
概率后缀树在移动用户轨迹异常检测中的应用
2018-09-03 01:48:16周湛
移动通信 2018年8期
周湛
(广州杰赛科技股份有限公司,广东 广州 510310)
1 引言
移动用户的出行轨迹反映了移动用户的出行行为规律,移动用户出现的每一个位置都会与之前出现的若干个位置存在一定的联系。因此,可用概率后缀树对移动用户的出行位置序列进行建模,用于反映移动用户轨迹的离群点或者异常点。目前的异常轨迹挖掘方法有:(1)通过提取轨迹的特征向量,采用基于距离的检测方法来检测异常的特征向量,从而达到轨迹异常点的提取[1]。(2)通过历史轨迹数据提取出k个热点轨迹,然后对比同一时间段的轨迹与热点的距离,实现轨迹异常点检测[2]。(3)先对分段后的轨迹形状进行聚类,然后再对比整条轨迹的聚类单元进行对比,实现局部轨迹异常检测功能[3]。(4)通过改进Hausdorff的距离实现轨迹聚类,通过聚类结果判断轨迹异常检测点[4]。考虑到移动运营商具有海量用户以及移动用户自身的时空数据特点,本文提出基于概率后缀树的移动用户轨迹异常点检测方法,该方法由于采用n叉树思想检测移动用户的轨迹异常点,因此具有学习代价较低的特点。
2 相关研究
2.1 概率后缀树
文献[5]给出了概率后缀树(Probabilistic Suffix Tree,PST)的详细描述:概率后缀树其实是一棵对节点进行有序排列的n叉树。作为根节点Root给出了每一个字符或者符号的无条件概率,后面的每一节点给出了前面出现的一个或者多个字符或者符号的条件概率向量。深度为L的概率后缀树一共有L阶,叶节点保存了L个字符、符号的记录以及对应的条件概率向量。概率后缀树的示例图如图1所示。
2.2 概率后缀树的构造方法
概率后缀树的构造步骤分为两步:
(1)根节点的初始化以及计算每一个字符、符号的无条件概率。设置子节点的阈值,如果字符、符号的无条件概率大于所设置的入树概率阈值,则把对应的字符、符号作为候选的子节点。
(2)递归扩充每一个候选节点。
◆计算每一个候选节点的所有可能出现后续字符串的条件概率向量。
◆设候选节点的字符串为s,如果该字符串的后续字符串σ条件概率大于设定的候选节点阈值,那么候选节点的字符串为s添加到树中。
◆如果该节点的深度小于概率后缀树设定的深度阈值,如果候选节点的字符串为s,后续字符串为σ,如果sσ的相对概率大于入树概率阈值,那么标记sσ节点作为该节点的候选节点。
3 基于后缀树概率的移动用户轨迹异常检测
3.1 移动用户轨迹预处理
从移动用户发生业务时获取的用户轨迹数据较为连续,如果用户在某个位置驻留时间较长,将会产生多次通话记录。本文已经考虑了移动用户的逗留时间,为了降低该算法的复杂度,将同一个位置的轨迹信息合并成一个。移动用户轨迹处理如表1所示。
3.2 移动用户轨迹序列化
在对移动用户轨迹数据进行预处理后,按照时间依次排序移动用户的轨迹集合,形成移动用户的出行轨迹,时间序列Tri={(L1, t1), (L2, t2), …, (Li, ti), …, (Ln,tn)}。其中,(Li, ti)表示用户在时间ti出现在Li位置。
3.3 构造PST概率模型

图1 概率后缀树的示例图
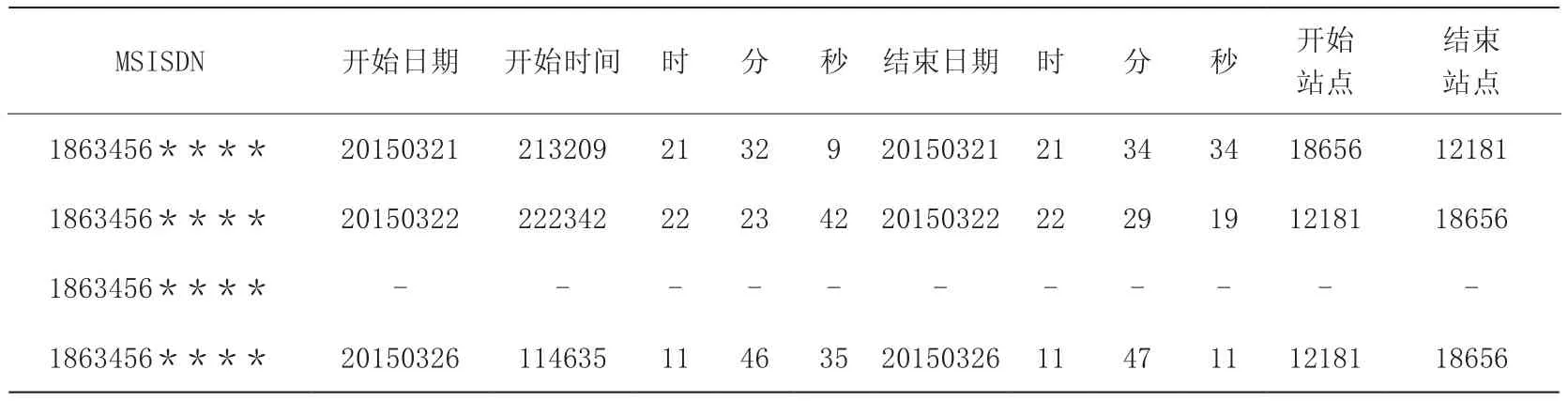
表1 移动用户轨迹处理
移动用户轨迹数据可以看作一个按照时间规律排列的时间序列。定义一个时间发生的条件概率为前n-1个时间序列已经发生的条件下第n个时间序列。不同排列的n个时间序列对应不同的条件概率分布。为了描述移动用户轨迹的规律性,以移动用户的时间序列构造概率后缀树模型,一个PST的节点对应着移动用户的某一个时间序列,而一个时间序列对应着一个d维条件概率矢量,其中d是用户时间序列的个数。图2是追踪某个移动用户在一个月内的轨迹序列,按照一个时间序列发生后下一个时间序列的条件概率以逆序从顶向下PST得到的概率后缀树,如果想知道用户经过基站12321与基站10032后去往基站10536的概率,那么从PST可知,用户去往基站10536的概率为0.25。同理,用户经过基站12321与基站10032后去往基站12321的概率为0。
3.4 移动用户轨迹的相似度分析
PST模型的一个重要作用就是计算用户轨迹时间序列之间的相似度。由参考文献[6]可知,移动用户轨迹的相似度可以定义为用户的轨迹时间序列与用户的轨迹时间序列集合之间的相似度。
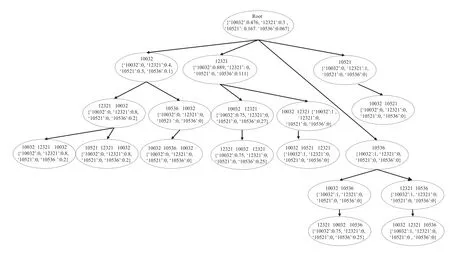
图2 基于某移动用户的轨迹数据构造概率后缀树模型
先计算一个用户的其中一个轨迹序列m在轨迹序列集合S中出现的概率:
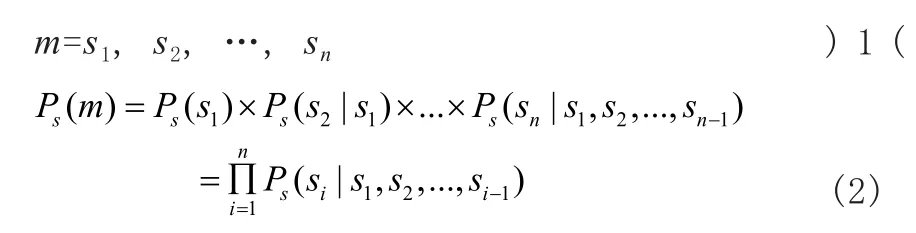
其中,Ps(m)为用户轨迹序列m在整个轨迹序列集合S的条件概率,可通过上述的PST得到。显然,当Ps(m)很大时,这表明用户轨迹序列m在用户整个轨迹序列中出现的概率较大,那么越可能是用户的常规路径,越有可能代表用户的出行规律。从聚类的角度来看,用户轨迹序列与该轨迹的集合的相似度越大。因此,本文定义移动用户出行轨迹序列与轨迹序列集合S的相似度为:

其中,Pr(m)表示移动用户的轨迹si独立随机发生的概率。显然,如果sims(m)大于1,那么表明该轨迹序列m很有可能发生;相反地,如果小于1,则表明该轨迹序列m发生的可能性不大。因此,本文把异常度的阈值设为1,如果该序列的相似度大于1则把用户的轨迹序列视为正常;相反地,如果小于1,则把用户的轨迹序列视为异常。
3.5 实验分析
(1)实验环境设置
实验环境:Windows Server 2008 R2 64bit,Inter Xeon 2.50 GHz CPU,16.0 GB内存。仿真环境:Matlab R2015b。
(2)实验数据及方法介绍
本文获取保定市某运营商10 000用户发生业务的位置以及发生的时间,然后根据上述的轨迹预处理以及轨迹序列化方法对轨迹数据进行处理,得到满足在道路上运动的移动用户数约为4 057,再通过剔除较长时间没有运动的用户,最后得到3.012×107名用户。本文收集3 012名移动用户3个月的轨迹数据,并通过频度分析的方式找到3 012名移动用户3个月正常轨迹数据并进行标注。随机抽取50%已标注的轨迹数据作为训练数据集并构建PST模型,然后对剩下的50%进行检验。得到的实验结果如图3所示:
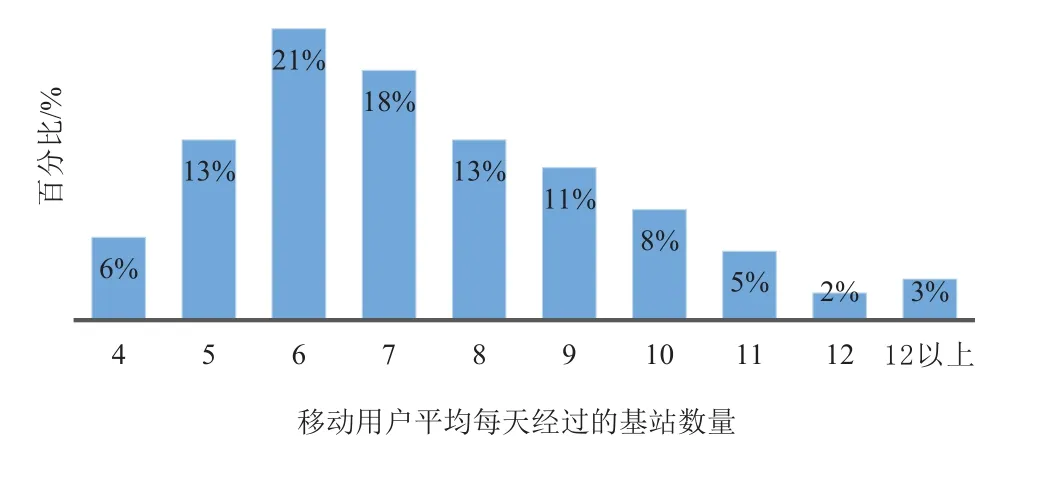
图3 移动用户经过的轨迹点数量统计图
从图3可知,大部分移动用户平均每天经过的基站数量区间为5~9,按照基站的平均部署的距离得出移动用户的日均运动距离的区间为2.5 km~5 km。该数据结果符合一般用户的出行路径长度。
对上述满足要求的移动用户轨迹数据重复10次实验,得到的移动用户轨迹异常检测准确率如表2所示:
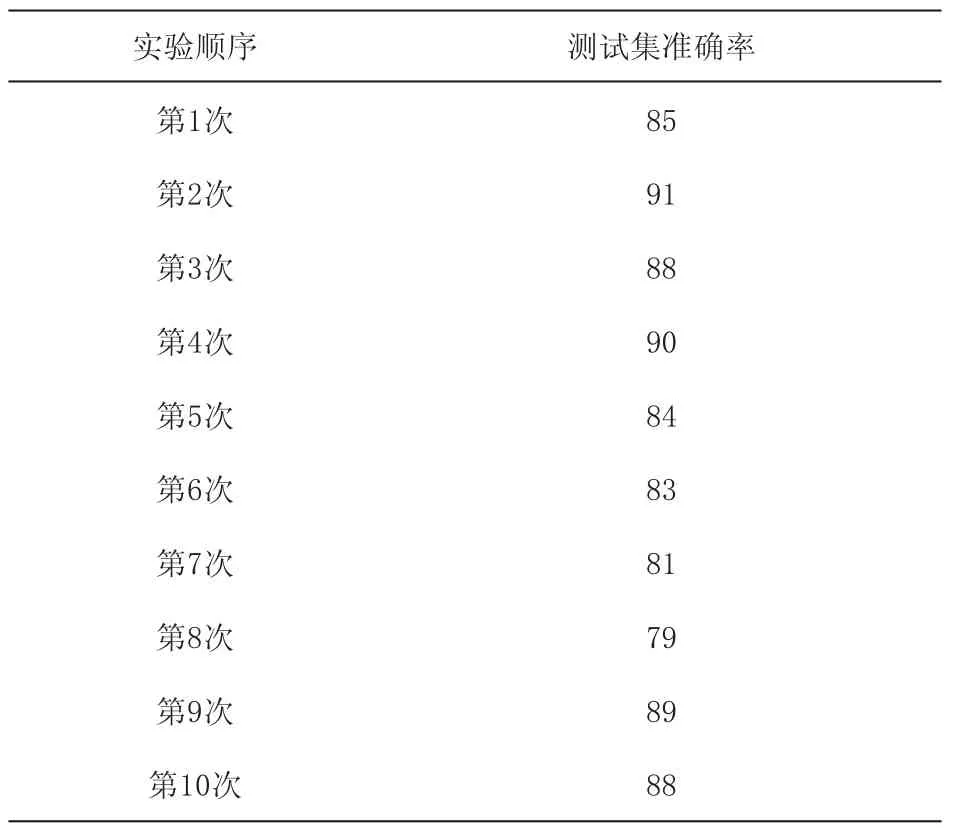
表2 移动用户轨迹异常检测模型平均准确率 %
从表2可知,测试集的平均准确率达到86%,满足工程应用的精度。由此说明,该算法能够实现移动用户轨迹异常检测的应用。
4 结束语
本文以移动用户轨迹序列数据为出发点,提出了一种移动用户轨迹异常检测的方法——基于后缀概率树的算法。在对移动轨迹进行预处理和轨迹序列化的基础上,构建移动用户出行轨迹的PST模型,基于PST模型得到的条件概率计算移动用户出行轨迹序列与轨迹序列集合的相似度,以此来实现移动用户轨迹异常检测。实验证明,基于概率后缀树的移动用户轨迹异常检测方法能够满足一定的工程应用要求。
猜你喜欢
探索科学(2017年4期)2017-05-04 04:09:47
现代商贸工业(2016年22期)2016-12-27 11:08:49
电脑知识与技术(2016年25期)2016-11-16 12:52:39
中国交通信息化(2016年8期)2016-06-06 03:56:25
现代语文(2016年21期)2016-05-25 13:13:35
意林(绘英语)(2016年5期)2016-04-09 10:55:20
辽金历史与考古(2016年0期)2016-02-02 01:34:10
移动通信(2015年17期)2015-08-24 08:13:10
电子与信息学报(2015年2期)2015-07-18 12:04:47
金融理财(2015年7期)2015-07-15 08:29:02
