
Opus话音编解码器关键技术研究
2018-09-13 05:04徐山峰王兆伟
中国电子科学研究院学报 2018年4期
梁 静,谢 佳,徐山峰,王兆伟
(中国电子科学研究院,北京 100041)
0 引 言
随着互联网的迅猛发展,VoIP技术得到越来越广泛的应用。话音编解码技术作为VoIP体系架构的核心之一,也在不断推陈出新。Opus[1]是一款由Xiph.Org、Mozilla、微软、Broadcom、Octasic和Google联合开发的有损音频压缩格式,特别适合互联网上的话音实时交互需求。2010年12月由IETF正式批准成为国际标准,版本号是RFC6716。Opus是由声码器SILK[2]和CELT融合发展而来,Opus编码后码率范围是6 kbps到510 kbp,具备静音检测功能,支持单声道和立体声,最多可支持255路声道的混音,成帧周期范围覆盖2.5 ms到120 ms,采样率范围是8 kHz到48 kHz,可以较好的兼容话音通话和多媒体立体声[3]。
1 Opus编解码器原理
Opus编解码器由两款编解码器融合而成:基于线性预测(LP)的SILK编解码器;基于改进的离散余弦变换(MDCT)[4]的CELT编解码器。Opus工作在以下三种模式:SILK模式;CELT模式;混合模式。其中SILK模式适用于宽带话音信号,CELT模式适用于音乐盒高码率话音信号,混合模式适用于SILK与CELT同时工作的超带宽与全带宽话音信号。图1展示了Opus的宏观架构。
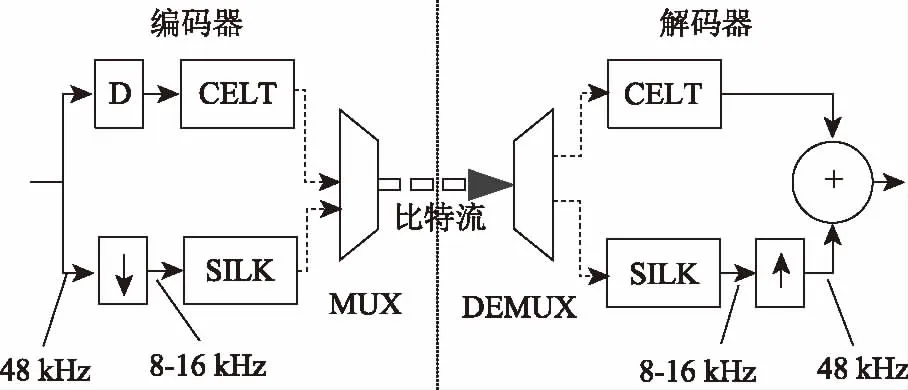
图1 Opus架构图
CELT模式始终工作在48 kHz的采样率,而SILK模式可以在8 kHz,12 kHz或16 kHz采样率下工作。在混合模式下,两种模式可以进行无缝切换,交叉频率为8k Hz,当SILK的采样率为16 kHz时,CELT将会丢弃所有低于8 kHZ的频率[3]。
Opus编解码器融合了CELT和SILK两种编解码器,下面分别对CELT和SILK这两种编解码器的关键技术进行综述。
1.1 SILK编解码器
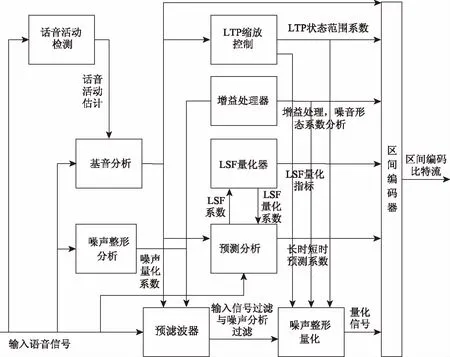
图2 SILK编码器结构图
SILK编码适合采样率不超过16 kHz采样率的低频信号,因此Opus编码中的所有低于16 kHz采样率的音频内容都由SILK编码。SILK编码器包含一系列组件,总结为4个部分:音频分析、预过滤、编码和输出。首先,基音分析将音频信号分为清音帧和浊音帧两部分,噪声整形分析将周围环境中重复的噪音打包为越小越好的音频子帧,使其占用更小的带宽。利用分析阶段获得的信息,就可以进行预过滤和频率量化处理,这一步的目的是让数据流在保证质量的同时,越少越好。对浊音帧进行预白化(pre-whitened)处理,经过长时预测滤波器(LTP)去除浊音中的周期成分,在通过短时滤波(LPC)去除近样点之间的冗余信息。对于清音帧信号,由于其信号的周期性并不明显,则不需要通过长时滤波器(LTP)进行滤波。因此清帧信号将被丢弃,直接通过短时滤波器(LPC)进行分析。将产生的激励信号进行LSF量化和增益量化,最后经过区域编码器进行无损压缩形成编码比特流。SILK编码器结构图如图2所示。
SILK解码器是一个高度模块化的结构,主要包含熵解码、参数解码、激励信号生成、帧重建、立体声分离以及采样率变换,其中帧重建模块主要包含LTP合成滤波器和LPC合成滤波器两个模块。
SILK的解码过程如下:首先,编码比特流通过区间解码器对输入的比特流进行熵解码,熵解码是基于区间编码(Range coding)的熵编码的方法,将解码后的音频数据流传入参数解码器中,参数解码器输出标志位脉冲、信号增益、高音延迟、长时预测系数和线形预测系数等,其中标志位脉冲和信号增益用来产生激励信号,而长时预测系数和线性预测系数来用于LTP和LPC合成,激励信号需要经过帧重建模块。帧重建后产生的音频信号包括立体声音频和单声道音频,对于立体声音频需要进行立体声分离,单声道音频则直接跳过这个过程。最后,将产生的音频信号经过采样率变换过滤器进行重采样编号,得到最终的解码音频信号[5]。SILK解码器结构图如图3所示。
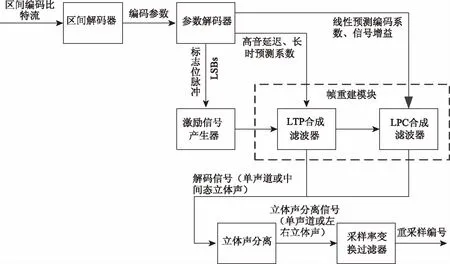
图3 SILK解码器结构图
1.2 CELT编解码器
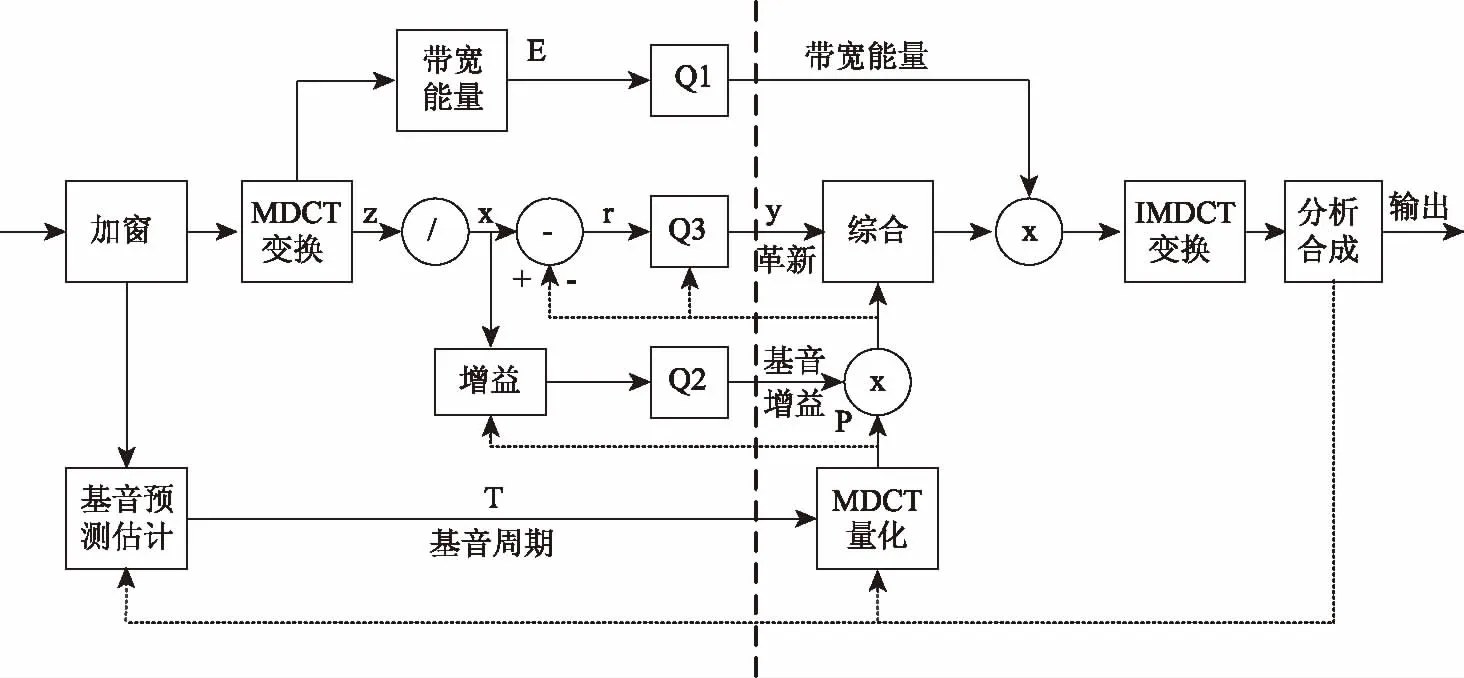
图4 CELT编解码器结构图
如同大多数的变换编码算法,CELT编解码器是基于改进的离散余弦变换(MDCT)实现的,拥有高质量、低时延两大特点。CELT编解码器的基本思想是话音的频谱包络,能够精确的编码接近听觉系统的关键频带能量,保证了频谱包络的输入与输出相匹配,从而实现了其原始的高质量音质。通过改进的离散余弦变换(MDCT),将输入信号划分为256个样本帧,每个MDCT窗口由两个样本帧组成,重叠窗口时长仅2.5 ms,在质量、比特率开销很小的情况下降低了算法时延。
CELT主要编解码过程如下,将编码前的时域语音信号,利用MDCT变换将时域转换为频域。而在解码时,IMDCT变换则是将数据从频域转换为时域的语音信号。由于人耳对于能量大的关键频带比较敏感,每个帧只有少量的比特率是可用的,CELT必须限制或消除元信息,所以讲MDCT频谱粗略的划分为20个频带,将每个频带的频谱进行规范化,并分别对能量及频谱进行编码,使得每个频带上矢量化的能量和频谱传输到解码器端,从而能够更精确的恢复其语音信号。CELT通过基音预测估计模块对合成后的语音信号的密集谐波进行建模,用于产生低延时和高分辨率的谐波信号。由于短块变换只能解决周期为整数倍帧大小的谐波信号,因此基音预测被编码为时间偏移,在频域时则需要基音增益进行编码。最后经过分析合成模块,恢复语音信号的原始增益,减少噪音对原始音质的影响,从而获得高质量的语音输出[7]。CELT编解码流程如图4所示。
2 鲁棒性
在整合、优化CELT和SILK两款编解码器的基础上,Opus兼具了以下四种技术,具有较强的鲁棒性。
(1)前向差错纠正(FEC)
前向差错纠正是在数据传输中进行错误控制,当传输中出现错误,允许接收端利用数据传输的冗余信息再建数据,将丢失包解码出来。将前一帧或前两帧的冗余信息加到当前帧,对于每一帧,编码器根据以下信息决定是否使用FEC:外部提供的信道丢失率估计值;外部提供的信道容量估计值;音频信号对丢包的敏感度;接收端解码器是否显示可以利用“带内”FEC信息。前向差错纠正(FEC)的好处就是在数据传输中进行控制,使得Opus不会产生大的延时,最多也就是一个包的延时,适用于实时的交互应用。
(2)灵活的误差传播(Flexible Error Propagation)
在话音编码中经常利用帧与帧之间的相关性,以增加误差传播为代价来减少编码比特率,在话音包丢失后,解码器需要接收到几个话音包之后,才能准确的重建话音信号。Opus利用帧与帧之间的相关性,能够动态的调整编码比特率与误差传播数量之间的比例,从而灵活的控制误差传播。
(3)不连续传输(DTX)
由于SILK编解码器是码率自适应的,对于特定的输入信号,比如静音周期或背景有杂音,码率会被自动削减。
在连续模式下,当码率被削减时,接收端的传输不会被中断。因此,接收到的信号在全部传输过程中能够使码率最小化并且保持较高水平的音质。
当设置成不连续传输(DTX)时,部分编码信号不能被传送到接收端,在接收端,没有传送的部分将被SILK解码器当作丢失帧处理,即产生舒适噪音信号代替没有传送的音频信号部分。
(4)数据丢包隐藏(PLC)
PLC的意义在于当FEC和重传之后还是无法恢复时,通过信号处理的方法在接收端对丢失的数据进行补偿。PLC产生一个与丢失的语音包相似的代替语音,这种技术是基于语音的短时相似性,可以处理较小的丢包率和较小的语音包。Opus在解码端利用PLC技术,将丢失数据包对语音产生的影响隐藏,从而减轻语音的失真,进一步提高了音质。
3 性能评测
如图5所示,在编码码率较低的情况下,相同码率条件下,Opus比业界流行的实时声码器iLBC、Speex和AMR的音质更高;在编码码率较高的情况下,相同码率条件下,Opus比实时声码器G.719、G.722和G.711的音质更高,甚至超过了AAC、Vorbis和MP3等专业多媒体音乐格式。
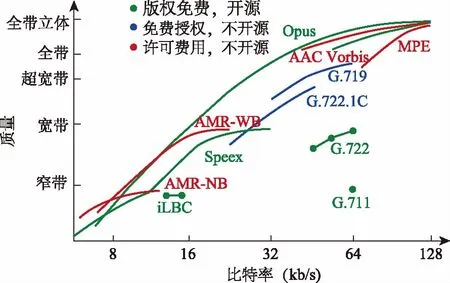
图5 不同比特率下各编码器音质对比[6]
如图6所示,相对于业界其他流行的声码器,Opus声码器具备更宽编码码率范围的同时,编解码处理的时延开销却只有20 ms左右,这是Vorbis、AAC和MP3等追求更高音质的专业多媒体声码器难以达到的。即使是AMR、G.722、Speex和G.729等在VoIP中较流行的高实时性声码器也望尘莫及。

图6 不同比特率下各编码器延迟对比[6]
图7是对Opus丢包隐藏技术的性能评测,红线表示无丢包情况下的话音解码片段,紫线表示丢失的话音片段,绿线表示Opus采用PLC技术拟合生成的话音解码片段,可以看出绿线和红线差别并不大,达到了丢包隐藏的效果,体现了Opus优良的纠错能力。
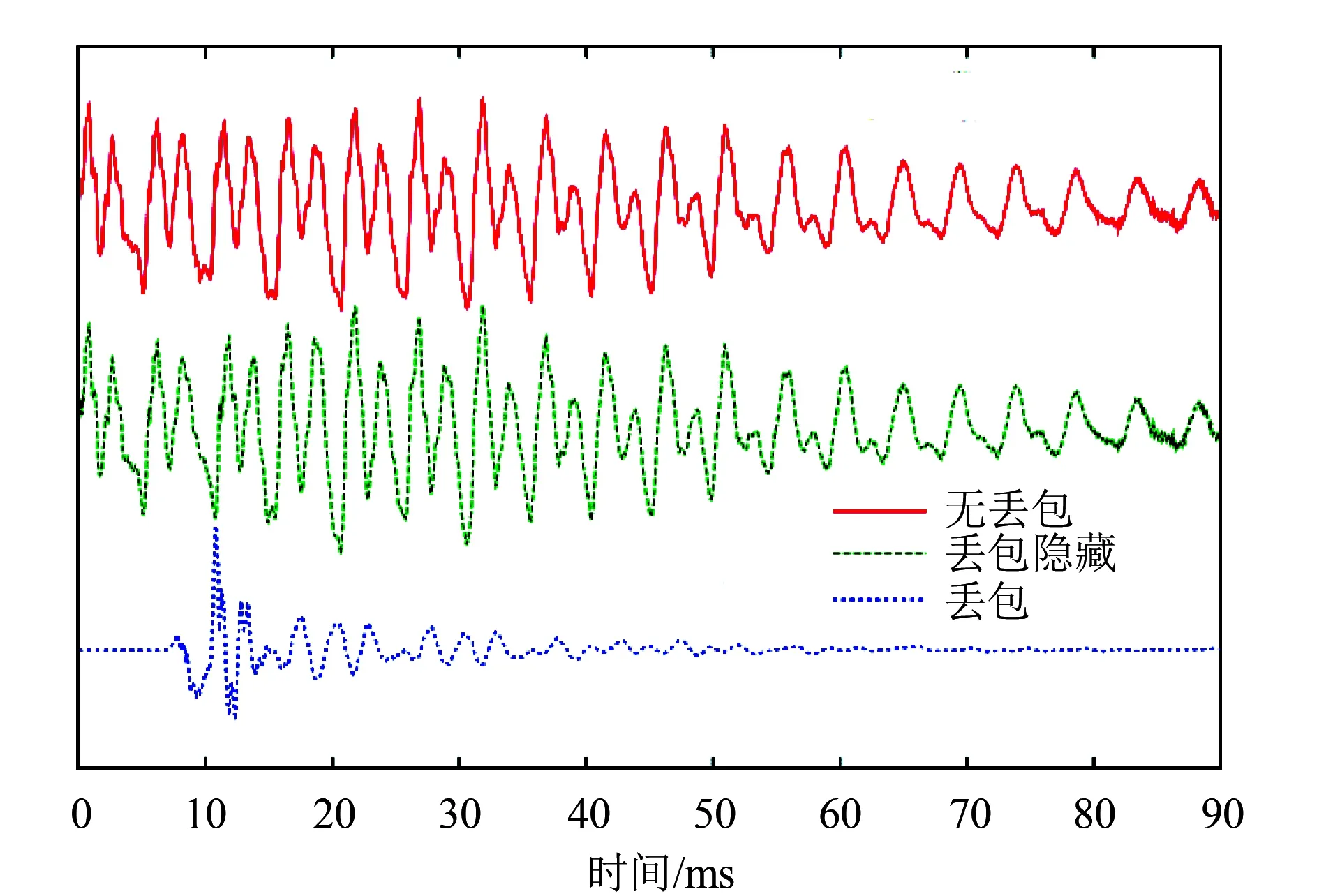
图7 无误码,解码端丢包后重建与丢包对比图[7]
另一个实验评估了Opus解码音质和网络丢包率的关系,用感知语音质量评价(PESQ)算法经过下采样后解码器输出8 kHz的话音信号,如图8所示,纵坐标表示PESQ LQO-MOS,横坐标表示网络随机丢包率,在随机丢包率为5%时解码音质依然较好,这充分反映了Opus声码器优良的鲁棒性。

图8 PESQ LQO-MOS根据随机丢包率变化[7]
综上所述,在VoIP等实时语音通信场合,Opus声码器在网络状况较差、实时性要求较高、带宽容量有限的条件下,依然能够保持较高的音质,各方面性能明显优于业界主流的其他声码器,更为重要的是,它还是一个开放源码、版税免费、遵从GPL协议的声码器。
4 结 语
OPUS话音编解码器因其开放源码、版税免费、低延迟和高音质的优势,在VoIP网络电话、语音聊天室、视频会议甚至远程在线音乐会等领域的应用前景非常广阔。目前,OPUS的最新开源版本是Opus1.1.4,随着OPUS话音编解码技术的不断更新和完善,其必将在业界得到广泛的推广和使用。
猜你喜欢
电子测试(2022年4期)2022-03-17
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
科学技术创新(2021年2期)2021-01-21
家庭影院技术(2019年8期)2019-12-04
计算机应用(2018年7期)2018-08-27
物联网技术(2018年6期)2018-06-29
数字技术与应用(2016年8期)2016-05-14
中国科技信息(2015年15期)2015-11-02
