节决定个体最优位置,群体认知环节决定群体最优位置,并且与当前位置都存有向量差。由于这两个差的存在,使粒子迭代过程中逐渐趋向群体最优解方向。惯性权值体现的是微粒子继承上一时刻速度的大小程度。Shi.Y是最早将惯性权值的理念引入到PSO算法中。分析并指出,更新早期较大的惯性权值,使算法具有很强全局搜索能力,而更新后期较小的惯性权值使算法具有很强局部搜索能力,惯性权值的动态变化思想是在此基础上提出的。本文在动态惯性权值的基础上,引入动态学习因子与迭代次数相结合的方法,使微粒子具有较强的探索能力,避免出现陷入局部最优的情况。并通过典型函数仿真验证,在迭代过程中动态改变惯性权值及学习因子幅值,使其能够摆脱局部极值的干扰,加快算法收敛速度,同时也提高了搜索的精度与准确度。
1 基本粒子群算法
传统PSO算法是依据个体(微粒子)的函数值或适应值进行操作的。每个微粒子根据自己及同伴的经验值共同作用,对速度和位置进行迭代更新,最终在群体空间中搜索出目标最优值。粒子可以用N维向量表示,设N维空间中有m个微粒,粒子i的位置Xi为{xi1,xi2,xi3,…,xiN},速度Vi为{vi1,vi2,vi3,…,viN},式中i为(1,2,3…,m),Xi表示i粒子的当前位置,Vi为微粒i的当前速度。每一次的更新过程当中,粒子自身找到的最优值,叫做个体极值(用Pbest表示其位置);整个种群当前找到的群体最优值,叫做全体极值(用Gbest表示其位置)。当前粒子通过跟随个体极值与全体极值来更新自身的位置。粒子在每次更新过程当中,根据以下两个公式来重新确定自身的速度和自身的位置。速度和位置更新公式为
(1)
式中,i∈(1,2,3,…,m);j∈(1,2,3,…,N);c1,c2学习因子,非负数;r∈(0,1)之间的随机数w为惯性权值,k为迭代次数。
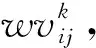
2 动态自适应粒子群算法
与其他算法进行比较,传统PSO算法,具有较短的收敛时间和较好的收敛性能,但是优化过程中存在提前收敛早熟等现象。在寻优过程中,容易由于种群多样性(维度)丧失而使种群在局部收敛。因此,本文引入动态惯性权值[13],加快进化速度的同时,加大其全局搜索能力。引入动态社会因子与动态认知因子增加局部搜索的准确性,并提高搜索精度。试验证明,动态w能获得比静态的权值更好的寻优效果。SHI提出的递减权值法(Linearly Decreasing Weight,LDW)如式(2)所示,目前已被广泛引用[14]
w(k)=wstart-k(wstart-wend)/Tmax
(2)
其中,wstar为初始惯性权重值,wend为最大迭代次数时的惯性权重值;K为当前迭代次数;Tmax为最大迭次数。一般来说,wstar=0.9,wend=0.4时寻优性能较好。这样,更新过程中,权值由0.9线性减至0.4。LDW方法为一种经验取法,常见的动态权值还包括以下几种
(3)
(4)
(5)
几种w动态曲线如图1所示。
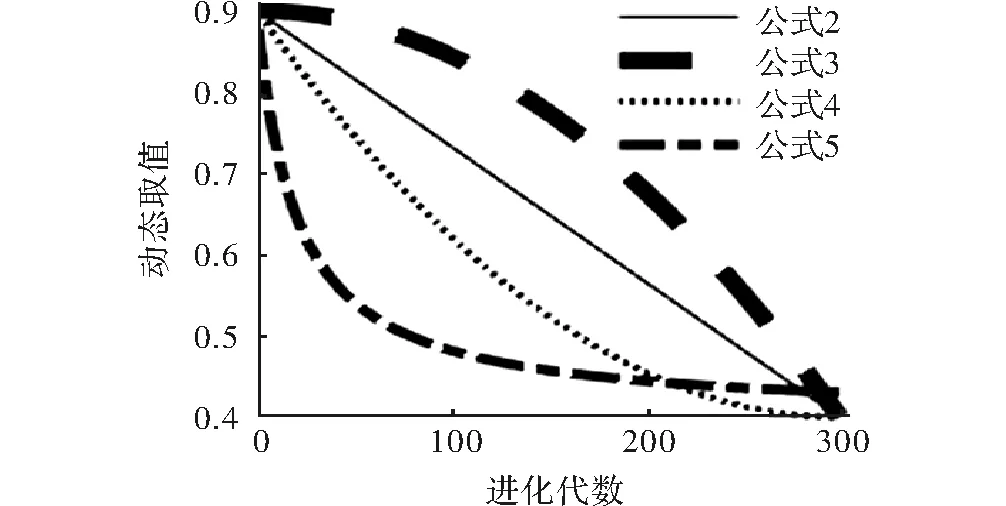
图1 几种常见动态权值曲线
为了验证w动态变化性能,采取4种w取值方法并进行比较。粒子群规模为50,迭代100次。运行20次,比较其平局值,失效次数,在精度和速度上进行分析。实验证明,动态权值采用式(3)具有更好的搜索性能,静态惯性权值w恒定不变的传统算法虽然具有较快的全局搜索速度,但后期容易陷入局部最优,求解准确度较低。式(3)中的w动态变化方法,前期w取值较大变化较慢,有利于算法进行全局搜索;后期w取值较小变化较快,有利于算法跳出局部搜索而求得全局最优值。提高了算法的求解精度,避免陷入局部陷阱。提高了算法的全局寻优能力,取得较好的全局最优解。
为了提高搜索的准确性,个体认知环节c1采纳线性递减的方法如式(6)所示,社会认知环节c2采纳线性递增的方发如式(7)所示。动态学习因子基本思想如图2所示。
c1=c1max+(c1min-c1max)(Tmax-k)/Tmax
(6)
c2=c2min+k(c2max-c2min)Tmax
(7)
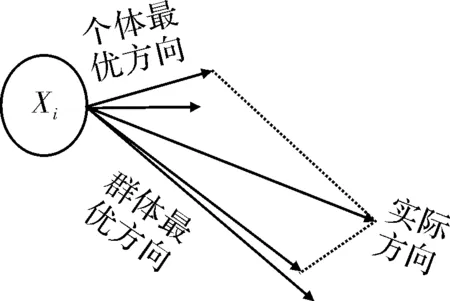
图2 动态学习因子示意图
粒子群更新前期,较大的个体认知环节有利于粒子群寻找个体最优值,更新前期以个体认知为主;更新后期,较小的个体认知部分有利于趋近群体最优方向。同样,更新前期,较小的社会认知部分有利于寻找个体最优值;更新后期以社会认知为主;较大的社会认知部分,有利于粒子趋于全体最优值算法流程如下
步骤1初始化粒子群,随机更新粒子位置与速度,设置种群数量,迭代次数;
步骤2计算粒子的适应度或函数值,确定个体最优位置Pbest和群体最优位置Gbest;
步骤3更新每个微粒子的位置和速度;
步骤4更新个体最优值与群体最优值;
步骤5迭代次数k加1,更新w,c1,c2;
步骤6如果k大于最大迭代次数,则去执行步骤7,否则返回到步骤3;
步骤7最终Gbest为所得到的最优参数。
3 实验仿真及分析
3.1 经典函数
本文采用经典的Rastrigin(Ras)函数和Schaffer函数对所提出的动态惯性权值自适应粒子群算法进行仿真测试,具体信息如下。
(1)Ras函数。Rastrigin函数为非线性对称函数,这个函数对模拟退火、蜂群算法等算法具有很强的干扰和欺骗性。它具有较多的局部最小值点和局部最大值点,寻优过程中容易陷入局部陷阱,提前收敛。这里采用改进的粒子群优化算法对其求解最大值,该函数的数学公式如下
f(x)=20+x2+y2-10(cos2πx+cos2πy)
(8)
Ras函数的三维表示如图3所示。
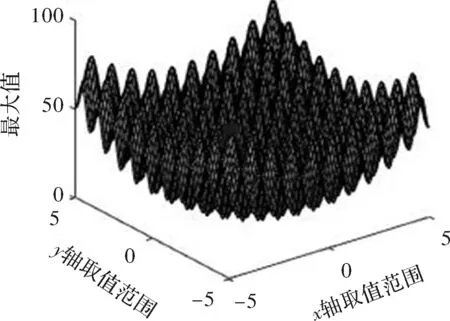
图3 Ras函数三维图
(2)Schaffer函数。Schaffer函数同Ras函数一样很难找到最优解,原因是全局极值的周围被很多局部极值所围绕,该函数公式如下
(9)
Schaffer函数的三维表示如图4所示。

图4 Schaffer函数的三维图
3.2 参数设置
为了验证改进的动态PSO算法的准确性和有效性,本文采用了经典的多峰Ras函数和Schaffer函数来测试算法的寻优性能,并与模拟退火算法进行比较,算法中粒子群规模为100,最大迭代次数300代,v∈[1,-1],c1∈[1,2.5],c2∈[1,2.5]。函数在[-5,5]范围内取最大值,实验结果表明,改进的动态惯性权值自适应粒子群算法具有很强的全局及局部搜索能力,精确度高、响应速度快。下面实验均进行20次,取最优作为实验的结果。
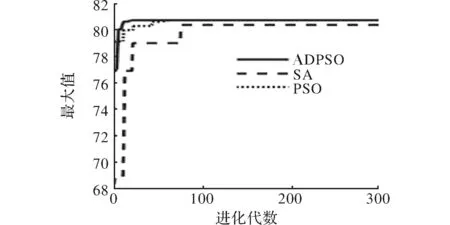
图5 Ras函数最大值
与传统粒子群算法和模拟退火算法相比,改进的PSO算法收敛速度更快,准确度更高。Ras函数大约迭代32代,Schaffer函数大约迭代30次可达到收敛,找到最大值,精度更高,寻优效果大幅增强。
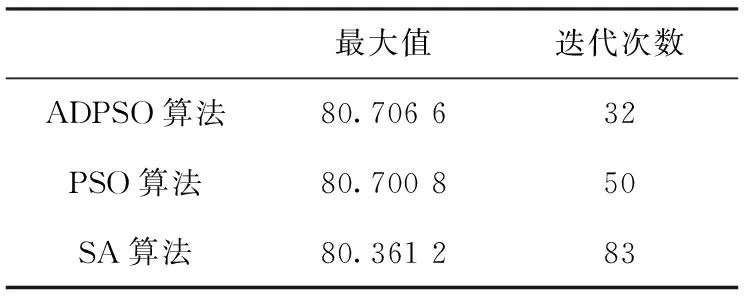
表1 Ras函数寻优
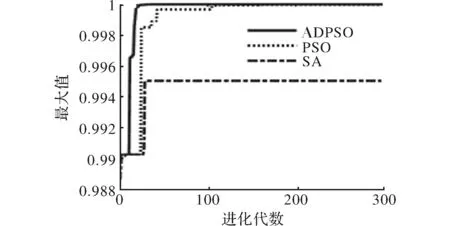
图6 Schaffer函数最大值
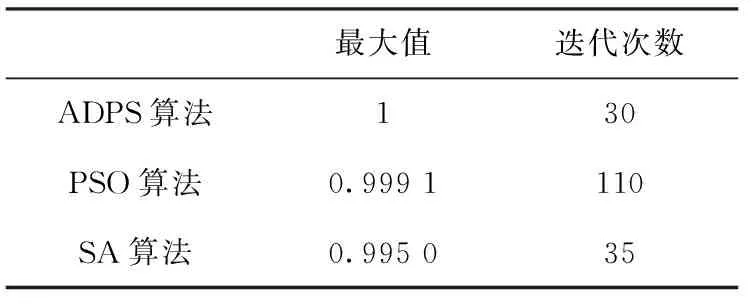
最大值迭代次数ADPS算法130PSO算法0.999 1110SA算法0.995 035
实验结果表明,本文提出动态惯性权值自适应粒子群算法(ADPSO)与传统PSO算法,模拟退火算法[15]进行比较。为了更好、更直观地反应寻优效果,图5和图6给出了3种算法在仿真过程中最优目标函数值变化曲线。改进的PSO算法采用动态变化的w能够较精确地控制搜索速度,使每次搜索的速度跟随迭代的次数进行变化,摆脱了传统PSO中搜索速度更新的盲目性。测试结果表明,改进的PSO算法能在不同程度上加快收敛速度提高搜索精度,同时有利于函数脱局部最优值,使函数最终收索到全局最优值。
4 结束语
本文提出的一种改进的动态权值自适应PSO 算法,该算法主要针对惯性因子、认知因子和社会因子的改进,改进的控制算法在寻优过程中全局开发与局部开发进行了合理搭配,在更新的初期阶段w算子的作用较大,有利于发现目标区域。随着迭代次数的增加,w和c1作用幅值逐渐减小,c2幅值逐渐增大,有利于在最优值附近进行局部开发,体现了全局探索与局部搜索搭配的合理性,典型函数目标优化的实验结果证明改进方法的优越性。从仿真结果可以看出,改进后的PSO在收敛速度上和搜索精度上,均高于传统粒子群算法与模拟退化算法。通过动态自适应调整种群使群体搜索时不断取向目标值,仿真结果表明,改进动态权值粒子群算法是有效、可行的。
猜你喜欢
中学生数理化·八年级物理人教版(2023年3期)2023-03-21
数学物理学报(2022年4期)2022-08-22
成都信息工程大学学报(2022年3期)2022-07-21
数学物理学报(2022年2期)2022-04-26
中学生数理化·八年级物理人教版(2022年3期)2022-03-16
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
金桥(2018年4期)2018-09-26
中学生数理化·八年级物理人教版(2017年3期)2017-11-09
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
