
电视节目推荐系统
2018-09-13 10:54刘炜楠杨泽灿黄再英
电脑与电信 2018年7期
刘炜楠 杨泽灿 黄再英 姜 永
(福建农林大学计算机与信息学院,福建 福州 350002)
1 引言
随着互联网技术的迅猛发展和三网融合的深入推进,传统数字电视也在不断变革,电视节目也涌现出许多新的形式、种类。数字电视拥有上百个频道,节目不可胜举,智能机顶盒对电视节目简单的分类并不满足人们对收看电视节目的需求。而通过电视节目个性化推荐,则能够减少用户面对众多节目选择以及切换频道的时间消耗,提升用户观看数字电视节目的体验。
传统的数字电视通常面向一个家庭,且互动性较低,难以获得家庭显性偏好。而通过智能机顶盒可以获取大量用户的收看信息,由此可分析用户的隐性偏好。
基于内容的推荐系统适用于电视节目推荐。依据用户节目观看时长、节目观看时段和节目观看次数挖掘家庭用户偏好模型,提出单一家庭用户,建立低一级的“时段-节目”模型,采用经典的K-means聚类方法对用户和节目进行聚类,实现对用户和电视产品分类推荐。
2 基于内容的推荐
基于内容的推荐是通过用户过去的行为记录挖掘用户的偏好特征,从而向用户推荐具有类似特征的电视产品,即对用户推荐新的符合用户过去偏好特征的电视产品。
这种推荐算法首先需要获取电视产品的特征描述,其次通过对用户行为记录分析,建立用户偏好模型,最后匹配推荐。在电视节目推荐中,基于内容的推荐系统首先分析用户看过电视节目的共性(演员、导演、类型等),再推荐与这些用户感兴趣的节目内容相似度高的其他节目。
基于内容推荐的优点是新的节目上线便可以进行推荐和新用户产生行为记录即可推荐;其缺点是推荐的新颖度和精细度低,难以给用户推荐新领域的节目,且由于新用户的行为信息不足,推荐有一定局限性。
3 电视节目特征的提取
基于内容的推荐核心是提取节目的属性特征,其中,节目内容尤为重要。对节目内容采用TF-IDF(一种用于资讯检索与资讯探勘的常用加权技术)计算出节目内容的每个词的TF-IDF值,按降序排列,取排在最前面的几个词作为节目的特征。
传统电视节目信息的分类形式有形态类型和内容类型,形态类型包括新闻时事、电影、电视剧、综艺娱乐、体育竞技、生活服务、科学教育和广告八大类;内容类型有综艺、喜剧、戏剧、动画、冒险、运动、游戏、儿童等可作为节目特征。此外,节目的制作信息(节目的导演、演员、内容描述、出品年代等信息)也可作为节目特征。
4 用户偏好的研究
与网络视频推荐不同,家庭用户往往具有多位成员,他们喜好不同、观看时间不同。为此,家庭用户模型建立主要包括两部分:一是推荐什么节目,二是什么时间推荐。可总结为:在合适的时间段推荐二级用户感兴趣的节目。
智能机顶盒在联网条件下能够实时记录用户所有的收看行为信息。这些信息包含用户以何种方式收看节目、用户观看起止时间和节目信息。
基于用户观看时长、观看次数和电视节目的标签属性等隐性反馈信息,可以很好地反应用户偏好特征。利用详细的一份频道节目信息表,通过比较频道节目信息表和用户行为信息表相应日期的时间先后,判断用户在何时观看了什么节目,可以关联出“用户-节目”信息表,得到“用户-节目”模型。
除了节目偏好,用户总是倾向在一个固定的时间段观看电视节目。因此可以按照时间先后划分,分别为6:00-10:00、10:00-14:00、14:00-19:00、19:00-24:00。以时间段为划分,统计各个时间段家庭用户播放的节目,以观看时间长、频率比重大的为用户时段偏好建立“时段-节目”模型。
机顶盒的信息是从机顶盒开机起实时记录的,未必是完全有效的用户行为信息,用户在寻找节目、切换频道时会产生时长较短的记录,用户极少数会存在连续不断地只观看一个频道。为应对这个问题,可以设置观看时长上下阈值。
用户收看电视节目主要有三大方式,包括直播、回看和点播,这些方式最大的区分点是时效性。直播是最传统的收看方式,节目准时在电视频道上放送,时效性最大。回看和点播的出现正是为了突破直播时效性受限性,给予用户更多的节目自主选择性。其中,点播的时效性最小,基本不受限。后两种方式通常是收费型功能,点播价格高于回看价格。金钱花费往往可以表达用户对节目的偏爱,则点播计算的偏好度权重应大于回看的,考虑到点播次数少于回看次数,故将两者权重设置相同。对于以上三种收看方式,可以分别设置1,2,2的权值。
针对收看直播和回看行为,定义用户对节目偏好度p为用户节目收看总时长与节目本身总时长之比;针对用户的点播行为,定义用户对节目偏好度p为用户单个节目点播总次数与用户点播总次数之比。
对于用户不同收视行为的偏好度计算方式不一,计算出的偏好度会出现偏差。为此利用函数

进行修正,其目的是让所有行为产生的偏好度p的值域处于(0,1)之间,以规范标准。
最后,按上述权值分配计算用户对节目偏好度f(p)的加权平均数,作为用户对节目最终偏好度。
5 电视节目推荐系统
电视节目推荐系统中,为了确定电视用户兴趣的相似度,以电视用户X对电视节目特征i的最终偏好度xi为坐标,即X=X(x1,x2,…,xn),n为节目特征数,并以欧几里德距离:

计算电视用户X和Y的相似度。为了使用方便,将其规约到(0,1]之间,其公式如下:
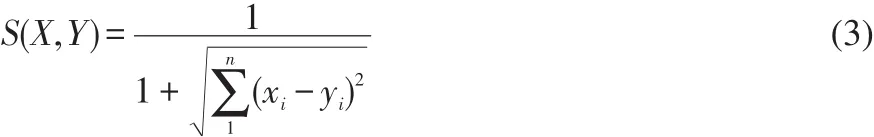
其中公式(2)的值越接近数值0,即公式(3)的值越接近数值1,表示用户间的偏好越接近。根据用户的最终偏好,采用K-means聚类算法对用户进行分类。
K-means算法通过将样本划分为k个方差齐次的类来实现数据聚类。聚类算法描述如下:
1)从数据源中读取数据,随机选取k个用户作为当前聚类的中心,记为{C1,C2,…Ck}。
2)对每个用户Ui,求其到每个类Cj的中心ui的距离,将该用户划分到距离最近的一个类中。
3)对于每一个类Cj,通过均值求出其中心ui。
4)通过步骤2)3)的迭代更新每个类Cj对应的ui,当ui与更新前的值相差微小,则结束迭代,否者一直重复2)3)步骤的迭代。
推荐方法:
1)根据K-means聚类算法对用户的偏好进行聚类,提取出本类用户中观看过的电视节目集合Ck。
2)对该类中的用户Ui计算其观看过的节目集合Cui。
3)对用户Ui推荐电视节目合集为:Ck-Cui。
通过节目特征对应用户偏好特征、节目对应时间匹配过滤,将相似度高的节目按“节目-时段”模型,在对应时段推荐给相应的用户。
6 结语
基于内容的电视推荐,在电视节目用户群体的行为记录中挖掘用户潜藏兴趣偏好,运用K-means聚类对节目分类,并根据描述统计推断并建立“用户-节目”模型。基于内容的推荐算法也存在一些问题:一是需要大量的用户行为信息,才能建立较为精确的用户模型,并据此提供合理的推荐方案。然而,对新用户而言,其行为信息不足,难以对其进行建立模型,对新用户的推荐精准度可能存在偏差。二是由于用户未关闭机顶盒或开着电视当背景音乐的行为数据的清理,利用随机抽样统计分析可得到较为合理的阈值设置方法,但不可避免存在误删有效数据的情况。
猜你喜欢
老年博览·上半月(2019年9期)2019-09-10
电子测试(2017年15期)2017-12-18
无线互联科技(2017年5期)2017-06-21
北京广播电视报(2016年15期)2016-10-19
北京广播电视报(2016年15期)2016-10-19
新闻传播(2016年13期)2016-07-19
西部广播电视(2015年10期)2016-01-18
新闻传播(2015年22期)2015-07-18
中学科技(2015年4期)2015-04-28
电子科技大学学报(2015年3期)2015-03-23
