
基于邻域值差异度量的离群点检测算法
2018-08-27 10:55:10袁钟,冯山
计算机应用 2018年7期
袁 钟,冯 山
(四川师范大学 数学与软件科学学院,成都 610068)(*通信作者电子邮箱fengshanrq@sohu.com)
0 引言
离群点是数据集中数据对象特征显著区别于其他数据对象的数据对象[1],其出现往往隐含或预示具有特殊意义的事件或现象发生。在入侵与欺诈检测、医疗处理、公共安全等领域,离群点检测技术具有十分重要的应用[2-4]。
离群点检测研究最早出现于统计学领域[5]。后来,Knorr等[6-7]将其引入到数据挖掘领域。现有离群点检测方法主要有三类:1)基于统计[5];2)基于邻近性[6-8];3)基于聚类[9]。其中,基于邻近性的离群点检测有基于距离、基于网格和基于密度三种方式。
符号型属性值是离散的,用传统距离法检测符号型属性数据集的离群点效果并不理想。为此,人们引入了粗糙集下的符号型属性离群点检测[10],但它基于等价关系和等价类建模,用于处理数值型属性数据集时要先对属性值离散化,既增加了处理时间,还带来了明显的数据信息损失,影响检测精准度。
为解决数值型属性的粗糙计算问题,结合邻域概念和邻域关系,文献[11]建立了邻域粗糙集模型,它是属性约简、特征选择、分类和不确定性推理研究中的重要工具[12];但是,利用邻域粗糙集模型进行离群点检测的研究并不多见,文献[13]进行了这方面的研究尝试,但是其邻域半径直接给定,具有较强的主观性和随机性。
针对离群点检测中传统距离法不能有效处理符号型属性和经典粗糙集方法不能有效处理数值型属性的问题,本文以邻域粗糙集模型为基础,提出了改进的邻域值差异度量(Neighborhood Value Difference Metric, NVDM)进行离群点检测。该方法通过定义邻域值差异度量来构造表征对象离群程度的邻域离群因子(Neighborhood Outlier Factor, NOF),从而,设计并实现了基于邻域值差异度量的离群点检测(Neighborhood Value Difference Metric-based Outlier Detection, NVDMOD)算法。所提算法拓展了离群点检测的传统距离法和粗糙集法,在计算单属性邻域覆盖(Single Attribute Neighborhood Cover, SANC)时改进了传统的无序逐一计算模式,使得算法时间复杂度降低到了对数级,明显优于现有传统无序逐一比较模式。UCI标准数据集实验表明,改进算法能有效分析和处理符号型、数值型和混合型属性数据集的离群点检测问题,且适应能力更强。
1 邻域粗糙集
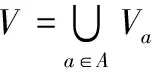
对∀x,y,z∈U和B⊆C,关联于属性子集B的距离函数dB:U×U→R+(R+非负实数集)应满足以下条件:
1)dB(x,y)≥0,dB(x,x)=0(非负性);
2)dB(x,y)=dB(y,x)(对称性);
3)dB(x,z)≤dB(x,y)+dB(y,z)(三角式)。
如果B={cj1,cj2,…,cjk}⊆C(1≤k≤m),距离函数dB的闵可夫斯基距离计算公式如下:
因等价关系和等价类只能处理符号型属性,可将距离函数和邻域半径ε结合并用来对论域U中的数据对象粒化,形成具有相似性特征的邻域关系和邻域类,进而构建可同时处理符号型属性和数值型属性的邻域信息系统(Neighborhood Information System, NIS)。
定义1 邻域。对∀x∈U,B⊆C和ε≥0,x在属性集B上的ε-邻域定义为:
(1)
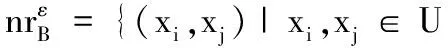
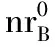
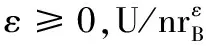
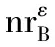
以邻域信息系统为基础,可以利用邻域粗糙性引起的邻域间的值差异度量对论域中对象之间的差异性或离群性进行度量,从而发现离群点。
2 基于邻域值差异度量的离群点检测
2.1 基于邻域值差异度量的离群点检测方法
用邻域粗糙集进行数据处理时通常会存在数据描述的量级和量纲差异。为使不同数据类型的表述都得到有效的数据处理结果,需要对数值型属性值进行归一化、标准化处理。本文采用的最小—最大法归一化的计算公式如下:
(2)
其中:maxcj和mincj为U中对象关于属性cj的最大取值和最小取值。显然,标准化属性取值区间为[0,1]。
为同时有效度量数值型和混合型属性值的差异,可用混合欧氏重叠度量(Heterogeneous Euclidian-Overlap Metric, HEOM)[14]进行邻域距离度量。
定义5 混合欧氏重叠度量。对∀x,y∈U,x和y的混合欧氏重叠度量HEOMB(x,y)定义为:
(3)
其中:
dcjh(x,y)=
对象邻域半径的设定一般由专家根据经验确定,具有较强的主观性和随机性。减少邻域构造判定算法对专家所定参数的敏感度,是提升离群点检测算法准确率的客观基础。能够将数据对象的属性取值分布信息和专家知识融合的邻域半径参数确定法更加合理、有效。为此,本文提出了x在属性cj上的邻域半径设置新方法,它具有很好的自适应特征:
(4)
其中:std(cj)是cj属性的取值标准差,用于衡量cj的均值分散程度,std(cj)大表示大部分数据对象在cj上的取值与其均值间的差异大,std(cj)小表示数据对象在cj上的取值与均值接近。λ是专家预设的用于调整邻域半径大小的参数,λ<1时邻域半径应大于属性值标准差;λ=1时邻域半径即属性值标准差;λ>1时邻域半径应小于属性值标准差。这种主、客观融合的邻域半径调节法兼顾了专家经验和属性取值分布特征对对象离群性的影响,为有效的自适应离群点检测奠定了基础。
通过对象邻域及其距离度量可刻画对象间的相似性或不可区分性。值差异度量(Value Difference Metric, VDM)[15]是度量符号型属性距离的一种有效的非加权函数。假定x和y是U中对象,F是U的特征集,xf和yf是x和y在f上的取值,df(xf,xf)是xf和xf的距离。对象x和y的VDM可定义如下:
其中:df(xf,yf)=(P(xf)-P(yf))2,P(xf)和P(yf)是x和y在f上的取值概率。
以此类推,为度量数值型属性取值的离群程度,可通过对象邻域概念将给定对象的邻域半径内的对象集成,进而对数值型属性取值进行离群度量。为此,可定义邻域值差异度量(NVDM)、邻域离群因子(NOF)及邻域离群点概念如下。
定义6 邻域值差异度量。给定λ>0,对∀xi,xj∈U,xi,xj的邻域值差异度量NVDM(xi,xj)为:
(5)

实际上,对象离群程度可用邻域离群因子度量,可将文献[13]的邻域离群因子开平方以加大对象离群程度的变化对其离群特性的正面影响。
定义7 邻域离群因子。对∀xi∈U,xi的邻域离群因子的计算公式如下:
(6)
定义8 基于邻域值差异度量的离群点。令μ为给定的离群点判定阈值,对∀x∈U,如果NOF(x)>μ,称x为U中基于邻域值差异度量的离群点。
2.2 基于邻域值差异度量的离群点检测算法
基于邻域和值差异度量概念,本文提出了基于邻域值差异度量的离群点检测(NVDMOD)算法(算法2)。它在单属性邻域覆盖(SANC)(算法1)计算时采取有序二分近邻搜索模式,效率较传统无序逐一比较模式有显著提升。在数据结构设计上,新算法用数组首行存放U中对象按属性cj升序排列的结果,数组第二行存放对象在U中的原始顺序号。
算法1 单属性邻域覆盖(SANC)算法。
输入:IS=(U,C,V,f),λ和j,其中|U|=n。
1)
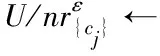
/*初始化*/
2)
N← ∅
3)
RankIndex[1..n][1..2] ← Ascend_sort(U)
/*U中对象按cj升序排列*/
4)
fori=1 tondo
5)
k←i
6)
whilek>0 do
7)
ifHEOM{cj}(RankIndex[i][1],
RankIndex[k][1])≤εcj
8)
k←k-1
9)
else
10)
break
11)
end if
12)
end while
13)
a←k+1
/*a:对象邻域的下限顺序号*/
14)
k←i+1
15)
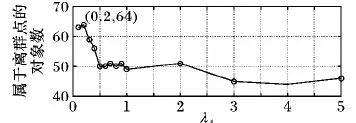
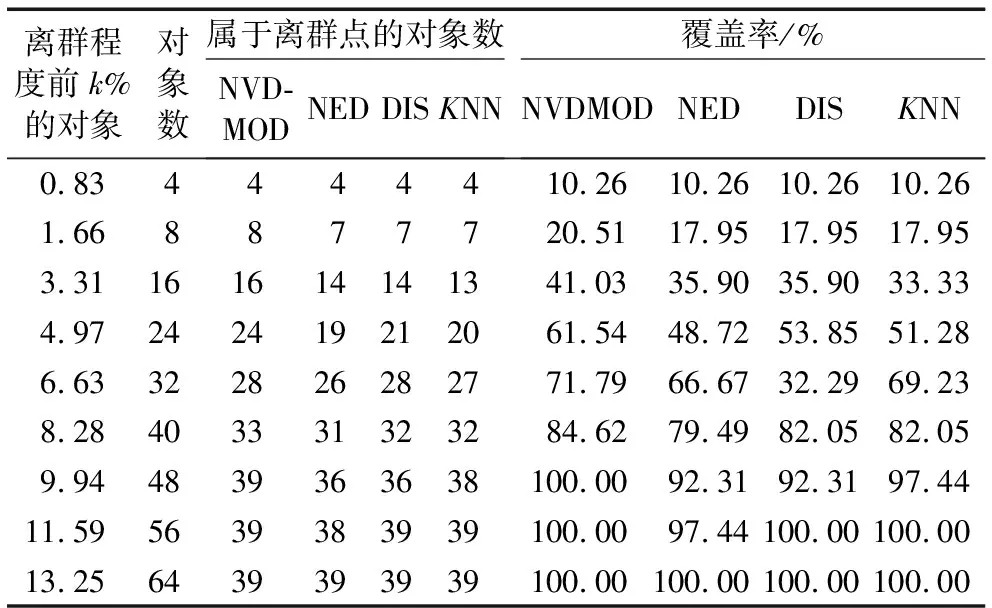
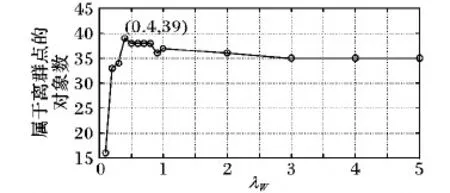
whilek 16) ifHEOM{cj}(RankIndex[i][1], RankIndex[k][1])≤εcj 17) k←k+1 18) else 19) break 20) end if 21) end while 22) b←k-1 /*b:对象邻域的上限顺序号*/ 23) N←RankIndex[a..b][1] 24) 25) end for 26) SANC算法第3)步采用堆排序[16],第4)~25)步的频度为n,第6)~12)及15)~21)步的频度为n,理论时间复杂度O(n2)与传统无序逐一比较算法相同,但由于SANC算法第3)步进行了属性值的预排序,计算对象的单属性邻域时可以利用该有序性进行二分近邻搜索。由于邻域中的对象都分布在邻近位置,对给定对象的邻域搜索比较次数会比n小很多,故SANC算法的实际计算复杂度远低于O(n2)。假定对象属性的取值等概率均匀分布,此时ε小,有序二分近邻搜索的复杂度将接近O(n)。综上,SANC算法的实际时间复杂度为O(nlogn),明显低于传统的无序逐一比较算法。 算法2 基于邻域值差异度量的离群点检测(NVDMOD)算法。 输入:IS=(U,C,V,f),阈值μ,λ,其中|U|=n,|C|=m。 输出:基于邻域值差异度量的离群点集OS(Outlier Set)。 1) OS← ∅ 2) forj← 1 tomdo 3) /*由SANC算法计算*/ 4) end for 5) fori← 1 tondo 6) forj← 1 tondo 7) fork← 1 tomdo 8) ifi≠j 9) 计算d{ck}(xi,xj) /*xi,xj的单属性距离*/ 10) end if 11) end for 12) end for 13) 计算NVDM(xi,xj) /*xi,xj的邻域值差异度量*/ 14) 计算NOF(xi) /*对象xi的邻域离群因子*/ 15) ifNOF(xi)>μ 16) OS←OS∪{xi} 17) end if 18) end for 19) returnOS 对于NVDMOD算法,由于SANC算法的复杂度为O(nlogn),它重复m次,同时,第5)~18)步的频度为m×n2,因此,NVDMOD算法的时间复杂度为O(mn2),空间复杂度为O(mn)。 本章对NVDMOD算法、邻域离群点检测(NEighborhood outlier Detection, NED)算法[13](邻域半径直接给定)、基于距离的离群点检测(DIStance-based outlier detection, DIS)方法[6](传统距离检测方法)和K最近邻(K-Nearest Neighbors,KNN)算法[17](传统距离检测方法)的性能进行实验比较,验证NVDMOD算法的有效性和适应性。 为测试NVDMOD算法的有效性,选取Annealing和Wisconsin Breast Cancer两个数据集进行实验。 首先从UCI机器学习库中获得上述数据集[18]。实验平台配置:处理器Intel Core i5- 2400;主频3.10 GHz;内存4 GB;操作系统Windows 7;编程环境Matlab R2015b。 为增强实验结果的可比性,本文采用文献[19]中的离群点检测方法评价体系以给定数据集上找出的离群点占比衡量算法的有效性。 Annealing数据集有798个数据对象、37个条件属性和1个决策属性。其中,条件属性包括30个符号型和7个数值型。数据对象分为5类,类3以外的数据对象均为离群点,共190个离群点。Annealing邻域信息系统记为NISA,邻域半径参数λA=0.2。4种算法的实验结果如表1所示。 表1 邻域信息系统NISA上的实验结果 其中:离群程度前k%的对象(对象数)是指将数据对象按离群程度值由高到低排序后,用于对比分析的对象子集比例(前k%)及其对象数;属于离群点的对象数是指离群度前k%的对象中属于离群点的对象数;覆盖率是指属于离群点对象数占离群点总数的比例。 Annealing数据集是混合型属性数据集。由表1可见,NVDMOD算法准确率明显高于其他3种算法,如离群程度前10.03%的80个数据对象中,它能检测出64个离群点,而NED、KNN和DIS算法只分别检测出了51、33和21个。由此可见,NVDMOD算法适用于混合型数据集,且优于其他算法。 图1 离群点数随λA变化的折线图(离群程度前10.03%) 离群程度前10.03%的对象中,NVDMOD算法检测出的离群点数随λA变化如图1所示,当λA=0.2时效果最好。0<λA≤2时,NVDMOD算法总体优于其他3种算法,而其余情形时优于DIS和KNN算法,接近NED算法。 Wisconsin Breast Cancer数据集有699个对象,分成 benign(65.5%)和malignant(34.5%)两类,对象的描述由9个数值型属性完成。为形成不均匀分布数据集,仿照Harkins等提出的方法[20]移去了一些属于malignant类的对象,最终的数据集包含了483个对象,其中39个属于malignant类。 将malignant类作为离群点,数据集的邻域信息系统记为NISW,邻域半径参数λW=0.4。在NISW上实验结果如表2所示。 表2 邻域信息系统NISW上的实验结果 从表2可知,在Wisconsin Breast Cancer数据集中,NVDMOD算法具有最好性能,通过对离群程度前9.94%的48个数据对象进行检测,即可检测出所有离群点。该数据集的9个属性全为数值型属性。由此可见,NVDMOD算法处理数值型数据对象问题也能取得很好的效果。 离群程度前9.94%的48个数据对象中,NVDMOD算法检测出的离群点数随λW变化的规律如图2所示,当λW=0.4时效果最好;λW≥0.4时NVDMOD算法大致具有稳定性和优化性。 图2 离群点数随λW变化的折线图(离群程度前9.94%) 针对传统距离法不能有效处理符号型属性和经典粗糙集方法不能有效处理数值型属性问题,通过归一化预处理、HEOM距离选取和具有自适应特征的邻域半径设定,本文构建了基于邻域关系和邻域类的邻域信息系统,利用邻近多数类的不确定性颗粒性质,以对象邻域值差异度量为基础进行离群点检测,较好地融合和拓展了传统距离法和粗糙集方法,能够更有效地处理符号型、数值型和混合型属性数据集。实验结果表明,所提算法在各类属性组合情形下都有更好的适应能力。本文的研究是针对邻域粗糙集方法及其应用的拓展。后续研究中,可以考虑通过属性序列和属性集序列[10]集成离群因子,以提高算法检测结果的有效性和算法效率。另外,还可以考虑将各类属性取值的离群特征信息融合到对象的离群度量模型中,进一步提高算法效率;以及引入统计检验进一步分析各算法的性能优劣。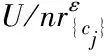
3 实验结果及其分析
3.1 实验环境
3.2 Annealing数据集

3.3 Wisconsin Breast Cancer 数据集
4 结语
猜你喜欢
科教导刊·电子版(2021年6期)2021-05-06 05:05:10
吉林大学学报(理学版)(2020年3期)2020-05-29 06:32:16
自动化学报(2018年7期)2018-08-20 02:59:04
厦门理工学院学报(2016年3期)2016-11-10 09:39:14
周口师范学院学报(2016年5期)2016-10-17 06:36:47
广东石油化工学院学报(2016年3期)2016-05-17 05:17:10
中国房地产业(2016年9期)2016-03-01 01:26:47
作文评点报·低幼版(2015年5期)2015-05-30 10:48:04
四川师范大学学报(自然科学版)(2015年1期)2015-02-28 14:07:21
西安交通大学学报(2014年8期)2014-04-16 05:07:06
