
深度学习在雷达中的研究综述
2018-09-14 10:44魏少明
雷达学报 2018年4期
王 俊 郑 彤 雷 鹏 魏少明
(北京航空航天大学电子信息工程学院 北京 100191)
1 引言
雷达是一种通过电磁波探测物体的电子设备。其主要包括:发射机、发射天线、接收机、接收天线以及信号处理部分。发射机通过发射天线,将电磁波向外发射,在某方向上与物体发生碰撞,电磁波发生反射,反射回波则被接收天线和接收设备接收,传至信号处理部分进行分析。该过程能够有效提取物体距雷达的距离、物体径向运动速度等信息。并且这些信息能够满足许多应用场景的需求。例如,在军事方面,其根据雷达所实现的功能不同,可分为预警雷达[1–3]、搜索警戒雷达[4–6]、导航雷达[7–9]以及防撞和敌我识别雷达等等。在社会科学发展方面,雷达可应用于气象预报[10–12]、资源探测[13–15]、环境监测[16–18]等。鉴于雷达的广泛应用场景,对雷达信号处理的研究就显得至关重要。
近些年,深度学习成为各个领域的研究热点,且在雷达领域同样如此。本文主要介绍通过深度学习方法对不同形式雷达数据进行处理的研究情况,整体框架如图1所示。经过调研发现,针对不同雷达成像原理以及信号处理方法,可获得不同形式的雷达数据。例如,合成孔径雷达(Synthetic Aperture Radar, SAR)图像[19–24]、高分辨距离像(High Range Resolution Profiles, HRRP)[25–28]、微多普勒(Micro-Doppler)谱图[29–32]以及距离多普勒(Range-Doppler, R-D)[33–36]谱图等。本文则主要针对上述可获取的雷达数据进行深度学习方法处理。其中,深度学习在SAR图像处理领域已得到广泛应用,典型应用的网络包括卷积神经网络(Convolutional Neural Network, CNN)[37]、稀疏自编码器(Sparse AutoEncoder, SAE)[38]以及深度置信网络(Deep Belief Network, DBN)[39]等等。其中,由于CNN在图像处理中具有明显优势,因此,基于CNN的SAR图像处理应用最为广泛。本文同时介绍了通过上述3类网络以及其他深度学习方法对HRRP, Micro-Doppler特征, R-D谱图等雷达数据进行处理的研究近况。
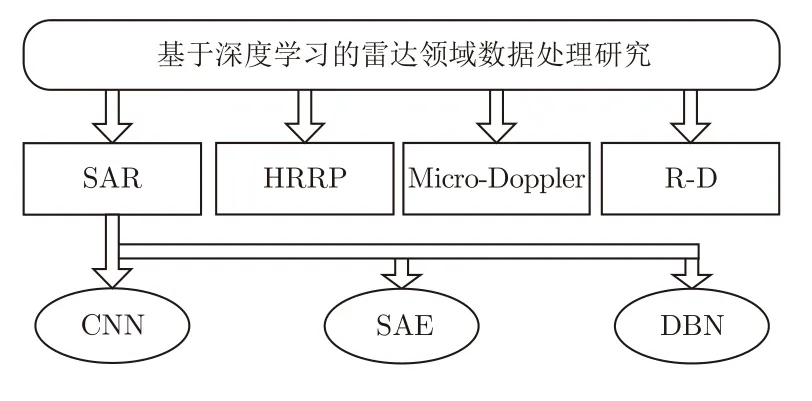
图1 本文介绍流程Fig.1 Flow chart of this paper
2 典型深度学习网络基本原理
2.1 CNN基本原理
20世纪60年代,Hubel和Wiese研究猫脑皮层发现用于局部敏感和方向选择的神经元具有独特的网络结构,该结构可以降低反馈神经网络的复杂性,针对此研究提出了CNN。近些年,针对CNN具有避免图像的复杂前期预处理的优势,该网络被广泛应用于图像的模式分类领域。其基本架构如图2所示,经典的CNN一般包括卷积层、池化层、全连接层和分类器。

图2 CNN结构示意图Fig.2 Typical CNN structure
在卷积层中,其目的是对图像进行特征提取。即通过对上一层输出的特征图进行卷积,并在加入偏置后通过一个激活函数激活,得到当前层的输出特征图,即得到当前层对应特征情况,如式(1)所示:

其中,x表示特征图,Mj表示输入特征图的集合,k为卷积核,b为偏置,l是层序号,i是卷积核序号,j是特征图通道序号。对于池化层而言,该层设置的目的是对图像进行下采样处理,而经典的池化方法包括:最大池化、均值池化等。在全连接层中可将上一层得到的特征图进行按顺序排列,得到1维向量,对其进行典型神经网络连接。最后,对于不同神经元的输出进行分类器分类,一般采用softmax或支持向量机(Support Vector Machine,SVM)分类器,得到分类标签。
在学习过程中,其主要针对网络中的卷积核、偏置情况进行学习,即需要通过反向迭代更新网络参数,进而使网络获得稳定的识别效果,网络训练结束。其中,反向迭代更新过程是通过对训练误差进行随机梯度下降处理。在典型的CNN中,训练误差由式(2)表示:

2.2 SAE基本原理
自编码器(AutoEncoder, AE)是一种尽可能复现输入信号的神经网络,可以代表输入数据的最重要的因素,并且其类似主成分分析方法,能够代表原信息的主要成分。其结构如图3所示。在AE的基础上加上L1正则化限制,就可以得到一个SAE。该限制使每次的编码表达尽量稀疏,更为有效。
AE尝试学习一个尽量满足hw,b(x)≈x条件的网络。即当网络输出接近于输入时,说明隐层神经元可以表示为输入元素的特征。在讨论SAE的代价函数表示时,首先需要引入激活度的概念。用表示给定输入为x的情况下,AE的隐层神经元j的激活度,则将隐层神经元j的平均激活度记为:

图3 AE结构示意图Fig.3 Typical AE structure
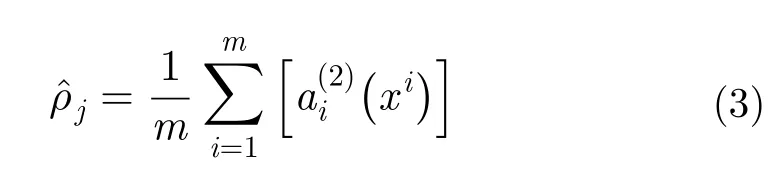
其中,m为 神经元个数。SAE是在AE的基础上加入稀疏性限制,而该限制的目的是使隐藏神经元的平均激活度特别小。为了满足该条件,需要在原始神经网络约束条件下加入稀疏性限制这一项,作为额外的惩罚因子,也称为相对熵,如式(4)所示:
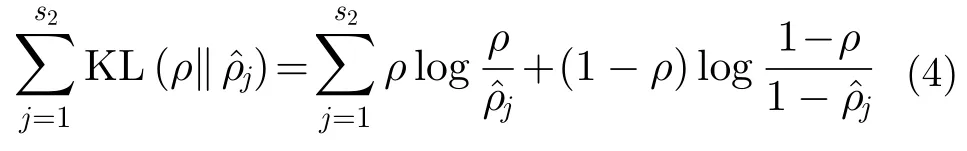
其中,s2是 隐层神经元数量,ρ是稀疏性参数。可以发现,当满足条件时相对熵获得最小值。
SAE的总体代价函数可表示为:

其中,J(w,b)为对应自编码器代价函数,为控制系数性惩罚因子权重。
2.3 DBN基本原理
DBN是一个概率生成模型,其建立一个观测数据与标签之间的联合分布。并且DBN由多个受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)组成,典型的DBN结构如图4所示。该网络由隐层和可视层组成,且层间存在连接,层内单元不存在连接。
在典型的RBM中,其能量可表示为:

其中,b,c,w分别为对应可视层、隐层和可视层与隐层之间连接的权重,Nv为 可视层节点数,为隐层节点数,v为可视层输出,h为隐层输出。则进一步表示出隐层神经元hj被激活的概率为:

图4 DBN结构示意图Fig.4 Typical DBN structure
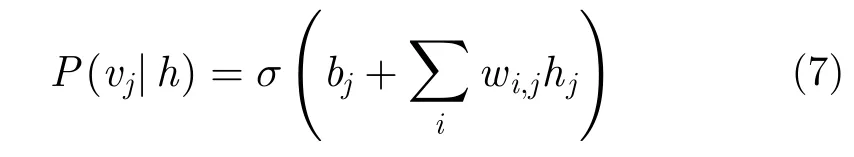
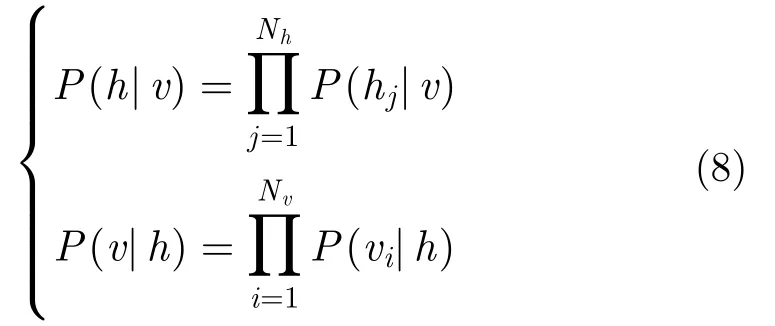
在训练过程中,当一条数据赋给可视层时,计算出每个隐层的开启概率,P(hj|x),j=1,2,···,Nh,进而比较其与阈值关系,大于阈值则激活,否则不激活。实现通过隐层计算出了可视层,之后通过对比散度算法对网络参数进行学习。具体地,首先,将x赋给可视v1, 得到隐层的激活概率为P(h1|v1),在该概率密度函数中采取Gibbs抽样抽取一个样本h1~P(h1|v1);之后,通过h1重 构可视层,计算可视层中每个神经元被激活的概率P(v2|h1),同样,从计算得到的概率分布中采取Gibbs抽样抽取一个样本v2~P(v2|h1);最后,通过v2计 算隐层中每个神经元被激活的概率h2~P(h2|v2),以此类推。权值更新为:

若干次训练后,隐层不仅能准确地表示可视层特征,而且还能还原可视层。
3 基于深度学习的SAR图像处理研究
通过上一节的介绍,可对典型的CNN, SAE,DBN算法基本处理过程具备一定了解。在此基础上,对雷达数据进行相应的处理成为该领域的研究热点。通过上述深度学习算法完成相应的雷达数据处理任务,并与传统方法进行对比。进一步验证了深度学习方法在进行自适应特征提取中存在的显著优势。
在雷达领域中,SAR是一种兼具距离向和方位向高分辨能力的成像雷达。其一方面作匀速直线运行,一面以一定的脉冲重复频率发射并接收信号。在距离向方面,它利用发射大时间带宽积的线性调频信号,采用脉冲压缩技术来获取高分辨率;在方位向,它利用目标和雷达相对运动形成的轨迹构成一个合成孔径,以取代庞大的阵列实孔径,获得方位向高分辨率。此外,SAR成像技术相对于光学遥感技术,主要具有以下优点:SAR利用地表反射的主动式电磁波成像,不需要传统光学成像的发光源,能够实现全天时、全天候的对地观测;当雷达波长选择恰当时,SAR能够穿透云雾、植被等覆盖物,观测到被隐藏的地物;SAR可以是多极化、多频段的,使图像具有丰富的相位等极化信息,有助于SAR图像的地物分类。鉴于SAR的众多优点,其在军事和民用领域得到广泛应用。
近些年,随着深度学习的研究热度逐渐增加,将深度学习方法运用到SAR图像处理成为新的研究热点。本节主要介绍深度学习算法在SAR图像处理中的研究情况。在该领域中,上一节主要介绍的CNN, DBN及SAE均在该领域均取得一定的研究成果。
3.1 基于CNN的SAR图像处理研究
基于CNN的SAR图像处理最广泛的应用主要集中在目标识别中,且典型的算法验证数据库为MSTAR数据,通过对该数据进行识别处理,从而对比不同方法的识别效果。该数据库包含10类目标,其示意图如图5所示。通过调研发现,基于CNN对SAR图像进行目标类型识别基本保证获得相比于传统目标识别方法更高的识别率。例如,南京理工大学的袁秋壮等人将CNN应用于SAR目标识别[40],该CNN网络包括2层卷积层,2层下采样层,3层dropout,2层全连接层。最终对MSTAR数据进行分类,平均识别率达到96.29%。此外,文献[41]选择对舰船数据进行训练及测试,其对4个场景下的SAR数据进行包含2层卷积层、2层全连接层的CNN训练,保证该网络对4个场景舰船SAR图像均具有稳定的识别能力,进而对一个场景下舰船进行识别测试。结果显示,该网络能从非货船目标和海杂波中提取货船目标。在上述文献中,由于缺少在不同舰船姿态情况下的舰船数据,因此训练得到的CNN对不同舰船姿态SAR图像适应性较差,导致对于不同姿态的舰船识别率还有待提高。为了解决该问题,需要通过对训练数据进行完善,增加不同舰船姿态SAR图像情况。
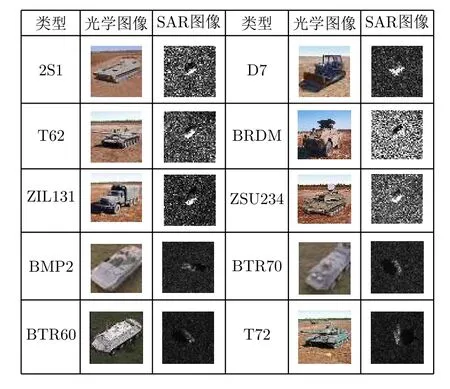
图5 MSTAR数据示意图Fig.5 Illustration of MSTAR data
为了解决训练数据量不足的问题,有学者提出通过一系列处理提升用于测试和训练的SAR质量,使训练图像能够尽量完备地代表实际待分类的图像情况。例如,西安电子科技大学的陈波团队[42]对MSATAR图像分别进行了目标位置的平移,加入随机斑点噪声的操作,之后再进行识别测试。在原始数据、目标位置平移、加入斑点噪声3种情况下,通过CNN得到的识别率与传统SVM等方法进行比较。CNN方法识别率分别为93.16%,82.40%以及91.89%。而传统SVM方法下,识别率仅为75.68%,17.05%以及70.58%。其中,由于对目标位置进行了平移变换,传统SVM方法识别率下降剧烈,而CNN方法识别率相对于原始数据,识别率仅下降10%左右,即说明CNN方法相对传统方法具有更优的鲁棒性。哈尔滨工业大学的朱同宇[43]在经典CNN模型基础上引入ReLU激活函数、L2正则化、批量归一化以及Dropout等现代深度学习技术,并使用目标镜像、目标位移、目标旋转以及加入噪声这4种SAR图像的数据增强方法,有效地抑制了过拟合问题。此外,其分别通过MSTAR实测数据集和OKTAL仿真数据集数据进行网络性能测试。其中,在运用MSTAR数据,且在原始测试集识别率达到98.22%的情况下,经过4种扩充测试集,保证准确率仍在90%以上。同样在对OKTAL仿真数据集进行测试时,平均识别率达到94.51%。可见,对于CNN方法而言,在一定程度下鲁棒性优于传统识别方法,且当训练样本与测试样本更加接近时,所训练网络特征提取越准确,识别率优势明显。此外,文献[44]提出通过两级CNN识别虚假目标。第1级CNN输入数据为原始SAR图像,且包含4类目标,每类分别由真实和虚假目标组成;第2级CNN输入数据为对阴影进行增强的处理后图像,每类目标的真实和虚假目标分别为两类,即完成8类目标的识别。文献[45,46]均对包含光学图像和SAR图像两模态数据进行CNN目标识别。其中,文献[45]通过对云的光学图像、SAR图像进行CNN分类,获得天气情况。文献[46]对两模态数据分别进行不同通道的CNN特征提取,之后将获取的两通道特征图进行全连接处理,进行分类器分类,即实现多模态数据分类识别。文献[47]通过CNN对TerraSAR-X高分辨图像进行分类,实现货船、游轮、直升机、平台以及港口的分类。在分类前,对感兴趣区域需进行检测预处理。
另外,极化SAR数据相比于单通道SAR,更能体现雷达的入射角、SAR图像噪声等信息,因此,应用场景更加广泛。文献[48–52]则对于极化SAR数据进行CNN处理,实现识别效果。其中,文献[48]通过对双极化SAR数据进行3D-CNN处理,实现对海水浓度进行判断,从而对由于冰川造成航船行驶的危害进行预警。文献[49]通过对多通道SAR数据进行6维实向量提取,然后对该6维实向量进行CNN分类。其中,对于极化SAR而言,其可表示为3×3的相干复矩阵:
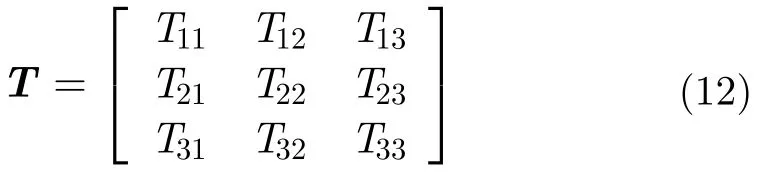
其中,对应的6维实向量分别为:

其中,A为 所有极化通道的总散射功率,SPAN=T11+T22+T33,B和C分别为T22和T33的归一化功率比,D,E和F分别为相关系数。对于该6维实向量进行包含2层卷积层,2层最大池化层,1层全连接层和softmax分类器的CNN架构建立。并且分别对典型的San Francisco和Flevoland多极化SAR数据库中的数据进行分类处理,San Francisco数据在训练和识别部分分别获得的识别率为99.43%和90.23%,Flevoland数据的训练和识别准确率分别为99.20%和97.66%。此外,复旦大学的徐丰、王海鹏、金亚秋提出对极化SAR数据进行复数CNN(Complex Value-CNN, CV-CNN)识别,文献[50]对同样的Flevoland数据进行包含2层卷积层,1层池化层以及1层全连接层的CV-CNN进行地物目标分类,平均识别率达到95.97%。文献[51]则分别将实数CNN (Real Value-CNN, RV-CNN)与CV-CNN进行识别性能上的对比。两模型均包含2层卷积层,1层池化层,1层全连接层,且均对Flevoland数据进行分类,准确率分别为97.3%和99.0%。可见,针对极化SAR数据直接在复数域进行CNN处理效果稍优于实数域情况。
此外,由于传统CNN模型针对SAR目标识别处理问题仍存在提升空间,尤其是网络训练存在一定的资源浪费,训练效率较低。其中,文献[52]提出一种全卷积神经网络(All-Convolutional Neural Network, ACNN),即在传统CNN模型下,将全连接层替换为稀疏连接层,从而针对MSTAR数据进行10类目标分类,识别率达到99.13%。该文献方法主要用于应对网络资源浪费的问题。在实际训练结果中可能存在部分权值、偏置参数接近0的情况,该部分对目标识别未起到任何作用,造成资源一定程度的浪费。此外,SAR图像质量本身受相干斑噪声、几何畸变和结构缺失等因素的严重影响,该因素导致人工标注困难,这使CNN的泛化能力急剧下降。针对这个问题,上海交通大学的赵娟萍等人[53]提出基于概率转移模型的CNN (Probability Transition CNN, PTCNN)方法,建立对带噪声的图像标记与无噪声情况之间的概率转移模型,建立噪声标记转移层,该网络能够增强带噪声标记情况下分类的鲁棒性。文献[54,55]通过CNN对SAR图像进行去斑点噪声处理,经过该处理后,图像质量明显提升,减小噪声对SAR图像的干扰,便于后续分类识别问题研究。其中,文献[54]将原始带噪声的SAR图像转换到log域,并由于斑点噪声属于乘性噪声,在log域减去通过深度网路学习到的噪声,并最终通过exp处理获得去斑后SAR图像。其中,斑点噪声为网络的学习目标,通过对去噪后图像的图像质量进行视觉观察和参数评价,可以发现图像质量提升明显。但是,该文献方法进行的对数-指数转换处于网络外的处理,为了进一步减少网络学习外的处理过程,文献[55]直接进行端对端的斑点噪声学习。其借鉴残差网络建立方法,将带噪声SAR图像与学习噪声相除,得到去噪后图像,且通过去噪后图像与无噪声图像之间差距作为网络损失函数,迭代更新网络参数。通过该方法进行的SAR图像去噪效果更优。
在基于CNN的类型识别方面,仍存在大量衍生网络的研究。文献[56]实现基于SAR图像的灾后地质损失情况快速评估网络结构。其分为区域选择和损失类型识别两部分。在区域选择部分,其通过CNN衍生得到的SqueezeNet方法[57]提取受灾区域。该网络的创新点为将网络分为squeeze层与expand层。其中squeeze层通过一个1×1卷积核进行卷积,expand层是通过1×1和3×3卷积核进行卷积,expand层中,把1×1和3×3得到的feature map进行连接。其整体思想是图像的分辨率是不变的,仅改变特征图的维数,即通道数。对于区域筛选结果进行基于WRN (Wide Residual Network,WRN)[58]的损失类型识别。该网络是以CNN为基础,衍生出的ResNet的改进网络。针对在训练过程中,仅很少的残差模块能学到有用的表达,而大部分残差模块并不对最终网络分类构成影响,对网络进行宽度提升,深度减小的处理。
此外,在SAR图像目标分割领域,虽然其研究不如目标识别那样广泛,但仍有学者借鉴CNN方法实现目标分割。其中,西安电子科技大学的于文倩[59]对CNN算法的结构进行粒子群优化(Particle Swarm Optimization, PSO)改进,调整网络结构,形成一种基于超像素和正交PSO修正深度学习的图像分割方法。实验表明,该方法不仅能够实现SAR图像的目标分割,同时能够加快网络学习速度。
3.2 基于SAE的SAR图像处理研究
SAE的特点是可自动从无标记数据中学习特征,并且给出比原始数据更好的特征描述,进一步通过该学习到的特征得到更好的分类效果。有学者将其应用于地物目标分类、舰船分类以及城市变化检测等场景。并且通过SAE对SAR图像进行分析,其与传统方法相比,展现SAE具有自动学习高层特征的特性。
首先,在地物目标分类中,文献[60–64]分别通过SAE对极化SAR数据进行了目标类型的识别。例如,西安电子科技大学的高蓉[60]针对极化SAR数据具有斑点噪声以及数据量庞大等问题,对其进行SAE处理,同时结合了极化SAR原始特征与邻域极化特征实现了对地物数据的有效分类。在实验测试过程中,针对Flevoland数据的识别获得了85.1%的准确率,对Germany数据获得了85.3%的准确率。文献[61,62]分别将SAE对极化SAR的识别效果与传统方法进行比较。其中,文献[61]同样对Flevoland数据进行测试,运用其中10%的数据进行训练,90%的数据进行测试,识别率达到93.58%,而运用传统的SVM方法所获得的识别率仅为89.86%。此外,文献[62]对Flevoland数据进行测试,SAE方法识别率达到98.61%,而传统的随机森林方法对应识别率仅为97.67%,基于SVM的识别方法为97.50%。并且多层自编码器方法仅为94.27%,可以看出对网络加入稀疏编码过程的必要性。在此基础上,西安电子科技大学的石俊飞等人[62]还提出,虽然SAE方法能够学习高层特征,有效地表示城市、森林等复杂的地物结构,却难以保留图像的边界和细节信息。因此,可将SAE与极化层次语义模型相结合。实验表明,针对San Francisco数据,相比于单独运用SAE方法进行识别,该方法将准确率提升了0.87%[63,64]。
此外,国防科学技术大学的涂松[65]提出通过SAE深度网络对SAR图像进行目标提取。在大尺寸SAR图像中,首先进行多尺寸显著区域检测,之后对显著图进行SAE深度网络分类,实现大尺寸SAR图像目标快速提取。其中,分别选择600个目标样本和600个背景杂波样本用于训练SAE网络。并且为了提高效率,将所有的训练样本降采样为64×64,然后将所有像素排成一个列向量,进行SAE训练。在该SAE网络中,输入为4096维,隐层数量为3层,每个隐层神经元个数为20,输出为2维。该网络能实现车辆目标和杂波背景两类样本的分类。文献[66]在进行目标分类时首先进行特征提取,进而通过归一化和白化的预处理。针对提取到的相互独立的特征进行SAE网络提取编码结果,最终获得分类标签。该方法充分体现了SAE方法的无监督性,且针对不同特征进行分类的能力。
SAE应用广泛,可对城市变化情况进行检测。由于该领域下带标签的已有数据量较小,因此很难通过传统的监督学习方法实现分类。文献[67]通过SAE进行检测,在数据量较小的情况下,检测概率达到92.34%,并且相比于传统方法虚警率减小了2.64%。此外,考虑到SAR图像具有斑点噪声的特点,且去噪自编码器对该噪声具有一定程度的鲁棒性。因此,中国科学技术大学的阮怀玉[68]考虑将多尺度稀疏表示与去噪自编码器网络相结合形成新的学习架构,实现了舰船的分类。分别对MSTAR地面目标数据集与TerraSAR-X舰船数据集进行分类,并且得到了98.83%和92.67%的识别率。
3.3 基于DBN的SAR图像处理研究
DBN应用灵活、广泛。其即可作为一种非监督学习模型,类似于AE,可尽可能保留原始特征,同时降低特征维数;又可以用于监督学习,类似于分类器,可尽可能减小分类错误率。因此,DBN可对不同SAR图像进行识别及其他操作处理。
在极化SAR目标识别领域,前文已经介绍了CNN以及SAE方法的研究成果。而本部分主要介绍基于DBN的极化SAR目标识别处理。其中,西安电子科技大学的罗小欢[69]结合极化SAR图像散射特征和数字图像特征以及颜色直方图特征训练一个有多个RBM组成的DBN模型。具体地,首先,将极化SAR数据的相干矩阵转化成一个9维极化SAR数据;之后,在每个维度上抽取大量模块,并对列向量进行RBM训练,从而获得每个维度的结构特征;最后,将该特征与原始相干矩阵元素相结合,训练DBN,实现极化SAR数据的分类。文献[70]则将DBN识别结果与传统方法识别结果进行对比,其中,DBN的识别准确率为87%,而基于SVM方法的识别率仅为44%。此外,西安电子科技大学的赵昌峰[71]将Wishart分布引入RBM,使极化SAR特征表达更加明显,提出了Wishart RBM (WRBM)。在对Flevoland和San Francisco数据进行测试时,识别率分别达到90.06%和91.49%。
此外,文献[72]提出由于DBN能够充分发掘主辅强度图和相干图在空间域和时间域上的相关性,因此可运用该方法进行干涉SAR图像分类处理。并且在对San Francisco进行实验分析时,分别讨论DBN层数、隐层节点数、学习率对网络识别率的影响。最终,在4层DBN、50个隐层节点以及0.1的学习率情况下,将DBN方法与传统方法进行对比。其中,K近邻(K-Nearest Neighbor, KNN)、SVM、SAE与DBN识别结果分别为:89.13%,90.92%,90.89%以及91.03%,可见DBN方法识别优势较为明显。此外,该文献将DBN用于SAR图像配准,且其能获得鲁棒性特征以及实现准确地配准。具体地,分别将两幅待匹配的SAR图像输入,并提取图像块,将其输入DBN,输出即为匹配标签。
4 基于深度学习的多种雷达数据处理研究
在上一节重点总结了基于深度学习的SAR图像处理研究,而在实际情况下,有学者分别对HRRP、Micro-Doppler谱图以及R-D谱图进行研究,并对其进行深度学习方法处理。同样能获得较优的结果,并与传统方法相比,深度学习算法能够有效地提取对应图像的深度特征,便于后续处理。
4.1 基于深度学习的HRRP处理研究
HRRP能反映目标散射点沿距离方向的分布信息,且获取方法更为简单。其特点是通过发出某一波长的高频信号,通过反射成像,从而获得HRRP。图6为4种目标的HRRP示意图。在此基础上,有学者选择通过不同的深度学习方法对HRRP进行目标的识别,其主要包括CNN, SAE, DBN以及RNN等。
文献[73]提出,对HRRP进行基于CNN的目标种类识别。具体地,该网络包含2层5×1大小的卷积层,以及2层3×1的最大池化层,1层包含1000节点的全连接层,最后运用softmax进行分类。通过对8类仿真HRRP数据进行网络训练及测试发现,深度CNN识别准确率大于深度感知机,约10%左右。在此基础上,对该数据加入高斯白噪声,使得处理后数据信噪比范围为–20~40 dB。并且每类数据进行1000次蒙特卡洛实验,对3类目标进行识别,平均准确率达到91.4%。说明CNN对HRRP进行识别时鲁棒性较强。
南京航空大学的张欢[74]对Su27, J6, M2K 3种仿真战斗机的HRRP数据分别采用SVM、深度神经网络(Neural Network, NN)、SAE方法进行分类。在固定输入数据为128维情况下,分别讨论了深度学习方法中层数、隐层节点数、数据信噪比以及目标姿态对识别效果的影响。其中,当对25 dB数据进行2层且隐层节点数为50的网络进行训练及识别时,NN和SAE平均识别率分别为79.63%和85.00%,明显高于传统SVM的74.26%。文献[75]运用SAE方法提取HRRP特征,之后对其进行极限学习机的分类。该方法通过SAE获取有效分类特征,并且极限学习机的结构简单,网络训练速度相对较快。并且经过测试,发现在识别率相近的情况下,该方法训练时长是经典SAE方法分类的1/6,效率提升明显。此外,文献[76]对SAE进行改进,对无标签数据进行目标相关性学习,提出SCAE (Stacked Corrective AutoEncoder)方法,进一步提升对HRRP的分类效果。
文献[77,78]均采用DBN对HRRP数据进行目标类型识别。其中,文献[77]提出对于RBM部分进行可视层和隐层之间的模糊(fuzzy)连接,即FRBM。通过实验发现,该模型能够有效削减取值为0的参数的个数,从而防止过拟合。同时,针对含噪数据,其鲁棒性更强。在该文章中,首先对3种飞机模型的HRRP仿真数据分别进行KNN、支持向量数据描述(Support Vector Domain Description,SVDD)、RBM和FRBM方法识别,平均识别率分别为82.3%,85.7%,88.9%和94.3%。其次,分别对原始数据加入高斯白噪声得到的不同信噪比(20 dB,10 dB, 5 dB)数据,以及加入椒盐噪声的数据分别进行RBM和FRBM分类处理,发现所有情况下FRBM识别率均高于RBM情况,且超出的识别率在10%以上。此外,文献[78]考虑了不同类别数据量不平衡的问题,并且实验证明,当不同类型HRRP数据量差异明显的情况下,通过DBN进行分类,不同类型的识别率差距明显。因此,该文献提出在进行DBN分类前,对样本进行t分布随机邻域插入处理,并对插入后的数据进行随机采样,扩充了相应类型的样本量,从而使不同种类样本量得到平衡。之后,再进行DBN的训练与识别。在该情况下,3类数据的平均识别率为92.8%,而在原始数据不平衡的情况下,平均识别率仅为56.3%,识别率提升明显。

图6 4种目标HRRP示意图Fig.6 HRRPs of four targets
文献[79]考虑到传统的CNN模型不能提取相邻时间输入的样本之间的相关性,而循环神经网络(Recurrent Neural Network, RNN)恰能提取该特征,从而提出对HRRP进行RNN处理。该文献采用RNN中的长短时记忆循环神经网络(Long-Short Term Memory recurrent neural network, LSTM)对HRRP进行分类。LSTM模型的输入节点为128,输出节点数为3,隐层节点数为50。对175幅3类HRRP进行LSTM训练,并对100幅HRRP进行测试,全部识别正确。
4.2 基于深度学习的Micro-Doppler谱图处理研究
微多普勒效应是由物体及其构建的微动产生的物理现象。雷达目标的Micro-Doppler谱图对于目标的检测识别具有重要意义。一般情况下,通过信号处理方法从雷达回波信号中提取表征目标微动部件情况的时频谱图,而对于单一维度的雷达回波无法获取该信息。图7为两个仿真目标的时频谱图。对于Micro-Doppler谱图,已有学者采用深度学习方法对其进行分析,提取深度信息,实现目标识别任务。其中,鉴于CNN方法对处理图像的优越性,最受人们青睐。此外,SAE方法能够在无监督情况下提取深层特征,也成为人们研究的重点。并且有学者将两者结合,或选择卷积自编码器(Convolutional Automatic Encoder, CAE)对Micro-Doppler谱图进行分析,获得明显的分类效果。
文献[80–85]均选择深层CNN方法对Micro-Doppler谱图进行类型识别。其中,文献[80]对7种人为动作进行包含3层卷积层,3层最大池化层、1层全连接层以及softmax的CNN分类处理。该方法与传统PCA, SVM方法识别率进行比较,分别为95.2%, 84.0%以及89.2%。此外,文献[81]通过Micro-Doppler谱图的识别进行手势识别处理。其中,90%的数据进行5层DCNN训练,并对10%的数据进行测试,得到的7种手势在4个场景下的平均识别率为93.1%。文献[82]则通过包含2层卷积层、2层池化层以及1层全连接层的CNN,先后进行人的检测与人动作的识别。在检测部分,通过该网络对人、狗、马、车4种目标进行分类,从而检测人是否存在,其检测概率达到97.6%;在识别部分,对人的跑、走、卧等7种动作进行分类,平均识别概率为90.9%。在文献[83]中,研究对人类步态的分类问题,其选用了14层CNN模型,其中包含8层卷积层,3层最大池化层和2层全连接层以及softmax分类器。相比于传统神经网络和SVM分类方法的68.3%和60.3%的识别率,运用CNN方法的情况下识别率有明显提升,达到86.9%。在此基础上,文献[84]通过基于CNN的迁移学习对人类水下动作进行识别。

图7 两仿真目标时频谱图Fig.7 Time-frequency map pf two simulation targets
此外,有学者将SAE架构应用于Micro-Doppler谱图的分类问题中。例如,文献[85]运用SAE方法对人的运动情况进行分类,得到87%的平均识别率,同样数据进行SVM分类器分类,得到识别率仅为58%。文献[86]运用3层SAE进行微动数据分类,获得89%的平均识别率,而对127个特征进行SVM分类,识别率仅为72%。在此基础上,文献[87,88]将SAE与CNN相结合进行Micro-Doppler谱图分类处理。其中,西安电子科技大学的张国祥[44]提出,首先运用SAE进行无监督的特征提取,得到特征谱图,之后对特征谱图进行CNN的分类,最终得到95.62%的平均识别率。文献[89]则运用CAE方法进行分类。其中,在编码器部分,由3层卷积层,3层池化层组成;在译码器部分,由3层反卷积层和3层逆池化层组成。最终,将提取到的特征进行分类器分类。在此基础上,提出运用迁移学习方法对网络初始化参数进行设置,从而对CAE模型的识别率提升了10%。
4.3 基于深度学习的R-D谱图处理研究
当对动作进行分类时,除了进行时频分析,距离向信息同样至关重要,即R-D谱图可作为分类研究对象。在线性调制连续波(Linear Frequency Modulated Continuous Wave, LFMCW)雷达中,首先对回波进行去斜处理,之后在快时间域进行快速傅里叶变换(Fast Fourier Transform, FFT),获得目标的实时径向距离信息;进而对各个距离单元内的基带信号的慢时间域FFT处理,获得回波信号在距离-多普勒域的能量分布情况,即R-D谱图。由多帧R-D谱图组成,即R-D谱图序列描述一个持续一段时间的行为动作。其中,基于雷达的动态手势识别处理为典型的应用场景。
针对动态手势的R-D谱图序列,文献[90]提出对Google的Soli传感器采集的10个人的11类手势动作进行R-D谱图序列分类。首先,对于每帧R-D谱图进行卷积及全连接处理,之后针对整个动作的不同时间点特征图之间进行LSTM连接,最终获得87.6%的平均识别率。本课题组对基于R-D谱图的手势数据进行了CNN的识别,对向前、向后、旋转、静止4种手势进行分类,示意图如图8所示。其中,CNN方法的平均识别率达到87.8%,同组数据进行传统动态规划方法识别,平均识别率仅为74.0%,即证明通过CNN方法对该手势进行识别,识别率提升明显。
此外,文献[91]进行人体运动检测,同样可视为两类运动的识别问题。首先,针对不同动作的距离-多普勒谱图序列,分别提取时间-频率谱图以及时间-距离谱图,然后分别进行SAE特征提取,并对两部分特征进行融合,最后完成分类器分类。该文献分别提出如图9的两个分类架构。图9(a)为串联结构,即先对两谱图分别进行SAE特征提取;之后进行特征融合,融合后再进行SAE提取特征;最后进行分类器分类。图9(b)为并联结构,即先对两谱图分别进行两层SAE特征提取;之后,将两部分特征进行融合;最后,通过分类器分类。经实验显示,该两网络对相同数据进行处理时,获得的检测概率分别为89.4%和84.1%。
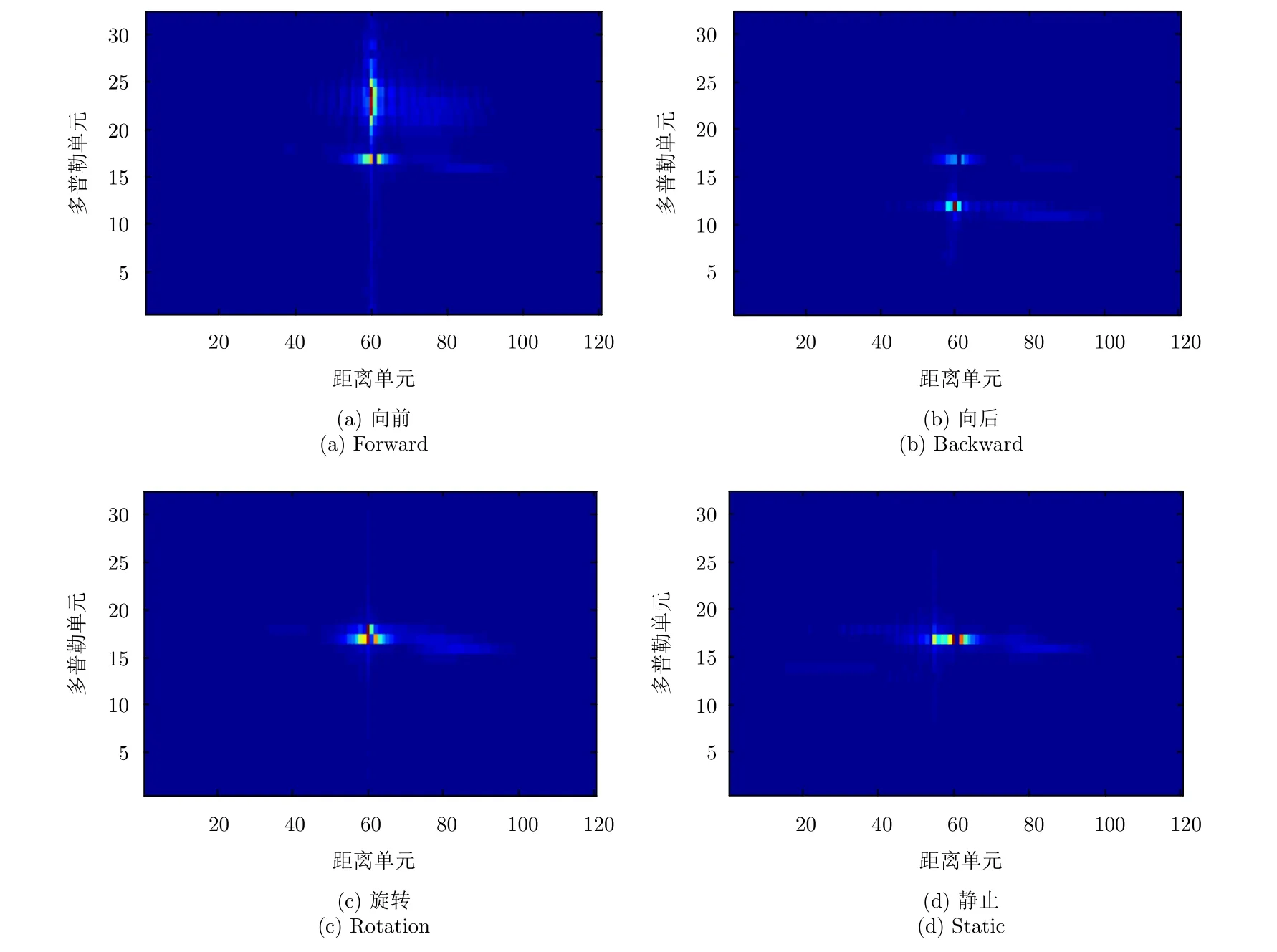
图8 4种手势R-D谱图Fig.8 R-D map of four gestures

图9 两种检测网络架构Fig.9 Two detection structure
5 深度学习研究面临的挑战
由前文所述可知,深度学习在雷达信号处理领域得到了广泛的应用,同时取得了不俗的成绩。虽然如此,但其深度学习研究仍存在诸多不足。其中,过拟合和网络可解译性为亟待解决的问题。
首先,对于过拟合问题而言,即当测试数据与训练数据有一定差异,而测试误差明显高于训练误差时,即说明网络泛化能力较差,出现过拟合问题。并且当网路模型是复杂的,包括大量参数,且训练数据不足的情况下,过拟合问题明显。针对该问题,文献[92]提出可通过扩大训练数据集、减少网络参数和降低网络迭代算法复杂度来减小过拟合情况。文献[93]利用DBN代替浅层神经网络,对隐层节点数的选取进行迭代设计,并且构建网络状态观测器,解决过拟合问题。文献[94]则对多层自编码器进行数据生成预训练,并进行正则化方法设计,用于防止过拟合。文献[95]在深度神经网络的全连接层后加入放弃层,可有效降低过拟合数据对预测的影响。此外,文献[96]设计一种定量检测过拟合的变量,即过拟合率。在此基础上,提出一种新的AdaBELM过拟合降低方法。文献[97]在CNN中最后一层进行全局平均池化,从而减小网络参数,有效缓解过拟合问题。
此外,由于网络设置原理具有“黑箱”特点,且为了避免网络设置的盲目性,可解译性成为研究热点。文献[98]提出基于小波核学习的深度滤波器组网络,该网络具有较强性能,且根据信号处理方法具有理论上的确定性和可重构性,对网络进行优化。该文献还对CNN可解译性的相关研究工作进行了总结。典型方法为2010年由Zeiler提出反卷积网络方法[99,100],该方法为卷积的反向处理过程。其为通过对学习得到的特征图进行卷积求和,得到接近输入图像的过程。文献[101]通过反卷积网络对特征图进行可视化,通过卷积网络中层特征可以恢复对应的原图中的一些信息,利用这样的关系,了解通过CNN提取到的特征的情况。2017年,文献[102]提出可解释CNN。该网络与经典CNN类似,均为端到端的学习架构。通过对卷积层卷积核的约束,使该卷积核有利于提取物体某些部件的特征。例如,对于动物的分类问题,其主要通过卷积核提取其头部特征。具体的,其正向学习过程与CNN基本无差异,但在反向迭代过程中,加入新的损失函数项,即经过卷积处理后的特征图与某部件理想分部之间的互信息量的相反数。
6 总结
本文主要总结了已有的基于深度学习的雷达数据处理研究方法。针对SAR, HRRP, Micro-Doppler谱图和R-D谱图均获得了一定的研究成果。其中,基于深度学习的SAR图像处理为研究的热点问题。针对SAR图像,前人分别使用了CNN, SAE和DBN等深度学习方法进行目标分类。虽然所采用的数据不同,但与传统识别方法相比,深度学习方法能获得较高识别率。此外,深度学习在HRRP, Micro-Doppler谱图和R-D谱图中的应用虽然不如在SAR图像中那样广泛,但仍有一定研究成果,能够实现目标分类。其中,基于深度学习的动态手势识别为典型的研究领域。在RNN中的LSTM能够有效地学习相邻时间上数据的联系,从而获取更加有效地提取不同手势的深度特征。
虽然,深度学习方法在雷达领域已有研究成果,但仍存在值得后续研究的典型问题:
(1) 需避免学习网络的过拟合。过拟合是深度学习的一个典型问题,已有的对CNN加入dropout操作的目的是降低网络过拟合,但该问题仍然为阻碍深度学习发展的一大难点;
(2) 增强特征提取的解译性。本文介绍的大量研究是将雷达数据直接输入设计好的深度学习网络进行训练,之后将训练好的网络用于同类型数据的测试。长期以来,深度学习部分被视为黑盒操作,每层输出特征也不具有明确的物理意义,即网络解译性较弱,这为改进网络架构设计形成一定的阻碍。
猜你喜欢
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
电子制作(2019年11期)2019-07-04
福建基础教育研究(2019年6期)2019-05-28
北京航空航天大学学报(2018年1期)2018-04-20
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
